结合深度学习模型和传统分类器的用于PolSAR数据的分类方法及系统
文献发布时间:2024-01-17 01:27:33
技术领域
本发明涉及数据分类技术领域,尤其涉及一种结合深度学习模型和传统分类器的用于PolSAR数据的分类方法及系统。
背景技术
合成孔径雷达(synthetic aperture radar,SAR)通过主动发射电磁波并接收回波来获取地面信息,不受光照和云雾的遮挡,能够全天时全天候地工作。全极化SAR(polarimetric synthetic aperture radar,PolSAR),有4个极化通道,电磁波水平发射后水平接收和垂直接收,垂直发射后垂直接收和水平接收,获得地物的全极化后向散射信息,在表征地物的极化特征方面更具有优势。因此利用PolSAR数据对地物进行分类是其重要的应用之一。
传统的用于PolSAR数据的分类方法,根据是否需要训练样本,可以分成监督极化分类和非监督极化分类。
监督分类是先用已知其属性类别的训练样本训练分类器,以掌握各个类别的统计特征,然后以此为依据按照分类决策规则进行分类识别的过程。用于PolSAR数据监督极化分类中主要有基于最大似然的监督分类,基于支持向量机(support vector machines,SVM)的监督分类和基于决策树的监督分类。
基于最大似然的监督分是建立在贝叶斯准则和每类的概率分布呈高斯分布这种假设的基础上的,是一种风险最小的判决分析。比如,Cheng等人通过分析表面散射、双反弹散射和体积散射的一般特征,提出了一种最大似然分类器,将PolSAR像元按3个PolSAR指标分为9类。Lee等人将最大似然规则推广到SAR多视情况,发展了基于复Wishart分布的极化协方差矩阵监督分类算法。但是由于遥感信息的统计分布具有高度的复杂性和随机性,当特征空间中类别的分布比较离散而导致不能服从预先假设的分布或者样本的选取不具有代表性,往往得到的分类结果会偏离实际情况。
基于SVM的监督分类,以统计学习理论为基础,在训练样本有限的情况下仍表现出良好的泛化能力。比如,Aghababaee等人利用泡利分解向量和分形维数构造了一种新的分形特征向量,并将SVM用于处理非线性分类器问题。但只考虑极化相干矩阵的各元素时,SVM在L波段与基于最大似然准则的分类结果相似。但SVM对自身的核函数及参数高度敏感,在有异常值的数据分类中,效率可能会降低。
基于决策树的监督分类是一种非参数算法,独立于数据分布,善于挖掘特征之间相关性的优势,通常利用各种极化SAR目标分解将散射矩阵分解为多个分量参与分类过程。比如,Deng等人提出了一种将极化分解和决策树算法相结合的极化SAR数据分类方法。但是当类别太多时,该方法分类的错误可能就会增加的比较快。
非监督分类是指在缺乏先验知识的情况下,以集群理论为基础,仅通过计算机对图像进行聚类统计分析,根据待分类样本特征参数的统计特征,建立决策规则来进行分类的方法。比如,Van Zyl提出利用入射波和散射波之间相位和旋转的关系进行非监督分类,将目标分为一次散射目标、二次散射目标、混合目标和不可分目标。这种方法对极化信息的利用是有限的。K-均值算法收敛快高效,可以用来对相干矩阵T或协方差矩阵C进行分类,通过计算每个聚类的最大似然估计来初始化聚类中心。但是K-均值算法对于初始点的选取敏感,并且只能保证分类结果局部最优。H/α非监督分类,通过Cloude分解得到散射熵H和平均散射角特征参数后,根据这两个参数对目标进行分类。这种方法从基本散射机制的物理解释来估计观测散射媒质的类型,然而H/α平面中任意固定边界可能不符合数据的分布,相似自然地物的聚类可能会跨越决策平面的边界。
随着机器学习的发展,研究人员发现,当目标对象具有丰富含义的时候,上述浅层结构的分类方法在提取特征及泛化能力方面有明显的不足。近年来,由于深度学习模型学习能力非常强,能够从影像数据中直接学习图像的丰富的特征,能解决很复杂的问题,具有很好的移植性,极大地提高影像分类的精度,在PolSAR数据分类中表现出了良好的性能。目前深度置信网络(deep Boltzmann machine,DBN)、深度自动编码(stacked auto-encoder,SAE)、卷积神经网络(,CNN)、胶囊网络等深度学习模型在PolSAR数据分类中都有应用。比如,Hua等人在考虑到PolSAR数据服从Wishart分布的基础上,提出了一种用于PolSAR图像分类的多层Wishart受限玻尔兹曼机(MWRBM)模型,用于提高分类结果。Shang等人增加局部像素之间的关系作为分类特征,提出了一种结合散射功率和堆栈稀疏自编码器(scattering SSAE)进行PolSAR分类的新方法。Bi等人为了在大幅降低标注成本的同时提高分类性能提出了一种将主动学习和卷积神经网络(Convolutional Neural Networks,CNN)相结合的最小监督PolSAR图像分类的主动深度学习方法。Cheng等人认为CNN中的单个神经元无法代表土地覆盖的多个极化属性,而胶囊网络(CapsNet)可以利用向量代替单个神经元来表征极化属性,提出了一种分层胶囊网络(HCapsNet)用于PolSAR图像的土地覆盖分类。虽然深度学习方法分类精度高,但是深度学习计算量大,对于硬件的要求很高,模型设计非常复杂,依赖数据,可解释性不高,在训练数据不平衡的情况下会出现精度下降等问题。
上述分类方法,无论是传统的浅层分类方法,还是深度学习分类方法都是没有重点考虑容易被错误标记的像素,影响了最终的分类结果。
发明内容
本发明提出一种结合深度学习模型和传统分类器的用于PolSAR数据的分类方法及系统,用以解决或者至少部分解决现有技术中存在的分类准确性不高的技术问题。
为了解决上述技术问题,本发明技术方案为:
第一方面提供了结合深度学习模型和传统分类器的用于PolSAR数据的分类方法,包括:
利用训练好的CNN模型对PolSAR数据进行分类;
将分类结果中容易被错误标记的像素作为重点像素,其他的像素作为一般像素,保留一般像素的类别标签;
利用AdaBoost算法将SVM分类器、wishart分类器和决策树分类器组成一个强分类器对重点像素进行再次分类,得到重点像素的类别;
将重点像素的类别和一般像素的类别组合作为PolSAR数据的最终分类结果。
在一种实施方式中,利用训练好的CNN模型对PolSAR数据进行分类,包括:
采用了分层随机抽样方法为每类地物选择训练样本;
将PolSAR数据四周填充0,填充大小为14,通过窗口滑动,将PolSAR数据切割为不同的patch,滑动步长为1,patch大小为15像素×15像素×9通道,每块patch的类别对应于中心像素的类别;
利用选择出的训练样本对应的patch对CNN模型进行训练,得到训练好的CNN模型,其中,训练好的CNN模型包括输入层、隐藏层和输出层,隐藏层包括多个激活函数、多个3D池化层、多个3D卷积层和多个全连接层;
将PolSAR数据输入训练好的CNN模型中,获得隐藏层的最后一层全连接层的输出和分类结果。
在一种实施方式中,隐藏层的最后一层全连接层根据输入的数据输出一个N×C矩阵,其中,N是PolSAR数据的像素个数,C是类别的总数,N×C矩阵的行表示某个像素的C个类别预测概率;找出每个像素的最大预测概率和第二大预测概率,取二者非负的差值作为概率差,如果概率差小于给定的阈值,则将该像素作为重点像素,其他的像素作为一般像素。
在一种实施方式中,利用训练好的CNN模型对PolSAR数据进行分类时,选择的分类特征包括存储地物的后向散射信息的相干矩阵T的9个元素:T11,T12_real,T12_imaginary,T13_real,T13_imaginary,T22,T23_real,T23_imaginary,T33。
在一种实施方式中,利用AdaBoost算法将SVM分类器、wishart分类器和决策树分类器组成一个强分类器对重点像素进行再次分类,包括:
使用同一个训练集训练不同的弱分类器;
将训练得到的弱分类器进行集合,构建一个强分类器,该过程中,被前一个弱分类器误分类的样本的权值会增大,正确分类的样本的权值会减小,并再次用来训练下一个弱分类器,同时,在每一轮迭代中,加入一个新的弱分类器,直到达到预设错误率或预先指定的最大迭代次数再确定最后的强分类器,且在每次迭代过程中将一个参与过分类的类别看作1,其他未参与过分类的类别看作-1;
利用构建的强分类器对重点像素进行再次分类。
基于同样的发明构思,本发明第二方面提供了结合深度学习模型和传统分类器的用于PolSAR数据的分类系统,包括:
初始分类模块,用于利用训练好的CNN模型对PolSAR数据进行分类;
重点像素筛选模块,用于将分类结果中容易被错误标记的像素作为重点像素,其他的像素作为一般像素,保留一般像素的类别标签;
再次分类模块,用于利用AdaBoost算法将SVM分类器、wishart分类器和决策树分类器组成一个强分类器对重点像素进行再次分类,得到重点像素的类别;
最终分类结果获取模块,用于将重点像素的类别和一般像素的类别组合作为PolSAR数据的最终分类结果。
基于同样的发明构思,本发明第三方面提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被执行时实现第一方面所述的方法。
基于同样的发明构思,本发明第四方面提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现第一方面所述的方法。
与现有技术相比,本发明提供的技术方案至少具有以下技术效果:
本发明首先利用CNN对PolSAR数据进行分类,定位出容易被错误标记的像素作为重点像素,其他的作为一般像素,保留一般像素的类别标签;接着利用AdaBoost算法将SVM分类器、wishart分类器和决策树分类器组成一个强分类器对重点像素再次分类。最后,把重要像素的类别和一般像素的类别组合为最终的结果,首先利用深度学习模型进行初步分类,并利用AdaBoost算法将SVM分类器、wishart分类器和决策树分类器组成一个强分类器对重点像素再次分类,由于考虑了容易被错误标记的重点像素,并结合深度学习模型和传统分类器的方式进行分类,从而可以提高分类的精度和准确性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
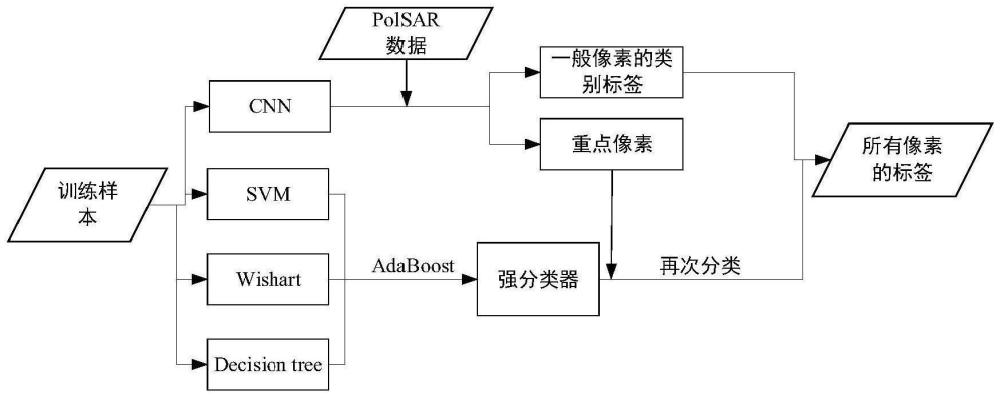
图1是本发明实施例提供的结合深度学习模型和传统分类器的用于PolSAR数据的分类方法的整体框架图;
图2是本发明实施例中定位关键像素的流程图;
图3是本发明实施例中实验数据在概率差分别为0.1至0.8时,被查找出的重点像素示意图;
图4是本发明实施例中PolSAR图像(实验数据)在不同概率差下的总体精度;
图5是本发明实施例中当概率差为0.7时,实验数据中重点像素的标签,其中(a)部分为重新分类之前;(b)部分为重新分类后;
图6是本发明实施例中实验数据分别使用不同的方法的分类结果示意图,其中,(a)部分采用的方法为CNN,(b)部分采用的方法为SVM,(c)部分采用的方法为Wishart,(d)部分采用的方法为decision tree,(e)部分采用的方法为AdaBoost,(f)部分采用的方法为本发明采用的方法。
具体实施方式
本申请发明人通过大量的研究与实践发现,任何分类器都有自身的优势和劣势,并且通过融合多个分类器可以获取多个分类器的优势。将多个分类器的分类结果融合起来,获得比单独使用某个分类器更好的分类结果。
然而现有的分类方法中,无论是传统的浅层分类方法,还是深度学习分类方法,或者是融合多种分类器的分类方法,都是没有重点考虑容易被错误标记的像素,影响了最终的分类结果。针对这个问题,本发明将容易被错误标记的像素进行再次分类获得最终的分类结果。本发明首先利用CNN对PolSAR数据进行分类,定位出容易被错误标记的像素作为重点像素,其他的作为一般像素,保留一般像素的类别标签;接着利用AdaBoost算法将SVM分类器、wishart分类器和决策树分类器组成一个强分类器对重点像素再次分类。最后,把重要像素的类别和一般像素的类别组合为最终的结果。本发明一方面融合了多个传统分类器,另一方面将深度学习模型与融合后的传统分类器相结合对重点像素进行再次分类,可以大大提高分类的精度。
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例一
本发明提供了结合深度学习模型和传统分类器的用于PolSAR数据的分类方法,包括:
利用训练好的CNN模型对PolSAR数据进行分类;
将分类结果中容易被错误标记的像素作为重点像素,其他的像素作为一般像素,保留一般像素的类别标签;
利用AdaBoost算法将SVM分类器、wishart分类器和决策树分类器组成一个强分类器对重点像素进行再次分类,得到重点像素的类别;
将重点像素的类别和一般像素的类别组合作为PolSAR数据的最终分类结果。
具体地,请参见图1,是本发明实施例提供的结合深度学习模型和传统分类器的用于PolSAR数据的分类方法的整体框架图。首先利用训练好的卷积网络模型对PolSAR数据进行初步分类,并定位出重点像素,然后利用AdaBoost算法将多个分类器进行集成得到一个强分类器,利用强分类器对定位出的重点像素进行再次分类,最后将一般像素的分类结果与重点像素的分类结果进行组合作为最终分类结果。
在一种实施方式中,利用训练好的CNN模型对PolSAR数据进行分类,包括:
采用了分层随机抽样方法为每类地物选择训练样本;
将PolSAR数据四周填充0,填充大小为14,通过窗口滑动,将PolSAR数据切割为不同的patch,滑动步长为1,patch大小为15像素×15像素×9通道,每块patch的类别对应于中心像素的类别;
利用选择出的训练样本对应的patch对CNN模型进行训练,得到训练好的CNN模型,其中,训练好的CNN模型包括输入层、隐藏层和输出层,隐藏层包括多个激活函数、多个3D池化层、多个3D卷积层和多个全连接层;
将PolSAR数据输入训练好的CNN模型中,获得隐藏层的最后一层全连接层的输出和分类结果。
具体来说,用以训练CNN模型的训练数据来自于每个PolSAR数据对应的地物真实分布参考图,每类地物的像素的数量差别较大,为了避免每类地物的训练样本数量的不平衡对最终结果产生不良影响,本发明采用了分层随机抽样方法为每类地物选择训练样本。分层随机抽样适用于总体单位数量较多、内部差异较大的调查对象,并且具有较小的抽样误差。
PolSAR数据四周填充0,填充大小为14。通过窗口滑动,将PolSAR数据切割为一块块patch,滑动步长为1,patch大小为15像素×15像素×9通道。每块patch的类别对应于中心像素的类别。然后利用训练样本对应的patch训练CNN得到一个CNN分类模型。本实施方式中采用的CNN的结构如表1所示。
表1CNN结构
其中,Input Layer、Hidden Layers、Output Layer分别为输入层、隐藏层和输出层,3D-convolution Layer、Activation Function、3D-Pooling Layer、Fully ConnectedLayer、Classification Layer分别表示3D卷积层、激活函数、3D池化层、全连接层和分类层。
在一种实施方式中,隐藏层的最后一层全连接层根据输入的数据输出一个N×C矩阵,其中,N是PolSAR数据的像素个数,C是类别的总数,N×C矩阵的行表示某个像素的C个类别预测概率;找出每个像素的最大预测概率和第二大预测概率,取二者非负的差值作为概率差,如果概率差小于给定的阈值,则将该像素作为重点像素,其他的像素作为一般像素。将一般像素的类别信息进行储存。
具体来说,将PolSAR影像数据输入训练好的CNN分类模型中,获得最后一层全连接层的输出和最终的分类结果。全连接层(fully connected layers,FC)可以完成特征的进一步融合,使得神经网络最终看到的特征是全局特征。
重点像素的定位过程如图2所示。
在一种实施方式中,利用训练好的CNN模型对PolSAR数据进行分类时,选择的分类特征包括存储地物的后向散射信息的相干矩阵T的9个元素:T11,T12_real,T12_imaginary,T13_real,T13_imaginary,T22,T23_real,T23_imaginary,T33,其中,T11表示相干矩阵的第一行第一列的元素,T12_real表示相干矩阵的第一行第一列的元素的实部,T12_imaginary表示相干矩阵的第一行第一列的元素的虚部,其他的类似。
具体来说,PolSAR通过测量地面每个分辨单元内的散射回波,进而获得其极化散射矩阵:
散射矩阵[S]只能够描述所谓的相干或纯散射体,不能用来描述所谓的分布散射体。由于存在斑点噪声,这类散射体只能统计地描述。为了减少斑点噪声的影响,只有二阶极化表达可以用来分析分布散射体。相干矩阵就是其中一种二阶描述因子。
已有研究工作证明,地物的后向散射信息主要集中在相干矩阵T中,因此本实施例选择相干矩阵T的9个元素T11,T12_real,T12_imaginary,T13_real,T13_imaginary,T22,T23_real,T23_imaginary,T33作为本发明的分类特征。
在一种实施方式中,利用AdaBoost算法将SVM分类器、wishart分类器和决策树分类器组成一个强分类器对重点像素进行再次分类,包括:
使用同一个训练集训练不同的弱分类器;
将训练得到的弱分类器进行集合,构建一个强分类器,该过程中,被前一个弱分类器误分类的样本的权值会增大,正确分类的样本的权值会减小,并再次用来训练下一个弱分类器,同时,在每一轮迭代中,加入一个新的弱分类器,直到达到预设错误率或预先指定的最大迭代次数再确定最后的强分类器,且在每次迭代过程中将一个参与过分类的类别看作1,其他未参与过分类的类别看作-1;
利用构建的强分类器对重点像素进行再次分类。
具体来说,在这一个步骤中,以SVM分类器、Wishart分类器和决策树分类器为弱分类器,利用AdaBoost algorithm将三者组合成一个强分类器,对重点像素进行再次分类。
首先,需要利用训练样本分别训练SVM分类器、Wishart分类器和决策树分类器,获得3个分类模型。
SVM是一种二分类模型。SVM学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面w
Lee等将最大似然规则推广到SAR多视情况,发展了基于复Wishart分布的极化协方差矩阵监督分类算法。由于极化协方差矩阵可以通过线性变换得到极化相干矩阵[T],所以极化相干矩阵pT]也服从复Wishart分布。应用最大似然准则于复Wishart分布,得到决策规则
决策树算法递归地选择最优特征,并根据该特征对训练数据进行分割,使得各个子数据集有一个最好的分类。决策树算法就是以信息增益来度量属性的选择,选择分裂后信息增益最大的属性进行分裂。假定当前样本集合X中第k类样本所占的比例为P
AdaBoost是一种迭代算法,其核心思想是使用同一个训练集训练不同的弱分类器,然后把这些弱分类器集合起来,构成一个强分类器。在这个过程中,被前一个弱分类器误分类的样本的权值会增大,而正确分类的样本的权值会减小,并再次用来训练下一个弱分类器。同时,在每一轮迭代中,加入一个新的弱分类器,直到达到某个预定的足够小的错误率或预先指定的最大迭代次数再确定最后的强分类器。
给定训练数据集:(x
D
其中,w
接着进行下列第t次迭代,t=1,2,3。
选取一个当前误差率最低的弱分类器h作为第H
其中,D
计算该基本分类器在最终强分类器中所占的权重:
其中,α
更新训练样本的权值分布D
其中Z
最后,按弱分类器权重组合各个弱分类器.
通过符号函数sign的作用,得到一个强分类器为:
以上AdaBoost算法是针对二分类问题。由于具体实验中采用的PolSAR数据中含有多个类别,本发明中每次迭代将一个没有参与过分类的类别看作1,其他未参与过分类的类别看作-1。最后,通过构建C次强分类器完成对重点像素的再次分类,获得重点像素的新的类别。
最后,将一般像素的分类结果和重点像素的分类结果组合成PolSAR的分类结果。
下面通过具体的实验数据对本发明提出的方法进行验证与说明。
1、实验数据
第1个PolSAR数据是NASA/JPL实验室AIRSAR系统1989年8月16日获取的荷兰中部Flevoland地区L波段全极化4视数据。图像大小为750像素×1024像素,方位向分辨率为12.1m,距离向分辨率为6.7m,包含11类地物,即Bareland,Beet,Grass,Lucerne,Pea,Potato,Rape,Soybean,Water,Wheat,Wood(分别表示裸地,甜菜,草地,苜蓿,豌豆,土豆,油菜,黄豆,水,小麦,林地)。在成像同期由JPL实验室组织对这一地区进行了详尽的勘察,得到了真实地物分布参考图,为评估分割精度提供了依据。
2、参数设置
本实施例中CNN的结构如表1所示。CNN的输入窗口尺寸为15×15×9。第一层卷积核为3×3×5,卷积层的滤波器数量为8,激励函数为Rectified Linear Unit(ReLU),池化层是尺寸为2×2×1最大池化,步长为1。第二层卷积核为3×3×4,卷积层的滤波器数量为4,激励函数为Rectified Linear Unit(ReLU),池化层是尺寸为2×2×1最大池化,步长为1。第一层全连接层有256个神经元,为了防止训练的时候过拟合采用dropout,dropout的概率为0.4。第二层全连接层有128个神经元,为了防止训练的时候过拟合采用dropout,dropout的概率为0.4。最后一层全连接层的神经元个数为类别数。最后采用交叉熵损失的softmax分类器实现分类。学习率为0.001,迭代次数为100次。
3、训练样本
具体实施过程中,分层随机抽样为PolSAR数据选择出来的训练样本。表2为每个数据的每类地物的样本数目。根据地物的类别数来确定总的训练样本数,实验采用的PolSAR数据有11种地物,因此训练样本总数为11000。
表2每类地物的样本数目
4、实验结果和分析
4.1重点像素的再次分类前后的精度比较
图3为实验数据在概率差分别为0.1至0.8时,被查找出的重点像素。其中,(a)部分对应的概率差为0.1;(b)部分对应的概率差为0.2;(c)部分对应的概率差为0.3;(d)部分对应的概率差为0.4;(e)部分对应的概率差为0.5;(f)部分对应的概率差为0.6;(g)部分对应的概率差为0.7;(h)部分对应的概率差为0.8。可以发现,这些点大部分位于每类地物的边缘,也就是后向散射信息比较复杂的区域。随着概率差的值增大,重点像素的涵盖范围逐渐从地物边缘向地物内部扩展,有的甚至覆盖了整块区域。
为了通过比较获得最佳的概率差,在每种概率差下使用本发明进行了分类。实验数据的分类结果的总体分类精度如图4所示,当概率差为0.7时,总体分类精度达到最大值92.10%。
如图5所示,为实验数据中重点像素进行再次分类前后的类别图,可以发现部分像素的类别发生了变化。
根据实验数据的真实地物分布参考图,对再次分类前后,重点像素中的每种地物的分类正确性进行了统计,结果如表3所示。11种地物中,有10种地物的分类正确率得到提高。其中,wood的正确率提高幅度最小,有0.3%,soybean的正确率提高幅度最大,有38.29%,而water的正确率从88.89%降为了59.26%。从表3来看,实验数据中重点像素整体分类精度提高了20.77%,说明本发明在改善重点像素分类精度上是有效的。
表3当概率差为0.7时,实验数据中重点像素再次分类前后的每种地物的正确率
需要说明的是,表3中的平均提升精度,是将11种地物的提升精度取了一个平均,作为整体的精度提高程度。
4.2各种方法视觉效果的比较
利用相同的训练样本分别训练浅层分类器中的SVM,Wishart和Decision tree,深度学习中的CNN,以及以SVM、Wishart和Decision tree作为弱分类器的AdaBoost算法,然后获得相应的分类结果,与本发明的分类结果进行视觉效果上的对比。
如图6所示,分别为实验数据分别使用CNN,SVM,Wishart,decision tree,AdaBoost和本发明的分类结果。参照真实地物分布图,在每个分类结果上选择了4块椭圆形区域进行对比。可以发现CNN比SVM,Wishart,decision tree和AdaBoost的分类结果更纯净,斑点情况更少,但是分类结果更模糊,纹理有丢失,而本发明的结果的纹理比深度学习模型CNN更清晰,而斑点状分类情况又比这几个浅层分类器的分类结果有很大改善。
4.3各种方法分类精度的比较
以真实地物分布图作为参照,利用混淆矩阵,从整体精度、Kappa系数、生产者精度和用户精度4个方面分析了两个实验数据的分类结果。并将本发明的分类结果与CNN,SVM,Wishart,decision tree和AdaBoost的分类结果进行了比较。
实验数据的分类结果的整体精度和Kappa系数如表4所示。在精度方面,本发明的整体分类精度相对于其他5种分类方法有2.22至20.38个百分点的提高,Kappa系数有0.03至0.24的提高。
表4实验数据的总体精度和Kappa系数
如表5所示,为实验数据中每种地物在不同方法下分类结果的生产者精度,表格的最后一行为每种方法下所有地物的生产者精度的标准化差异(standardized difference,STD)。本发明下每类地物的生产者精度是对各种分类方法的生产者精度的最小值大,接近最大值甚至大于最大值。Bareland(裸地)在Decision tree(决策树)下的生产者精度最小,为0.00%,在Wishart下的生产者精度最大,为97.64%,在发明分类方法下生产者精度为84.66%。类似于bareland这样,在本发明下生产者精度大于最小值而又接近最大值的地物还有beet、grass、pea、potato、rape和water。lucerne、soybean、wheat和wood在本发明下生产者精度大于在其他方法下的生产者精度,比如lucerne在Decision tree下的生产者精度最小,为41.58%,在本发明下的生产者精度最大,为94.74%。标准化差异被用来判断每种方法下全部地物生产者精度的均衡性,值越小表示数据越均衡。从表5中的数据可以看到,6种分类方法的标准差,最大值为Decision tree的0.3112,最小值为AdaBoost的0.0557。本发明的标准差为0.0569,比最小值大0.0012。但相比较与AdaBoost,本发明下11类地物中的10类地物的生产者精度都有提高,仅仅只有bareland的生产者精度降低了8.69%。说明本发明的生产者精度是比较均衡的。因此,无论是局部还是整体,在生产者精度方面,本发明优于其他5种分类方法。
表5实验数据(PolSAR图像)的生产者精度
如表6所示,为实验数据中每种地物在不同方法下分类结果的用户精度,表格的最后一行为每种方法下所有地物的用户精度的标准化差异,The proposed method为本发明的方法。本发明下每类地物的用户精度是对各种分类方法的用户精度的最小值大,接近最大值甚至大于最大值。lucerne在CNN下的用户精度最小,为87.95%,在Decision tree下的用户精度最大,为98.29%,在本发明分类方法下用户精度为95.08%。类似于lucerne这样,在本发明下用户精度大于最小值而又接近最大值的地物还有pea、rape、water、wheat和wood。beet、grass、potato和soybean在本发明下用户精度大于在其他方法下的用户精度,比如beet在Wishart下的用户精度最小,为78.17%,在本发明下的用户精度最大,为92.95%。标准化差异被用来判断每种方法下全部地物用户精度的均衡性,值越小表示数据越均衡。从表6中的数据可以看到,6种分类方法的标准差,最大值为Decision tree的0.2852,最小值为SVM的0.0435。本发明的标准差为0.0482,比最小值大0.0047,非常接近最小值。但相比较与SVM,本发明下11类地物中的9类地物的用户精度都有提高,只有pea和rape的用户精度分别降低了1.47%和0.07%。因此,综合考虑,在用户精度方面,本发明优于其他5种分类方法。
表6第一张PolSAR图像的用户精度
实施例二
基于同样的发明构思,本实施例公开了结合深度学习模型和传统分类器的用于PolSAR数据的分类系统,包括:
初始分类模块,用于利用训练好的CNN模型对PolSAR数据进行分类;
重点像素筛选模块,用于将分类结果中容易被错误标记的像素作为重点像素,其他的像素作为一般像素,保留一般像素的类别标签;
再次分类模块,用于利用AdaBoost算法将SVM分类器、wishart分类器和决策树分类器组成一个强分类器对重点像素进行再次分类,得到重点像素的类别;
最终分类结果获取模块,用于将重点像素的类别和一般像素的类别组合作为PolSAR数据的最终分类结果。
由于本发明实施例二所介绍的系统为实施本发明实施例一中结合深度学习模型和传统分类器的用于PolSAR数据的分类方法所采用的系统,故而基于本发明实施例一所介绍的方法,本领域所属人员能够了解该系统的具体结构及变形,故而在此不再赘述。凡是本发明实施例一中方法所采用的系统都属于本发明所欲保护的范围。
实施例三
基于同一发明构思,本发明还提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被执行时实现如实施例一中所述的方法。
由于本发明实施例三所介绍的计算机可读存储介质为实施本发明实施例一中结合深度学习模型和传统分类器的用于PolSAR数据的分类方法所采用的计算机可读存储介质,故而基于本发明实施例一所介绍的方法,本领域所属人员能够了解该计算机可读存储介质的具体结构及变形,故而在此不再赘述。凡是本发明实施例一的方法所采用的计算机可读存储介质都属于本发明所欲保护的范围。
实施例四
基于同一发明构思,本申请还提供了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,处理器执行上述程序时实现实施例一中的方法。
由于本发明实施例四所介绍的计算机设备为实施本发明实施例一中结合深度学习模型和传统分类器的用于PolSAR数据的分类方法所采用的计算机设备,故而基于本发明实施例一所介绍的方法,本领域所属人员能够了解该计算机设备的具体结构及变形,故而在此不再赘述。凡是本发明实施例一中方法所采用的计算机设备都属于本发明所欲保护的范围。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。显然,本领域的技术人员可以对本发明实施例进行各种改动和变型而不脱离本发明实施例的精神和范围。这样,倘若本发明实施例的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。