一种FPGA卷积加速器的资源占用率优化方法
文献发布时间:2023-06-19 19:35:22
技术领域
本发明属于硬件加速器技术领域,具体是对FPGA加速器中的卷积计算单元进行优化,使其资源占用率更低的方法,具体涉及到一种FPGA卷积加速器的资源占用率优化方法。
背景技术
近年来,随着神经网络和图像处理技术的发展,在硬件平台上执行卷积计算的需求大幅增加,硬件平台需要进行大量的乘累加运算以实现该功能。现场可编程门阵列(FPGA)由于其灵活性和能耗,已经成为卷积计算硬件加速的主要平台。当在FPGA上实现卷积处理单元时,供应商提供了专用的数字信号处理(DSP)单元以实现快速乘法器,但它们的位置固定以及数量有限。因此,当处理乘法器密集型应用时,需要另外设计乘法器以保证性能。
为了提升卷积硬件加速器的性能,国内外开展了大量的研究工作。其中,针对乘法器和加法器本身的性能优化,采用设计近似计算来提高性能和能效,代价是损失一定精度。与精确乘法器相比,尽管节省了硬件资源,但现有的精度损失将不可避免地降低其在应用中的性能。此外,如果采用针对卷积计算采用特殊的算法,如Winograd卷积加速算法,可以减少乘法的次数,但是这种方法增加了加法次数。同时,这类方法必须满足输入数据顺序的要求,不仅可能导致额外的延迟,并且对FPGA上的存储资源提出了挑战。需要注意的是,当前的FPGA卷积加速器设计大多考虑移植到专用集成电路(ASIC)的实现,忽略了FPGA和ASIC平台之间固有的架构差异,当直接在FPGA上部署时,这些方法的性能将受到限制。因此,针对上述问题,设计一种基于FPGA精确乘法器的、性能与近似乘法器相当的卷积处理单元,对于FPGA卷积加速器具有相当重要的工程意义。
发明内容
现有FPGA卷积处理单元主要考虑可移植至ASIC进行设计,忽略了固有的架构差异。同时,由于当前设计大多采用近似计算或特殊的卷积算法,在性能上存在各种限制,因此,针对基于FPGA的卷积处理单元的设计存在大量的优化空间。针对以上问题,本发明提出一种仅面向FPGA平台上卷积处理单元的设计方法,目的是让卷积处理单元能够充分使用FPGA平台上的可配置逻辑块,发挥FPGA平台的特殊优势,使其在使用精确乘法器的情况下性能达到与使用近似乘法器达到相当的性能,并且不存在特殊的输入数据顺序的要求,不占用额外的存储空间。
本发明的技术方案:
一种FPGA卷积加速器的资源占用率优化方法,具体步骤如下:
步骤1:使用符号位拓展方法设计基4booth乘法器:
步骤1.1:根据乘数的位数n,设计n/2个基4booth编码器,每个基4booth编码器将乘数的第2i+1位、第2i位以及第2i-1位作为操作数,只使用移位和取反的方式对另一个乘数进行编码,输出部分积;其中,i为基4booth编码器的序号,i=0,…,n/2-1;
步骤1.2:按照步骤1.1,从i=0开始,将一个位宽为n的乘数分解成n/2个操作数,输出n/2个部分积;若2i-1<0,该位填充0;
步骤1.3:使用符号位拓展方法,对所有部分积执行如下操作:首先将每个部分积的最低位加上对应操作数的最高位;其次将每个部分积的符号位取反;然后对第一个部分积的最高位加1;接下来在所有部分积的最高位前增加一个比特数1;最后将所有部分积合并到一个Wallace树中;
步骤1.4:对于上述Wallace树,在每一位中,以每3个加数为一组,压缩成当前位和下一位的两个数,直到每一位的剩余加数都小于3,相加得到乘法的结果;
步骤2:基于FPGA的基本单元可配置逻辑块对上述基4booth乘法器进行优化,分为基于LUT优化与基于进位链优化两个方面;
步骤2.1:基于LUT优化,在每一位中,如果加数总和大于或等于5,每满5个加数就压缩到3个加数,包括一个当前位和两个进位;如果加数总和小于5,则按照Wallace树的方法压缩加数,将3个加数压缩成1个当前位和1个进位,循环往复,直到每一位的加数都小于3;
步骤2.2:基于进位链优化,使用进位链代替LUT用于Wallace树的压缩;以Wallace树中添加的各个操作数的最高位作为进位链携带的进位进行压缩,每个进位链的使用需要满足两个8比特数携带一个进位压缩成一个9比特数,循环往复,直到每一位的加数小于3,求和;
步骤3:使用优化后的乘法器,设计基于合并部分积方法的卷积处理单元;
步骤3.1:首先确定卷积处理单元需要的乘法数m,使用m×n/2个编码器为所有的乘法生成部分积,对不同的乘法分别执行步骤1.3,生成m个Wallace树;
步骤3.2:将m个Wallace树的内容合并到1个Wallace树下,提前计算好已确定的数据加法,即在m个Wallace树中第一个部分积最高位的1以及所有部分积的最高位前增加的比特数1;
步骤3.3:执行步骤2,基于LUT或进位链压缩合并后的Wallace树,以实现在节约大量硬件资源的情况下得到卷积计算的结果。
本发明的有益效果:本发明首先针对卷积加速器中的基4booth乘法器在基于查找表(LUT)和进位链两个方面进行可配置逻辑块层面的优化,以减少实现单个乘法器需要的LUT资源。然后,根据优化的乘法器设计一种合并部分积的方法,忽略中间结果进行乘加,进一步节约LUT资源。与传统方法相比,本发明在无精度损失的前提下,性能与使用近似乘法器的设计相当。同时能够满足在DSP单元紧缺,需要另外设计部署乘法器的情况下,在FPGA上大量部署卷积处理单元的需求。
附图说明
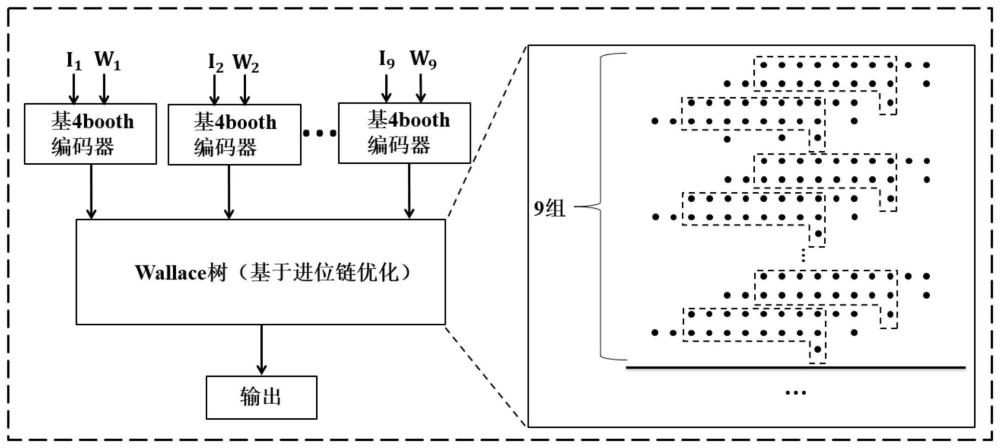
图1是本发明中设计的3×3卷积处理单元结构示意图,基于进位链优化,其中W
图2是本发明中基4booth8×8乘法的结构示意图,其中A和B为乘法的乘数,PP代表生成的部分积,B
图3是本发明中使用8×8乘法器的基于进位链优化Wallace树的算法示意,虚线框表示使用进位链进行计算,总计使用5个进位链完成一个乘法器。
具体实施方式
下面结合附图和具体实施例对本发明作进一步的说明,使用8×8乘法器完成3×3卷积处理单元的设计,基于进位链进行优化。
步骤1:设计8×8基4booth乘法器:
步骤1.1:乘数的位数为8,因此设计4个基4booth编码器,每个基4booth编码器可以将乘数的第2i+1位,第2i位以及第2i-1位作为操作数,只使用移位和取反的方式对另一个乘数进行编码,输出部分积,其中,i为基4booth编码器的序号,i=0,1,2,3。硬件编码方式如表1所示。
步骤1.2:按照步骤1.1,从i=0开始,第-1位填充为0,将8位的乘数分解成4个操作数,输出4个部分积。
步骤1.3:使用符号位拓展方法,对所有部分积执行如下操作:首先将每个部分积的最低位加上对应操作数的最高位;其次将每个部分积的符号位取反;然后对第一个部分积的最高位加1;接下来在所有部分积的最高位前增加一个比特数1;最后将所有部分积合并到一个Wallace树中。生成的Wallace树如图2下方所示。
步骤1.4:对于上述Wallace树,在每一位中,以每3个加数为一组,压缩成当前位和下一位的两个数,直到每一位的剩余加数都小于3,相加得到乘法的结果,基4booth乘法器的结构如图2所示。
步骤2:基于FPGA的基本单元可配置逻辑块对上述基4booth乘法器进行进位链优化。
步骤2.1:基于进位链优化,使用进位链代替LUT用于Wallace树的压缩。以Wallace树中添加的各个操作数的最高位作为进位链携带的进位进行压缩,每个进位链的使用需要满足两个8比特数携带一个进位压缩成一个9比特数,循环往复,直到每一位的加数小于3,求和。对单个8×8基4booth乘法器生成的Wallace树的压缩方法如图3所示。
步骤3:使用优化后的乘法器,设计基于合并部分积的卷积处理单元,大小为3×3,卷积处理单元的结构如图1所示。
步骤3.1:使用36个基4booth编码器为9个需要的乘法生成部分积,对不同的乘法分别执行步骤1.3,生成9个Wallace树。
步骤3.2:将9个Wallace树的内容合并到1个Wallace树下,提前计算好已确定的数据加法,同一位中的9个1提前计算为二进制下的1001。
步骤3.3:执行步骤2,基于进位链压缩合并后的Wallace树,不计算中间结果,在大量节约硬件资源的情况下得到卷积计算的结果。使用本发明实现的3×3卷积计算单元最终结果与对比如表2所示。
综上所述可见:本发明提出的一种基于FPGA的卷积处理单元的优化设计方法,整个方法主要包括基于FPGA平台的基本单元可配置逻辑块对基4booth乘法器进行优化以及使用优化后的乘法器,设计基于合并部分积的卷积处理单元两个部分。其中优化后的乘法器可以在性能上达到与近似乘法器接近,基于合并部分积的卷积处理单元可以进一步减少对于FPGA上的LUT资源。
表1基4booth编码器的硬件编码方式,其中S代表A的符号位,B
表2使用本发明中的方法设计3×3的卷积处理单元的结果以及该方法与使用其他方法设计相同功能的卷积处理单元结果的对比,数据位宽为8。