一种协同机器语义任务的深度压缩方法
文献发布时间:2023-06-19 13:46:35
技术领域
本发明属于信息压缩处理技术领域,涉及一种协同机器语义任务的深度压缩方法。
背景技术
在当今的信息时代,大量的图片和视频内容随时都在产生,并被传输到互联网上。2018年思科网站的报告显示,机器对机器的应用将会在未来几年占据大量的互联网内容。并且,机器学习算法倾向于直接处理更多的内容信息,而不仅仅为适应人类的视觉感知,因此,建立既能被机器智能应用程序处理又能被人类视觉系统感知的处理方法至关重要。所以,如何在有限的带宽内建立能够支持混合人机智能应用的方案是亟待解决的问题。近年来,随着深度学习地快速发展,一些基于深度学习的压缩方法也逐步被提出来。然而,这些方法是由服务于人类视觉感知的率失真损失驱动的,与高级的机器视觉任务并不能很好地兼容。此外,在面对大数据和高层分析时,无论是传统的压缩方法,还是基于深度的压缩方法仍存在一些不足。因此,一种能将数据压缩和机器智能分析任务相结合的新一代视频编解码器VCM(Video Coding for Machine)正在被倡议。
在现有技术中,近些年来,众多国内外的团队提出了很多基于深度学习的图像和视频压缩方法
此外,随着人工智能技术的发展,图像和视频内容越来越多地需要由机器分析。因此图像压缩编码算法不仅需要满足人类视觉系统,也需要符合机器视觉任务的需求。为了能够协作压缩和智能分析任务,弥合机器视觉压缩编码和人类视觉压缩编码之间的差距,国际标准化组织提出了新一代视频编解码器标准VCM(Video Codingfor Machine)的倡议。因此,研究人员试图将机器视觉任务与图像压缩任务结合起来,作为统一的框架,来完成针对高级机器视觉任务的压缩任务。比如,一种基于参考DCNN的混合分辨率编码框架
在现有技术中,存在以下缺点:
现有的图像压缩技术是在不影响人类视觉系统感知的情况下对图像数据进行压缩。但随着智能分析任务的飞速发展,大部分的现有图像压缩算法在图像压缩过程中的信息丢失,可能会影响后续的机器视觉任务,比如:语义分割和目标检测等高级任务。本发明要解决的技术问题就是要联合考虑人类视觉系统和机器视觉任务,端到端地进行图像压缩任务和高级机器视觉任务。
目前,图像压缩编码方法是从人类的视觉系统HVS(Human Visual System)角度出发,提高图像的压缩比。然而,近年来视频监控设备在世界各地(特别是我国)广泛布设,为社会安全提供非常有力的技术保障。这些海量的视频数据更多是用于机器的自动分析研判、场景识别和行为检测等。换句话说,越来越多的视频数据不仅要面向人类使用,更要面向机器使用。但当前的压缩编码技术主要是面向人类视觉感知的需求进行设计的,对机器系统而言,并不一定是合适的。
因此,本发明联合考虑人类视觉系统和机器视觉任务,构建深度学习网络,实现兼顾图像压缩和高级机器视觉任务的图像压缩算法,可以达到不影响视觉任务精度的前提下,提高图像压缩性能。
与联合压缩任务与高级机器视觉任务的混合任务相比,本发明不仅利用增强模块,提高了图像压缩性能,而且利用融合模块,增强了语义分割任务的性能。
整个发明提出了一个将图像压缩和语义分割任务结合的统一框架,二者相互增强,既可以提升语义分割任务的性能,又可以提高解压图像的质量。
关键术语定义列表
1、压缩编码:在满足一定保真度的要求下,对图像或视频数据进行变换、量化以及编码等操作,以去除多余数据,从而减少表示图像和视频时所需的数据量,方便存储和传输。
2、语义分割:在图像领域,语义指的是图像的内容,对图片意思的理解,分割则是指从像素的角度分割出图片中的不同对象,语义分割就是让计算机根据图像的语义来进行分割。
发明内容
大多数基于深度学习的图像压缩算法仅仅考虑到了人眼视觉系统,并未考虑到机器视觉系统。而有些基于语义的压缩算法(如EDMS和DSSILC)又无法端到端地进行。本发明既考虑了人眼视觉系统也考虑了机器视觉系统,并且可以进行端到端的训练。此外,本发明的方法还可以兼容除了语义分割任务以外的其他机器视觉任务。
因此,本专利提出了一种面向图像压缩和语义分割任务的端到端的增强网络框架;既使得压缩框架与语义分割框架兼容,又能实现相互增强,具体技术方案如下:
一种协同机器语义任务的深度压缩方法,
所述协同机器语义任务的深度压缩方法基于面向图像压缩和语义分割任务的端到端的增强网络框架;
所述面向图像压缩和语义分割任务的端到端的增强网络框架包括:编码器、量化模块、算术编码模块、算术解码模块、解码器和后处理增强模块;
所述编码器包括:基网络和多尺度融合模块(简称:融合模块);
所述基网络对应压缩分支,所述多尺度融合模块对应语义分割分支;
所述协同机器语义任务的深度压缩方法包括以下步骤:
S1、将输入图像x输入所述基网络,基网络输出压缩特征
S2、所述多尺度融合模块融合基网络的输出,输出多尺度语义特征
S3、将压缩特征
S4、将组合特征z依次经过量化模块的量化、算术编码模块的编码和算术解码模块的算术解码,获得隐特征
S5、隐特征
S6、将解压缩图像
在上述技术方案的基础上,所述基网络采用若干个级联卷积层描述相邻像素之间的相关性;
在卷积层之间加入广义分裂归一化变换;
所述基网络利用广义分裂归一化变换,将像素域特征转移到分裂归一化空间;
第i个卷积层和第i次广义分裂归一化变换构成基网络的第i层,其中,i=1,2,…,n-1;n为基网络的卷积层的总数量;
第i次广义分裂归一化变换称为基网络第i个广义分裂归一化变换层;
所述图像x经过基网络的第i层处理后,输出基网络第i层学习到的特征
在第n个卷积层后输出压缩特征
在上述技术方案的基础上,所述多尺度融合模块包括:n-1个分层特征融合块、3个下采样块和13个non-bottleneck-1D卷积层;
每个分层特征融合块包括:逆向广义分裂归一化变换层和卷积层;
所述步骤S2的具体步骤如下:
S2.1、特征
S2.2、通过n-1个分层特征融合块将来自基网络第i层学习到的特征
其中,j=1,2,…,n-1,
S2.3、将特征
在上述技术方案的基础上,步骤S5的具体步骤如下:
S5.1、压缩特征
所述语义分支的解码器包括:若干反卷积层,在所述反卷积层之间加入non-bottleneck-1D层;
S5.1、语义特征
所述解压缩分支的解码器包括:若干反卷积层,在所述反卷积层之间加入逆向广义分裂归一化层;在所述逆向广义分裂归一化层进行逆向广义分裂归一化变换;
所述逆向广义分裂归一化变换为:所述基网络中广义分裂归一化变换的逆变换。
在上述技术方案的基础上,所述步骤S4的具体步骤如下:
S4.1、将组合特征z量化为特征
S4.2、采用熵编码方法将特征
S4.3、通过熵解码器将分段比特流还原成隐特征
在上述技术方案的基础上,将组合特征z作为超先验信息进行同样的量化、算术编码和算术解码操作,以辅助解码,具体步骤如下:
S4.4、组合特征z通过卷积操作编码器获得特征h;
S4.5、特征h经过量化操作得到特征
S4.6、特征
S4.7、将算术解码结果通过卷积操作编码器进行卷积操作;
S4.8、将步骤S4.7获得的卷积操作结果作为方差
在上述技术方案的基础上,当所述面向图像压缩和语义分割任务的端到端的增强网络框架处于训练阶段时,采用基于加性噪声的量化方法,将组合特征z量化为特征
当所述面向图像压缩和语义分割任务的端到端的增强网络框架处于测试阶段时,采用直接取整的方法,将组合特征z量化为特征
在上述技术方案的基础上,步骤S6的具体步骤如下:
S6.1、首先,将语义分割图像s沿通道维度分别进行最大池化和平均池化操作,然后再进行通道拼接,获得特征s
s
其中,Max(s)表示:对语义分割图像s进行最大池化操作,Avg(s)表示:对语义分割图像s进行平均池化操作;[Max(s),Avg(s)]表示:对Max(s)和Avg(s)进行通道拼接;
S6.2、接着,将特征s
将上述空间结构特征的权值与在语义分割图像s中学习到的语义特征相乘,输出学习到的空间结构特征s
s
其中,W
S6.3、解压缩图像
S6.4、将特征空间结果通过若干增强块处理,获得高频信息
S6.5、将空间结构特征s
然后,再将通道拼接的结果进行卷积操作;
最后,将卷积操作的结果与解压缩图像
在上述技术方案的基础上,步骤S6.4的具体步骤如下:
S6.4.1、将作为第1个增强块的输入,经过若干残差块处理,获得残差块处理结果;
S6.4.2、将第1个增强块的输入与最后一个残差块的处理结果相加,获得第1个增强块处理结果;
S6.4.3、将前一个增强块处理结果作为下一个增强块的输入,直到最后一个增强块输出高频信息
步骤S6.4.1的具体步骤如下:
S6.4.1.1、将特征空间结果作为输入;
S6.4.1.2、将输入经过第一个残差块的第一次卷积运算处理;
S6.4.1.3、将第一次卷积运算处理的结果再经过ReLU函数处理;
S6.4.1.4、将ReLU函数处理的结果再经过第一个残差块的第二次卷积运算处理;
S6.4.1.5、将第一次卷积运算处理的结果与第一个残差块的输入相加,输出第一个残差块的处理结果;
S6.4.1.6、将第一个残差块的处理结果作为输入,进入第二个残差块处理;重复步骤S6.4.1.2-S6.4.1.5,获得第二个残差块的处理结果;
S6.4.1.7、后续残差块的处理过程相同,只是将前一残差块的处理结果作为后一残差块的输入。
在上述技术方案的基础上,所述协同机器语义任务的深度压缩方法的损失函数如式(4)所示,
L=λD+R+CE (4)
其中,λ表示权重超参数,D表示重建图像
其中,N是一批样本的个数,k为一批样本中的第k个样本,M是类别数,c为类别,且c=1,2,…,M,s
本发明具有以下有益技术效果:
1)本发明提出了一种新颖的端到端的相互增强网络,将图像压缩和语义分割任务集成到一个统一的框架。
2)整个框架基于编解码器的结构,在编码器中设计了多尺度融合模块来提高语义分割任务的准确性,在解码器端之后设计了增强模块,用于增强压缩任务的重建图片。
3)从实验结果可以看出,本发明的方法在图像压缩和语义分割任务上实现了相互增强。此外,此框架可以进行拓展,用以支持不仅仅是语义分割的更多机器视觉分析任务。
附图说明
本发明有如下附图:
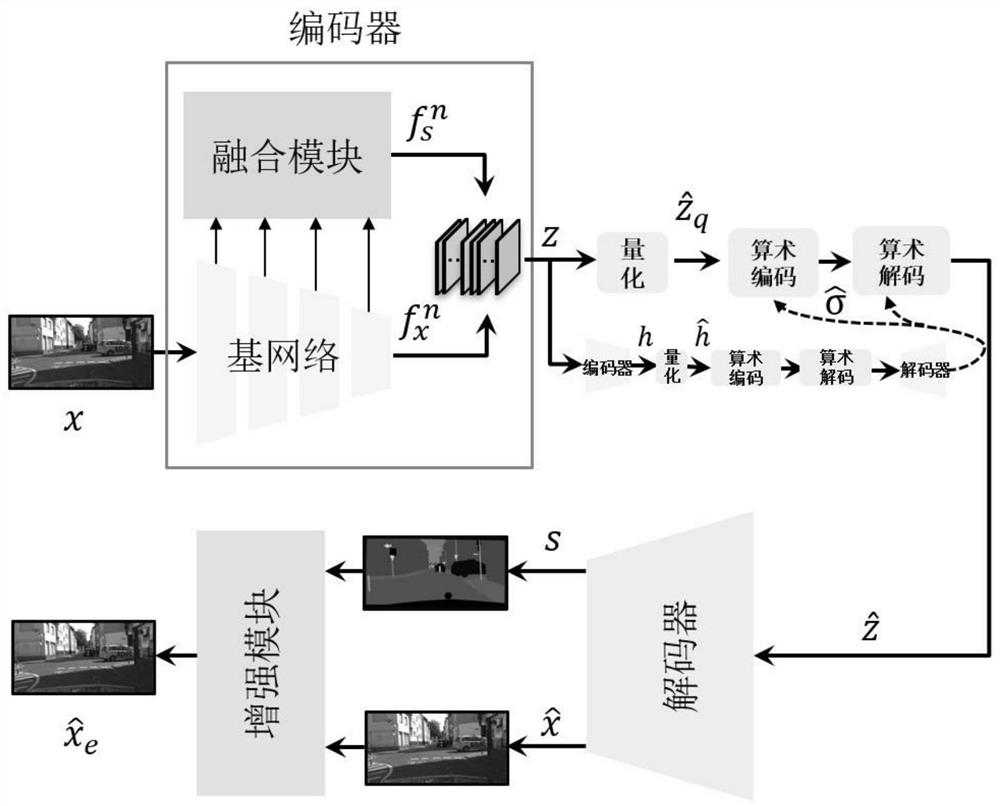
图1为本发明所述基于面向图像压缩和语义分割任务的端到端的增强网络框架的总框架示意图;
图2为基网络的基本结构示意图;
图3为多尺度融合模块的基本结构示意图;
图4为解码器的基本结构示意图;
图5为增强模块的基本结构示意图;
图6为Kodak数据集在PSNR评价指标下的率失真曲线示意图;
图7为Kodak数据集在MS-SSIM评价指标下的率失真曲线示意图;
图8为可视化Kodak数据集的“kodim21.png”的几种方法的解压图像以及原始图像对比结果示意图。
具体实施方式
以下结合附图对本发明做进一步详细说明,如图1-8所示,
本专利提出一种面向图像压缩和语义分割任务的端到端的增强网络框架,如图1所示,既使得压缩框架与语义分割框架兼容,又能实现相互增强。
对于输入图像x,经过编码器中的基网络,得到输出的压缩特征
将压缩特征
对于学习到的压缩特征
其中,本发明还将组合特征z作为超先验信息进行同样的量化、算术编码和算术解码操作,以辅助解码。具体操作如图1所示,组合特征Z通过卷积操作编码器获得特征h,特征h经过量化操作得到特征
需要注意的是,传统方法中的量化操作是将连续的数据转换成离散的数据,从而减少数据量。然而,基于深度学习的方法依赖基于梯度的端到端优化技术,因此量化操作就无法像传统方法中的量化操作一样实施,为此,很多工作也提出一些可以利用在基于深度学习方法中的量化操作。本发明沿用了文献[8]中的方法,在对整个面向图像压缩和语义分割任务的端到端的增强网络框架的训练阶段,添加均匀噪声来近似量化操作,而在测试阶段,则直接取整。
隐特征
简述编码器如下:
本发明的编码器由两部分组成,分别为基网络和多尺度融合模块,分别对应压缩分支和语义分割分支。如图2所示,基网络采用了几个级联卷积层描述相邻像素之间的相关性,这与自然图像的分层统计特性相一致。为了优化图像压缩的特征,本发明利用广义分裂归一化(GDN)变换
第i个卷积层和第i次广义分裂归一化变换构成基网络的第i层,其中,i=1,2,…,n-1;n为基网络的卷积层的总数量;在图2中采用了4个卷积层和3次广义分裂归一化变换。第i次广义分裂归一化变换称为基网络第i个广义分裂归一化变换层;所述图像x经过基网络的第i层处理后,输出基网络第i层学习到的特征
每一层卷积操作都是一个下采样过程,四个卷积层就将原始输入下采样了16倍;这样做的目的就是为了能够更好地学习到更多细节信息。
另一部分用于学习和增强语义特征,称为多尺度融合模块(如图3所示)。为了节省传输和存储空间,在本框架中,将包括语义特征在内的所有学习到的特征都会进行量化。因此,多尺度融合模块有一个关键任务就是减少量化操作带来的影响。本发明中尝试探索利用丰富的特征来增强语义表示,更准确地说,是利用基网络不同层的层次特征来学习高级语义特征。例如,通过n-1个分层特征融合块(即图3中的HFFB)将来自基网络第i层学习到的特征
其中,j=1,2,…,n-1,
W
关于
在分层特征融合块中,特征
为了进一步改善语义信息的表示,采用了特殊的卷积层non-bottleneck-1D
简述解码器如下:
如图4所示,在解码器端,首先将接收到的隐特征
而对于图像的解压缩过程,解码器是由几个反卷积层(图中在卷积式后面有↑,代表上采样操作)和逆向广义分裂归一化变换(IGDN)层组成,相当于对
为了同时满足人眼视觉特性和机器视觉任务的需求,本发明的图像压缩算法(即协同机器语义任务的深度压缩方法)的损失函数可以写成如式(4)所示,
L=λD+R+CE (4)
其中,λ表示权重超参数,D表示重建图像
一般来说,按照式(5)计算,
其中,N是一批样本的个数,k为一批样本中的第k个样本,M是类别数,c为类别,且c=1,2,…,M,s
在语义分割任务中,将一张图片中的对象分成各种类别,例如:在一张交通图片中,人为一个类别、车为一个类别等等。
简述增强模块如下:
受语义分割任务可以识别出每个像素的类别的启发
如图5所示,本发明设计了一个后处理增强模块(简称增强模块),用以改进解压缩图像
首先,对语义分割图像s通过空间注意力模块处理,获得空间结构特征的权值,具体步骤是:
S6.1、首先,将语义分割图像s沿通道维度分别进行最大池化和平均池化操作,然后再进行通道拼接,获得特征s
s
其中,[·,·]表示通道的连接操作(即通道拼接)。
接着,将特征s
将上述空间结构特征的权值与在语义分割图像s中学习到的语义特征相乘,输出学习到的空间结构特征s
s
其中,W
将学习到的空间结构信息(即空间结构特征s
解压缩图像
通过每个增强块处理的具体步骤如下:
首先,将特征空间结果作为第1个增强块的输入,经过若干残差块处理,获得残差块处理结果;
然后,将第1个增强块的输入与最后一个残差块的处理结果相加,获得第1个增强块处理结果;
最后,将前一个增强块处理结果作为下一个增强块的输入,直到最后一个增强块输出高频信息
若干残差块处理的具体步骤如下:
S6.4.1.1、将特征空间结果作为输入;
S6.4.1.2、将输入经过第一个残差块的第一次卷积运算处理;
S6.4.1.3、将第一次卷积运算处理的结果再经过ReLU函数处理;
S6.4.1.4、将ReLU函数处理的结果再经过第一个残差块的第二次卷积运算处理;
S6.4.1.5、将第一次卷积运算处理的结果与第一个残差块的输入相加,输出第一个残差块的处理结果;
S6.4.1.6、将第一个残差块的处理结果作为输入,进入第二个残差块处理;重复步骤S6.4.1.2-S6.4.1.5,获得第二个残差块的处理结果;
S6.4.1.7、后续残差块的处理过程相同,只是将前一残差块的处理结果作为后一残差块的输入。
所述残差块起到频率滤波器的作用,获取高频信息
将空间结构特征s
然后,为了变换通道以适应输出,再将通道拼接的结果进行卷积操作;
最后,将卷积操作的结果与解压缩图像
为了验证本发明所述基于面向图像压缩和语义分割任务的端到端的增强网络框架(简称框架)的有效性,本发明进行了一系列实验,以进行评估方法的有效性。
在本发明中,使用具有19个语义标签的2974张图像的Cityscapes训练集作为整个框架的训练集,统一调整图像的分辨率为512×1024。本发明利用Kodak图像数据集
本发明使用不同的λ值(256、512、1024、2048、4096、6144、8192)控制量化步长,实现端到端的训练方式。实验还使用了Adam优化器,并在前200000次迭代中,固定学习率为0.0001,在后100000次迭代中,将学习率下降到0.00001,GPU采用NVIDIA RTX 3090。
为了客观地评价所提方法的压缩性能,本发明与将计算机视觉任务与压缩结合的工作EDMS
图像压缩的实验结果简述如下:
为了验证本发明的压缩性能,选用了几种常用的图像压缩算法JPEG
如图6所示,本发明的方法优于传统的图像压缩方法JPEG
本发明的压缩分支与HYPERPRIOR方法具有相似的结构,当这个结构集成到本发明的框架中时,综合图6和图7来看,本发明的性能是优于HYPERPRIOR方法的。这个结果表明,本发明中的增强模块通过提取语义分割图中的语义信息,可以有效地改进解压缩图像的质量。
在Kodak数据集上,本发明与JPEG、JPEG2000、BPG、END2END以及HYPERPRIOR方法的解压图像对比结果如图8所示,其中,图像底部括号中的数字表示:Bpp/PSNR/MS-SSIM。在比特率相似的情况下,JPEG和JPEG2000方法得到的解压图像中的海浪是模糊的,且其中的岩石出现较多的噪声和伪影现象。BPG、END2END和HYPERPRIOR方法则略好于JPEG和JPEG2000,但仍有纹理不清晰的问题。而利用本发明的方法重建的解压图像中的纹理信息清晰、颜色与原始图像接近。
简述语义分割的实验结果如下:
本发明的语义分割分支可以兼容许多性能良好的语义分割网络。本发明采用经典的语义分割网络ERFNet
由表1可知,由于量化操作,B+Q结构比baseline结构获得的类平均IoU(即Cla-IoU)下降了将近1%。加入聚合模块的B+Q+A结构比B+Q结构的精度提高了1.3%,甚至优于baseline结构所获得的精度。对比B+A结构与baseline结构可知,B+A模型的精度比baseline提高了0.4%。这些实验结果表明,本发明设计的多尺度聚合模块(即多尺度融合模块)是有效的,可以利用基网络中的多尺度特征信息增强语义信息。
表1消融实验表
表2显示的是本发明的语义分割分支与其他几种语义分割方法在精度上的比较。这些结果是从Cityscapes数据集测试服务器中得到的。加入融合模块的结构(B+A)实现了70.8%的类平均IoU(Cla-IoU)和88.1%平均类别IoU(Cat-IoU)。B+Q+A模型的Cla-IoU和Cat-IoU的值则分别为70.5%和88.0%。对于B+Q+A结构,Cla-IoU与LRR-4x
表2在Cityscapes数据集测试上不同方法的对比结果表
本发明的关键点和欲保护点如下:
1)本发明提出一个统一的端到端的互增强网络框架(即基于面向图像压缩和语义分割任务的端到端的增强网络框架),它集成了图像压缩和语义分割任务;
2)本发明设计了一个融合模块来减少量化操作对精度的影响;
3)本发明中还构造了一个后处理增强模块,通过利用解压缩之后的语义分割图中的语义信息提高解压缩图像的质量。
参考文献(如专利/论文/标准)如下所列:
[1]Liu,D.,Li,Y.,Lin,J.,Li,H.,Wu,F.:Deep learning-based video coding:Areviewand a case study.ACM Computing Surveys(CSUR)53(1),1–35(2020)
[2]Lin,W.,He,X.,Han,X.,Liu,D.,See,J.,Zou,J.,Xiong,H.,Wu,F.:Partition-aware adaptive switching neural networks for post-processing inHEVC.IEEETransactions on Multimedia 22(11),2749–2763(2019)
[3]Cui,W.,Zhang,T.,Zhang,S.,Jiang,F.,Zuo,W.,Wan,Z.,Zhao,D.:Convolutional
neural networks based intra prediction for HEVC.In:2017DataCompressionConference(DCC).pp.436–436.IEEE Computer Society(2017)
[4]Mao,J.,Yu,L.:Convolutional neural network based bi-predictionutilizing spatial
and temporal information in video coding.IEEE Transactions onCircuits andSystems for Video Technology 30(7),1856–1870(2019)
[5]Song,R.,Liu,D.,Li,H.,Wu,F.:Neural network-based arithmetic codingof intraprediction modes in HEVC.In:Visual Communications and ImageProcessing(VCIP).pp.1–4.IEEE(2017)
[6]Liu,D.,Ma,H.,Xiong,Z.,Wu,F.:CNN-based DCT-like transform forimagecompression.In:International Conference on Multimedia Modeling.pp.61–72.Springer(2018)
[7]Alam,M.M.,Nguyen,T.D.,Hagan,M.T.,Chandler,D.M.:A perceptualquantization strategy for hevc based on a convolutional neural networktrained on naturalimages.In:Applications of Digital ImageProcessing.vol.9599,p.959918.International Society for Optics and Photonics(2015)
[8]Ball′e,J.,Laparra,V.,Simoncelli,E.P.:End-to-end optimized imagecompression.In:5th International Conference on Learning Representations,ICLR2017(2017)
[9]Ball′e,J.,Minnen,D.,Singh,S.,Hwang,S.J.,Johnston,N.:Variationalimagecompression with a scale hyperprior(2018)
[10]Lee,J.,Cho,S.,Beack,S.K.:Context-adaptive entropy model for end-to-end optimizedimage compression.In:International Conference on LearningRepresentations(2018)
[11]Hou,D.,Zhao,Y.,Ye,Y.,Yang,J.,Zhang,J.,Wang,R.:Super-resolvingcompressedvideo in coding chain.arXiv preprint arXiv:2103.14247(2021)
[12]Ho,M.M.,Zhou,J.,He,G.:RR-DnCNN v2.0:Enhanced restorationreconstruction deep neural network for down-sampling-based videocoding.IEEETransactions on ImageProcessing 30,1702–1715(2021)
[13]Akbari,M.,Liang,J.,Han,J.:DSSLIC:deep semantic segmentation-basedlayeredimage compression.In:IEEE International Conference on Acoustics,SpeechandSignal Processing.pp.2042–2046.IEEE(2019)
[14]Sun,S.,He,T.,Chen,Z.:Semantic structured image coding frameworkfor multiple intelligent applications.IEEE Transactions on Circuits andSystems for VideoTechnology(2020)
[15]Hoang,T.M.,Zhou,J.,Fan,Y.:Image compression with encoder-decodermatchedsemantic segmentation.In:Proceedings of the IEEE/CVF Conference onComputer Vision and Pattern Recognition Workshops.pp.160–161(2020)
[16]Romera,E.,Alvarez,J.M.,Bergasa,L.M.,Arroyo,R.:ERFNet:Efficientresidual factorized convnet for real-time semantic segmentation.IEEETransactions onIntelligent Transportation Systems 19(1),263–272(2017)
[17]Kodak,E.:Kodak lossless true color image suite(PhotoCD PCD0992).URLhttp://r0k.us/graphics/kodak 6(1993)
[18]Wallace,Gregory,K.:The JPEG still picture compressionstandard.IEEE Transactionson Consumer Electronics 38(1),xviii–xxxiv(1992)
[19]Skodras,A.,Christopoulos,C.,Ebrahimi,T.:The JPEG 2000still imagecompressionstandard.IEEE Signal Processing Magazine 18(5),36–58(2001)
[20]Bellard,F.:Better portable graphics.https://www.bellard.org/bpg(2014)
[21]Ghiasi,G.,Fowlkes,C.C.:Laplacian reconstruction and refinementfor semanticsegmentation.arXiv preprint arXiv:1605.022644(4)(2016)
[22]Chen,L.C.,Papandreou,G.,Kokkinos,I.,Murphy,K.,Yuille,A.L.:Deeplab:Semantic image segmentation with deep convolutional nets,atrousconvolution,andfully connected CRFs.IEEE Transactions on Pattern Analysis andMachine Intelligence 40(4),834–848(2017)
[23]Yu,F.,Koltun,V.:Multi-scale context aggregation by dilatedconvolutions.arXivpreprint arXiv:1511.07122(2015)
[24]Kreˇso,I.,ˇCauˇsevi′c,D.,Krapac,J.,ˇSegvi′c,S.:Convolutionalscale invariance forsemantic segmentation.In:German Conference on PatternRecognition.pp.64–75.Springer(2016)
[25]Lin,G.,Milan,A.,Shen,C.,Reid,I.:RefineNet:Multi-path refinementnetworkswith identity mappings for high-resolution semanticsegmentation.arXiv preprintarXiv:1611.06612
[26]Lin,G.,Shen,C.,Van Den Hengel,A.,Reid,I.:Efficient piecewisetraining ofdeep structured models for semantic segmentation.In:Proceedings ofthe IEEEConference on Computer Vision and Pattern Recognition.pp.3194–3203(2016)
上述实施例对本发明的技术方案进行了详细说明。显然,本发明并不局限于所描述的实施例。基于本发明中的实施例,熟悉本技术领域的人员还可据此做出多种变化,但任何与本发明等同或相类似的变化都属于本发明保护的范围。
本说明书中未做详细描述的内容属于本领域专业技术人员公知的现有技术。