一种基于深度学习的危险动作识别方法
文献发布时间:2024-04-18 19:52:40
技术领域
本发明属于人工智能技术领域,涉及一种基于深度学习的危险动作识别方法。
背景技术
在水泥生产发运作业环节中,设备种类众多,场景复杂,同时外来发运车辆、船只众多,人员类型复杂,时长出现外来人员危险作业、做出危险动作的情况,如氨水房、纸袋库人员点火吸烟,发运船只盖棚上人员行走等。为了减少外来人员危险动作发生频次,提高外来人员安全意识,同时也降低厂内安全巡检人员工作难度。而对于某些复杂的图像场景,目标检测仍然不能完全满足检测需求。在工业作业中,我们需要保证员工按照要求进行规范的作业行为,从而避免产生安全隐患和产品质量隐患;此外,员工的危险动作,例如翻越护栏、水泥运输船盖棚上作业等对其自身安全造成威胁的举动需要被及时制止。本发明在基于深度学习技术的基础上提出一种危险动作识别方法。
发明内容
本发明的目的是提供一种基于深度学习的危险动作识别方法,用于解决现有技术分析角度不够全面,对于发运船只盖棚上人员行走等危险行为检测不够准确的技术问题。
所述的一种基于深度学习的危险动作识别方法,包括下列步骤:
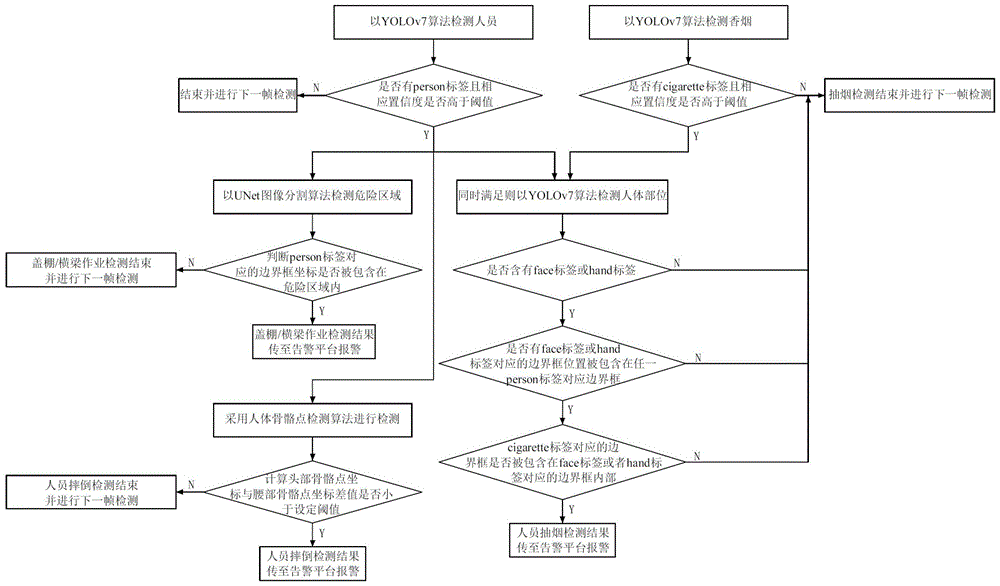
步骤一、采集图像后,采用目标检测算法对当前帧进行检测,分别识别人员和香烟;识别出人员后进入步骤二和步骤四,当同时识别出人员和香烟后进入步骤五;未识别出人员时,当前检测结束,开始进行下一帧的识别;
步骤二、采用UNet图像分割算法对当前帧进行处理以检测是否包含危险区域;
步骤三、根据前两步的检测结果,判断人员标签对应的边界框坐标是否被包含在危险区域内,并据此产生预警结果发送到告警平台;
步骤四、采用人体骨骼点检测算法对识别出的人员进行检测,判断是否人员发生摔倒,并据此产生预警结果发送到告警平台;
步骤五、对识别出的人员进一步进行人体部位的检测,识别该人员的脸部和手部,
步骤六、判断香烟对应的边界框位置是否被包含在脸部或手部对应的边界框内部,并据此产生预警结果传至告警平台。
优选的,所述步骤一采用目标检测算法中的YOLOv7算法进行人员检测,检测后再对当前帧的检测结果进行遍历,判断模型检测结果中是否包含人员标签并判断检测结果的置信度是否高于设置的置信度阈值,若不能同时满足,当前检测结束,进行下一帧检测;若同时满足,则进入步骤二和步骤四。
优选的,所述步骤一中,采用训练后的YOLOv7算法对当前帧进行检测以识别香烟,之后对当前帧的检测结果进行遍历,判断结果中是否含有香烟标签,同时判断香烟标签对应的置信度是否高于设定的置信度阈值,若不能同时满足,当前帧抽烟检测结束,进行下一帧检测;若同时满足,则看当前帧对人员的检测结果,如果同时包含人员标签并判断检测结果的置信度高于设置的置信度阈值进入步骤五。
优选的,所述步骤二中,采用UNet图像分割算法对当前帧进行处理,识别危险区域,检测后再对当前帧的检测结果进行遍历,判断当前帧图像分割结果中是否包含危险区域,若结果为否,当前帧危险区域作业检测结束,进行下一帧检测;若结果为是,进入步骤三。
优选的,所述步骤三中,根据目标检测算法和UNet图像分割算法二者的检测结果,判断人员标签对应的边界框坐标是否包含在危险区域内,若结果为否,当前帧危险区域作业检测结束,进行下一帧检测;若结果为是,将结果传至告警平台。
优选的,所述步骤四中,采用人体骨骼点检测算法对识别出的人员进行检测,确定头部骨骼点坐标与腰部骨骼点坐标,再计算头部骨骼点坐标与腰部骨骼点坐标差值是否小于设定阈值,所述阈值根据摔倒检测点位模拟摔倒测试得出,若结果为否,当前检测结束;若结果为是,将结果传至告警平台。
优选的,所述步骤五中,在进行人体部位的检测后,判断当前帧的模型检测结果中是否含有脸部标签或手部标签,同时判断其中是否有与脸部标签或手部标签对应的边界框位置被包含在任一人员标签对应边界框内部;若不能同时满足,当前帧抽烟检测结束,进行下一帧检测;若同时满足,进入步骤六。
优选的,所述步骤六中,判断当前帧检测到的香烟标签对应的边界框位置是否被包含在脸部标签或者手部标签对应的边界框内部;若不能同时满足,当前帧抽烟检测结束,进行下一帧检测;若同时满足,将结果传至告警平台。
优选的,所述步骤六中,若含有多个脸部标签或手部标签,则遍历各个标签,满足任意一个脸部标签或手部标签即可。
优选的,所述危险区域为发运船只上的危险区域,包括发运船只上的盖棚区域和横梁区域。
本发明具有以下优点:本发明通过一套系统即可同时对发运船只上危险区域是否有人员行走、严禁明火区域是否有人员点火吸烟、以及是否发生人员摔倒发生危险等危险动作和状态实现及时可靠的识别。针对危险动作和状态是否发生情况较少,缺少样本训练的问题,本方案首先对人员、香烟、人体部位和危险区域的识别分割,这些主体易于获取样本图片,训练后识别的可靠性好。在识别上述标签并确定相应边界框后,利用整体的检测预警流程,通过对检测结果的处理,筛除一部分由于YOLOV7算法对应小目标检测精度不够高导致的误检数据,从而在不明显提升训练计算量和时间的情况下,保证检测结果可靠,并能将该方法同时用于包括吸烟检测、水泥运输船盖棚/横梁作业检测及人员摔倒等多方面检测,大大减少了采用的模型数量,缩短了检测训练的时间。同时本方案还针对盖棚、横梁对应区域不规则、易变化的特点和人体骨骼点检测目标与常规检测对象有明显差异的特点,分别采用不同的模型进行检测,大大提高了相应标签检测的可靠性和准确性。
附图说明
图1为本发明中一种基于深度学习的危险动作识别方法的基本流程图。
具体实施方式
下面对照附图,通过对实施例的描述,对本发明具体实施方式作进一步详细的说明,以帮助本领域的技术人员对本发明的发明构思、技术方案有更完整、准确和深入的理解。
如图1所示,本发明公开了一种基于深度学习的危险动作识别方法,包括下列步骤:
步骤一、采集图像后,采用目标检测算法对当前帧进行检测以识别人员。
该步骤采用目标检测算法中的YOLOv7算法进行人员检测,检测后再对当前帧的检测结果进行遍历,判断模型检测结果中是否包含person(人员)标签并判断检测结果的置信度是否高于设置的置信度阈值,若不能同时满足,当前检测结束,进行下一帧检测;若同时满足,则进入步骤二。
目标检测算法模型利用TensorRT优化器对模型进行训练后量化再进行部署。TensorRT是一个只有前向传播的深度学习框架,这个框架能将Caffe,TensorFlow,Pytorch等框架的网络模型解析,然后与TensorRT中对应的层进行一一映射,把其他框架的模型统一全部转换到TensorRT中,然后在TensorRT中针对NVIDIA自家的GPU实施优化策略,并进行部署加速。
步骤二、采用UNet图像分割算法对当前帧进行处理以检测是否包含危险区域。
采用UNet图像分割算法对当前帧进行处理,识别危险区域,危险区域包括发运船只的盖棚和横梁。检测后再对当前帧的检测结果进行遍历,判断当前帧图像分割结果中是否包含canopy(盖棚)、beam(横梁)区域,若否,当前帧盖棚作业/横梁作业检测结束,进行下一帧检测;若是,进入步骤三。
对于发运船只(水泥运输船)的盖棚、横梁等危险区域,由于船只停靠位置、角度不固定,目标区域不规则且紧邻安全区域,利用YOLOV7检测容易将安全区域纳入检测框,因此本方法采用UNet图像分割算法。
步骤三、根据目标检测算法和UNet图像分割算法二者前两步的检测结果,判断人员标签对应的边界框坐标是否被包含在危险区域内,并据此产生预警结果发送到告警平台。
根据目标检测算法和UNet图像分割算法二者的检测结果,判断person标签对应的边界框坐标是否包含在canopy(盖棚)或beam(横梁)区域内,若否,当前帧盖棚作业/横梁作业检测结束,进行下一帧检测;若是,将结果传至告警平台。
本方法通过YOLOv7算法进行人员检测的结果还能用于对人员是否摔倒进行检测。当步骤一的结果为同时满足模型检测结果中包含person(人员)标签并判断检测结果的置信度高于设置的置信度阈值,还能进入步骤四。
步骤四、采用人体骨骼点检测算法对识别出的人员进行检测,确定头部骨骼点坐标与腰部骨骼点坐标,再计算头部骨骼点坐标与腰部骨骼点坐标差值是否小于设定阈值(阈值根据摔倒检测点位模拟摔倒测试得出),若否,当前检测结束;若是,将结果传至告警平台。
所述步骤一进行时,本方案还能同时进行对香烟的检测,采用训练后的YOLOv7算法对当前帧进行检测以识别香烟,与对人员的检测分别进行。
该步骤中,对当前帧的检测结果进行遍历,判断结果中是否含有cigarette(香烟)标签,同时判断cigarette标签对应的置信度是否高于设定的置信度阈值,若不能同时满足,当前帧抽烟检测结束,进行下一帧检测;若同时满足,则看当前帧对人员的检测结果,如果同时包含person(人员)标签并判断检测结果的置信度高于设置的置信度阈值进入步骤五。
步骤五、针对步骤一中检测到的人员进一步进行人体部位的检测,判断当前帧的模型检测结果中是否含有face(脸部)标签或hand(手部)标签,同时判断其中是否有face标签或hand标签对应的边界框位置被包含在任一person(一张图可能多个person标签)标签对应边界框内部;若不能同时满足,当前帧抽烟检测结束,进行下一帧检测;若同时满足,进入步骤六。
步骤六、判断当前帧检测到的cigarette标签对应的边界框位置是否被包含在face标签或者hand标签对应的边界框内部(若含有多个face,hand标签,则遍历,满足一个即可);若不能同时满足,当前帧抽烟检测结束,进行下一帧检测;若同时满足,将结果传至告警平台。
针对上述具体的危险情况进行训练时,存在样本图片数据量小,训练后检测算法精度不够高等因素,本文提出的危险动作识别方法包括视觉算法检测及检测结果处理两部分,通过检测结果处理,筛除一部分由于YOLOV7算法对应小目标检测精度不够高导致的误检数据。
应用上述方法的系统利用现场安装的高清相机作为输入设备,通过边缘计算盒子中的算法模型服务进行检测,并配合可视化界面、数据转发、数据存储策略,构成一整套以深度学习为中心的水泥发运人员安全监测系统。
输入设备层即系统的感知层,主体为前端的视觉传感器,该层负责获取系统所需的实时图像数据、视频流数据等。具体的设备类型可在系统前端设置,以实现数据抓取模块的适配及设备的正确接入。
边缘计算盒子中算法服务模块为本系统核心技术方案的实现主体,其主要功能是承载训练出来算法模型,对视觉传感器输出的实时图像经过深度学习检测及逻辑判断后,返回运算结果。
前端显示模块主要包括两个方面的功能,一是配置功能,一是显示功能。配置功能主要为用户提供系统参数配置的能力,主要包括设备配置、场景配置、算法配置、第三方接口配置以及数据管理配置等;显示功能包括现场视频播放功能、告警展示功能、日志展示功能、系统状态显示以及统计信息展示功能。
管理后台需要为前端的配置功能及展示功能提供后台能力支撑。主要体现在,需要为配置信息提供访问接口及数据结构化存储,也需要为展示信息提供必要的请求接口,同时,对于系统产生的运行数据,如数据库记录、存储的图片数据、视频数据、日志以及操作数据等进行归档管理,并自动删除过期数据以释放存储资源。其中,场景管理是该系统的核心功能之一,其主要功能是允许用户根据逻辑关系或者位置关系等建立场景,在所建场景中添加设备,并为其配置相应的业务,以实现设备与算法的绑定;第三方接口配置功能则可通过配置第三方接口地址,实现系统信息的对外推送,使得系统具备与第三方系统的通信能力,从而满足信息融合的需求,避免信息孤岛,为客户的安全生产及日常管理提供支撑和依据。
上面结合附图对本发明进行了示例性描述,显然本发明具体实现并不受上述方式的限制,只要采用了本发明的发明构思和技术方案进行的各种非实质性的改进,或未经改进将本发明构思和技术方案直接应用于其它场合的,均在本发明保护范围之内。