信息处理装置以及对信息处理装置进行控制的方法
文献发布时间:2023-06-29 06:30:04
本申请享受以日本特许申请2021-201065号(申请日:2021年12月10日)为基础申请的优先权。本申请通过参照该基础申请而包含基础申请的全部内容。
技术领域
本实施方式涉及信息处理装置以及对信息处理装置进行控制的方法。
背景技术
以往以来,具有进行如下信息处理的装置或者方法,该信息处理为针对作为输入数据的查询来搜索相似的数据,并输出其结果。在这样的装置或者方法中,对于查询要求到输出结果为止的信息处理涉及的查询响应速度和搜索精度。作为用于兼顾查询响应速度和搜索精度的近邻搜索的算法,已知使用了多个异构(heterogeneous)存储器的近似最近邻搜索(Approximate Nearest Neighbor Search:ANNS)算法。
然而,根据现有的使用了多个异构存储器的近似最近邻搜索的算法,关于查询响应速度具有提高的余地。
发明内容
一个实施方式的目的在于提供提高了查询响应速度的信息处理装置以及对信息处理装置进行控制的方法。
根据一个实施方式,信息处理装置具备第1存储器、第2存储器以及处理器。所述第1存储器保存多个第1数据,所述多个第1数据分别被基于第1数据间的距离而群集化为包括一个以上的第1数据的多个群集。所述第2存储器保存分别与多个群集中的一个群集一对一地对应的多个第2数据,能够进行比所述第1存储器高速的动作。所述多个第2数据分别为对所述多个群集中的所对应的一个群集进行代表的数据。所述处理器受理查询的输入,从所述多个第2数据中确定作为最接近所述查询的第2数据的第3数据。并且,所述处理器从所述第1存储器一并读取所述多个群集中的与所述第3数据对应的群集所包含的一个以上的第1数据,从所读取到的所述一个以上的第1数据中确定作为最接近所述查询的第1数据的第4数据。并且,所述处理器输出所述第4数据。
附图说明
图1是表示实施方式涉及的信息处理装置的硬件结构的一个例子的示意图。
图2是表示实施方式涉及的SSD的使用例的示意图。
图3是用于对实施方式涉及的处理器执行的近邻搜索进行说明的示意图。
图4是表示实施方式涉及的DRAM的使用例的示意图。
图5是表示实施方式涉及的代表数据以及数据的配置方法的一个例子的示意图。
图6是表示实施方式涉及的信息处理装置执行的将数据保存于SSD的步骤的一个例子的流程图。
图7是表示实施方式涉及的信息处理装置执行的近邻搜索的步骤的一个例子的流程图。
图8是用于对实施方式的变形例涉及的群集化的方法进行说明的示意图。
图9是表示实施方式的变形例涉及的数据的配置方法的一个例子的示意图。
标号说明
1信息处理装置;2处理器;3SSD;4DRAM;5总线;31图解(graph)信息;32搜索程序;33配置程序;41工作区域;ADR地址;S尺寸;CL群集(cluster);D数据;RD代表数据。
具体实施方式
实施方式涉及的近邻搜索例如由具备处理器、第1存储器以及第2存储器的信息处理装置来执行。第1存储器是具有比第2存储器大的容量的存储器。第2存储器是能够进行比第1存储器高速的动作的存储器。在以下中,对在具备SSD(Solid State Drive,固态硬盘驱动器)来作为第1存储器、具备DRAM(Dynamic Random Access Memory,动态随机访问存储器)来作为第2存储器的计算机中实施实施方式涉及的近邻搜索的例子进行说明。
此外,实施方式涉及的近邻搜索也可以通过由网络相互连接了的两个以上的信息处理装置的协作来执行。另外,实施方式涉及的近邻搜索也可以在具备NAND型闪速存储器的存储芯片等的储存介质来作为第1存储器、具备DRAM来作为第2存储器、并具备处理器的存储装置中执行。
以下参照附图对实施方式涉及的信息处理装置以及方法进行详细的说明。此外,并不是通过该实施方式限定本发明。
(实施方式)
图1是表示实施方式涉及的信息处理装置的硬件结构的一个例子的示意图。
信息处理装置1是具备处理器2、作为第1存储器的一个例子的SSD3、作为第2存储器的一个例子的DRAM4以及将这些部件电连接的总线5的计算机。此外,第1存储器和第2存储器不限定于这些。例如第1存储器也可以是任意的储存存储器。第1存储器也可以是UFS(Universal Flash Storage,通用闪速储存器)设备、磁盘装置。
处理器2按照计算机程序执行预定运算。处理器2例如为CPU(Central ProcessingUnit,中央处理单元)。当对信息处理装置1输入作为输入数据的查询时,处理器2利用SSD3和DRAM4,执行基于所输入的查询的预定运算。
SSD3是具有大容量的储存存储器。SSD3具备NAND型闪速存储器来作为储存介质。
DRAM4的容量比SSD3小,但能够进行比SSD3高速的动作。
此外,信息处理装置1可以连接任意的输入输出设备。输入输出设备例如为输入装置、显示装置、网络设备或者打印机等。
图2是表示实施方式涉及的SSD3的使用例的示意图。
在SSD3中保存有多个数据D。各数据D的种类不限定于特定种类。各数据D是图像、文档或者这些以外的任意种类的信息。各数据D的尺寸(size)在全部数据D中被设为是通用(共同)的。多个数据D可以被作为近邻搜索的对象。
当对信息处理装置1输入作为输入数据的查询时,处理器2从保存于SSD3的多个数据D中搜索到所输入的查询为止的距离最近的数据D。
在本说明书中,距离是表示数据间的相似度的尺度。距离在数学上例如为欧几里德距离。此外,距离的数学上的定义不限定于欧几里德距离。
此外,处理器2也可以在近邻搜索中对最接近查询的多个数据D进行搜索。
多个数据D构成图解。在本说明书中,图解是具有用边缘将多个节点间连接而得到的构造的数据。在该情况下,各数据D相当于节点。对节点间的连接关系进行规定的图解信息31通过设计者或者预定的计算机程序来预先生成。图解信息31被保存于SSD3。
另外,在SSD3中保存有搜索程序32和配置程序33。搜索程序32是使处理器2执行近邻搜索的计算机程序。配置程序33是使处理器2执行数据D等的配置的计算机程序。处理器2将保存于SSD3的搜索程序32和配置程序33加载到DRAM4来加以执行。关于依照了配置程序33的数据D等的配置方法,将在后面进行描述。
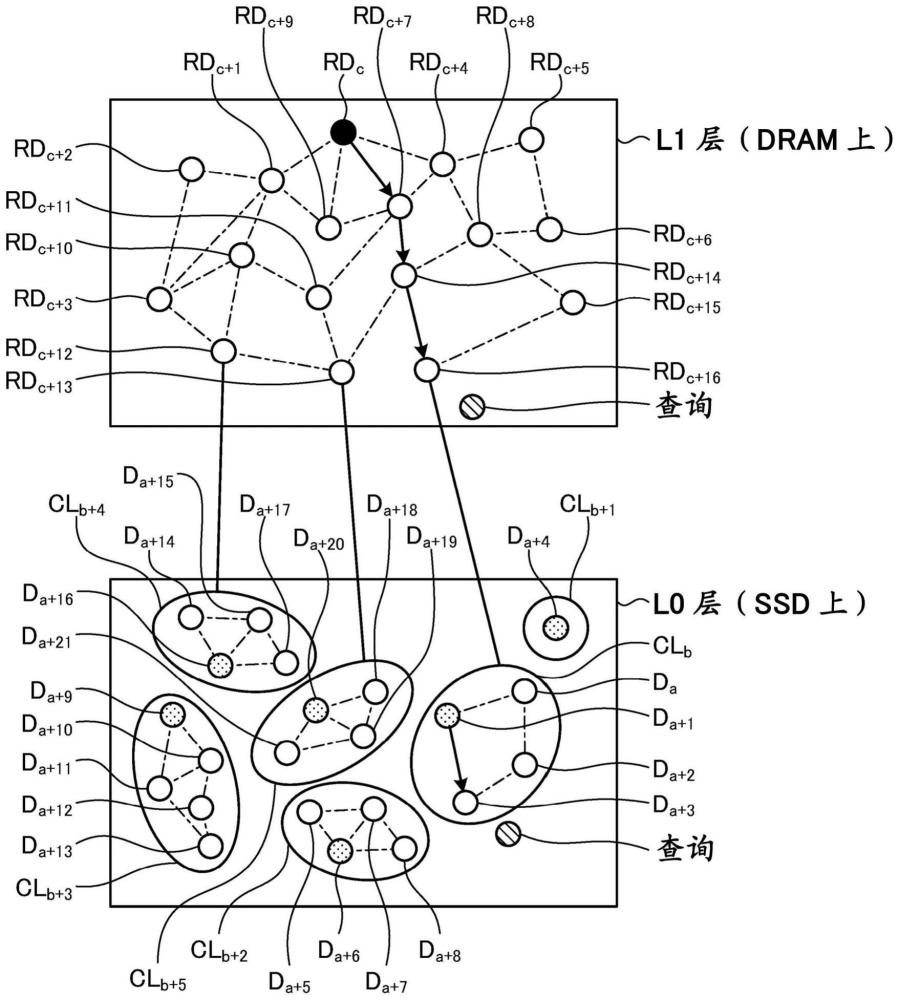
图3是用于对实施方式涉及的处理器2执行的近邻搜索进行说明的示意图。
在实施方式中,被进行搜索的空间被分层为多个层。在此,作为一个例子,被进行搜索的空间包括L0层和L1层这两个层。
L0层是保存于SSD3的数据D分布的空间。保存于SSD3的数据D中的彼此的距离近的两个以上的数据D构成一个群集CL。由此,L0层包括多个群集CL。也即是,构成L0层的多个数据D基于数据D间的距离而被群集化为多个群集CL。对于群集化,只要是基于数据D间的距离来执行,则可以通过任意方法来执行。例如,也可以将L0层的空间划分为格子状,各格子内的数据D的数据集被设定为一个群集CL。由此,能够将彼此的距离近的两个以上的数据D分类为一个群集CL。
构成各群集CL的数据D的数量既可以在全部群集CL中是通用的,也可以不是通用的。另外,也可以存在由一个数据D构成的群集CL。
在图3中描绘了数据D
构成各群集CL的数据D的数据集构成图解。在图3中,L0层内的单点划线表示将数据D间连接的边缘。由被添加了点阴影线的圆表示的数据D
根据各群集CL计算代表数据RD,该代表数据RD是对属于该群集的数据D的数据集进行代表的数据。以后,将成为了某代表数据RD的计算基础的群集CL记载为与该代表数据RD对应的群集CL。
代表数据RD的计算方法不限定于特定方法。在一个例子中,代表数据RD也可以是通过任意的方法来从构成所对应的群集CL的数据D的数据集中选择出的数据D。例如,构成群集CL的数据D的数据集中的最靠近该群集CL的中心的数据D可以被设为该群集CL的代表数据RD。或者,代表数据RD也可以是通过使用了构成所对应的群集CL的数据D的数据集的任意算术运算来计算出的数据。例如,构成群集CL的数据D的数据集的平均可以被设为该群集CL的代表数据RD。各群集CL的代表数据RD既可以由处理器2进行计算,也可以由设计者等预先进行计算。此外,各代表数据RD的尺寸在全部群集CL的代表数据RD各自中被设为是通用的。
全部群集CL的各个代表数据RD构成L1层。
在图3中描述了代表数据RD
L1层内的代表数据RD的数据集构成图解。在图3中,L1层内的单点划线表示将代表数据RD间连接的边缘。由被实施了涂黑的圆表示的代表数据RD
全部群集CL量的代表数据RD被保存在DRAM4内。并且,处理器2在被输入了查询的情况下,首先,在L1层中按照图解进行近邻搜索。对DRAM4的访问速度比对SSD3的访问速度高。由此,在L1层中执行的近邻搜索被高速地执行。
例如,处理器2首先选择作为入口点的代表数据RD
此外,在图解中,将新选择由边缘连接于选择中的某节点的其他节点记载为跳跃(hop)。
处理器2在确定了最接近查询的代表数据RD之后,从SSD3一并读取构成与最接近查询的代表数据RD对应的群集CL的数据D的数据集,并将其保存于DRAM4。然后,处理器2通过对保存于DRAM4的数据D的数据集进行基于图解的近邻搜索,取得最接近查询的数据D。然后,处理器2输出所被确定了的数据D来作为对于查询的响应。
在图3所示的例子中,在被输入了查询的情况下,处理器2将代表数据RD
对与实施方式比较的技术进行说明。将与实施方式比较的技术记载为比较例。根据比较例,由L0层内的几个数据构成L1层。由L0层内的全部数据构成一个图解,由L1层内的全部数据构成一个图解。L0层内的全部数据被保存于SSD等的储存存储器。L1层内的全部数据被保存于能够进行比DRAM等的储存存储器高速的动作的存储器。在被输入了查询的情况下,在L1层中进行基于图解的近邻搜索。然后,当在L1层中确定最接近查询的数据后,将所确定的数据作为L0层中的入口点,进行基于图解的近邻搜索。
根据比较例,在L0层中的近邻搜索时,按跳跃而产生对储存存储器的访问。具体而言,按跳跃而执行从储存存储器读取由边缘连接于选择中的数据的全部数据的处理。由此,跳跃的次数越多,查询响应需要越多时间。
与此相对,根据实施方式,在L0层中的近邻搜索时,构成最接近查询的群集CL的全部数据D被一并进行读取。并且,通过仅使用了所读取到的数据D的近邻搜索,确定最接近查询的数据。由此,根据实施方式,与比较例相比,能抑制对储存存储器的访问所需要的时间,能缩短查询响应所需要的时间。即,查询响应的速度提高。
图4是表示实施方式涉及的DRAM4的使用例的示意图。
在DRAM4中保存有全部代表数据RD。
另外,在DRAM4设置有处理器2的工作区域41。在工作区域41中加载各种程序(配置程序33或者搜索程序32),对图解信息31进行缓存,暂时性地保存构成通过L1层中的近邻搜索确定的群集CL的数据D的数据集。
图5是表示实施方式涉及的代表数据RD以及数据D的配置方法的一个例子的示意图。在本图中描述了DRAM4的地址空间和SSD3的地址空间。DRAM4的地址空间是由能够在处理器2访问DRAM4时进行指定的地址的范围确定的空间。SSD3的地址空间是由能够在处理器2访问SSD3时进行指定的地址的范围确定的空间。
构成各群集CL的数据D的数据集被配置在SSD3的地址空间内的连续的区域中。也就是说,构成一个群集CL的数据D的数据集不被配置在相互分离了的两个以上的区域。处理器2例如对于构成所希望的群集CL的数据D的数据集(对象集),向SSD3发送包含配置了对象集的区域的开头地址和对象集尺寸的一个读取命令。由此,处理器2能够通过一个读取命令,从SSD3取得对象集。也即是,处理器2只是对SSD3进行一次读取,就能够取得L0层中的近邻搜索所需要的全部数据D。
DRAM4内的各代表数据RD被与表示区域的开头的地址ADR和该区域的尺寸S相关联地配置在DRAM4的地址空间中,所述区域是配置有构成所对应的群集CL的数据D的数据集的区域。由此,处理器2能够基于代表数据RD,确定配置了构成与该代表数据RD对应的群集CL的数据D的数据集的区域。
在图5所示的例子中,群集CL
另外,群集CL
另外,群集CL
此外,在构成各群集CL的数据D的数量在全部群集CL中通用的情况下,能够从与各代表数据RD关联的信息中省略尺寸S。在那样的情况下,处理器2在从SSD3读取构成所希望的群集CL的数据D的数据集时,指定被固定的尺寸。
图6是表示实施方式涉及的信息处理装置1执行的将数据D保存于SSD3的步骤的一个例子的流程图。本图所示的一系列动作通过处理器2执行配置程序33来实现。此外,也可以不是处理器2而是设计者执行该一系列动作中的一部分或者全部。
对信息处理装置1输入多个数据D(S101)。于是,处理器2基于数据D间的距离,将该多个数据D群集化为多个群集CL(S102)。
接着,处理器2将各群集CL配置于SSD3(S103)。在S103中,处理器2如使用图5说明过的那样将构成各群集CL的数据D的数据集配置在SSD3的地址空间中的连续的区域。例如,处理器2通过向SSD3发送指定了各群集CL的配置目的地的区域的写入命令,进行各群集CL的配置。
进一步,处理器2按群集CL而计算代表数据RD(S104)。然后,处理器2将各代表数据RD与配置了所对应的群集的SSD3的地址空间中的区域的开头地址以及该区域的尺寸相关联地配置于DRAM4(S105)。
然后,处理器2生成L0层中的图解和L1层中的图解(S106)。处理器2将所生成的图解的构造描述为图解信息31,将该图解信息31保存于SSD3(S107)。
在S107之后,将数据D保存于SSD3的处理完成。
此外,在已经在SSD3中保存有多个数据D的状态下被输入了新的数据D的情况下,处理器2再次执行S102以后的处理。在再次执行S102以后的处理时,处理器2可以针对对新输入的数据D添加已经保存于SSD3的数据D而得到的全部数据D执行各处理。或者,处理器2也可以仅针对对新输入的数据D添加该新输入的数据D附近的群集CL而得到的数据D执行各处理。
此外,上述描述过的一系列步骤是一个例子。只要如图5所示那样配置数据D和代表数据RD,将数据D保存于SSD3的步骤就不限定于上述例子。
图7是表示实施方式涉及的信息处理装置1执行的近邻搜索的步骤的一个例子的流程图。本图所示的一系列动作通过处理器2执行搜索程序32来实现。
对信息处理装置1输入查询(S201)。于是,处理器2通过S202~S206的处理,确定在L1层中最接近查询的代表数据RD。
具体而言,处理器2从DRAM4取得入口点的代表数据RD,并设定为对象代表数据RD(S202)。处理器2从DRAM4取得由边缘连接于对象代表数据RD的全部代表数据RD(S203)。处理器2计算从对象代表数据RD和由边缘连接于对象代表数据RD的全部代表数据RD各自到查询为止的距离(S204)。处理器2将到查询为止的距离最近的代表数据RD设定为对象代表数据RD(S205)。通过S203~S205的处理,完成L1层中的一次跳跃。
接着S205,处理器2判定当前的对象代表数据RD是否在全部代表数据RD中最接近查询(S206)。S206的判定方法不限定于特定方法。例如,在最后执行的S203~S205的处理中对象代表数据RD未被变更的情况下,能够推定为当前的对象代表数据RD在全部代表数据RD中最接近查询。由此,在最后执行的S203~S205的处理中对象代表数据RD未被变更的情况下,处理器2判定为当前的对象代表数据RD在全部代表数据RD中最接近查询。在最后执行的S203~S205的处理中对象代表数据RD被进行了变更的情况下,处理器2不判定为当前的对象代表数据RD最接近查询。
在未判定为当前的对象代表数据RD在全部代表数据RD中最接近查询的情况下(S206:否),处理器2再次执行S203~S206的处理。
在判定为当前的对象代表数据RD在全部代表数据RD中最接近查询的情况下(S206:是),处理器2确定保存有构成与当前的对象代表数据RD对应的群集的数据D的数据集的区域(S207)。在S207中,处理器2通过从DRAM4取得与当前的对象代表数据RD相关联的地址ADR和尺寸S,确定保存有构成与当前的对象代表数据RD对应的群集的数据D的数据集的区域。
处理器2向SSD3发送指定了所确定的区域的读取命令(S208)。然后,处理器2将SSD3相应于读取命令而输出的数据D的数据集保存于工作区域41(S209)。然后,通过S210~S214的处理,执行在L0层中确定最接近查询的数据D的近邻搜索。
具体而言,处理器2取得保存于工作区域41的数据D的数据集中的入口点的数据,并设定为对象数据(S210)。然后,处理器2从工作区域41取得由边缘连接于对象数据D的全部数据D(S211)。处理器2取得从对象数据D和由边缘连接于对象数据D的全部数据D各自到查询为止的距离(S212)。处理器2将到查询为止的距离最近的数据D设定为对象数据D(S213)。通过S211~S213的处理,完成L0层中的近邻搜索的一次跳跃。
接着S213,处理器2判定当前的对象数据D是否在保存于工作区域41的数据D的数据集、换言之构成与最接近查询的代表数据RD对应的群集CL的数据D的数据集中最接近查询(S214)。S214的判定方法不限定于特定方法。例如在最后执行的S211~S213的处理中对象数据D未被变更的情况下,能够推定为当前的对象数据D在保存于工作区域41的数据D的集中最接近查询。由此,在最后执行的S211~S213的处理中对象数据D未被变更的情况下,处理器2判定为当前的对象数据D在保存于工作区域41的数据D的集中最接近查询。在最后执行的S211~S213的处理中对象数据D被进行了变更的情况下,处理器2不判定为当前的对象数据D最接近查询。
在未判定为当前的对象数据D在保存于工作区域41的数据D的集中最接近查询的情况下(S214:否),处理器2再次执行S211~S214的处理。
在判定为当前的对象数据D在保存于工作区域41的数据D的集中最接近查询的情况下(S214:是),处理器2输出当前的对象数据D来作为查询响应(S215)。然后,近邻搜索的一系列动作结束。
此外,输出查询响应的方式是任意的。处理器2也可以生成记载了查询响应的数据并将其保存于预定存储器(例如SSD3)。在信息处理装置1连接有打印机或者显示装置的情况下,处理器2也可以向打印机或者显示装置输出查询响应。在信息处理装置1连接于网络的情况下,处理器2也可以经由该网络向其他计算机输出查询响应。
在以上的说明中,处理器2分别在L1层内和与最接近查询的代表数据RD对应的群集CL内进行了基于图解的近邻搜索。处理器2也可以在L1层内和与最接近查询的代表数据RD对应的群集CL内的一方或者两方中通过不使用图解的任意方法来进行近邻搜索。
例如,处理器2也可以通过计算L1层内的全部代表数据RD与查询之间的距离,从L1层内的全部代表数据RD确定最接近查询的代表数据RD。同样地,处理器2也可以通过计算构成与最接近查询的代表数据RD对应的群集CL的全部数据D与查询之间的距离,确定最接近查询的数据D。
如以上描述的那样,根据实施方式,在SSD3中保存有基于数据D间的距离而被群集化为多个群集CL的多个数据D。在DRAM4中保存有分别与多个群集CL中的一个群集一对一地对应的多个代表数据RD。各代表数据RD是对构成所对应的群集CL的数据D的数据集进行代表的数据。处理器2当受理查询的输入时,从多个代表数据RD中确定最接近所被输入的查询的代表数据RD。然后,处理器2从SSD3一并读取构成与所确定的代表数据RD对应的群集CL的数据D的数据集。然后,处理器2从所读取到的数据D的数据集中确定最接近查询的数据D,输出所确定的数据D来作为查询响应。
由于从SSD3一并读取在L0层内的近邻搜索中所需要的数据D,因此,与需要按跳跃而从SSD读取数据的比较例相比,查询响应所需要的时间被缩短。也即是,根据实施方式,查询响应的速度提高。
另外,根据实施方式,多个群集CL各自配置在SSD3的地址空间连续的区域中。
由此,处理器2能够通过一个读取命令取得所需要的数据D的数据集。
另外,根据实施方式,各个代表数据RD被与配置了所对应的群集CL的区域的开头的地址相关联地保存于DRAM4。处理器2取得与确定为最接近查询的代表数据RD的代表数据RD相关联的地址,向SSD3发送指定了所取得的地址的读取命令。
另外,各个代表数据RD是从构成所对应的群集CL的数据D的数据集计算出的数据。
(变形例)
在以上的说明中设为各数据D仅属于一个群集CL来进行了说明。各数据D也可以属于2个以上的群集CL。
图8是用于对实施方式的变形例涉及的群集化的方法进行说明的示意图。
在图8中描述了数据D
数据D
此外,也可以容许一个数据D属于3个以上的群集CL。
在多个群集CL被设定为一个数据D属于两个以上的群集CL的情况下,在SSD3的地址空间中例如如图9所示那样配置数据D。图9是表示实施方式的变形例涉及的数据D的配置方法的示意图。
在图9所示的例子中,数据D
在图9所示的例子中,数据D
如以上描述的那样,保存于SSD3的多个数据D也可以包括属于某群集CL和其他群集CL这两方的数据D。
如在实施方式以及实施方式的变形例中描述的那样,进行近邻搜索的空间被分层为2层,其中的1层被配置在作为第1存储器的SSD3,另一层被配置在作为第2存储器的DRAM4。具体而言,在作为第1存储器的SSD3中保存有基于数据D间的距离而被群集化为多个群集CL的多个数据D。在作为第2存储器的DRAM4中保存有分别与多个群集CL中的一个群集一对一地对应的多个代表数据RD。各代表数据RD是对构成所对应的群集CL的数据D的数据集进行代表的数据。
由此,处理器2能够从配置于SSD3的层一并读取所需要的数据D的数据集。因此,根据实施方式以及实施方式的变形例,与比较例相比,查询响应的速度提高。作为第1存储器的SSD3和作为第2存储器的DRAM4连接于总线5。至少具备SSD3、DRAM4以及总线5的装置(第1装置)也可以作为与至少具备处理器2的装置(第2装置)不同的装置来构成。第1装置和第2装置经由预定的接口和电路而相连接。
此外,进行近邻搜索的空间也可以被分层为3个以上的层。例如,也可以是3个以上的层中的最上层被配置在作为第2存储器的DRAM4,3个以上的层中的其他全部层被配置在作为第2存储器的SSD3。
以上对本发明的几个实施方式进行了说明,但这些实施方式是作为例子提示的,并不是意在限定发明的范围。这些新的实施方式能够以其他各种各样的方式来实施,能够在不脱离发明的宗旨的范围内进行各种省略、置换、变更。这些实施方式及其变形包含在发明的范围、宗旨内,并且,包含在权利要求书记载的发明及其等同的范围内。