基于强化学习的主动声纳目标回波检测方法
文献发布时间:2023-06-19 18:32:25
技术领域
本发明属于水声工程技术领域,涉及一种基于强化学习的主动声纳目标回波检测方法。
背景技术
主动声纳是一种能够发射声波并通过处理物体反射回波获取信息的水下设备。目前,主动声纳广泛应用于海洋测绘、海洋渔业和军事等领域。
由于复杂多变的海洋环境,海洋声信道具有时变、空变的特性。当物体反射的回波通过海洋声信道到达接收端后往往会产生严重的畸变,给回波信号的检测和处理带来了困难。
为了对物体具有较高的分辨率,主动声纳通常会发射高频声波。
然而,高频声波在海水中传播衰减较低频声波更为严重,因此,主动声纳的接收信号幅度往往都非常小,因而非常容易被海洋噪声以及混响噪声等淹没。
另外,接收高频声信号需要较高的采样率,因此实时处理难度也会相应增加。
智能算法的出现,使得对于回波信号的检测和处理成为可能。但是由于回波信号具有其独特的特性,即跟随环境的变化,回波信号的回波特征会变得模糊。
虽然在后续处理过程中,模糊逻辑可适用于任意复杂的对象环境变化,但是随着输入、输出变量的增加,模糊逻辑的推理将变得非常复杂且难于调试。
发明内容
本发明的目的在于提出一种基于强化学习的主动声纳目标回波检测方法,通过强化学习的方法对主动声纳接收信号进行处理,检测目标回波的有无,以提高检测的准确率和鲁棒性。
本发明为了实现上述目的,采用如下技术方案:
基于强化学习的主动声纳目标回波检测方法,包括如下步骤:
步骤1. 获取主动声纳信号回波的历史状态数据;
首先对历史状态数据进行量化以及标准化预处理操作,然后对预处理后的信号进行分割并进行灰度值处理,其中,声纳信号的特征将隐藏在生成的灰度图中;
每一个生成的灰度图即为一组历史状态数据;为每组历史状态数据制作标签表示其回波所在的位置,将添加标签后的各组历史状态数据分别作为一组训练数据;
步骤2. 建立奖励值体系,根据信号的功率的相关程度计算奖励值;
步骤3. 将每一组历史状态数据输入到强化学习模型中进行初步决策;
在训练过程中将每一组历史状态数据和初步决策数据输入预先建立的卷积网络模型中,卷积网络模型提取主动声纳信号的特征,将信号的特征量化,得到状态变化量以及奖励值;
状态量变化值为当前状态数据与下一状态数据的差值;根据每一组历史状态数据以及对应的初步决策数据、状态变化量以及奖励值更新数据表结构;
其中,数据表结构是强化学习模型进行学习时对每一步的状态进行收集,当使用训练好的强化学习模型做出动作时,通过查表操作判断所执行的动作;
通过最小化预定目标的价值与输出的价值的差值,更新估值网络,以本次价值与前次价值的差值构建目标函数,用梯度下降法更新估值网络的权值;
此处预定目标是指距离目标回波的最小距离,输出是指实际距离目标的距离;
步骤4. 使用训练好的卷积网络模型与数据表结构,对输入的主动声纳信号回波数据进行状态判断,直到找到主动声纳信号回波数据对应的目标回波位置。
本发明具有如下优点:
如上所述,本发明述及了一种基于强化学习的主动声纳目标回波检测方法。该检测方法通过利用强化学习的方法对主动声纳接收信号进行处理,检测目标回波的有无,从而提高了检测的准确率和鲁棒性。本发明方法使用卷积提取特征的方式,使得目标回波检测更加准确,同时通过大量的数据集的加持,使其能力更加泛化,对与多种不同状态的回波信号都能检测出。强化学习的引入相当于给信号回波的判断加入一个大脑,其中Q的动作效用用于评价在特定状态下采取某个动作的优劣,利用马尔科夫性质,只利用了下一步信息,让系统按照策略指引进行探索,在探索每一步都进行状态价值的更新,这就相当于提取准确特征,经过机器大脑判断是否为目标回波,并给出下一步的状态提示,提高了对目标回波的判断效率。
附图说明
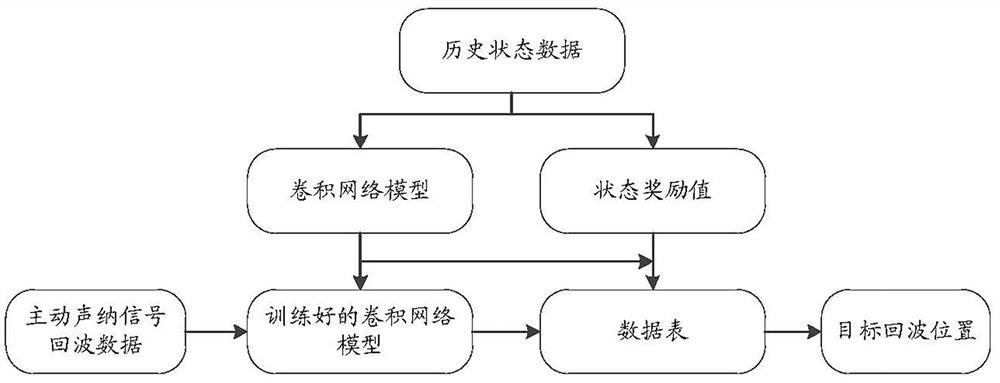
图1为本发明实施例中基于强化学习的主动声纳目标回波检测方法的流程框图。
图2为本发明实施例中信号处理流程图。
图3为本发明实施例中强化学习模型的网络架构图。
图4为本发明实施例中基于强化学习模型的主动声纳目标回波存在性判断流程图。
具体实施方式
下面结合附图以及具体实施方式对本发明作进一步详细说明:
如图1所示,基于强化学习的主动声纳目标回波检测方法,包括如下步骤:
步骤1. 获取主动声纳信号回波的历史状态数据。
首先对历史状态数据进行量化以及标准化预处理操作,然后对预处理后的信号进行分割,并对分割的信号进行灰度值处理,声纳信号的特征将隐藏在生成的灰度图中。
此处分割是指对主动声纳信号进行有序的分割,即对主动声纳信号进行分割中,下一段的信号会包含上一段的1/3部分,这是为了让特征学习具有连续性。
在生成的每个灰度图中四个连续像素点黑白之间的差异变化,相当于一个返回的正弦波。
每一个生成的灰度图即为一组历史状态数据。
如图2所示,使用信号的平均值和方差将信号转换为灰度信号图的过程如下:
步骤1.1 通过如下公式计算主动声纳信号的方差G
G
其中,a
步骤1.2 通过如下公式调整主动声纳信号的幅值图。
G(i,j)= [G(i,j)-min[G]]/max[G]。
其中,min[G]表示主动声纳信号的灰度值G中的最小值,max[G]表示G中的最大值。
步骤1.3 使用灰度均值及方差归一化调整后的主动声纳信号图。
当G≥g时,调整后的灰度值G
为每组历史状态数据制作标签表示其回波所在的位置;将添加标签后的每组历史状态数据分别作为一组训练数据,用于下述强化学习模型的训练。
步骤2. 建立奖励值体系,根据信号的功率的相关程度计算奖励值。
本实施例对于CW(连续波)回波进行了给予了特定的奖励计算方法,如下所示:
P
其中,P
β表示为混响抑制因子,I表示单位矩阵;Q
d表示信号分割后的序列长度,d=N/K;其中,N为信号协方差矩阵估计的秩;K表示初始的滤波器阶数,其为信号的分段数,K为一维矩阵。
本发明根据发射信号原有的特性建立相关性求解,当检测到的信号与发射信号功率相匹配时,则最高给予其奖励1,当与原有信号的功率谱相关性小时则最低给予奖励0。
此时的相关性小,是指与原有信号的功率谱相关性小于预设的相关性阈值。
为了在训练时告诉其目标在什么位置,需要将奖励值提供进来,奖励值的计算如上述公式所示,每当越来越靠进目标时将提供一个奖励值,对其进行奖励。
此种方式可引导卷积网络模型去寻找目标,并且对目标的附近的特征进行详细的学习。
步骤3. 将每一组历史状态数据(即根据训练集对网络进行训练判断结果,通过不断覆盖更新生成的数据表集合)输入到强化学习模型中进行初步决策。
本实施例中采用强化学习的模型,其模型结构如图3所示。将每一步的状态
得益于这种结构,能使用少量数据集得到不错的学习效果。
在训练过程中将每一组历史状态数据和初步决策数据输入预先建立的卷积网络模型中,卷积网络模型提取主动声纳信号的特征,将信号的特征量化,得到状态变化量以及奖励值。
将标准处理后生成的灰度值图像数据输入到卷积网络模型中提取其主要特征,根据其特征分析出,其下一步的运动状态,即左、停、右三种运动状态。
当下一步的运动状态为左时,判断其回波信号在其左侧,将向左侧继续寻找回波。
当下一步的运动状态为右时,判断其回波信号在其右侧,将向右侧继续寻找回波。
当下一步的运动状态为停时,说明这个为回波所在位置,将停止不运动。
状态量变化值指当前状态数据与下一状态数据的差值;根据每一组历史状态数据以及对应的初步决策数据、状态变化量以及奖励值更新数据表结构。
其中,数据表结构是强化学习模型进行学习时对每一步的状态进行收集,当使用训练好的强化学习模型做出动作时,通过查表操作判断所执行的动作。
数据表结构表示为Qtable=(s,[a,r],s
得到状态s和下一步的奖励值r之后,对当前状态的价值进行评估,计算公式如下:
Q=r+γmax
Q为当前操作的对应评价,在后面将通过此步骤不断的进行更新,直到为最佳值。
通过最小化预定目标的价值与输出的价值的差值,来更新估值网络,以本次价值与前次价值的差值构建目标函数,用梯度下降法更新估值网络的权值。
此处预定目标是指距离目标回波的最小距离,输出是指实际距离目标的距离。
估值网络的更新过程如下:
Q
L(θ)=E(TargetQ
其中,Q*(s,a)表示做完动作后对Q值的更新;Q(s,a)表示当前行动的Q值;α表示学习效率。s’和a’分别表示下一步的行动以及下一步的状态。
max
L(θ)表示在参数θ下的损失函数,损失函数通过进行反向传播梯度,对网络权值进行更新,当L(θ)收敛不变时即为最优结果,此时的动作网络即为最优的控制策略。
此时保存好的卷积网络模型,即为训练好的卷积网络模型(声纳信号特征提取网络模型)。
通过估值网络的更新公式不断与原有的信号进行误差判断,直到找到目标信号使其与原有的网络结构的损失函数值最小,训练其能够快速找到目标回波信号所在的位置。
本发明动作网络和估值网络兼顾动态性能和鲁棒性,估值网络能较为准确的估计当前回波信号探测系统的运行状态,同样对控制过程有着一定的指导意义,也可用于在线更新。
步骤4. 使用训练好的卷积网络模型与数据表结构Qtable,对输入的主动声纳信号回波数据进行状态判断,直到找到主动声纳信号回波数据对应的目标回波位置。
如图4所示,基于强化学习模型的主动声纳目标回波存在性判断方法步骤如下:
步骤4.1. 将输入的主动声纳信号进行量化以及标准化预处理处理。
输入的原始信号会存在跳点、奇异值等问题,这一些点都会为后面的特征发现增加难度,在开始步骤对输入的原始信号进行预处理,将使得特征判断与计算更加准确。
步骤4.2. 对主动声纳信号进行有序的分割,其中,对主动声纳信号进行分割中,下一段的信号会包含上一段的1/3部分,这是为了让特征学习具有连续性。
步骤4.3. 按照步骤3获得训练好的卷积网络模型以及Q表,即存储状态数据表;Q表存储有强化学习中对于下一步的动作判断,卷积网络模型存储对于信号的特征提取与学习。
步骤4.4. 通过卷积网络模型对主动声纳探测信号进行识别,得到信号特征,以用Q表对下一步的推断与判定。
步骤4.5. 通过查询Q表结构快速推断下一步是结束判断,还是继续判断。
步骤4.6. 当通过查询Q表结构,表示下一步为结束时,则本段数据则是包含回波信号的数据段,同时根据回波的位置推断出声纳距离目标的距离位置。
当然,以上说明仅仅为本发明的较佳实施例,本发明并不限于列举上述实施例,应当说明的是,任何熟悉本领域的技术人员在本说明书的教导下,所做出的所有等同替代、明显变形形式,均落在本说明书的实质范围之内,理应受到本发明的保护。