一种基于区块链和联邦强化学习的自动驾驶车可信换道方法
文献发布时间:2023-06-19 18:27:32
技术领域
本发明属于自动驾驶领域。
背景技术
自动驾驶,又称无人驾驶,是依靠计算机与人工智能技术在没有人为操纵的情况下,完成完整、安全、有效的驾驶的一项前沿技术。现阶段自动驾驶技术在效率上已经取得较大的突破,但是由于技术中普遍使用数据驱动的模型引发了用户对个人数据隐私的担忧。同时由于“数据孤岛”问题也在一定程度上影响自动驾驶模型的效果。
近年来,联邦学习已成为解决机器学习中敏感数据问题的一种方案。联邦机器学习是一个机器学习框架,能有效帮助机构在满足用户隐私保护、数据安全和政府法规的要求下,进行数据使用和机器学习建模。联邦学习作为分布式的机器学习范式,可以有效解决数据孤岛问题,让参与方在不共享数据的基础上联合建模,能从技术上打破数据孤岛,实现协作学习。但是,在联邦学习中,容易收到恶意客户端的攻击,导致模型训练效果不理想。同时,联邦学习缺乏对参与训练的车辆的奖励机制导致本地设备不愿意参加联邦训练。因此,如何在确保用户数据的安全性的同时提高模型训练的可靠性是目前急需解决的问题。
发明内容
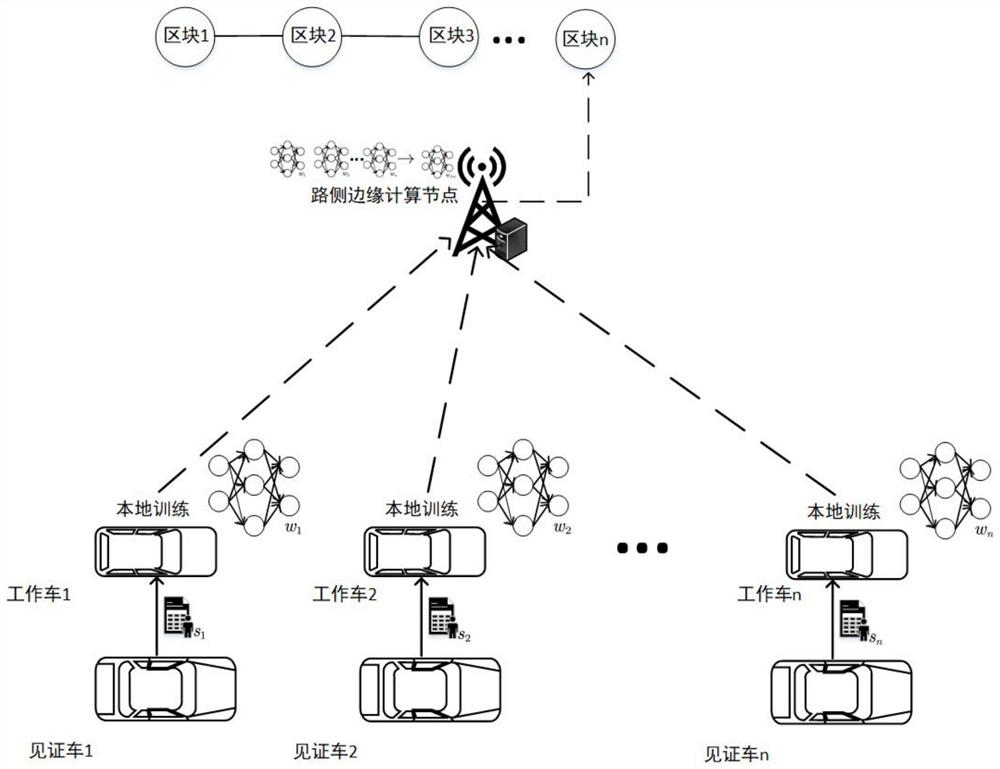
本发明目的在于提供一种基于区块链的联邦学习系统完成换道任务,以克服现有技术的不足,本发明能够有效解决数据隐私问题的同时,使得联邦学习训练达到理想的性能指标,见图1。
本发明包括三个部分:
1.联邦学习:联邦学习也称为协同学习,它可以在产生数据的设备上进行大规模的训练,并且这些敏感数据保留在数据的所有者那里,本地收集、本地训练。在本地训练后,中央的训练协调器通过获取分布模型的更新获得每个节点的训练贡献,但是不访问实际的敏感数据。在典型的联邦学习方案中,中央服务器将模型参数发送到各节点(也称为客户端、终端或工作器)。节点针对本地数据的一些训练初始模型,并将新训练的权重发送回中央服务器,中央服务器对新模型参数求平均值(通常与在每个节点上执行的训练量有关)。在这种情况下,中央服务器或其他节点永远不会直接看到任何一个其他节点上的数据。
2.近端策略优化算法:作为执行换道任务的底层模型,近端策略优化算法是一种策略梯度方法,它使用随机梯度下降优化智能体目标函数。智能体目标函数是损失函数的近似值,它限制了新策略和旧策略之间的比率,以避免大的损失。近端策略优化算法与其他深度强化学习算法相比具有很大的优势。首先,重要性采样和广义优势估计有助于近端策略优化算法代理有效利用采样数据,提高网络更新速度。其次,通过在新旧策略之间进行策略裁剪来限制新策略的更新范围,近端策略优化算法表现出比其他深度强化学习算法更好的收敛性。
3.区块链:区块链本质上是一个去中心化的数据库,是指通过去中心化和去信任的方式集体维护一个可靠数据库的技术方案。区块链技术不依赖第三方、通过自身分布式节点可以实现网络数据的存储、验证、传递和交流。它利用密码学和分布式共识算法,在无法建立信任关系的互联网上,无需借助任何第三方中心的介入就可以使参与者达成共识,以极低的成本解决了信任与价值的可靠传递难题。另外,区块链还具有去中心化、开放性、独立性、安全性和匿名性的特征。
附图说明
图1是整体系统图
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
S1:道路内的所有实体,即所有自动驾驶车和路侧边缘节点,在可信中心中进行区块链网络初始化注册成为授权节点。信任中心向授权节点下发公私钥对和电子钱包账户。
其中,公私钥用来在边缘计算节点和自动驾驶车之间通信加密。电子钱包账户用于数字货币的管理。在可信中心中所有注册的设备都需要缴纳一定的数字货币作为保证金用以预防设备的恶意行为,不同设备需要缴纳保证金的金额与其声望值负相关。另外,各实体经步骤S1授权后成为普通节点。但由于自动驾驶车内存限制,对自动驾驶车节点采取轻量化设计,即自动驾驶车只保留区块链的块头。
S2:路侧边缘计算节点根据道路交通需要发布联邦学习训练任务成为联邦学习服务器端,在路侧边缘计算节点服务范围内的自动驾驶车根据意愿申请成为客户端。服务器与分布式客户端建立训练合约。为了激励自动驾驶车成为客户端,路侧边缘计算节点会为参与训练的客户端可供一笔数字货币(B) 作为奖励。
在路侧边缘计算节点中发布的联邦学习训练任务中应包括:训练任务目标、模型大小、声望阈值要求、验证签名的数量,以及完成任务获得的比特币奖金。路侧边缘计算节点作为服务器在选择客户端时根据申请自动驾驶车的任务声望排名来选择,自动驾驶车声望由积极性,诚实度,任务完成质量三个指标组成。积极性表示自动驾驶车自注册以来担任客户端和见证车的次数,诚实度表示为完成的任务数和未完成任务数之差,任务完成质量由每次完成任务路侧服务器对其任务完成质量是见证车对工作车模型奖励的打分,即见证车用自身计算资源加载模型计算工作车模型的平均奖励。自动驾驶车声望计算方式为:
S3:路侧边缘计算节点生成初始初始模型参数w
对于执行换道任务的底层控制模型,即服务器下发和本地训练的模型,应采用近端策略优化算法。近端策略优化算法是一种基于策略的、使用两个神经网络的深度强化学习算法。在近端策略优化算法中,两张神经网络分别为动作价值网络和状态价值网络,算法将智能体的状态S
在换道任务中,关键模型参数设置为:
(1)状态空间:表示智能体对周围环境的观察。在本地训练开始后,状态空间内的数值作为,算法的输入,本专利中状态空间设置为:
S
其中s
s
(x,y)表示车i的经纬坐标,v
(2)动作空间:在近端策略优化算法模型中,动作是模型根据获得状态得出的策略,一般把动作神经网络的输出直接作为动作。动作空间包括:
A
其中,-1表示被训练车辆向左变道,0表示被训车保持原车道,1表示被训车向右换道。
(3)奖励函数:当动作完成时,环境会为智能体返回奖励,借助梯度上升算法优化近端策略优化算法模型。奖励函数被计算为:
r
r
对于动作价值网络采用含有3个隐藏层的神经网络,隐藏层神经网络节点数分别为256、512、256,输入为智能体的状态,输出为智能体的动作。状态价值网络采用含有3个隐藏层的神经网络,隐藏层神经网络节点数分别为 256、512、256,输入为智能体的状态,输出为智能体的该状态下的价值。
PPO算法可参考论文:[1]Schulman J,Wolski F,Dhariwal P,et al. ProximalPolicy Optimization Algorithms[J].2017.
S4:客户端邀请通信范围内的5辆自动驾驶车成为见证车,验证客户端的训练结果。为了激励周围车参与认证,客户端分出一部分任务奖励b(b<B) 作为认证报酬。
S5:当客户端训练轮数e达到5000次后,客户端首先将训练的结果发送给见证车进行工作认证,见证车认证后把认证结果和签名发送给客户端,当客户端训练结果通过所有见证车的认证。客户端将附有各见证车签名的模型上传到服务器当中。
S6:当聚合时间到时,服务器对已收到的客户端返回的模型参数采用联邦平均聚合算法进行参数聚合,得到本轮聚合参数;当所述本轮聚合模型的平均奖励r
其中是否到聚合时间判断方式为:t-t
所述联邦平均聚合算法总结为:所述联邦平均聚合算法总结为:
其中,w
S7:区块链网络中根据路侧边缘计算节点声望投票选出共识节点。由于自动驾驶车的计算和内存限制,因此,共识节点只在路侧边缘计算节点中选出。路侧边缘计算节点投票选出共识节点,得票数排名前10的节点可以被选择为共识节点。各节点持有的票数与其信誉声望正相关,路侧边缘计算节点j 的信誉声望被计算为:
R
F=F
其中,F表示边缘计算节点的正向贡献,为节点诚实贡献与恶意行为贡献之差。F
各共识节点分别把网络内发生的所有合约内容都被打包进区块。率先完成区块制作的共识节点把自己的共识提议广播给所有共识节点认证,共识节点中半数以上共识节点验证同意该区块提议后,将该区块写入区块链,并将新区块链广播到所有节点。
对于共识机制采用PoW机制,即工作量证明机制,机制中根据共识节点的工作量来执行货币的分配和记账权的确定。算力竞争的胜者将获得相应区块记账权。因此,共识节点的算力越高,越可能获得记账权,而算力需要投入极大的成本。选择PoW机制的原因有:方案简单易实现;节点间无需交换额外的信息即可达成共识;恶意节点破坏系统需要投入极大的成本。
在共识过程完成后,路侧边缘计算节点会读取区块链上的数据,经过计算后为所有参与训练的客户端下发奖励,客户端更新轻量区块链之后,利用块头缓存最近区块的数据,凭借区块中的合约为见证车分发奖励。最后各设备重新计算声望,并在下次共识时写入区块链中。