与CD47和PD-L1特异性结合的双特异性抗体
文献发布时间:2024-04-18 19:58:53
技术领域
本发明涉及双特异性抗体。具体地,本发明涉及与CD47和PD-L1特异性结合的双特异性抗体、其用途和制备方法。
背景技术
体内的免疫功能通过抗原识别和与之同时发生的共刺激(co-stimulatory)和共抑制(co-inhibitory)的信号来调节。但是,癌细胞通过改变肿瘤微环境或抑制免疫功能来回避免疫攻击。这样的回避战略之一就是通过改变免疫检查点功能来抑制免疫细胞的功能。例如,癌细胞通过表达PD-L1或CD47之类的特定细胞表面蛋白使它们与T细胞或巨噬细胞之类的免疫细胞结合来抑制免疫细胞的功能。
随着上述机制的发现,通过阻断上述特定细胞表面蛋白之类的免疫检查点蛋白的活性来活化免疫细胞以攻击癌细胞的免疫检查点抑制剂的开发正活跃地进行着,作为PD-L1抑制剂的阿特珠单抗(Atezolizumab)、杜法鲁单抗(Durvalumab)、阿维鲁单抗(Avelumab)等多种抗-PD-L1单克隆抗体获得美国食品药品监督管理局(FDA)的认证在市面上出售或已进入临床阶段。并且,多种抗-CD47单克隆抗体也正在研究或已进入临床阶段。
然而,免疫检查点抑制剂具有患者反应率不充分或者具有副作用或低生物体利用率的问题,因此仍需要开发新的免疫检查点抑制剂。
发明内容
技术问题
本发明的目的在于解决上述所有问题。
本发明的一个目的在于,提供与CD47和PD-L1特异性结合的双特异性抗体。
本发明的再一个目的在于,提供与CD47和PD-L1特异性结合的双特异性抗体的用于预防或治疗癌症的用途。
本发明的还有一个目的在于,提供与CD47和PD-L1特异性结合的双特异性抗体的用来制备用于预防或治疗癌症的药剂的用途。
本发明的另一个目的在于,提供包含与CD47和PD-L1特异性结合的双特异性抗体的药物组合物。
本发明的又一个目的在于,提供预防或治疗癌症的方法,包括向对象施用与CD47和PD-L1特异性结合的双特异性抗体的步骤。
本发明的又一个目的在于,提供用于制备与CD47和PD-L1特异性结合的双特异性抗体的多核苷酸、表达载体、宿主细胞或方法。
本发明的目的不限于上述提及的目的。本发明的目的将通过以下说明得以进一步明确,并通过发明要求保护范围记载的手段及其组合来实现。
解决方案
用来实现上述目的的本发明的代表性结构如下。
根据本发明的一个实施方式,提供一种包含与CD47特异性结合的第一抗原结合结构域和与PD-L1特异性结合的第二抗原结合结构域的双特异性抗体,所述第一抗原结合结构域包含重链可变区与轻链可变区,所述重链可变区包含:包含SEQ ID NO:17的氨基酸序列的CDR1;包含SEQ ID NO:19的氨基酸序列的CDR2;和包含SEQ ID NO:21的氨基酸序列的CDR3,所述轻链可变区包含:包含SEQ ID NO:23的氨基酸序列的CDR1;包含SEQ ID NO:25的氨基酸序列的CDR2;和包含SEQ ID NO:27的氨基酸序列的CDR3,所述第二抗原结合结构域包含重链可变区与轻链可变区,所述重链可变区包含:包含SEQ ID NO:29的氨基酸序列的CDR1;包含SEQ ID NO:31的氨基酸序列的CDR2;和包含SEQ ID NO:33的氨基酸序列的CDR3,所述轻链可变区包含:包含SEQ ID NO:35的氨基酸序列的CDR1;包含SEQ ID NO:37的氨基酸序列的CDR2;和包含SEQ ID NO:39的氨基酸序列的CDR3。
根据特定实施方式,双特异性抗体包含:包含SEQ ID NO:1的重链可变区和SEQ IDNO:3的轻链可变区的第一抗原结合结构域;和包含SEQ ID NO:5的重链可变区和SEQ IDNO:7的轻链可变区的第二抗原结合结构域。
根据特定实施方式,双特异性抗体包含:Fc区域、包含与CD47特异性结合的抗原结合结构域的第一抗体片段(例如Fab片段);和包含与PD-L1特异性结合的抗原结合结构域的第二抗体片段(例如scFv片段)。
根据特定实施方式,在双特异性抗体中,第二抗体片段(例如scFv片段)通过肽接头融合于Fc区域的C-末端。
根据特定实施方式,双特异性抗体包含:Fc区域、包含与CD47特异性结合的抗原结合结构域的两个Fab片段;和包含与PD-L1特异性结合的抗原结合结构域的两个scFv片段。
根据特定实施方式,双特异性抗体包含含有与PD-L1特异性结合的抗原结合结构域的单链可变片段(scFv)。
根据特定实施方式,双特异性抗体包含含有与CD47特异性结合的抗原结合结构域的Fab片段。
根据特定实施方式,双特异性抗体包含源自IgG1的重链恒定区(CH)的Fc区域。
根据特定实施方式,双特异性抗体的Fc区域包含源自IgG1的重链恒定区CH1、CH2和CH3,CH3以SEQ ID NO:11为基准包含E239D和M241L的氨基酸取代。所述Fc区域通过作用于效应细胞(effector cell)来表现出免疫活化效果,尤其可以表现出增加的免疫活化效果。
根据特定实施方式,双特异性抗体包含含有与所述PD-L1特异性结合的抗原结合结构域的抗体片段,所述抗体片段通过肽接头与所述Fc区域的C-末端融合。
根据特定实施方式,双特异性抗体的单链可变片段(scFV)包含SEQ ID NO:9的氨基酸序列。
根据特定实施方式,双特异性抗体的Fc区域包含SEQ ID NO:11的氨基酸序列。
根据特定实施方式,双特异性抗体与表达PD-L1、CD47或者两者都表达的癌细胞特异性结合。
根据本发明的再一个实施方式,提供将本发明的双特异性抗体用于预防或治疗包括乳癌、肺癌、B-细胞诱导的淋巴瘤和T-细胞诱导的淋巴瘤在内的多种癌的用途。
根据本发明的还有一个实施方式,提供包含本发明的双特异性抗体的用于预防或治疗包括乳癌、肺癌、B-细胞诱导的淋巴瘤、T-细胞诱导的淋巴瘤在内的多种癌的药物组合物。
根据本发明的另一个实施方式,本发明的双特异性抗体可以与化学疗法、放射线疗法和/或其他免疫疗法并用。
根据本发明的又一个实施方式,提供预防或治疗包括乳癌、肺癌、B-细胞诱导的淋巴瘤和T-细胞诱导的淋巴瘤在内的多种癌的方法,包括向需要预防或治疗包括乳癌、肺癌、B-细胞诱导的淋巴瘤和T-细胞诱导的淋巴瘤在内的多种癌的对象施用有效量的本发明的双特异性抗体的步骤。
根据本发明的又一个实施方式,提供在对象中抑制肿瘤细胞生长的方法,包括向对象施用有效量的本发明的双特异性抗体的步骤。
根据本发明的又一个实施方式,提供编码本发明的双特异性抗体的多核苷酸。
根据本发明的又一个实施方式,提供包含编码本发明的双特异性抗体的多核苷酸的宿主细胞。
根据本发明的又一个实施方式,提供制备本发明的双特异性抗体的方法,包括:在适于所述双特异性抗体表达的条件下培养包含编码双特异性抗体的多核苷酸的宿主细胞的步骤;和从培养物中回收双特异性抗体的步骤。
发明效果
根据本发明,与CD47和/或PD-L1特异性结合的双特异性抗体可以有效用于预防或治疗包括乳癌、肺癌、B-细胞诱导的淋巴瘤、T-细胞诱导的淋巴瘤在内的多种癌。具体地,与抗-CD47抗体和/或抗-PD-L1抗体相比,本发明的双特异性抗体具有优秀的抗原结合能力,尤其在对CD47抗原具有异常突出的结合能力的同时保持对红细胞(RBC)的低结合能力。因此,确认本发明的双特异性抗体通过对表达CD47和/或PD-L1的肿瘤细胞具有高结合力来发挥优异的抗肿瘤效果,并且因与红细胞的低结合能力而表达出最小化的血凝副作用。并且,本发明的双特异性抗体通过抗体依赖性细胞毒性(ADCC,Antibody Dependent CellularCytotoxicity)活性评估在表达PD-L1和/或CD47的细胞中表现出癌症抑制效果和自然杀伤(NK)细胞和T细胞的活化效果。进而,本发明的双特异性抗体在利用缺失后天免疫细胞的BALB/c裸小鼠乳癌细胞株Xenograft模型与利用BALB/c-hPD-1/hSIRPα小鼠的大肠癌CT26-hPD-L1/hCD47细胞株Syngenic模型中证明具有癌细胞生长抑制效果,并且证明具有抑制因记忆T细胞的生成而引起的肿瘤复发的效果。因此,本发明的双特异性抗体可以通过癌细胞生长抑制效果和免疫细胞活化效果来有效用于预防、改善或治疗包括乳癌、肺癌、B-细胞诱导的淋巴瘤、T-细胞诱导的淋巴瘤在内的多种癌。
附图说明
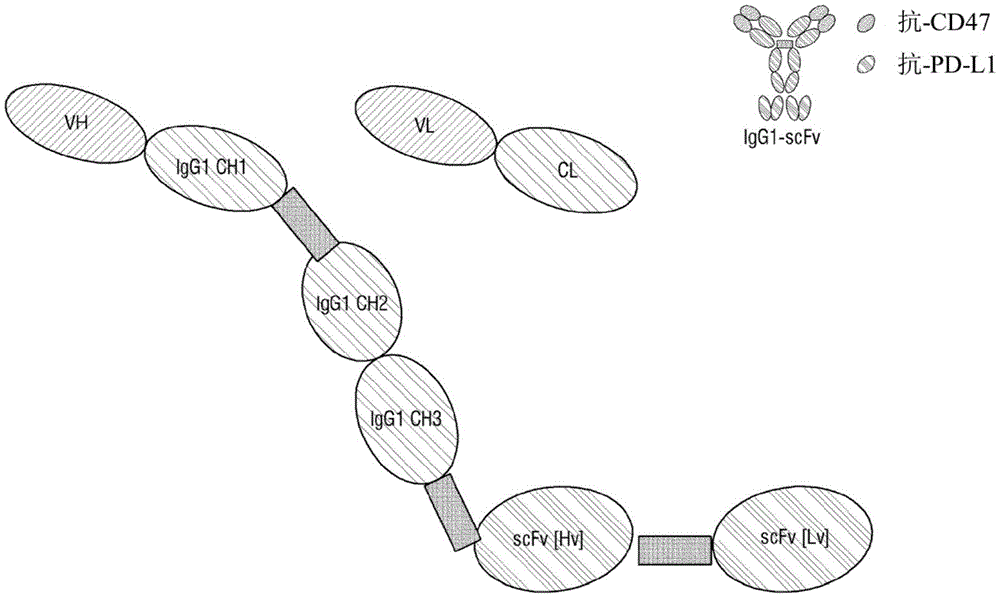
图1为示出本发明的针对CD47和PD-L1的双特异性抗体的简要示意图。
图2示出实施例1.2中制备的抗体在4%至20%变性、还原和非还原的聚丙烯酰胺凝胶电泳(SDS-PAGE)分析中的结果。分子量标记以千道尔顿表示。
图3示出用来观察实施例1.2中制备的抗体的分析用凝胶-过滤洗脱轮廓(色谱柱:Superdex 200increase 10/300GL;吸收波长:214nm;缓冲液:磷酸盐缓冲溶液(PBS);温度(℃):19;流量(ml/min):0.75;使用的SOP/WI:WIPP 24.0;批号:120520)。
图4a和图4b分别示出通过ELISA分析双特异性抗体针对CD47和PD-L1的单或双配体结合力的结果。
图5分别示出双特异性抗体对富含(enriched)PD-L1肿瘤细胞和富含CD47肿瘤细胞的结合力。
图6a至图6d分别示出双特异性抗体对MDA-MB-231的WT、PD-L1 KO、CD47KO和PD-L1/CD47双KO细胞的结合力。
图7示出对双特异性抗体进行红细胞结合检验的结果。
图8示出对双特异性抗体进行血凝(hemagglutination)检验的结果。
图9示出双特异性抗体对4种细胞(MDA-MB-231、H1975、Raji和SR786)的吞噬作用结果。
图10a和图10b示出分别在Raji细胞和MDA-MB-231细胞中对双特异性抗体进行(ADCC NFAT—Luc)测定的结果。
图11示出在MDA-MB-231细胞中对双特异性抗体进行自然杀伤细胞NK细胞的ADCC测定的结果。
图12示出为确认双特异性抗体的T细胞活化效果而进行混合淋巴细胞反应分析的结果。
图13示出在实施例3.1至实施例3.3中提和的小鼠的肿瘤接种部位。
图14为在移植人MDA-MB-231细胞株的BALB/c裸小鼠中确认双特异性抗体癌细胞生长抑制功效的研究结果。
图15为在CT26-hPD-L1/hCD47肿瘤同种移植BALB/c-hPD-1/hSIRPα小鼠中确认双特异性抗体的癌细胞生长抑制功效的研究结果。
图16示出与实施例3.3的复发研究相关的,在BALB/c-hPD-1/hSIRPα小鼠的CT26-hPD-L1/hCD47肿瘤同种移植模型的处理中的肿瘤体积曲线。数据以平均数±标准误(SEM)的方式示出。
具体实施方式
本发明的以下详细说明将参照特定附图来描述能够实施本发明的特定实例,但本发明不限定于这些实施例,恰当地说,本发明应由与权利要求主张的内容同等的所有范围通过随附的权利要求来限定。除非另有定义,否则本说明书使用的技术和学术术语具有本发明所属技术领域中通常使用的含义。出于解释本说明书的目的采用以下定义,在适当情况下,以单数使用的术语包括复数形式,反之亦可。
定义
本说明书中使用术语“抗原结合分子”使之与抗原决定因子特异性结合的分子。抗原结合分子的例包括抗体、抗体片段和抗原结合支架蛋白,但不限定于此。
术语“抗体”已非常广泛的含义来使用,包括多种抗体结构物,例如单克隆抗体、多克隆抗体、单特异性或多特异性抗体(例如双特异性抗体)、具有抗原结合活性的抗体片段和抗体融合体(例如抗体与(多)肽的融合体或抗体与化合物的融合体),但不限定于此。在本说明书中,词头“抗-”在与抗原相关的情况下,表示该抗体与该抗原具有反应性。与特定抗原具有反应性的抗体可以在噬菌体或类似的载体中通过重组抗体文库的筛选之类的合成和/或重组方法,或者通过使用抗原或抗原-编码核酸的动物的免疫化来生成,但不限定于此。代表性的IgG抗体是由通过二硫键结合的两个相同的重链和两个相同的轻链构成的。各个重链和轻链包含恒定区和可变区。重链可变区(HVR)和轻链可变区(LVR)分别包含称为“互补决定区(CDR)”或“超变区”的三个片段,这些主要有关于与抗原表位的结合。这些从N-末端依次标上数字称为CDR1、CDR2和CDR3。在CDR外部的可变区中,保存得更为完好的区域称为“骨架区(FR)”。在本说明书中,抗体可以为例如动物抗体、嵌合体抗体、人源化抗体或人抗体。
术语“单克隆抗体”是指从实质上同种的抗体集团中获得的抗体。即,所述集团所包含的个体抗体,除微量存在的可能的变异抗体(例如,在制备单克隆抗体时出现的具有天然发生的突变的抗体)以外,彼此相同或相同的表位结合。与典型的包含对不同的决定因子(表位)诱导的不同的抗体的多克隆抗体制剂相比,单克隆抗体制剂的各单克隆抗体只对抗原上的单个决定因子诱导。
术语“单特异性”抗体是指各结合部位具有与相同的抗原的相同表位结合一个以上的结合部位的抗体。术语“双特异性”是指抗原结合分子能够与两个以上的不同抗原决定因子特异性结合。通常,双特异性抗原结合分子包含两个抗原结合部位,它们分别对不同的抗原决定因子具有特异性。在一部分实例中,双特异性抗原结合分子可以同时与两个抗原决定因子,例如同时与两个不同细胞上表达的两个抗原决定因子结合。并且,本申请中记载的双特异性抗原结合分子可以形成多特异性抗体的一部分。
术语“抗体片段”是指具有对抗原的特异性结合能力的抗体的一部分或包含其的多肽。抗体片段的包括例如Fv、Fab、Fab'、Fab'-SH、F(ab')2、双体、三体、四体、交叉-Fab片段、线型抗体、单链抗体分子(例如scFv)、由抗体片段与单结构域抗体形成的多特异性抗体,但不限定于此。
术语“单链可变片段”或“scFv”是指免疫球蛋白的重链(VH)和轻链(VL)的可变区通过共价键合形成VH-VL异二聚体的融合蛋白。所述重链(VH)与轻链(VL)直接连接,或者通过连接重链的N-末端与轻链的C-末端或连接重链的C-末端与轻链的N-末端的肽接头来连接。
术语“抗原结合结构域”是指与抗原决定因子特异性结合的抗原结合分子的部分。抗原结合结构域可以通过例如一个以上的可变区来提供。优选地,抗原结合结构域可以包含抗体轻链可变区和抗体重链可变区。
术语“Fc区域”表示免疫球蛋白的重链的C-末端区域,是指各链中由铰链区的一部分、CH2和CH3结构域形成的同种型二聚体。Fc区域表示通过使用木瓜蛋白酶的消化来生产的无损抗体(例如IgG的一部分)。在一个实例中,“Fc区域”可以为天然序列Fc区域或变体Fc区域。“天然序列Fc区域”表示与通常在自然中发现的Fc区域的氨基酸序列相同的氨基酸序列。在本发明中,Fc区域只要具有与天然型实质上相同的效果或提高的效果,可以为只排除免疫球蛋白的重链与轻链可变区而包含一部分或全部重链恒定区1(CH1)和/或轻链恒定区1(CL1)的扩张的Fc区域。并且,也可以为排除相当于CH2和/或CH3的相当长的一部分氨基酸序列的区域。例如,在本发明中,Fc区域可以为1)CH1、CH2和CH3;2)CH1和CH2;3)CH1和CH3;4)CH2和CH3;5)CH1至CH3中一个或两个或更多个的结构域与免疫球蛋白铰链区(铰链区的一部分)的组合;或者6)重链恒定区的各结构域与轻链恒定区的二聚体。并且,在本发明中,Fc区域不仅包括天然型氨基酸序列,还包括该序列的变体。氨基酸序列变体是指天然氨基酸序列中的一个以上的氨基酸残基通过缺失、插入、非保守或保守性取代或者它们的组合来具有不同的序列的含义。
术语“CD47”已知为存在于癌细胞表面的蛋白质,是指已知为通过与巨噬细胞的SIRPα结合发出“不要吃我(Do-not-eat-me)”信号来阻断巨噬细胞的吞噬作用的蛋白质。
术语“PD-L1”已知为存在于癌细胞表面的蛋白质,是指通过与T细胞表面的蛋白质PD-1结合来使T细胞无法攻击癌细胞的蛋白质。
术语“接头”可以指具有1个至100个,具体地,具有2个至50个,更具体地,具有5个至30个氨基酸长度的肽接头。所述接头可以包含例如选自由Gly、Asn、Ser、Thr、Ala、Asp等组成的组中的一种以上的氨基酸,但不限定于此。作为例子,所述接头可以由(GGGGS)n来表示,n为(GGGGS)单元的重复次数,考虑到双特异性抗体的功效,n可以为1至10,具体地,可以为1至5。再举个例子,所述接头可以为已知能够连接抗体片段结构域的肽片段,例如,可以具有GGGGSGGGGSGGGGS的氨基酸序列。
术语“多核苷酸”、“寡核苷酸”、“核酸”可以相互替换来使用,包括脱氧核糖核酸(DNA)分子(例如,互补脱氧核糖核酸(cDNA)或基因组脱氧核糖核酸)、核糖核酸(RNA)分子(例如信使核糖核酸(mRNA))、利用核酸类似物生成的脱氧核糖核酸或核糖核酸类似物(例如,肽核酸和非自然生成的核酸类似物)和它们的杂交物。核酸分子可以为单链或双链。在一个实例中,本发明的核酸分子包括编码抗体或其片段、衍生物、突变体或变体的连续开放读码框。
术语“对象”可以与“患者”交换来使用,可以为需要预防或治疗癌症的哺乳动物,例如灵长类(例如人)、宠物(例如狗、猫)、家畜(例如牛、猪、马、羊、山羊等)和实验动物(例如大鼠、小鼠、豚鼠等)。本发明的在一个实例中,对象为人。
术语“治疗”通常是指获得所预期的药理学效果和/或生理学效果。所述效果在部分或完全治愈疾病和/或由所述疾病引起的副作用方面具有治疗效果。优选的治疗效果包括疾病发生或复发的防止、症状的好转、疾病的任意直接或间接的病理学结果的缩小、转移的防止、疾病进展速度的减小、疾病状态的好转或缓解和好转或改善的预后,但不限定于此。优选地,“治疗”可以指对已经存在的疾病或障碍的治疗性介入。
术语“预防”是指获得预防性治疗,即,比起治疗疾病,更倾向于预防的效果。从部分或完全预防疾病或其症状的方面来说,“预防”是指获得所预期的预防性的药理学效果和/或生理学效果。
术语“施用”是指向对象提供达到预防或治疗目的的物质(例如本发明的双特异性抗体)。
本发明的双特异性抗体
本发明提供包含与CD47特异性结合第一抗原结合结构域和与PD-L1特异性结合的第二抗原结合结构域的新型双特异性抗体。所述抗体可以与表达CD47、PD-L1或者二者都表达的癌细胞特异性结合,具有结合亲和力、生物学活性、免疫细胞活化、靶化功效、抑制肿瘤复发的能力和减少的副作用之类的特别有利的特征。
根据本发明的一实施方式,提供一种包含与CD47特异性结合第一抗原结合结构域和与PD-L1特异性结合的第二抗原结合结构域的双特异性抗体,所述第一抗原结合结构域包含重链可变区与轻链可变区,所述重链可变区包含:包含SEQ ID NO:17的氨基酸序列的CDR1;包含SEQ ID NO:19的氨基酸序列的CDR2;和包含SEQ ID NO:21的氨基酸序列的CDR3,所述轻链可变区包含:包含SEQ ID NO:23的氨基酸序列的CDR1;包含SEQ ID NO:25的氨基酸序列的CDR2;和包含SEQ ID NO:27的氨基酸序列的CDR3,所述第二抗原结合结构域包含重链可变区与轻链可变区,所述重链可变区包含:包含SEQ ID NO:29的氨基酸序列的CDR1;包含SEQ ID NO:31的氨基酸序列的CDR2;和包含SEQ ID NO:33的氨基酸序列的CDR3,所述轻链可变区包含:包含SEQ ID NO:35的氨基酸序列的CDR1;包含SEQ ID NO:37的氨基酸序列的CDR2;和包含SEQ ID NO:39的氨基酸序列的CDR3。
在一部分实例中,与CD47特异性结合的第一抗原结合结构域可以包含SEQ ID NO:1的重链可变区和SEQ ID NO:3的轻链可变区,和/或与PD-L1特异性结合的第二抗原结合结构域可以包含SEQ ID NO:5的重链可变区和SEQ ID NO:7的轻链可变区。尤其,与PD-L1特异性结合的第二抗原结合结构域可以包含SEQ ID NO:9的单链可变片段(scFv)。
在一部分实例中,本发明的双特异性抗体可以包含:Fc区域;包含与所述CD47特异性结合的抗原结合结构域的第一抗体片段;和包含与所述PD-L1特异性结合的抗原结合结构域的第二抗体片段。
在一部分实例中,所述第一抗体片段可以为Fab片段。
在一部分实例中,所述第二抗体片段可以为单链可变片段(scFv)。
在一部分实例中,所述Fc区域可以通过作用于效应细胞(effector cell)来表现出免疫活化效果。优选地,所述Fc区域可以源自IgG1的重链恒定区(CH)。更优选地,所述Fc区域可以包含源自IgG1的重链恒定区CH1、CH2和CH3或者源自IgG1的重链恒定区CH2和CH3。最优选地,所述Fc区域的CH3能够以SEQ ID NO:11为基准包含E239D和M241L的氨基酸取代。
在一部分实例中,所述Fc区域可以包含SEQ ID NO:11的氨基酸序列。
在一部分实例中,所述第二抗体片段可以融合于所述Fc区域的C-末端。更具体地,所述第二抗体片段可以通过重链可变区(即,第二抗体片段的N-末端)融合于Fc区域的C-末端(参照图1)。在此情况下,第二抗体片段可以通过接头融合于Fc区域的C-末端。所述接头可以为肽接头,可以具有例如GGGGS、GGGGSGGGGSGGGGS或GSGSGSGSGSGSGSGSGS的氨基酸序列。
在一部分实例中,所述第二抗体片段的所述第二结构域可以包含重链可变区与轻链可变区通过接头连接的可变区(例如,单链可变片段scFv)。作为一例,所述接头可以为由(GGGGS)n表示的肽接头,所述n为(GGGGS)单元重复的次数,考虑到双特异性抗体的功效,n可以为1至10,具体地,可以为1至5。优选地,所述第二抗体片段可以为scFv片段。更优选地,所述scFv片段可以包含SEQ ID NO:9的氨基酸序列。
在一部分实例中,本发明的双特异性抗体可以包含:Fc区域、包含与CD47特异性结合的抗原结合结构域的两个Fab片段;和包含与PD-L1特异性结合的抗原结合结构域的两个scFv片段。在此情况下,各scFv片段的重链可变结构域可以通过肽接头融合于(连接于各Fab片段的重链的)Fc区域的C-末端。
在一部分实例中,本发明的双特异性抗体包含与CD47特异性结合且含有两个抗体重链和两个抗体轻链的全长抗体和含有与PD-L1特异性结合的重链可变区和轻链可变区的抗体片段(例如scFv片段),所述抗体片段的重链可变区可以直接或通过肽接头融合于所述全长抗体的重链的C-末端。
在一部分实例中,本发明的双特异性抗体可以包含与所述CDR序列、重链可变区序列和/或轻链可变区序列具有80%以上的序列同源性,优选地,具有90%以上的序列同源性,更优选地,具有95%以上的序列同源性,最优选地,具有98%以上的序列同源性的序列。
在特定实例中,可以考虑本发明双特异性抗体的氨基酸序列变体。例如,能够以改善抗体的结合亲和力和/或其他生物学特性为佳。抗体的氨基酸序列变体可以通过向编码分子的核苷酸序列内导入适当的变形或者通过肽合成来制备。所述变形包括例如所述抗体的氨基酸序列的残基的缺失和/或向所述氨基酸序列内插入残基和/或在所述氨基酸序列内的残基的取代。可以通过进行包括缺失、插入和取代在内的多种变更的任意组合来达成最终的结构物,但最终结构物应保有所希望的特性,例如抗原-结合特性。与用于取代突变诱发相关的部位包括重链可变区(HVR)和骨架区(FR)。保守性取代在表1的“优选取代”项下提供,以下,进一步描述关于氨基酸侧链种类(1)至(6)的内容。可以将氨基酸取代引入所关心的分子和筛选的产物中以获得所希望的活性,例如,根据保持/改善的抗原结合、减少的免疫原性,或者改善的ADCC或CDC。
表1
氨基酸可以根据通常的侧链性质进行如下分组:(1)疏水性:正亮氨酸、Met、Ala、Val、Leu、Ile;(2)中性亲水性:Cys、Ser、Thr、Asn、Gln;(3)酸性:Asp、Glu;(4)碱性:His、Lys、Arg;(5)给链的方向带来影响的残基:Gly、Pro;(6)芳香族:Trp、Tyr、Phe。
非保守性取代可以伴随以所述种类中的一种被其他种类取代。
在本说明书中,术语“氨基酸序列变体”包括母本抗体结合分子(例如,人源化或人抗体)的一个以上的超变区残基存在氨基酸取代的实质上的变体。通常,为追加研究而选择生成的变体与母抗原结合分子相比,具有特定的生物学特性的变形,例如改善(例如增加的亲和力、减少的免疫原性)和/或实质上保持抗原结合分子的特定生物学特性。示例性取代变体为亲和力成熟抗体,可以通过例如本发明所属技术领域中公知的基于噬菌体展示的亲和力成熟方法来方便地生成。简单来说,一个以上的重链可变区残基突变,变体抗原结合分子在噬菌体上展示来筛选特定生物活性(例如结合亲和力)。在特定实例中,取代、插入或缺失能够以所述变更不实质上减少与抗原结合的抗原结合分子的能力的方式在一个以上的重链可变区内发生。例如,可以在重链可变区中实现不实质上减少结合亲和力的保守性变更(例如本说明书中提供的保守性取代)。
氨基酸序列插入不仅包括向序列内插入单个或多个氨基酸残基,还可以包括从包含一个残基到一百个残基以上的多肽范围内的氨基-末端和/或羧基-末端融合。末端插入的例包括具有N-末端甲硫氨酸残基的抗体。分子的其他插入变体可以包括增加抗体的血清半衰期的与多肽的N-末端或C-末端的融合。并且,分子的其他插入变体还可以包括用来易于通过血脑屏障(blood-brain barrier,BBB)的多肽的N-末端或C-末端的融合。
核酸、载体、宿主细胞和制备方法
可以通过本发明所属技术领域已知的任意抗体生成技术来制备本发明的双特异性抗体。
根据本发明的再一实施方式,本发明提供编码本发明中描述的双特异性抗体或其片段的分离核酸(例如多核苷酸)。所述核酸可以编码包含所述双特异性抗体的重链可变区或重链CDR区域的氨基酸序列和/或包含轻链可变区或轻链CDR区域的氨基酸序列。
在一部分实例中,本发明的双特异性抗体可以通过编码整个抗原结合分子的单个多核苷酸或共表达的多个多核苷酸来表达。通过多个多核苷酸编码的多肽可以通过例如二硫键合或形成功能性抗原结合分子的其他手段来结合。例如,免疫球蛋白的轻链部分可以通过从免疫球蛋白的重链部分分离出来的多核苷酸来编码。在共表达的情况下,所述重链多肽与用于形成免疫球蛋白的轻链多肽结合。
在一个实例中,所述多核苷酸可以包含SEQ ID NO:2的序列和SEQ ID NO:5的序列。并且,所述多核苷酸序列可以包含SEQ ID NO:12的序列。
在再一个实例中,所述多核苷酸可以包含SEQ ID NO:6的序列和SEQ ID NO:8的序列。并且,所述多核苷酸序列可以包含SEQ ID NO:10的序列。
在还有一个实例中,所述多核苷酸可以为SEQ ID NO:15的序列和/或SEQ ID NO:16的序列或者包含所述序列。
在另一个实例中,所述多核苷酸可以包含与编码本发明的双特异性抗体多核苷酸具有至少约70%、至少约75%、至少约80%、至少约85%、至少约90%、至少约95%、至少约98%或约100%的同源性的核酸序列。
在又一个实例中,所述多核苷酸可以编码本发明双特异性抗体所包含的多肽。
根据本发明的又一实施方式,本发明提供包含所述核酸中的一个以上的载体(例如表达载体)。术语“载体”为可以用于将连接于核酸的另一核酸导入细胞的核酸。载体的一种类型为指称能够结扎追加核酸片段的线型或环型双链脱氧核糖核酸分子的“质粒”。另一类型的载体为病毒载体(例如不可复制的逆转录病毒、腺病毒和腺相关病毒),在此情况下,可以将追加的脱氧核糖核酸片段导入病毒基因组。特定载体可以在它们导入的宿主细胞内自我复制(例如包含细菌复制起点的细菌载体和附加体哺乳动物载体)。其他载体(例如非附加体哺乳动物载体)在导入宿主细胞时与宿主细胞整合,与所述宿主的基因组一同复制。“表达载体”为能够诱导选择的多核苷酸的表达的载体的一种类型。
根据本发明的又一实施方式,本发明提供包含一种以上的编码本发明的双特异性抗体的多核苷酸的宿主细胞。所述宿主细胞可以为原核或真核细胞。例如,所述宿主细胞中国仓鼠卵巢(CHO)细胞或淋巴细胞。在不需要糖化等的情况下,可以在细菌中制备抗体。
根据本发明的又一实施方式,本发明提供制备本发明双特异性抗体的方法,包括:在适合表达本发明的双特异性抗体的条件下培养所述宿主细胞的步骤;和从培养物中回收双特异性抗体的步骤。
为了双特异性抗体的重组生产,例如,可以在分离所述编码双特异性抗体的多核苷酸后,插入一个以上的载体内来在宿主细胞内追加克隆和/或在宿主细胞内部表达。所述核酸可以通过本发明所属技术领域中通常的过程进行分离或测序。
培养所述转化的细胞的方法可以利用本发明所属技术领域中广为人知的方法来进行。例如,可以通过在培养基中培养所述转化体来大量生产双特异性抗体,可以根据宿主细胞来适当选择常用的培养基和培养条件。培养时为了适合细胞的生育和蛋白质的大量生产,可以适当调节温度、培养基的pH和培养时间等条件。
为了回收所述双特异性抗体,为了免疫球蛋白的纯化,可以使用本发明所属技术领域中公知的任意方法,例如色谱法(离子交换、亲和性(例如蛋白A(protein A))、尺寸排除等)、离心分离、梯度溶解度或者用于蛋白质纯化的其他标准技术。
预防或治疗方法
根据本发明的又一实施方式,可以在预防或治疗方法中使用本发明的双特异性抗体。
在一部分实例中,治疗的疾病为增殖性障碍,尤其可以是癌症。尤其,本发明的双特异性抗体可以用于抑制癌症的增殖、存活、转移和复发。
在一部分实例中,提供在对象中抑制肿瘤细胞生长的方法,包括向具有肿瘤细胞的对象施用有效量的本发明的双特异性抗体的步骤。在一部分实例中,提供用于预防或治疗癌症的方法,包括向需要预防或治疗癌症的对象施用有效量的本发明的双特异性抗体的步骤。
在一部分实例中,所述癌症可以为实体癌或血液癌。
在一部分实例中,所述癌症可以选自由卵巢癌、结肠癌、大肠癌、乳癌、肺癌、骨髓瘤、神经母细胞-诱导的中枢神经系统肿瘤、单核细胞白血病、B-细胞诱导的白血病、T-细胞诱导的白血病、B-细胞诱导的淋巴瘤、T-细胞诱导的淋巴瘤和肥大细胞诱导的肿瘤组成的组中,但不限定于此。优选地,所述癌症可以为选自由卵巢癌、肺癌、B-细胞诱导的淋巴瘤和T-细胞诱导的淋巴瘤组成的组中的任一种。
本发明的双特异性抗体可以根据是否希望进行局部或全身治疗和治疗的区域来以多种方式施用。向对象施用双特异性抗体的方法可根据给要目的、发病部位、对象的状态等的不同而不同。施用途径可以为胃肠外、吸入、外用或局部施用(例如病变内施用)。例如,胃肠外施用可以包括静脉内、皮下、腹腔内、肺内、动脉内、肌肉内、直肠、阴道内、关节内、前列腺内、鼻内、眼球内、膀胱内、脊髓腔内施用或心室内施用(例如脑室内施用),但不限定于此。并且,在并用的情况下,本发明的双特异性抗体可以与追加免疫抗癌剂以相同的途径或不同的途径施用。
在所述方法中,本发明双特异性抗体的有效量可以根据个体(患者)的年龄、性别、体重的不同而不同,每kg体重施用约0.01mg至100mg或5mg至约50mg,可以一天施用一次至分为数次施用。但有效量可以根据施用途径和期间、疾病的严重程度、性别、体重、年龄等进行增减,本发明的范围不限定于此。
在一部分实例中,本发明的双特异性抗体可以与抗癌化疗剂、放射线治疗和/或其他免疫抗癌剂(例如抗PD-1、抗CTLA-4抗体等)一同使用或联合施用。所述并用治疗法包括联合施用(两种以上的治疗性制剂包含于同一或单独组合物中的施用)和单独施用,在这种情况下,双特异性抗体的施用可以在追加治疗剂/治疗法的施用/使用之前、同时和/或依次进行。
药物组合物
根据本发明的又一实施方式,本发明提供包含本发明的双特异性抗体的药物组合物。组合物能够以预防性或治疗性有效量包含所述双特异性抗体。
在一部分实例中,可以为抑制癌症的增殖、存活、转移和复发而向对象施用所述药物组合物。因此,可以为预防或治疗癌症而向对象施用所述药物组合物。在此情况下,所述药物组合物可以与抗癌化疗剂、放射线治疗和/或其他免疫抗癌剂(例如抗PD-1、抗CTLA-4抗体等)一同使用或联合施用。所述并用治疗法包括联合施用(两种以上的治疗性制剂包含于同一或单独组合物中的施用)和单独施用,在这种情况下,双特异性抗体的施用可以在追加治疗剂/治疗法的施用/使用之前、同时和/或依次进行。
在一部分实例中,所述癌症可以为实体癌或血液癌。
在一部分实例中,所述癌症可以选自由卵巢癌、结肠癌、大肠癌、乳癌、肺癌、骨髓瘤、神经母细胞-诱导的中枢神经系统肿瘤、单核细胞白血病、B-细胞诱导的白血病、T-细胞诱导的白血病、B-细胞诱导的淋巴瘤、T-细胞诱导的淋巴瘤和肥大细胞诱导的肿瘤组成的组中,但不限定于此。优选地,所述癌症可以为选自由卵巢癌、肺癌、B-细胞诱导的淋巴瘤和T-细胞诱导的淋巴瘤组成的组中的任一种。
为了制备本发明的药物组合物,本发明的双特异性抗体可以与制药上可接受的载体和/或赋形剂混合。药物组合物可以制备为冷冻干燥制剂或水性溶液的形态。例如,可以参照文献[Remington's Pharmaceutical Sciences and U.S.Pharmacopeia:NationalFormulary,Mack Publishing Company,Easton,PA(1984)]。
可接受的载体和/或赋形剂(包括稳定剂)应在所使用的剂量和浓度方面对对象无毒性,可以包括:缓冲液(例如磷酸、柠檬酸或其他有机酸);抗氧化剂(例如抗坏血酸或甲硫氨酸);防腐剂(例如十八烷基二甲基苄基氯化铵;氯化六甲双铵;苯扎氯铵、苄索氯铵;苯酚、丁醇或苯甲醇;对羟基苯甲酸烷基酯,例如对羟基苯甲酸甲酯或对羟基苯甲酸丙酯;邻苯二酚;间苯二酚;环己醇;3-戊醇;和间甲酚);低分子量(约10以下的残基)多肽;蛋白质(例如血清白蛋白、明胶或免疫球蛋白);亲水性聚合物(例如聚乙烯吡咯烷酮);氨基酸(例如离氨酸、谷胺酰胺、天冬氨酸、组氨酸、精氨酸或离氨酸);单糖类、二糖类和其他碳水化合物,例如葡萄糖、甘露糖或糊精;螯合剂(例如乙二胺四乙酸(EDTA));糖(例如蔗糖、甘露醇、海藻糖或山梨糖醇);盐形成反离子(例如钠);金属络合物(例如Zn-蛋白质络合物);和(或者)非离子类表面活性剂(例如TWEEN(注册商标)、PLURONICS(注册商标)或聚乙二醇(PEG)),但不限定于此。
本发明的药物组合物可以根据施用途径配制为本发明所属技术领域公知的适当形态。
在本说明书中,术语“预防性或治疗性有效量”或“有效量”为预防和治疗对象的癌症时有效的组合物的有效成分的量,是指医学处置上可能起作用的以合理的收益/风险比例预防或治疗癌症的充分且不引起副作用的量。所述有效量的水平可以根据包括患者的健康状态、疾病的种类、疾病的严重程度、药物的活性、对药物的敏感度、施用方法、施用时间、施用途径和代谢比例、治疗期间、配合或同时使用的药物在内的因素和其他医学领域中熟知的因素来决定。在此情况下,在考虑上述所有因素后能够以副作用最小或无副作用的最小的量来获得最大的效果的量是至关重要的,这可以通过普通的技术人员轻易做出决定。
具体地,在本发明的药物组合物中,有效成分的有效量可以根据个体(患者)的年龄、性别、体重的不同而不同,通常,每kg体重施用约0.0001mg至100mg、0.001mg至50mg或5mg至约50mg,可以一天施用一次至分为数次施用。但有效量可以根据施用途径和期间、疾病的严重程度、性别、体重、年龄等进行增减,本发明的范围不限定于此。
下文中,通过以下实施例更为详细地说明本发明。以下实施例仅为帮助理解本发明而提出,无论何种方式,都不出于限制本发明的目的,不应解释为限定本发明。
实施例1.制备针对CD47和PD-L1的双特异性抗体
实施例1.1.制备用于制备针对CD47和PD-L1的双特异性抗体的序列和包含其的载体
为了制备具有如图1所示结构的抗体,依靠Fusion Antibodies plc.(位于北爱尔兰贝尔法斯特)制备分别含有这样的抗体的重链的核苷酸序列(SEQ ID NO:15)和轻链的核苷酸序列(SEQ ID NO:16)的载体。
实施例1.2.生产和纯化针对CD47和PD-L1的双特异性抗体
在中国仓鼠卵巢细胞株中进行实施例1.1中制备的载体的瞬时转染。分批培养后,从细胞培养上清液中纯化表达的抗体。然后,为了确认是否满足如以下表2所示的指定标准,对纯化的抗体完成质量控制(QC)分析。
表2
有关上述转染、纯化和质量控制分析的具体步骤如下。在作为哺乳动物瞬时表达质粒的pETE V2(融合抗体(Fusion antibodies))中克隆实施例1.1中制备的载体。使用基于中国仓鼠卵巢的瞬时表达系统表达抗体后,对生成的包含抗体的细胞培养上清液进行离心分离和过滤来纯化。通过亲和色谱法从细胞培养上清液中纯化抗体(使用最新的AKTA色谱法设备)。将纯化的抗体在磷酸盐缓冲溶液内进行缓冲液更换。通过还原和变性十二烷基硫酸钠聚丙烯酰胺凝胶判断,确认抗体的纯度>95%(图2)。在图2中,各泳道如以下表3所示。
表3
通过尺寸排阻色谱法(SEC)分析抗体来获得色谱(图3)。色谱表现出一个主要波峰(总面积超过95%)。有关图3所示的色谱的积分结果如以下表4所示(以对照蛋白质的滞留体积(数据未显示)为基准)。与单体部分相应的波峰为>98%。
表4
使用
表5
通过表5可知,所希望的抗体以满足指定标准的程度成功地表达并纯化。以下,这样制备的与CD47和PD-L1特异性结合的双特异性抗体也称为“IMC-201”。
如上制备的抗体具有如下的重链和轻链可变区和CDR序列。Fc区域具有SEQ IDNO:11的氨基酸序列(参照序列表)。
表6
/>
制备例1.制备抗-PD-L1单克隆抗体和抗-CD47单克隆抗体
本制备例中制备的单克隆抗体是指不包含内在性污染物质的同种重组多肽。
首先,为了制备抗-PD-L1单克隆抗体,使用了美国专利第10118963号的可变区序列(SEQ ID NO:1和SEQ ID NO:2)。通过连接人IgG1恒定区序列完成轻链和重链抗体序列后,使用本发明所属技术领域中公知的任意的表达系统制备上述抗体。具体地,对在中国仓鼠卵巢(CHO)细胞株中使用包含编码抗体的核酸的重组表达载体通过瞬时表达从宿主细胞中回收的上清液进行蛋白A纯化来制备上述抗体。
然后,为了制备抗-CD47单克隆抗体而使用了美国专利第10035855号公开的可变区序列(SEQ ID NO:22和SEQ ID NO:8)。通过连接人IgG4恒定区序列完成轻链和重链抗体序列后,使用本发明所属技术领域中公知的任意的表达系统制备上述抗体。具体地,对在中国仓鼠卵巢(CHO)细胞株中使用包含编码抗体的核酸的重组表达载体通过瞬时表达从宿主细胞中回收的上清液进行蛋白A纯化来制备上述抗体。
以下,将如上制备的抗-PD-L1单克隆抗体和抗-CD47单克隆抗体分别称为“IMC-001”和“IMC-002”。
实施例2.评估IMC-201的抗原结合能力和活性(体外(in vitro))
实施例2.1.通过酶联免疫吸附测定(ELISA)确认配体结合能力
首先,以如下方式通过ELISA检测IMC-201的单配体(PD-L1)结合力。连续稀释(0.01ng/ml至600ng/ml,3倍稀释)IMC-201和IMC-001后,与事先以75ng/孔的浓度包被于培养板的人PD-L1一同培养。在IMC-201和IMC-001的检测中使用辣根过氧化物酶(HRP)-缀合抗人IgG Fcγ片段特异性抗体(Peroxidase AffiniPure Goat Anti-Human IgG,Fcγfragment specific(#109-035-098),Jackson IR Lab公司)。
然后,通过ELISA检测IMC-201的单配体(CD47)结合力。连续稀释(0.01ng/ml至600ng/ml,3倍稀释)IMC-201和IMC-001后,与事先以50ng/孔的浓度包被于培养板的人CD47一同培养。在IMC-201和IMC-001的检测中使用辣根过氧化物酶-缀合抗人IgG Fcγ片段特异性抗体。
然后,以如下方式通过ELISA检测IMC-201的双配体(PD-L1与CD47)同时结合力。连续稀释(0.09ng/ml至1800ng/ml,3倍稀释)IMC-201、IMC-001和IMC-002后,分别以100μL的量与事先以50ng/孔的浓度包被于培养板的重组人CD47-fc一同培养。洗涤后以50ng/孔的浓度与重组人PD-L1-his一同培养后,在IMC-201、IMC-001和IMC-002的检测中使用辣根过氧化物酶-缀合抗人his片段特异性抗体。
结果,作为PD-L1单克隆抗体的IMC-001的EC
实施例2.2.确认对肿瘤细胞的结合能力
通过如下方式测量IMC-201对肿瘤细胞的细胞结合能力。
在4℃的温度下,将PD-L1表达高的H1975细胞株(ATCC#CRL-5908)和CD47表达高的Jurkat细胞株(ATCC#TIB-152)分别与3倍稀释的IMC-201、IMC-001和IMC-002一同培养1小时后,通过流式细胞分析(BD#LSRFortessa X-20)测量它们的结合强度。
结果与ELISA的结果不同,确认到与IMC-001和IMC-002相比,IMC-201对细胞的结合力更有优势(图5)。
实施例2.3.确认对敲除(KO)细胞株的结合能力
通过如下方式测量IMC-201对敲除稳定细胞株的细胞结合力。
在4℃的温度下,将利用MDA-MB-231(ATCC#HTB-26)和CRISPR-Cas9敲除获得的PD-L1(Sigma公司)KO、CD47(Sigma公司)KO和PD-L1和CD47双KO细胞分别与3倍稀释的IMC-201、IMC-001和IMC-002一同培养1小时。通过流式细胞分析测量结合强度。
结果,在CD47KO细胞中检测到IMC-201的结合能力与作为母本抗体的IMC-001相似,但在PD-L1KO细胞中检测到IMC-201的结合能力显著高于作为母本抗体的IMC-002。作为结论,如上述实施例2.2中确认的,与IMC-001和IMC-002相比,IMC-201对肿瘤细胞的结合力更有优势,其原因可以确认是由于IMC-201具有比对CD47的单克隆抗体高出很多的对CD47的结合力(图6a至图6d)。
实施例2.4.检验红细胞结合能力
通过如下方式测量IMC-201对人红细胞的细胞表面结合。在此情况下,将作为抗-CD47抗体的IMC-002和Hu5F9(根据文献[Liu J,et al.Pre-clinical development of ahumanized anti-CD47 antibody with anti-cancer therapeutic potential.PLoSOne.2015;10(9):e0137345]制备)用作比较抗体。
将从健康的供体(n=3)获得的人红细胞(5×10
结果,作为比较抗体的Hu5F9表现出高的红细胞结合力,与之相反,IMC-201几乎未表现出红细胞结合力,这与作为同种型对照和单克隆抗体的IMC-002没有差异。因此,确认IMC-201虽然对癌细胞的结合力高(图5),但对红细胞的结合力低(图7)。
实施例2.5.检验血凝
使用1X杜氏磷酸盐缓冲溶液(DPBS)将健康供体(n=3)的人红细胞稀释为十分之一,在37℃的温度下与标示浓度的IMC-201和其他比较抗体(IMC-002和Hu5F9)过夜培养。
结果,作为比较抗体的Hu5F9表现出高的血凝度,与之相反,IMC-201几乎未表现出血凝度。确认到在与作为对照组的空白组、同种型对照比较时,也表现出相似的结果,与作为单克隆抗体的IMC-002的结果也相似。确认到在此确认的IMC-201几乎不表现出凝血度反映除在上述实施例2.4中确认的对红细胞的低结合力(图8)。
实施例2.6.确认吞噬作用(phagocytosis)
在抗体的存在下,以1:1的比例将单核细胞来源巨噬细胞(monocyte-derivedmacrophage,MDM)分别与CFSE-标记MDA-MB-231、H1975、Raji(ATCC#CCL-86)和SR786(DSMZ#ACC369)细胞共同培养2小时。在MDA-MB-231细胞的情况下,以5μg/ml、10μg/ml的浓度处理IMC-002和IMC-201,在H1975细胞的情况下,以0.37μg/ml、1.11μg/ml、3.33μg/ml的浓度处理IMC-002和IMC-201。在Raji细胞的情况下,以0.04μg/ml、0.12μg/ml、0.37μg/ml的浓度处理IMC-002和IMC-201,在R786细胞的情况下,以0.01μg/ml、0.04μg/ml、0.12μg/ml的浓度处理IMC-002和IMC-201。
在试验抗体的存在下通过流式细胞分析评估巨噬细胞对肿瘤细胞的吞噬作用。巨噬细胞定义为存活的CD11b+细胞。吞噬作用%定义为作为CFSE+的巨噬细胞的百分比。
结果,在4种细胞中都确认到IMC-201的吞噬作用与IMC-002相比为同等或以上,尤其在MDA-MB-231细胞与H1975细胞中,IMC-201表现出显著高的吞噬作用(图9)。
实施例2.7.评估肿瘤细胞的ADCC活性
利用ADCC assay kit(Promega_G7018)评估ADCC活性。在试验当天铺靶细胞Raji,而靶细胞MDA-MB-231则是事先过夜铺在培养板上。在抗体(IMC-201、IMC-001、IMC-002或Avelumab)的存在下,在4℃的温度下共同培养ADCC生物测定靶细胞1小时。在此情况下,在Raji细胞中连续稀释4倍来处理抗体,在MDA-MB-231细胞中连续稀释7倍来处理抗体。通过洗涤完全去除未与靶细胞结合的抗体后,在5%CO
结果,表现出在表达CD47的细胞(Raji)中只有IMC-201表达出ADCC效果的惊人结果(图10a)。并且,在同时表达PD-L1与CD47的细胞(MDA-MB-231)中,IMC-201表现出最高的效果(图10b)。
实施例2.8.评估初级自然杀伤细胞(primary NK cell)的ADCC活性
通过CD107a脱颗粒评估来评估初级自然杀伤细胞的ADCC。以0.1μg/ml、1μg/ml、10μg/ml浓度向作为初级自然杀伤细胞靶细胞的MDA-MB-231细胞预处理抗体(IMC-001、IMC-201)30分钟后,在37℃、5%的CO
结果,确认到通过IMC-201的自然杀伤细胞的活性与竞争药物相同(未出示数据),与IMC-001相比,在所有浓度中都显著优异(图11)。自然杀伤细胞的活性增加表明通过IMC-201增加了先天免疫(innate immunity)活性。
实施例2.9.确认通过抗体的T细胞活性(混合淋巴细胞反应(MLR)分析)
通过利用树突状细胞和T细胞的混合淋巴细胞反应(MLR,Mixed LymphocyteReaction)分析确认通过抗体的T细胞的活性。在CD14+单核细胞中分化出单核细胞衍生的树突状细胞(Monocyte derived dendritic cells,moDC)后,在外周血单个核细胞(PBMC,Peripheral blood mononuclear cells)中使用分离用试剂盒(stem cell#17952)分离CD4+T细胞来确保。在IMC-001或IMC-201(0.001μg/mL至10μg/mL,10倍稀释)的存在下以1:10的比例一同培养单核细胞衍生树突状细胞与CD4+T细胞5天,在确保的细胞培养液中通过ELISA确认γ干扰素(IFN-γ)的表达。
结果,确认到IMC-201浓度依赖性地增加浓度γ干扰素(图12)。IMC-201表现出与作为母本抗体的IMC-001相似的功效,在混合淋巴细胞反应分析中的γ干扰素的表达增加暗示在肿瘤微环境中通过增加对癌细胞的细胞毒性来抑制癌症的可能性。
实施例3.确认IMC-201的效果(体内(in vivo))
实施例3.1.在乳癌细胞株Xenograft模型中的癌细胞生长抑制效果
为了IMC-201的生物体内功效研究,解冻和培养MDA-MB-231乳癌细胞株,将该细胞以1×10
接种细胞后的第17天,当平均肿瘤大小到达90.89mm
在D0、D4、D7、D11、D14、D18、D21、D25、D28、D32、D39、D46和D53测量肿瘤体积和体重。通过以下式计算肿瘤体积并以mm
数据以平均值±标准误(Mean±SEM)的方式表示。为了两组之间的比较,进行独立标本T检验(Independent-Samples T test)。使用SPSS的18.0版本分析所有数据。将P<0.05看做统计学显著性。
移植乳癌细胞株的功效研究设计如下。
表7
与进行功效研究的结果相关地,以肿瘤生长曲线为基准的肿瘤生长抑制如图14所示。
通过上述结果确认到如下事项。在作为功效研究终点的第65天,与同种型对照(G1、IgG1kappa、21.4mpk、QW×5w)相比,IMC-001(G2,2.1mpk,QW×5w)组中的肿瘤体积(TGItv=42.70%)无显著差异。相反,与对照组相比,IMC-002(G3,2.1mpk,QW×5w)组中的肿瘤体积(TGItv=51.12%)表现出显著差异(P<0.05*)。并且,在IMC-001与IMC-002的并用-处理组(G4,2.1mpk+2.1mpk,QW×5w)和IMC-201-处理组(G5,3mpk,QW×5w)中,有关肿瘤体积的TGI值分别为67.14%、92.78%,表现出显著差异(P<0.01**)。尤其,IMC-201-处理组最表现出组显著的肿瘤生长抑制效果。
实施例3.2.在大肠癌细胞株Xenograft模型中的癌细胞生长抑制效果
用于IMC-201的生物体内功效研究的癌细胞株为CT26-hPD-L1/hCD47,这是通过流式细胞分析确认到该细胞通过敲除CT26 WT细胞(Kerafast公司,Cat No:ENH204)的小鼠PD-L1和CD47基因并插入恒常表达的人PD-L1和CD47基因来生成。
解冻并传代培养CT26-hPD-L1/hCD47细胞后,将该细胞以2×10
接种细胞后的第7天,当平均肿瘤大小到达99.92mm
数据以平均值±标准误的方式表示。为了两组之间的比较,进行独立标本T检验。使用SPSS的18.0版本分析所有数据。将P<0.05看做统计学显著性。
移植大肠癌细胞株的功效研究设计如下。
表8
在上述试验物品中,同种型对照为IgG1 kappa(Crownbio公司)。
与进行功效研究的结果相关地,以肿瘤生长曲线为基准的肿瘤生长抑制如图15所示。
通过上述结果确认如下事项。在功效研究终点,与同种型对照(G1、IgG1 kappa、21.4mpk、QW×2w)相比,G3(IMC-002施用组,2.1mpk,BIW×2w)组中的肿瘤体积(TGItv D28=27.08%)和肿瘤重量(TGItw=21.11%)表现出不显著的差异。并且,与G1相比,G4(IMC-001+IMC-002并用处理组,2.1mpk,BIW×2w)的肿瘤体积(TGItv D28=27.37%)和肿瘤重量(TGItw=26.93%)也表现出不显著的差异。与之相反,与G1相比,IMC-001处理组(G2,2.1mpk,BIW×2w)的肿瘤体积(TGItv D28=38.60%)和肿瘤重量(TGItw=41.43%)表现出显著差异(P<0.05*)。而且,G5(IMC-201,3mpk,BIW×2w)的肿瘤体积(TGItv D28=83.57%)和肿瘤重量(TGItw=82.98%)在统计学上表现出很高的显著性(P<0.001***)。在所有治疗剂施用组中均未观察到异常的体重变化,通过施用IMC-201观察到显著水平的癌症生长抑制,作为母本抗体的IMC-001和IMC-002的单独处理组和并用处理组相比,确认到高水平的癌细胞生长抑制效果。
实施例3.3.复发研究
复发研究是在实施例3.2的功效研究分组后第53天将CT26-hPD-L1/hCD47肿瘤细胞以2×10
通过上述结果确认到以下事项。在作为研究终点的第88天,G1(G1:BALB/c-hPD-1/hSIRPα小鼠)、G5(3mpk(BIW×2w)IMC-201处理的肿瘤退行小鼠)的平均肿瘤体积分别为3233.74mm
通过此确认,IMC-201(3mpk)在相同肿瘤复发研究中具有因记忆T细胞的生成而抑制复发的效果。
<110>益免安协公司
<120>与CD47和PD-L1特异性结合的双特异性抗体
<130>FC22007/PCT
<150>KR 10-2021-0059596
<151>2021-05-07
<160>40
<170>KoPatentIn 3.0
<210>1
<211>119
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第一结构域的经密码子优化的重链可变区
<400>1
Gln Val Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 1015
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
202530
Tyr Met His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
354045
Gly Ile Ile Asn Pro Ser Gly Gly Ser Thr Ser Tyr Ala Gln Lys Phe
505560
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Thr Ser Thr Val Tyr
65707580
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
859095
Ala Arg Ser Thr Leu Trp Val Ser Glu Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210>2
<211>357
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第一结构域的经密码子优化的重链可变区
<400>2
caagtccaac tagtgcagtc cggggccgag gtgaagaagc cgggagcgag cgttaaggtg60
tcatgcaagg caagcggcta tactttcaca agctattaca tgcattgggt tagacaggcc 120
ccaggacagg gcctggagtg gatgggtata attaatccta gtgggggatc tacttcctac 180
gcccaaaaat tccagggaag ggtcacaatg accagggata cctccaccag taccgtatac 240
atggagctgt caagtctgcg aagcgaagat acagcagtgt actactgtgc acgttctacc 300
ctgtgggtgt cagaattcga ttattgggga caggggaccc tggttacagt cagtagt357
<210>3
<211>110
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第一结构域的经密码子优化的轻链可变区
<400>3
Gln Ser Ala Leu Thr Gln Pro Ala Ser Val Ser Gly Ser Pro Gly Gln
1 5 1015
Ser Ile Ser Ile Ser Cys Thr Gly Thr Ser Ser Asp Val Gly Gly His
202530
Asn Tyr Val Ser Trp Tyr Gln Gln His Pro Gly Lys Ala Pro Lys Leu
354045
Met Ile Tyr Asp Val Arg Asn Arg Pro Ser Gly Val Ser Asn Arg Phe
505560
Ser Gly Ser Lys Ser Gly Ser Thr Ala Ser Leu Thr Ile Ser Gly Leu
65707580
Gln Thr Glu Asp Glu Ala Asp Tyr Tyr Cys Asn Ser Tyr Thr Gly Ser
859095
Arg Thr Tyr Val Phe Gly Ser Gly Thr Lys Leu Thr Val Leu
100 105 110
<210>4
<211>330
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第一结构域的经密码子优化的轻链可变区
<400>4
cagtccgccc tgacccagcc tgcatctgta agcggttccc caggccaaag tatctccata60
tcttgcactg gcactagttc tgacgtcggc ggccataact atgtctcatg gtaccagcag 120
catccaggaa aagcccccaa gctcatgatc tatgatgtcc gcaacagacc gtctggggtg 180
agcaaccgat ttagcgggag caaatccgga tccacggcat cattaacaat ttctggattg 240
cagactgagg atgaagctga ctattactgt aattcctata ccggttcgcg gacctatgtc 300
ttcgggagcg ggacaaagct cacagtgctg330
<210>5
<211>121
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第二结构域的经密码子优化的scFv (Hv)
<400>5
Gln Met Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 1015
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
202530
Ala Tyr Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
354045
Gly Gly Ile Ile Pro Ser Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
505560
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65707580
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
859095
Ala Arg Gly Pro Ile Val Ala Thr Ile Thr Pro Leu Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210>6
<211>363
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第二结构域的经密码子优化的scFv (Hv)
<400>6
cagatgcagc tcgtgcagtc cggggccgag gtgaagaagc caggctcctc tgtaaaggtt60
tcctgcaaag ccagcggtgg aacctttagc tcttacgcat atagctgggt tagacaagct 120
ccaggacagg gccttgaatg gatgggtggc ataatcccct cgtttggtac tgctaactac 180
gcacagaagt ttcagggccg cgtgactatc actgcagatg agtccacgtc cactgcatat 240
atggagctgt caagtctacg gtctgaagac accgcagtgt actactgcgc ccgcgggcct 300
atcgtggcta ccataacccc actggattat tggggccaag gtacactagt gacagtctcc 360
tct 363
<210>7
<211>112
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第二结构域的经密码子优化的scFv (Lv)
<400>7
Ser Tyr Val Leu Thr Gln Pro Pro Ser Val Ser Val Ala Pro Gly Lys
1 5 1015
Thr Ala Thr Ile Ala Cys Gly Gly Glu Asn Ile Gly Arg Lys Thr Val
202530
His Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Val Leu Val Ile Tyr
354045
Tyr Asp Ser Asp Arg Pro Ser Gly Ile Pro Glu Arg Phe Ser Gly Ser
505560
Asn Ser Gly Asn Thr Ala Thr Leu Thr Ile Ser Arg Val Glu Ala Gly
65707580
Asp Glu Ala Asp Tyr Tyr Cys Leu Val Trp Asp Ser Ser Ser Asp His
859095
Arg Ile Phe Gly Gly Gly Thr Lys Leu Thr Val Leu Gly Gln Pro Lys
100 105 110
<210>8
<211>336
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第二结构域的经密码子优化的scFv (Lv)
<400>8
tcttatgtcc tcacccagcc accatccgtc tcggtggctc ccgggaaaac cgctacgatt60
gcctgtgggg gcgaaaacat cggccggaag acagttcact ggtatcagca gaaacctggc 120
caggccccag tgcttgtgat ctactacgat tccgacaggc caagtggcat ccccgagagg 180
ttttcaggat ctaattctgg gaatacagct actctgacta ttagcagagt cgaagctgga 240
gatgaagcgg actactattg tctggtatgg gatagttcct cagaccatag aattttcggt 300
ggaggcacta agttaactgt gctgggccaa cctaaa 336
<210>9
<211>248
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第二结构域的经密码子优化的全scFv
<400>9
Gln Met Gln Leu Val Gln Ser Gly Ala Glu Val Lys Lys Pro Gly Ser
1 5 1015
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Gly Thr Phe Ser Ser Tyr
202530
Ala Tyr Ser Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
354045
Gly Gly Ile Ile Pro Ser Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe
505560
Gln Gly Arg Val Thr Ile Thr Ala Asp Glu Ser Thr Ser Thr Ala Tyr
65707580
Met Glu Leu Ser Ser Leu Arg Ser Glu Asp Thr Ala Val Tyr Tyr Cys
859095
Ala Arg Gly Pro Ile Val Ala Thr Ile Thr Pro Leu Asp Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly
115 120 125
Gly Gly Ser Gly Gly Gly Gly Ser Ser Tyr Val Leu Thr Gln Pro Pro
130 135 140
Ser Val Ser Val Ala Pro Gly Lys Thr Ala Thr Ile Ala Cys Gly Gly
145 150 155 160
Glu Asn Ile Gly Arg Lys Thr Val His Trp Tyr Gln Gln Lys Pro Gly
165 170 175
Gln Ala Pro Val Leu Val Ile Tyr Tyr Asp Ser Asp Arg Pro Ser Gly
180 185 190
Ile Pro Glu Arg Phe Ser Gly Ser Asn Ser Gly Asn Thr Ala Thr Leu
195 200 205
Thr Ile Ser Arg Val Glu Ala Gly Asp Glu Ala Asp Tyr Tyr Cys Leu
210 215 220
Val Trp Asp Ser Ser Ser Asp His Arg Ile Phe Gly Gly Gly Thr Lys
225 230 235 240
Leu Thr Val Leu Gly Gln Pro Lys
245
<210>10
<211>744
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第二结构域的经密码子优化的全scFv
<400>10
cagatgcagc tcgtgcagtc cggggccgag gtgaagaagc caggctcctc tgtaaaggtt60
tcctgcaaag ccagcggtgg aacctttagc tcttacgcat atagctgggt tagacaagct 120
ccaggacagg gccttgaatg gatgggtggc ataatcccct cgtttggtac tgctaactac 180
gcacagaagt ttcagggccg cgtgactatc actgcagatg agtccacgtc cactgcatat 240
atggagctgt caagtctacg gtctgaagac accgcagtgt actactgcgc ccgcgggcct 300
atcgtggcta ccataacccc actggattat tggggccaag gtacactagt gacagtctcc 360
tctggagggg gtgggtcagg cggtggggga agcggcggag gtggatcatc ttatgtcctc 420
acccagccac catccgtctc ggtggctccc gggaaaaccg ctacgattgc ctgtgggggc 480
gaaaacatcg gccggaagac agttcactgg tatcagcaga aacctggcca ggccccagtg 540
cttgtgatct actacgattc cgacaggcca agtggcatcc ccgagaggtt ttcaggatct 600
aattctggga atacagctac tctgactatt agcagagtcg aagctggaga tgaagcggac 660
tactattgtc tggtatggga tagttcctca gaccatagaa ttttcggtgg aggcactaag 720
ttaactgtgc tgggccaacc taaa744
<210>11
<211>340
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第一结构域的经密码子优化的Fc区域
<400>11
Ala Ser Thr Lys Gly Pro Ser Val Phe Pro Leu Ala Pro Ser Ser Lys
1 5 1015
Ser Thr Ser Gly Gly Thr Ala Ala Leu Gly Cys Leu Val Lys Asp Tyr
202530
Phe Pro Glu Pro Val Thr Val Ser Trp Asn Ser Gly Ala Leu Thr Ser
354045
Gly Val His Thr Phe Pro Ala Val Leu Gln Ser Ser Gly Leu Tyr Ser
505560
Leu Ser Ser Val Val Thr Val Pro Ser Ser Ser Leu Gly Thr Gln Thr
65707580
Tyr Ile Cys Asn Val Asn His Lys Pro Ser Asn Thr Lys Val Asp Lys
859095
Lys Val Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys
100 105 110
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
115 120 125
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
130 135 140
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
145 150 155 160
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
165 170 175
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
180 185 190
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
195 200 205
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
210 215 220
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
225 230 235 240
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
245 250 255
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
260 265 270
Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser Phe Phe
275 280 285
Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
290 295 300
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
305 310 315 320
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys Gly Ser Ala Gly Gly Ser
325 330 335
Gly Gly Asp Ser
340
<210>12
<211>1020
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第一结构域的经密码子优化的Fc区域
<400>12
gcctctacaa aaggcccttc agtgtttcca ctagctccct cctcaaaatc tacaagcggc60
ggcacagccg cgctcgggtg cttagtcaag gactatttcc ctgagccagt gactgtgagc 120
tggaatagcg gggcccttac atcgggggtt cacacattcc ccgctgtctt gcaaagcagt 180
ggtttgtata gtttgtcatc agtggtcacc gtccctagca gctctttggg cacgcagacg 240
tacatttgca acgtgaatca taagccatcg aacacaaaag ttgataaaaa ggttgaaccg 300
aagtcctgtg acaaaacgca cacctgtccc ccgtgtcctg ctcccgaact tttgggtggt 360
cctagtgtct ttcttttccc tccaaagccc aaggacacac tgatgatttc tcggacccca 420
gaggttactt gcgtagttgt agacgtaagc cacgaggatc ctgaagtcaa atttaattgg 480
tacgtggacg gagtcgaggt acacaatgct aagaccaaac cccgcgagga acaatacaat 540
tccacttacc gcgtcgtttc ggtgctgact gtgctccatc aggactggct gaacggcaaa 600
gaatacaaat gcaaggtaag caacaaggcc ctccccgccc caatcgagaa aaccatctcc 660
aaggccaagg gccagcctcg ggagccccag gtgtataccc tcccccccag ccgagatgaa 720
ctgaccaaaa accaggtgag cctgacttgt ctggtgaagg gattttatcc tagtgatatc 780
gccgtggagt gggagtctaa cggacagccc gagaacaact ataagaccac accgcctgtc 840
cttgactccg acggttcttt cttcctgtac agcaagctca ccgtggacaa gtctcgatgg 900
cagcagggca atgtgttctc ttgctccgtg atgcacgagg cactccataa ccactacaca 960
cagaaaagcc tctctttgtc acccggcaag gggagtgctg gcggctccgg tggagactcc1020
1020
<210>13
<211>106
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第一结构域的经密码子优化的轻链恒定区
<400>13
Gly Gln Pro Lys Ala Ala Pro Ser Val Thr Leu Phe Pro Pro Ser Ser
1 5 1015
Glu Glu Leu Gln Ala Asn Lys Ala Thr Leu Val Cys Leu Ile Ser Asp
202530
Phe Tyr Pro Gly Ala Val Thr Val Ala Trp Lys Ala Asp Ser Ser Pro
354045
Val Lys Ala Gly Val Glu Thr Thr Thr Pro Ser Lys Gln Ser Asn Asn
505560
Lys Tyr Ala Ala Ser Ser Tyr Leu Ser Leu Thr Pro Glu Gln Trp Lys
65707580
Ser His Arg Ser Tyr Ser Cys Gln Val Thr His Glu Gly Ser Thr Val
859095
Glu Lys Thr Val Ala Pro Thr Glu Cys Ser
100 105
<210>14
<211>318
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第一结构域的经密码子优化的轻链恒定区
<400>14
ggccaaccca aagctgcgcc cagtgtaacc cttttccctc cctctagcga ggaactgcag60
gctaataaag ctaccctggt ttgcctcatc tcagattttt accccggcgc cgttaccgtg 120
gcctggaagg cagacagctc acctgttaag gccggtgtgg agacaacaac ccctagcaag 180
cagagcaaca ataaatacgc cgcatccagt tacctgtcac taactccaga acaatggaag 240
tctcacaggt cctacagttg tcaggtgacg cacgagggaa gtacagtgga gaagactgtg 300
gctccaaccg aatgctcg 318
<210>15
<211>2121
<212>DNA
<213>人工序列
<220>
<223>IMC-201的经密码子优化的重链
<400>15
caagtccaac tagtgcagtc cggggccgag gtgaagaagc cgggagcgag cgttaaggtg60
tcatgcaagg caagcggcta tactttcaca agctattaca tgcattgggt tagacaggcc 120
ccaggacagg gcctggagtg gatgggtata attaatccta gtgggggatc tacttcctac 180
gcccaaaaat tccagggaag ggtcacaatg accagggata cctccaccag taccgtatac 240
atggagctgt caagtctgcg aagcgaagat acagcagtgt actactgtgc acgttctacc 300
ctgtgggtgt cagaattcga ttattgggga caggggaccc tggttacagt cagtagtgcc 360
tctacaaaag gcccttcagt gtttccacta gctccctcct caaaatctac aagcggcggc 420
acagccgcgc tcgggtgctt agtcaaggac tatttccctg agccagtgac tgtgagctgg 480
aatagcgggg cccttacatc gggggttcac acattccccg ctgtcttgca aagcagtggt 540
ttgtatagtt tgtcatcagt ggtcaccgtc cctagcagct ctttgggcac gcagacgtac 600
atttgcaacg tgaatcataa gccatcgaac acaaaagttg ataaaaaggt tgaaccgaag 660
tcctgtgaca aaacgcacac ctgtcccccg tgtcctgctc ccgaactttt gggtggtcct 720
agtgtctttc ttttccctcc aaagcccaag gacacactga tgatttctcg gaccccagag 780
gttacttgcg tagttgtaga cgtaagccac gaggatcctg aagtcaaatt taattggtac 840
gtggacggag tcgaggtaca caatgctaag accaaacccc gcgaggaaca atacaattcc 900
acttaccgcg tcgtttcggt gctgactgtg ctccatcagg actggctgaa cggcaaagaa 960
tacaaatgca aggtaagcaa caaggccctc cccgccccaa tcgagaaaac catctccaag1020
gccaagggcc agcctcggga gccccaggtg tataccctcc cccccagccg agatgaactg1080
accaaaaacc aggtgagcct gacttgtctg gtgaagggat tttatcctag tgatatcgcc1140
gtggagtggg agtctaacgg acagcccgag aacaactata agaccacacc gcctgtcctt1200
gactccgacg gttctttctt cctgtacagc aagctcaccg tggacaagtc tcgatggcag1260
cagggcaatg tgttctcttg ctccgtgatg cacgaggcac tccataacca ctacacacag1320
aaaagcctct ctttgtcacc cggcaagggg agtgctggcg gctccggtgg agactcccag1380
atgcagctcg tgcagtccgg ggccgaggtg aagaagccag gctcctctgt aaaggtttcc1440
tgcaaagcca gcggtggaac ctttagctct tacgcatata gctgggttag acaagctcca1500
ggacagggcc ttgaatggat gggtggcata atcccctcgt ttggtactgc taactacgca1560
cagaagtttc agggccgcgt gactatcact gcagatgagt ccacgtccac tgcatatatg1620
gagctgtcaa gtctacggtc tgaagacacc gcagtgtact actgcgcccg cgggcctatc1680
gtggctacca taaccccact ggattattgg ggccaaggta cactagtgac agtctcctct1740
ggagggggtg ggtcaggcgg tgggggaagc ggcggaggtg gatcatctta tgtcctcacc1800
cagccaccat ccgtctcggt ggctcccggg aaaaccgcta cgattgcctg tgggggcgaa1860
aacatcggcc ggaagacagt tcactggtat cagcagaaac ctggccaggc cccagtgctt1920
gtgatctact acgattccga caggccaagt ggcatccccg agaggttttc aggatctaat1980
tctgggaata cagctactct gactattagc agagtcgaag ctggagatga agcggactac2040
tattgtctgg tatgggatag ttcctcagac catagaattt tcggtggagg cactaagtta2100
actgtgctgg gccaacctaa a2121
<210>16
<211>648
<212>DNA
<213>人工序列
<220>
<223>IMC-201的经密码子优化的轻链
<400>16
cagtccgccc tgacccagcc tgcatctgta agcggttccc caggccaaag tatctccata60
tcttgcactg gcactagttc tgacgtcggc ggccataact atgtctcatg gtaccagcag 120
catccaggaa aagcccccaa gctcatgatc tatgatgtcc gcaacagacc gtctggggtg 180
agcaaccgat ttagcgggag caaatccgga tccacggcat cattaacaat ttctggattg 240
cagactgagg atgaagctga ctattactgt aattcctata ccggttcgcg gacctatgtc 300
ttcgggagcg ggacaaagct cacagtgctg ggccaaccca aagctgcgcc cagtgtaacc 360
cttttccctc cctctagcga ggaactgcag gctaataaag ctaccctggt ttgcctcatc 420
tcagattttt accccggcgc cgttaccgtg gcctggaagg cagacagctc acctgttaag 480
gccggtgtgg agacaacaac ccctagcaag cagagcaaca ataaatacgc cgcatccagt 540
tacctgtcac taactccaga acaatggaag tctcacaggt cctacagttg tcaggtgacg 600
cacgagggaa gtacagtgga gaagactgtg gctccaaccg aatgctcg648
<210>17
<211>7
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第一结构域的重链可变区的CDR1
<400>17
Gly Tyr Thr Phe Thr Ser Tyr
1 5
<210>18
<211>21
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第一结构域的重链可变区的CDR1
<400>18
ggctatactt tcacaagcta t21
<210>19
<211>6
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第一结构域的重链可变区的CDR2
<400>19
Asn Pro Ser Gly Gly Ser
1 5
<210>20
<211>18
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第一结构域的重链可变区的CDR2
<400>20
aatcctagtg ggggatct18
<210>21
<211>10
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第一结构域的重链可变区的CDR3
<400>21
Ser Thr Leu Trp Val Ser Glu Phe Asp Tyr
1 5 10
<210>22
<211>30
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第一结构域的重链可变区的CDR3
<400>22
tctaccctgt gggtgtcaga attcgattat 30
<210>23
<211>14
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第一结构域的轻链可变区的CDR1
<400>23
Thr Gly Thr Ser Ser Asp Val Gly Gly His Asn Tyr Val Ser
1 5 10
<210>24
<211>42
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第一结构域的轻链可变区的CDR1
<400>24
actggcacta gttctgacgt cggcggccat aactatgtct ca 42
<210>25
<211>7
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第一结构域的轻链可变区的CDR2
<400>25
Asp Val Arg Asn Arg Pro Ser
1 5
<210>26
<211>21
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第一结构域的轻链可变区的CDR2
<400>26
gatgtccgca acagaccgtc t21
<210>27
<211>10
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第一结构域的轻链可变区的CDR3
<400>27
Asn Ser Tyr Thr Gly Ser Arg Thr Tyr Val
1 5 10
<210>28
<211>30
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第一结构域的轻链可变区的CDR3
<400>28
aattcctata ccggttcgcg gacctatgtc 30
<210>29
<211>5
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第二结构域的重链可变区的CDR1
<400>29
Ser Tyr Ala Tyr Ser
1 5
<210>30
<211>15
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第二结构域的重链可变区的CDR1
<400>30
tcttacgcat atagc 15
<210>31
<211>16
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第二结构域的重链可变区的CDR2
<400>31
Gly Ile Ile Pro Ser Phe Gly Thr Ala Asn Tyr Ala Gln Lys Phe Gln
1 5 1015
<210>32
<211>48
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第二结构域的重链可变区的CDR2
<400>32
ggcataatcc cctcgtttgg tactgctaac tacgcacaga agtttcag 48
<210>33
<211>12
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第二结构域的重链可变区的CDR3
<400>33
Gly Pro Ile Val Ala Thr Ile Thr Pro Leu Asp Tyr
1 5 10
<210>34
<211>36
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第二结构域的重链可变区的CDR3
<400>34
gggcctatcg tggctaccat aaccccactg gattat36
<210>35
<211>11
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第二结构域的轻链可变区的CDR1
<400>35
Gly Gly Glu Asn Ile Gly Arg Lys Thr Val His
1 5 10
<210>36
<211>33
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第二结构域的轻链可变区的CDR1
<400>36
gggggcgaaa acatcggccg gaagacagtt cac 33
<210>37
<211>7
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第二结构域的轻链可变区的CDR2
<400>37
Tyr Asp Ser Asp Arg Pro Ser
1 5
<210>38
<211>21
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第二结构域的轻链可变区的CDR2
<400>38
tacgattccg acaggccaag t21
<210>39
<211>11
<212>PRT
<213>人工序列
<220>
<223>IMC-201中的第二结构域的轻链可变区的CDR3
<400>39
Leu Val Trp Asp Ser Ser Ser Asp His Arg Ile
1 5 10
<210>40
<211>33
<212>DNA
<213>人工序列
<220>
<223>IMC-201中的第二结构域的轻链可变区的CDR3
<400>40
ctggtatggg atagttcctc agaccataga att 33