一种企业税务风险预测方法
文献发布时间:2023-06-19 13:45:04
技术领域
本申请实施例涉及电子信息技术领域,尤其涉及一种企业税务风险预测方法。
背景技术
目前税务风险主要是靠税务稽查部门进行税务信息核对,这种处理方法需要耗费大量人力并且缺乏对纳税整体的把握,同时由于稽查是对已有申报信息进行事后核对,税局通过人工稽查的方式往往无法及时获得企业或地区的风险情况。例如经典风险预测方法有决策树、随机森林、逻辑回归等机器学习模型等神经网络模型,这些模型可以通过历史数据对某类税收风险情况有一定的预测,但是很难获得较为全面准确的预测结果。
发明内容
有鉴于此,本实施例提供一种基于企业关系链条的税务风险主动预测模型,用以克服传统税收风险预测结果不准确,企业风险数量与宏观经济相脱离的等问题。
第一方面,本申请实施例提供了一种企业税务风险预测方法,包括:
通过设置的第一通讯接口,获取第三方网络应用发送的至少一种税收风险项,并根据第三方网络应用发送的企业风险信息和企业总数通过第一信息处理器计算税收风险的先验概率矩阵和状态转移矩阵;当第三方网络应用发送的税收风险项大于一个时,任意两个税收风险项不同;
根据先验概率矩阵和状态转移矩阵通过第一信息处理器计算出税收风险项的风险状态概率;
根据税收风险项的风险状态概率和企业总数,通过第一信息处理器计算出税收风险项对应的目标数量;
通过设置的第二通讯接口,获取第三方网络应用发送的企业信息并根据企业信息通过第二信息处理器构建企业和风险之间的风险路径链路,根据风险路径链路生成多维矩阵;通过多维矩阵对分解因子机特征提取模型进行参数调整;
根据分解因子机特征提取模型通过第二信息处理器确定出税收风险项对应的企业以及企业风险概率;
根据风险项对应的目标数量,通过第三信息处理器,在税收风险项对应的企业中,按照企业风险项概率由高到低的顺序,筛选出目标数量的企业,并作为预测结果输出至应用程序终端。
可选地,在一种实现方式中,根据风险路径链路生成多维矩阵包括:
通过第二信息处理器从构建的企业和风险路径链路中抽取企业税务风险特征对;进而根据每种企业相同的企业税务风险特征对,构建多维矩阵。
可选地,在一种实现方式中,企业税务风险预测方法还包括:
通过第二信息处理器对多维矩阵进行矩阵分解,得到税务风险项矩阵及其对应的企业风险概率特征矩阵;
通过第二信息处理器对企业风险概率特征矩阵的二阶关系进行建模得到初始的分解因子机特征提取模型;初始的分解因子机特征提取模型输出结果计算最小化均方损失函数,根据最小化均方损失函数的损失函数值调整分解因子机特征提取模型中的参数。
可选地,在一种实现方式中,企业税务风险预测方法还包括:
通过第二信息处理器对二阶关系的损失函数进行正则化处理,根据正则化损失函数的损失函数值调整分解因子机特征提取模型,得到正则化后的分解因子机特征提取模型。
可选地,在一种实现方式中,企业税务风险预测方法还包括:
根据近端梯度法通过第二信息处理器对二阶关系损失函数进行迭代计算,根据迭代后损失函数的损失函数值调整分解因子机特征提取模型,得到迭代后的分解因子机特征提取模型。
可选地,在一种实现方式中,通过设置的第二通讯接口,获取第三方网络应用发送的企业信息并根据企业信息通过第二信息处理器构建企业和风险之间的风险路径链路,根据风险路径链路生成多维矩阵,包括:通过设置的第二通讯接口,获取第三方网络应用发送的企业信息并根据企业信息通过第二信息处理器构建异质信息网络,从异质信息网络中构建企业和风险之间的风险路径链路,根据风险路径链路生成多维矩阵。
可选地,在一种实现方式中,第三方网络应用发送的税收风险项包括:
虚开增值税专用发票或者虚开用于骗取出口退税、抵扣税款的其他发票;偷税;虚开普通发票;骗取出口退税;走逃;私自印制、伪造、变造发票,非法制造发票防伪专用品,伪造发票监制章。
第二方面,本申请实施例提供了一种电子设备,包括:处理器、存储器、通信接口和通信总线,处理器、存储器和通信接口通过通信总线完成相互间的通信;
存储器用于存放至少一可执行指令,可执行指令使处理器执行如第一方面或第一方面的任意一种实现方式中所描述的的企业税务风险预测方法对应的操作。
第三方面,本申请实施例提供了一种计算机存储介质,其上存储有计算机程序,该程序被处理器执行时实现如第一方面或第一方面的任意一种实现方式中所描述的的企业税务风险预测方法。
第四方面,本申请实施例提供了一种计算机程序产品,包括计算机指令,计算机指令指示计算设备执行如第一方面或第一方面的任意一种实现方式中所描述的的企业税务风险预测方法。
本发明通过对于至少一种税收风险项,根据企业风险信息和企业总数计算税收风险的先验概率矩阵和状态转移矩阵;当税收风险项大于一个时,任意两个税收风险项不同;根据先验概率矩阵和状态转移矩阵计算出税收风险项的风险状态概率;通过税收风险项的风险状态概率和企业总数,计算出税收风险项对应的目标数量;获取企业信息并根据企业信息构建企业和风险之间的风险路径链路,根据风险路径链路生成多维矩阵;通过分解因子机特征提取模型确定出税收风险项对应的企业以及企业风险概率;按照风险项对应的目标数量,在税收风险项对应的企业中,按照企业风险项概率由高到低的顺序,筛选出目标数量的企业,并作为预测结果输出。因为通过税收风险项的风险状态概率和企业总数,计算出税收风险项对应的目标数量,即宏观上对企业进行预测,通过分解因子机特征提取模型确定出税收风险项对应的企业以及企业风险概率,即对企业进行个体微观上的预测,最后通过按照风险项对应的目标数量,在税收风险项对应的企业中,按照企业风险项概率由高到低的顺序,筛选出目标数量的企业,综合宏观和微观对企业进行综合预测,因此,本发明实现了对企业税务风险从宏观和微观角度进行了税务风险主动预测,解决了传统税收风险预测结果不准确,企业风险数量与宏观经济相脱离的缺点。
附图说明
为了更清楚地说明本申请实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请实施例中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据这些附图获得其他的附图。
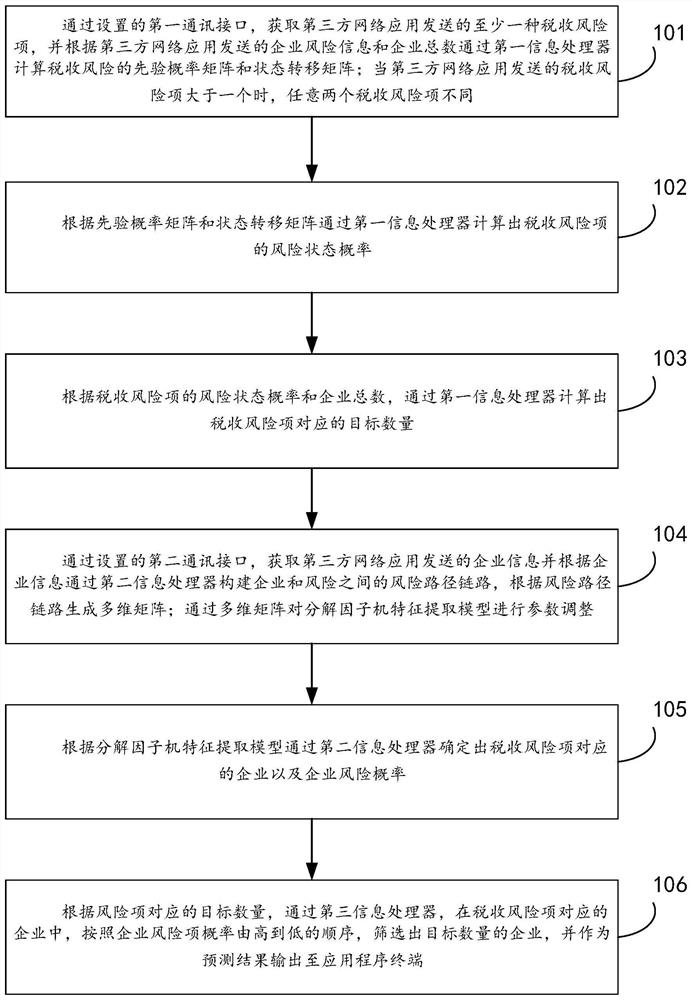
图1为本申请实施例提供的一种企业税务风险预测方法流程图;
图2为本申请实施例提供的一种异质信息网络结构;
图3为本申请实施例提供的一种异质信息网络元路径知识链;
图4为本申请实施例提供的一种电子设备。
具体实施方式
为了使本领域的人员更好地理解本申请实施例中的技术方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请实施例一部分实施例,而不是全部的实施例。基于本申请实施例中的实施例,本领域普通技术人员所获得的所有其他实施例,都应当属于本申请实施例保护的范围。
下面结合本申请实施例附图进一步说明本申请实施例具体实现。
实施例一
本申请实施例一提供一种企业税务风险预测方法,参照图1所示,该方法可以在后台服务器上运行,其具体包括以下步骤:
步骤101、通过设置的第一通讯接口,获取第三方网络应用发送的至少一种税收风险项,并根据第三方网络应用发送的企业风险信息和企业总数通过第一信息处理器计算税收风险的先验概率矩阵和状态转移矩阵;当第三方网络应用发送的税收风险项大于一个时,任意两个税收风险项不同;
需要说明的是,税收风险项可以根据相关部门定义进行分类,也可以自定义进行分类,企业风险信息为企业的税收风险信息,此处企业是指企业所得税法及其实施条例规定的居民企业和非居民企业。居民企业,是指依法在中国境内成立,或者依照外国(地区)法律成立但实际管理机构在中国境内的企业。非居民企业,是指依照外国(地区)法律成立且实际管理机构不在中国境内,但在中国境内设立机构、场所的,或者在中国境内未设立机构、场所,但有来源于中国境内所得的企业;企业总数为某一地区企业数量总数,企业风险信息和企业总数可通过官方渠道获得。
可选地,第三方网络应用发送的税收风险项包括:虚开增值税专用发票或者虚开用于骗取出口退税、抵扣税款的其他发票;偷税;虚开普通发票;骗取出口退税;走逃(失联);私自印制、伪造、变造发票,非法制造发票防伪专用品,伪造发票监制章;以及其他风险中的至少一项。风险项的获悉,通过与税务机构建立通信接口进行连接,例如,通过设置第一通信接口获悉税务机构异常代码或税务公告风险项数据,此处的第一接口仅表示接口的区分。例如,异常代码为001表示企业偷税。
其中企业风险信息为已知的风险企业信息,此处计算先验概率矩阵为根据不同风险对应的代码计算获得当前月份的风险企业数量占比的初始概率矩阵π,此处按月份进行获取既保证了准确度又降低了运算量,也可以按照季度、周、年进行获取,企业数量占比可以用某类风险项的概率乘以企业总数得出
此处计算状态转移矩阵可以为计算企业状态变化的状态转移概率P
P
其中E
设置税收风险预测模型,通过对模型进行利用状态转移概率和先验概率计算从而得到预测月份的状态概率π(k)对应的税收风险预测模型,其中,先验概率就是初始概率:
π(k)=π(k-1)P=π(0)P
对税收风险预测模型经过k次状态转移计算后(一般为1次),得到在第k个时刻对应的税务风险状态的概率。利用状态概率和预测月份的企业数,可以获得不同税收风险的企业总数Ri(表示第i个风险项具有Ri个风险企业),其中,K次代表多少月之后例如k为3次就代表预测3次之后的概率取1次更准确。获得预测结果后,表示获得不同税收风险的企业总数Ri的预测过程。
步骤102、根据先验概率矩阵和状态转移矩阵通过第一信息处理器计算出税收风险项的风险状态概率;
需要说明的是,先验概率矩阵是指获得不同税务风险在当前月份的风险企业数量占比的初始概率矩阵。矩阵中的元素即不同税务风险在当前月份的风险企业数量占比,此处的占比因为是对整体企业进行的计算,也可表述为概率;状态转移矩阵指的是企业从某一风险状态转变另一风险状态的概率矩阵,即风险状态的一种映射关系,例如,企业A由具有风险经过状态转移矩阵运算得到企业A不具有风险;企业状态变化可以是正常企业变为风险企业,风险企业变为正常企业,也可也是正常变为正常,风险变为风险,可以概括为风险企业风险类型变更,变化过程可以是正常变为正常,风险变为风险,也可以是风险变为正常,正常变为风险。
步骤103、根据税收风险项的风险状态概率和企业总数,通过第一信息处理器计算出税收风险项对应的目标数量;
需要说明的是,对计算出税收风险项对应的目标数量进行举例说明,例如,A地区具有偷税风险项的风险状态概率为30%,,即表示A地区具有偷税风险项企业的占比为30%,例如,A地区总计有100家企业,则A地区具有偷税风险项的企业数量为30家。
步骤104、通过设置的第二通讯接口,获取第三方网络应用发送的企业信息并根据企业信息通过第二信息处理器构建企业和风险之间的风险路径链路,根据风险路径链路生成多维矩阵;通过多维矩阵对分解因子机特征提取模型进行参数调整;
需要说明的是,在一种可选的实现方式中,对于一组企业-税务风险对,其中企业-税务风险对是从某一知识链中抽取出的,我们将企业和风险用u
式中F是每种矩阵的秩,u
需要说明的是,此处的企业信息指的是除企业税务风险信息外的与企业有关的所有信息,例如,企业交易信息,企业人员信息等。此处的企业和风险之间的风险路径链路,也可称为知识链,用来表示用户和服务之间的关系,每条知识链表示一种企业和风险之间存在的路径,即一个企业和与之相关事项的联系,其知识链可以穷举,代表企业和风险之间存在的某种关系。此处的多维矩阵指的每种企业-风险对用L×F维形式表达的特征矩阵,用来更高效地统计归纳相同的特征对。
可选地,根据风险路径链路生成多维矩阵包括:
通过第二信息处理器从构建的企业和风险路径链路中抽取企业税务风险特征对;进而根据每种企业相同的企业税务风险特征对,构建多维矩阵。
需要说明的是,通过抽取风险特征对,可以更加准确得出多维矩阵,对于一组企业-税务风险对,其中企业-税务风险对是从某一知识链中抽取出的,可以将企业和风险分别用矩阵元素A和矩阵元素B表示,然后将所有相同的企业-税务风险特征对联合起来。
可选地,通过设置的第二通讯接口,获取第三方网络应用发送的企业信息并根据企业信息通过第二信息处理器构建企业和风险之间的风险路径链路,根据风险路径链路生成多维矩阵,包括:通过设置的第二通讯接口,获取第三方网络应用发送的企业信息并根据企业信息通过第二信息处理器构建异质信息网络,从异质信息网络中构建企业和风险之间的风险路径链路,根据风险路径链路生成多维矩阵。
需要说明的是,通过构建异质网络可以更方便的构建出风险路径链路。如图2所示的一个税务异质信息网络结构,本专利利用企业交易信息和企业登记信息构造异质信息网络,异质信息网络是一种信息网络,包含了节点和边,并且该节点和边具有一种或多种类型,异质信息网络包含了更更丰富的语义信息,可以将企业的登记信息、风险信息、交易信息等囊括在一起。为了更好的将异质信息网络转换为多维矩阵,其中多维矩阵表示有N个不同企业的异质信息网络,如图3所示,从异质信息网络中抽取并构建七条知识链来表示用户和服务之间的关系,每条知识链表示一种企业和风险之间存在的路径,即一个企业和与之相关事项的联系,其知识链可以穷举,代表企业和风险之间存在的某种关系。
步骤105、根据分解因子机特征提取模型通过第二信息处理器确定出税收风险项对应的企业以及企业风险概率;
可选地,通过第二信息处理器对多维矩阵进行矩阵分解,得到税务风险项矩阵及其对应的企业风险概率特征矩阵;
通过第二信息处理器对企业风险概率特征矩阵的二阶关系进行建模得到初始的分解因子机特征提取模型;根据初始的分解因子机特征提取模型的输出结果计算最小化均方损失函数,根据最小化均方损失函数的损失函数值调整分解因子机特征提取模型中的参数;相应地,通过分解因子机特征提取模型确定出税收风险项对应的企业以及企业风险概率,为通过初始的分解因子机特征提取模型确定出税收风险项对应的企业以及企业风险概率。
需要说明的是,在生成特征矩阵后,对特征之间的二阶关系进行建模,通过二阶关系建模可以获得不同特征间的关系,但不能采用1阶段和3阶,原因是,1阶不能与公式2进行结合运算,3阶及以上不能进行分解。本发明中通过对二阶参数进行低秩分解如公式2所示:
其中w
式中y
需要说明的是,通过对特征矩阵的二阶关系建模,可以找出不同风险特征间的关系。
可选地,通过第二信息处理器对二阶关系的损失函数进行正则化处理,根据正则化损失函数的损失函数值调整分解因子机特征提取模型,得到正则化后的分解因子机特征提取模型;相应地,通过分解因子机特征提取模型确定出税收风险项对应的企业以及企业风险概率,为通过正则化后的分解因子机特征提取模型确定出税收风险项对应的企业以及企业风险概率。
需要说明的是,本发明通过元路径知识链,其中元路径就是知识链,两者概率相同的方式构造企业和风险之间的一些隐式特征,为了防止训练结果过拟合,即为了防止数据不均导致训练无意义,本发明利用因子分解机(FM)的方式解决稀疏矩阵(即没有风险的矩阵)下特征组合的问题,排除掉无用的知识链,无用知识链表示没有风险特征的知识链,放弃了对相似度计算无用的特征组,将目标函数简化为非凸非光滑的的问题,正则化后的二阶关系如公式4所示,其中公式4是公式3的具体运算:
式中Φ
需要说明的是,通过对二阶关系模型进行正则化处理,可以剔除正常风险特征,防止训练过拟合。此处正常风险即为没有风险的情况。
可选地,根据近端梯度法通过第二信息处理器对二阶关系损失函数进行迭代计算,根据迭代后损失函数的损失函数值调整分解因子机特征提取模型,得到迭代后的分解因子机特征提取模型;相应地,通过分解因子机特征提取模型确定出税收风险项对应的企业以及企业风险概率,为通过迭代后的分解因子机特征提取模型确定出税收风险项对应的企业以及企业风险概率。
此处的近端梯度法是一种可选地矩阵分解数学方法,经过迭代训练从而获得训练后的参数,有益于减少运算误差,此处的迭代限度设置可以是次数设定,例如100次,也可以是数值设定,例如0.01或0.001。
需要说明的是,近端梯度法是一种可选地矩阵分解数学方法。经过迭代训练获得一阶和二阶参数,迭代的目的是为了减少运算误差,迭代限度设置可以是次数设定,例如100次,也可以是数值设定,例如0.01或0.001。
步骤106、根据风险项对应的目标数量,通过第三信息处理器,在税收风险项对应的企业中,按照企业风险项概率由高到低的顺序,筛选出目标数量的企业,并作为预测结果输出至应用程序终端;
当输入新的企业信息时,新的信息包括企业及其相关的所有信息,将新企业所形成的税务元路径知识链带入模型中获得企业-风险相似度,最后输出企业和风险的关联概率,也就是说将每种企业信息依次输入至模型中,针对按照不同风险,对不同企业依照风险概率大小顺序进行排序再结合得出的不同风险概率对应的企业数目Ri,截取不同风险类型的前Ri项,最后得出风险项目-企业风险概率(由高到低)的矩阵,概率越大说明企业具有该风险的可能性就越大,根据概率大小完成初步风险排序。
最终,获得的不同税收风险企业总数Ri和元路径知识链计算得到的企业风险概率综合排序,根据概率从高到低选择第i个风险项的前Ri个企业作为最终的风险预测结果进行输出
实施例二
结合上述实施例一所描述的企业税务风险预测方法,参照图4所示,本申请实施例二提供了一种电子设备,包括:处理器、存储器、通信接口和通信总线,处理器、存储器和通信接口通过通信总线完成相互间的通信;
存储器用于存放至少一可执行指令,可执行指令使处理器执行上述实施例一所描述的企业税务风险预测方法对应的操作。
实施例三
结合上述实施例一所描述的企业税务风险预测方法,本申请实施例三提供了一种计算机存储介质,其上存储有计算机程序,该程序被处理器执行时上述实施例一所描述的企业税务风险预测方法。
实施例四
结合上述实施例一所描述的企业税务风险预测方法,本申请实施例四提供了一种计算机程序产品,包括计算机指令,计算机指令指示计算设备执行上述实施例一所描述的企业税务风险预测方法对应的操作。