一种利用k均值聚类算法识别就业地的方法
文献发布时间:2023-06-19 11:26:00
技术领域
本发明涉及城市就业地研究领域,具体涉及一种利用k均值聚类算法识别就业地的方法。
背景技术
就业地是城市居民参与生产活动而构成的固定空间范围——时间上,在就业地参与生产活动的时间具有规律性,通常呈现白天人多,晚上人少的特征;地点固定性,是居民参与生产活动频繁使用的空间。因此,根据上述特征,本研究探讨的就业地是指城市居民参与生产活动的地理位置。
传统的就业地识别思路主要依赖于用户白天数据的规律性,即通过用户白天在一个周期内不同时间节点出现在同一基站的次数累加起来判断是否为就业地,有一定的可操作性和合理性。
目前,上述识别方法最大的问题是:首先,识别时间主要依赖单时段(白天)用户的基站移动情况,而很可能将上夜班、两班倒和三班倒(如医院和工厂等特定的企事业单元)的实际就业地忽略,甚是误判为用户居住地;其次,该方法从用户个体行为数据角度直接判断其就业地,预先假设了用户“白天上班,晚上居家”的行为模式,忽略了用户除就业以外的出行,缺少在微观空间单元内对大量用户数据进行统计分析以准确判断该微观空间单元是否为就业地。
发明内容
针对现有技术的不足,本发明提出了一种利用k均值聚类算法识别就业地的方法,通过同步采纳和分析手机用户的白天和夜间的大数据进行“整日识别”,能够精准识别其居住地与就业地,避免了传统方法的疏漏;在以基站作为空间单元的基础上,以用户行为模式作为样本进行聚类分析,能够准确的判断各空间单元中占主导的人群活动方式,并进一步判断就业者的实际就业模式和空间单元的就业/居住类型。本发明的目的可以通过以下技术方案实现:
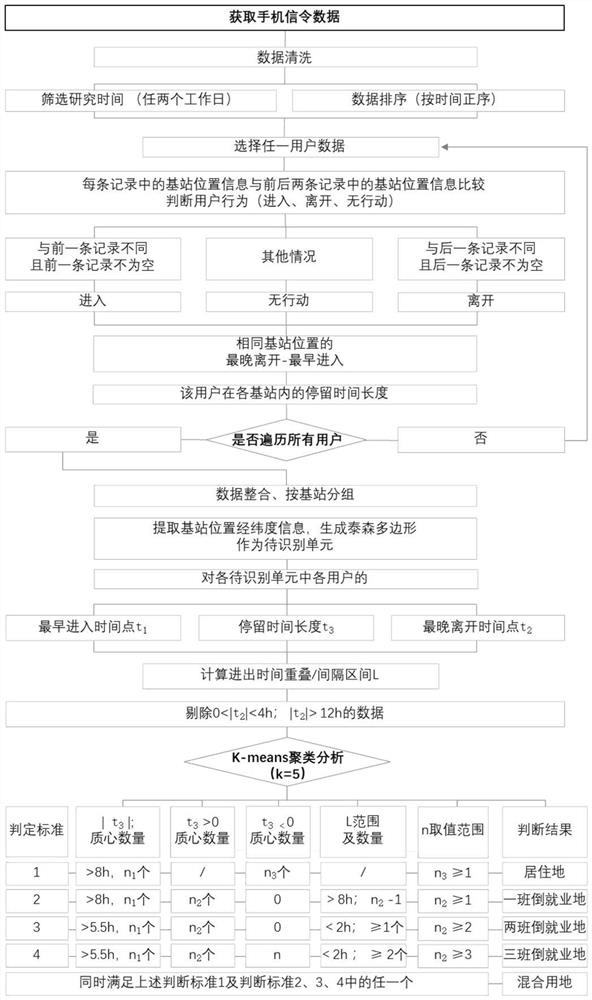
一种利用k均值聚类算法识别就业地的方法,包括以下步骤:
根据区域内目标基站的经纬度信息数据生成泰森多边形,并以泰森多边形作为待识别单元;
根据区域内的两个相邻工作日的手机信令数据进行清洗并统计所有用户进入和离开所述待识别单元行为发生的时间节点;
将所有用户的最晚离开时间节点减去对应用户的最早进入时间节点获取用户的停留时间长度;
采用k均值聚类算法对所述用户最晚离开时间节点、所述用户最早进入时间节点和所述用户的停留时间长度进行聚类分析获取质心,并根据所述质心计算所述质心之间进出时间点重叠/间隔区间;
根据满足所述停留时间长度阈值的质心数量、所述停留时间长度的正负方向和所述进出时间点重叠/间隔区间判断所述待识别单元是否为就业地及就业地种类。
进一步地,所述最晚离开时间节点的选取包含以下步骤:
若用户满足在第一天工作日存在离开所述待识别单元的记录,则选取所述第一天工作日的最晚离开时间节点为所述最晚离开时间节点;
若用户不满足在第一天工作日存在离开所述待识别单元的记录,则选取所述第二天工作日的最晚离开时间节点为所述最晚离开时间节点。
在用户第二天0点前无离开行动记录的前提下,取第二天24点前最晚离开时间节点,目的在于同时统计当日进出与隔日进出两种行动模式中的最晚离开时间节点。居民进出居住地多为当日进出,因此其最晚离开时间-最早进入时间<0;而夜班工作人员进出夜班就业地多为隔日进出,其最晚离开时间-最早进入时间>0。
进一步地,所述质心之间进出时间点重叠/间隔区间的计算包含以下步骤:
任选两个满足所述停留时间长度阈值的质心记为质心A和质心B,将所述质心A和所述质心B的进出时间点分别记为(Ia,Ea)、(Ib,Eb);
根据L=||Ia-Eb|-(|Ia-Ea|+|Ib-Eb|)|,计算所述进出时间点重叠/间隔区间L。
进一步地,所述就业地种类的具体判断过程,包含以下步骤:
满足所述停留时间长度大于0、绝对值大于8h的质心数量大于等于1、所述进出时间点重叠/间隔区间存在且大于8h或者所述进出时间点重叠/间隔区间不存在,则判定所述待识别单元为一班就业地;
满足所述停留时间长度小于0、绝对值大于8h的质心数量大于等于1、所述进出时间点重叠/间隔区间不存在,则判定所述待识别单元为居住地;
满足所述停留时间长度大于0、绝对值大于5.5h的质心数量大于等于2、所述进出时间点重叠/间隔区间小于2h且所述进出时间点重叠/间隔区间的数量大于等于1,则判定所述待识别单元为两班倒就业地;
满足所述停留时间长度大于0、绝对值大于5.5h的质心数量大于等于3、所述进出时间点重叠/间隔区间小于2h且所述进出时间点重叠/间隔区间的数量大于等于2,则判定所述待识别单元为三班倒就业地;
所述待识别单元的判定结果既为居住地,又为一班就业地、两班倒就业地或三班倒就业地中的任一个,则判断所述待识别单元为居住混合用地。
考虑到同一待识别单元内不同企业单位上下班时间点可能不同,但9点-17点应属于工作时间的集中区间(大部分一班倒工作地工作时长应≥8h),规定进行一班倒就业地判断时,停留时间阈值需>8h、进出时间点重叠/间隔区间需>8h;考虑到同一待识别单元内不同住区住户回家、上班时间点可能不同,但22点-次日6点应属于睡眠的集中区间,规定进行居住地判断时,停留时间阈值需>8h、进出时间点重叠/间隔区间需>8h;考虑到倒班就业地每班工作时长可能较短,每一班次的交接换班时间一般在2h之内,规定进行两班倒、三班倒就业地判断时,停留时间阈值需>5.5h、进出时间点重叠/间隔区间需<2h。
进一步地,所述k均值聚类算法中的K值设定为5,k=5意味着聚类分析结果为五个簇,得以涵盖班次最多的三班倒就业地人群行动模式,同时经检验k=5时聚类分簇情况较好。
进一步地,所述k均值聚类算法计算前,筛除所述停留时间长度的绝对值大于12h和小于4h对应用户的手机信令数据;目的在于筛除停留时间过短或过长,不属于正常就业班次的样本,避免对聚类结果的影响。
所述k均值聚类算法计算后,筛除簇内样本量小于总样本量10%的簇,是因为这类簇样本量不足,属于偶然情况或数据噪点,避免对后续判断产生误导。
进一步地,所述根据区域内的两个相邻工作日的手机信令数据进行清洗并统计所有用户进入和离开所述待识别单元行为发生的时间节点包含以下步骤:
根据所述手机信令数据获取用户任意一条记录中的所述目标基站位置信息;
根据所述记录的目标基站位置信息、所述记录的前一条记录和后一条记录中的基站位置信息,判断所述记录对应的时间点类型;
满足所述前一条位置信息存在且与所述目标基站位置信息不同,则判定所述记录对应的时间点为进入所述待识别单元的时间点;
满足所述后一条位置信息存在且与所述目标基站位置信息不同,则判定所述记录对应的时间点为离开所述待识别单元的时间点;
满足所述后一条位置信息和所述前一条位置信息均不存在,或者所述后一条位置信息和所述前一条位置信息均与所述目标基站位置信息相同,则判定所述记录对应的时间点为无行动的时间点。
进一步地,获取所述待识别单元的用地性质,所述待识别单元的用地性质为E类或G类用地,直接判定所述待识别单元为非就业地。
进一步地,执行所述计算机程序时实现如权利要求1-8任一项所述的方法。
一种城市布局研究终端,其特征在于:包括如权利要求9所述的存储介质。
本发明的有益效果:
本发明提供一种采用运营商手机信令大数据,相对精确地辨识某个区域是否为就业地的方法。以某个基站生成的泰森多边形为识别区域,统计每个用户最晚离开时间节点、最早进入时间节点,及二者之间的停留时间长度,通过K均值聚类法对时间节点和时间间隔进行聚类分析,根据聚类结果中满足停留时间长度阈值的质心数量、停留时间长度的正负方向,以及各质心进出时间的重叠/间隔区间判断该基站是否为就业地、是何种就业地类型(一班制就业地、两班倒就业地和三班倒就业地)。本发明可较为便捷和准确地识别城市人口的就业地,为城市空间的利用提供有力的技术支撑。
附图说明
下面结合附图对本发明作进一步的说明。
图1为本申请的利用K均值聚类处理手机信令数据识别就业地的方法流程示意图;
图2为本申请的某示例街道示意图;
图3为本申请的改示例街道内基站示意图;
图4为本申请的示例街道内基站生成泰森多边形作为待识别单元示意图;
图5为本申请的示例街道判断结果;
图6为本申请的实施一判断结果及其K均值聚类图像;
图7为本申请的实施二判断结果及其K均值聚类图像;
图8为本申请的实施三判断结果及其K均值聚类图像;
图9为本申请的实施四判断结果及其K均值聚类图像;
图10为本申请的重叠/间隔区间计算示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
在本发明的描述中,需要理解的是,术语“开孔”、“上”、“下”、“厚度”、“顶”、“中”、“长度”、“内”、“四周”等指示方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的组件或元件必须具有特定的方位,以特定的方位构造和操作,因此不能理解为对本发明的限制。
在本说明书的描述中,参考术语“一个实施例”、“示例”、“具体示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
以为某市的街道为试验点,按照图1的流程进行判断所有基站;
步骤1:将该示例街道内的所有手机基站生成泰森多边形,每个泰森多边形代表一个基站的覆盖范围,作为本发明的待识别单元,如图2至图5所示;
步骤2:获取最早进入、最晚离开各识别单元行为的发生时间节点和二者之间的停留时间长度;
步骤2.1:提取任两个工作日手机信令数据,将手机信令数据进行时间排序,遍历所有用户数据;
步骤2.2:对每个用户的每条记录中的基站位置信息与前后两条记录中的基站位置信息比较,来判断用户行为属于进入基站、离开基站、无行动中的哪一种;
步骤2.3:筛选待识别单元内每个用户最早进入时间节点t
步骤2.4:筛选待识别单元内每个用户的最晚离开时间节点t
步骤2.5:将每个用户在每个待识别单元内的最晚离开时间点减去最早进入时间点,得到停留时间长度t
步骤3:选择示例街道任一基站(待识别单元),统计各用户的最晚离开时间节点、最早进入时间节点,及二者之间的停留时间长度,并通过K均值聚类法对时间节点和时间间隔进行聚类分析;
步骤3.1:统计每个用户的最晚离开时间节点、最早进入时间节点,及二者之间的停留时间长度,
步骤3.2:以每个用户行为为样本,以最晚离开时间节点、最早进入时间节点、停留时间长度为变量,通过K均值聚类法进行聚类分析,k=5(k=5意味着聚类分析结果为五个簇,得以涵盖班次最多的三班倒就业地人群行动模式,同时经检验k=5时聚类分簇情况较好);
步骤3.3:对不同质心进出时间点的重叠/间隔区间L进行计算,方式如下:
设任两个质心为质心A、质心B;其进入、离开时间节点为(Ia,Ea)、(Ib,Eb)
则质心A、B进出时间点重叠/间隔区间L=||Ia-Eb|-(|Ia-Ea|+|Ib-Eb|)|,如图10所示。
步骤3.4:对质心分布规律进行比较和判断如表1所示,是对满足停留时间长度阈值的质心数量、停留时间长度的正负方向,以及各质心进出时间的重叠/间隔区间进行比较和判断,来确定待识别单元是否为就业地及就业地类型;
表1
步骤4:遍历示例街道的所有基站(待识别单元),对各个待识别单元进行如上述步骤2、步骤3操作直所有待识别单元都判断完毕;
下面举出关于待识别单元的就业地种类的具体判断实施例:
实施例一:以某光电厂区及其宿舍区的基站为例
表2
由表2和图6可见,该待识别单元簇内样本量>总样本数量10%的簇(第1、2、5类)中:存在一个t
无|t
存在三个t
因此该待识别单元应属于纯一班制白班就业地,现状为某光电厂区及其宿舍区,判断结果和现状相符合。
实施例二:以某住宅区的基站为例
表3
由表3和图7可见,该待识别单元簇内样本量>总样本数量10%的簇(第2、3、4、5类)中:
无t
存在2个|t
存在1个t
因此该待识别单元应属于纯居住地,现状为某住宅区,判断结果和现状相符合。
实施例三:以某科技产业园的基站为例
表4
由表4和图8可见,该待识别单元簇内样本量>总样本数量10%的簇(第2、3、4、5类)中:
存在一个t
无|t
存在四个t
因此该待识别单元应属于纯一班制白班就业地,现状为某科技产业园,判断结果和现状相符合。
实施例四:以某电子商务有限公司的基站为例
表5
由表5和图9可见,该待识别单元簇内样本量>总样本数量10%的簇(第1、3、4、5类)中:
存在一个t
无|t
存在四个t
因此该待识别单元应属于三班倒就业地,现状为某电子商务有限公司,判断结果和现状相符合。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。
- 一种利用k均值聚类算法识别就业地的方法
- 一种基于招聘文本挖掘的专业主要就业方向识别方法