翻译质量评估方法、电子设备、芯片及可读存储介质
文献发布时间:2024-01-17 01:18:42
技术领域
本申请涉及软件技术领域,尤其涉及一种翻译质量评估方法、电子设备、芯片及计算机可读存储介质。
背景技术
机器翻译是目前翻译工作中经常使用的技术,需求量很大。机器翻译译文质量的评价,对机器翻译的研究非常重要,有利于提升机器翻译的准确性。
现有的机器翻译质量的评估模型一般通过比较机器译文和参考译文的差异来计算机器译文的得分数值,以此来评估机器译文的翻译质量。该种评估方式依赖于人工生产的高质量参考译文,由于人工生产的高质量参考译文的数量有限,导致评估模型无法较好地满足实际的翻译业务的质量评估场景需求。
发明内容
有鉴于此,有必要提供一种翻译质量评估方法,其可基于原文与机器译文对机器译文的翻译质量进行评估。
本申请实施例第一方面公开了一种翻译质量评估方法,应用于电子设备,包括:获取待翻译的原文及与原文对应的译文;基于原文与译文得到与译文对应的第一特征向量组,其中第一特征向量组包括n个特征向量,n个特征向量与对译文进行分词得到的n个词相对应;基于第一特征向量组生成第二特征向量组,其中第二特征向量组包括2n+1个特征向量,2n+1个特征向量包括与译文中的n个词相对应的n个特征向量及与译文中的n+1个空隙相对应的n+1个特征向量;对第二特征向量组中的每个特征向量进行分类预测,得到每个特征向量的翻译结果标签;基于每个特征向量的翻译结果标签,输出译文的翻译评估结果。
采用该技术方案,通过提取与对译文分词得到的n个词相对应的n个特征向量,及基于该n个特征向量生成2n+1个特征向量,该2n+1个特征向量对应n个词及n个词旁边的n+1个空隙,再对2n+1特征向量进行分类预测,评估每个词和词旁边每个空隙的是否翻译出错,进而可以基于每个词和每个空隙的评估结果得到整句译文的翻译评估结果,使得电子设备可以响应翻译评估指令获取原文与译文,即可输出译文的翻译评估结果,无需基于参考译文对机器译文进行翻译评估,评估结果更客观。
在一种可能的实现方式中,翻译质量评估方法还包括:对原文进行分词处理与词表映射,得到与原文对应的第一数字序列,其中第一数字序列包括m个数字,m个数字与对原文进行分词得到的m个词相对应;对译文进行分词处理与词表映射,得到与译文对应的第二数字序列,其中第二数字序列包括n个数字,n个数字与n个词相对应。
采用该技术方案,通过对原文与译文分别进行分词与词表映射处理,使得原文与译文文本转为计算机可处理的数字串,便于后续提取与译文对应的第一特征向量组。
在一种可能的实现方式中,基于原文与译文得到与译文对应的第一特征向量组,包括:将第一数字序列与第二数字序列输入至注意力神经网络,得到与译文对应的第一特征向量组;其中,注意力神经网络包括编码器及解码器,编码器的输入包括用于表征第一数字序列中的每个数字的第一向量及用于表征第一数字序列中的每个数字的位置的第二向量,解码器的输入包括用于表征第二数字序列中的每个数字的第三向量、用于表征第二数字序列中的每个数字的位置的第四向量及编码器的编码结果。
采用该技术方案,通过由编码器与解码器组成的注意力神经网络来提取与译文对应的第一特征向量组,编码器的输入包括原文中的每个词的向量表示及每个词的位置的向量表示,解码器的输入包括译文中的每个词的向量表示及每个词的位置的向量表示,解码器同时将编码器的输出作为额外输入,从而将原文的编码信息融合到译文中。
在一种可能的实现方式中,基于第一特征向量组生成第二特征向量组,包括:对第一特征向量组进行上采样处理,得到第二特征向量组。
采用该技术方案,通过对第一特征向量组进行上采样处理,实现基于n个特征向量生成2n+1个特征向量,该2n+1个特征向量组成第二特征向量组。
在一种可能的实现方式中,对第一特征向量组进行上采样处理,得到第二特征向量组,包括:对第一特征向量组进行上采样得到2n+1个第一向量,及基于2n+1个第一向量得到第一矩阵;对第一矩阵进行卷积与激活操作,得到第二矩阵;将第一矩阵与第二矩阵进行相加,得到第三矩阵;对第三矩阵进行双向长短记忆(bidirectional long short-termmemory,Bi-LSTM)运算,得到第四矩阵,及基于第四矩阵得到第二特征向量组。
采用该技术方案,通过对译文的n个特征向量进行上采样、卷积激活、Bi-LSTM运算等处理,生成由2n+1个特征向量组成的第二特征向量组,且可使得该2n+1个特征向量对应着译文中的词和词旁边的空隙。
在一种可能的实现方式中,译文中的词的翻译结果标签包括三个分类,译文中的空隙的翻译结果标签包括两个分类,对第二特征向量组中的每个特征向量进行分类预测,包括:对第二特征向量组中的奇数位置的特征向量进行二分类预测,得到译文中的每个空隙的翻译结果标签;对第二特征向量组中的偶数位置的特征向量进行三分类预测,得到译文中的每个词的翻译结果标签。
采用该技术方案,通过对n+1个对应空隙的特征向量进行二分类预测,对n个对应词的特征向量进行三分类预测,实现预测出译文中每个词和词旁边空隙的翻译错误类型,使得用户可以基于翻译评估结果较轻易地对译文进行调整。
在一种可能的实现方式中,翻译评估结果包括译文中的每个词的翻译结果标签、译文中的每个空隙的翻译结果标签、译文的翻译出错得分及所述译文出现的翻译错误类型。
采用该技术方案,使得电子设备可以输出译文的每个词和词旁边的空隙的翻译错误类型、整句译文的翻译出错得分及整句译文出现的翻译错误类型,使得用户可以基于翻译评估结果较轻易地对译文进行调整。
在一种可能的实现方式中,翻译质量评估方法还包括:基于译文中的每个词的翻译结果标签及译文中的每个空隙的翻译结果标签统计总翻译出错数量,及基于总翻译出错数量计算得到译文的翻译出错得分,其中总翻译错误数量为词的翻译出错数量与空隙的翻译出错数量之和;基于译文中的每个词的翻译结果标签及译文中的每个空隙的翻译结果标签统计得到译文出现的翻译错误类型。
采用该技术方案,可以根据译文中的每个词的翻译结果及词旁边的空隙的翻译结果计算得到整句译文的翻译出错得分及统计整句译文出现的翻译错误类型。
在一种可能的实现方式中,电子设备安装有翻译应用程序,原文与译文显示在翻译应用程序的第一页面,输出译文的翻译评估结果,包括:将译文的翻译评估结果显示在翻译应用程序的第二页面,其中第二页面部分覆盖第一页面。
采用该技术方案,翻译应用程序的第一页面显示原文与译文,翻译应用程序可以响应翻译评估指令,在第二页面显示译文的翻译评估结果,例如以弹窗页面的形式显示译文的翻译评估结果。
第二方面,本申请实施例提供一种翻译质量评估方法,应用于电子设备,电子设备运行有预先训练的翻译质量评估模型,翻译质量评估方法包括:获取待翻译的原文及与原文对应的译文;利用翻译质量评估模型提取与译文对应的第一特征向量组,其中第一特征向量组包括n个特征向量,n个特征向量与对译文进行分词得到的n个词相对应;利用翻译质量评估模型基于第一特征向量组生成第二特征向量组,其中第二特征向量组包括2n+1个特征向量,2n+1个特征向量包括与译文中的n个词相对应的n个特征向量及与译文中的n+1个空隙相对应的n+1个特征向量;利用翻译质量评估模型对第二特征向量组中的每个特征向量进行分类预测,得到每个特征向量的翻译结果标签,及根据翻译结果标签得到译文的翻译评估结果。
采用该技术方案,电子设备可通过其上运行的翻译质量评估模型可对译文分词得到的n个词,提取与n个词相对应的n个特征向量,及基于该n个特征向量生成2n+1个特征向量,该2n+1个特征向量对应n个词及n个词旁边的n+1个空隙,再对2n+1特征向量进行分类预测,评估每个词和词旁边每个空隙的是否翻译出错,进而可以基于每个词和每个空隙的评估结果得到整句译文的翻译评估结果。
在一种可能的实现方式中,翻译质量评估模型的训练数据包括多个原文样本及与多个原文样本对应的多个译文样本,多个译文样本中的每个译文样本均包括词的翻译结果标签及空隙的翻译结果标签,词的翻译结果标签及空隙的翻译结果标签作为翻译质量评估模型的训练监督标签。
采用该技术方案,在翻译质量评估模型的训练过程中,将多个原文样本及译文样本作为模型训练的输入,译文样本中的词的翻译分类标签及词旁边空隙的翻译分类标签作为模型训练的监督标签,对翻译质量评估模型进行训练。
第三方面,本申请实施例提供一种计算机可读存储介质,包括计算机指令,当计算机指令在电子设备上运行时,使得电子设备执行如第一方面或第二方面所述的翻译质量评估方法。
第四方面,本申请实施例提供一种电子设备,电子设备包括处理器和存储器,存储器用于存储指令,处理器用于调用存储器中的指令,使得电子设备执行如第一方面或第二方面所述的翻译质量评估方法。
第五方面,本申请实施例提供一种计算机程序产品,当计算机程序产品在计算机上运行时,使得计算机执行如第一方面或第二方面所述的翻译质量评估方法。
第六方面,提供一种装置,该装置具有实现上述第一方面或第二方面所提供的方法中电子设备行为的功能。功能可以通过硬件实现,也可以通过硬件执行相应的软件实现。硬件或软件包括一个或多个与上述功能相对应的模块。
可以理解地,上述提供的第三方面所述的计算机可读存储介质,第四方面所述的电子设备,第五方面所述的计算机程序产品,第六方面所述的装置均与上述第一方面或第二方面的方法对应,因此,其所能达到的有益效果可参考上文所提供的对应的方法中的有益效果,此处不再赘述。
附图说明
图1为本申请一实施例提供的翻译质量评估方法的应用场景图;
图2a为本申请一实施例提供的翻译质量评估模型的运行环境示意图;
图2b为本申请一实施例提供的翻译APP的用户界面示意图;
图3a为本申请一实施例提供的翻译质量评估模型的功能模块示意图;
图3b为本申请一实施例提供的Transfromer模型的功能模块示意图;
图4为本申请一实施例提供的翻译质量评估方法的步骤流程示意图;
图5为本申请另一实施例提供的翻译质量评估方法的步骤流程示意图;
图6为图4的翻译质量评估方法的一步骤流程的细分流程示意图;
图7为本申请又一实施例提供的翻译质量评估方法的步骤流程示意图;
图8为本申请实施例提供的一种可能的电子设备的结构示意图。
具体实施方式
需要说明的是,本申请中“至少一个”是指一个或者多个,“多个”是指两个或多于两个。“和/或”,描述关联对象的关联关系,表示可以存在三种关系,例如,A和/或B可以表示:单独存在A,同时存在A和B,单独存在B的情况,其中A,B可以是单数或者复数。本申请的说明书和权利要求书及附图中的术语“第一”、“第二”、“第三”、“第四”等(如果存在)是用于区别类似的对象,而不是用于描述特定的顺序或先后次序。
在本申请实施例中,“示例性的”或者“例如”等词用于表示作例子、例证或说明。本申请实施例中被描述为“示例性的”或者“例如”的任何实施例或设计方案不应被解释为比其它实施例或设计方案更优选或更具优势。确切而言,使用“示例性的”或者“例如”等词旨在以具体方式呈现相关概念。
为了便于理解,示例的给出了部分与本申请实施例相关的概念说明以供参考。
应用程序(application,APP),可以简称应用,为能够实现某项或多项特定功能的软件程序。例如,即时通讯类应用、视频类应用、音频类应用、图像拍摄类应用、云桌面类应用等等。其中,即时通信类应用,例如可以包括短信应用、
电子设备可以为手机、可折叠电子设备、平板电脑、个人电脑(personalcomputer,PC)、膝上型计算机、手持计算机、笔记本电脑、超级移动个人计算机(ultra-mobile personal computer,UMPC)、上网本、蜂窝电话、个人数字助理(personal digitalassistant,PDA)、增强现实(augmented reality,AR)设备、虚拟现实(virtual reality,VR)设备、人工智能(artificial intelligence,AI)设备、可穿戴式设备、车载设备、智能家居设备、或智慧城市设备、服务器中的至少一种,本申请实施例对电子设备的具体类型不作特殊限制。电子设备100可以通过通信网络与其他电子设备或服务器进行通信。通信网络可以是有线网络,也可以是无线网络。例如,通信网络可以是局域网(local area networks,LAN),也可以是广域网(wide area networks,WAN),例如互联网。当该通信网络为局域网时,示例性的,该通信网络可以是wifi热点网络、wifi P2P网络、蓝牙网络、zigbee网络或近场通信(near field communication,NFC)网络等近距离通信网络。当该通信网络为广域网时,示例性的,该通信网络可以是第三代移动通信技术(3rd-generation wirelesstelephone technology,3G)网络、第四代移动通信技术(the 4th generation mobilecommunication technology,4G)网络、第五代移动通信技术(5th-generation mobilecommunication technology,5G)网络、未来演进的公共陆地移动网络(public landmobile network,PLMN)或因特网等。
电子设备包括但不限于搭载
下面结合图1示例性的介绍本发明实施例提供的翻译质量评估方法的应用场景图。
该实施例可应用于电子设备100。例如,图1以电子设备100为手机为例,电子设备100可以安装有翻译APP A_1,翻译APP A_1可以实现将一种语言翻译为另一种语言,语言的类型可以根据实际开发需求进行设定,例如,可以支持中文、英语、日语、韩语、法语、德语、俄语、西班牙语、葡萄牙语、越南语、印尼语、意大利语、荷兰语、泰语等语言互译。翻译APPA_1可以支持在线翻译和/或本地离线翻译。
在一些实施例中,电子设备100也可以为服务器或服务器集群,服务器上部署有翻译软件,其他电子设备可以通过网络接入服务器,通过网络传送要翻译的词汇至服务器,及接收服务器返回的翻译结果,实现在线翻译。
当基于待翻译的原文得到译文时,可以将原文与译文输入至图3a所示的翻译质量评估模型10,实现对译文进行翻译质量评估。以待翻译的原文为中文,译文为英语为例,通过图3a所示的翻译质量评估模型10可以实现对译文进行翻译评估。例如,翻译评估结果可以包括:评估得到译文中的每个单词是否翻译正确、是否错译、是否过译,即每个单词可对应有一翻译结果标签,通过该单词的翻译结果标签表征该单词是否翻译正确、是否错译、是否过译;评估每个单词左右两边的空隙是否翻译正确、漏译,即每个空隙亦可对应有翻译结果标,通过该空隙的翻译结果标签表征该空隙是否翻译正确、是否漏译;基于每个单词以及每个单词左右两边的空隙的翻译错误类型计算并输出整句译文的翻译出错得分;输出译文出现的翻译错误类型。
可以理解的,译文中第i个词左边的空隙即为译文中第i+1个词右边的空隙。
在一些实施例中,以待翻译的原文为中文,译文为英语为例,翻译评估结果可以包括译文中的每个单词及其左右两边的空隙的翻译结果标签、译文的翻译出错得分及译文出现的翻译错误类型。
在一些实施例中,译文的翻译出错得分越高,表明译文的翻译出错概率越大,译文翻译准确的可能性越低;译文的翻译出错得分越低,表明译文的翻译出错概率越小,译文翻译准确的可能性越高。
如图2a所示,为本申请实施例提供的翻译质量评估模型10的运行环境示意图。
该实施例可应用于电子设备100。电子设备100安装有翻译APP A_1。电子设备100的输入设备可以输入待翻译的原文至翻译APP A_1,翻译APP A_1翻译得到与该原文对应的译文。例如,输入设备为触控屏,触控屏响应用户的输入指令输入原文W1至翻译APP A_1,翻译APP A_1翻译得到与原文W1对应的译文W2。电子设备100的处理器可以运行有训练完成的翻译质量评估模型10,原文W1与译文W2作为翻译质量评估模型10的输入,翻译质量评估模型10可以得到译文W2的翻译评估结果。例如,译文W2的翻译评估结果可以由电子设备100的输出设备进行可视化显示,可视化显示包括但不限于以图表加文字的方式进行显示。例如,电子设备100的输出设备为触控屏,通过触控屏来显示译文W2的翻译评估结果。
如图2b所示,为翻译APP A_1的用户界面U1,在用户界面U1中可以选择翻译方式(如中译英),用户界面U1还可以包括原文输入栏位、译文的显示栏位及“开始评估”图标。但用户点击“开始评估”图标时,即可执行对译文进行翻译评估,翻译评估结果可以以新用户界面U2进行显示。例如,在当前用户界面U1弹出新用户界面U2显示翻译评估结果,新用户界面U2部分覆盖当前用户界面U1。例如,在新用户界面U2中,译文中的每个单词的翻译结果标签可以用高亮底色进行标识,如果某个单词翻译正确,则不添加底色,如果某个单词错译,则为该单词添加第一底色(如红色)进行标识,如果某个单词过译,则为该单词添加第二底色(如黄色)进行标识。对于单词左右两边的空隙的翻译结果标签同样可以采用高亮底色进行标识,如果某个空隙翻译正确,则不添加底色,如果某个空隙错译,则在该空隙出添加第一底色(如红色)进行标识。译文W2的翻译出错得分及译文W2出现的翻译错误类型可以以图表的形式进行展示。
举例而言,原文W1为:“我在北京西站门口的肯德基店里等你。”,译文W2为“I'llbe waiting for you at the KFC in front of Beijing West Station.”。对译文W2进行分词处理,得到的序列为:“I'll”、“be”、“waiting”、“for”、“you”、“at”、“the”、“KFC”、“in”、“front”、“of”、“Beijing”、“West”、“Station”、“.”,翻译质量评估模型10可以预测得到译文W2中的每个单词的翻译结果如表1所示,译文W2中的每个空隙的翻译结果如表2所示。
表1
表2
可以通过统计表1与表2中出现的错误个数计算得到译文W2的翻译出错得分,例如可以得到表1的总数为15个,错误个数为3个,表2的总数为16个,错误个数为2个,翻译出错得分以百分制为例,可以计算得到译文W2的翻译出错得分为:100*(3+2)/(15+16)=16.129。表1出现的翻译错误类型包括错译,表2出现的翻译错误类型包括错译,即可得到译文W2出现的翻译错误类型:错译。
如图3a所示,为本申请实施例提供的翻译质量评估模型10的功能模块示意图。
该实施例的翻译质量评估模型10可应用于电子设备100。翻译质量评估模型10可以包括文本预处理层、特征提取层、特征生成层及输出层。翻译质量评估模型10可以是一端到端的深度学习模型,可以使用诸如梯度下降法、反向传播法进行模型训练。在翻译质量评估模型10的训练过程中,可以将待翻译的原文文本及与原文对应的译文文本作为模型的输入,将译文中的每个词(或词语)的翻译结果标签(以下简称为word_tag)及每个词(或词语)的左右两边的空隙的翻译结果标签(以下简称为gap_tag)作为模型训练时的监督标签,直至监督训练的损失收敛,其中训练模型参数的优化器可以使用诸如Adam优化器、SGD优化器等,本申请对此不作限制。
word_tag包括3种分类标签:0、1、2,其中0表示翻译正确,1表示错译,2表示过译。gap_tag包括2种分类标签:0、1,其中0表示翻译正确,1表示错译。
模型训练过程中,可以通过以下方式计算监督训练的损失:a).计算word_tag的3种分类的交叉熵损失loss_1;b).计算gap_tag的2种分类的交叉熵损失loss_2;c).计算监督训练的损失loss,loss=0.5*loss_1+0.5*loss_2。
在一些实施例中,用于模型训练的译文中的word_tag与gap_tag可以预先由人工或者其他方式进行标定,本申请对此不作限定。假设译文被划分为n个词,n个词对应有n个word_tag,n个词对应有n+1个空隙,即对应有n+1个gap_tag。例如,译文为“I like it”,译文包括三个词“I”、“like”、“it”,空隙包括4个:gap1、gap2、gap3、gap4,空隙可以示意为:“[gap1]I[gap2]like[gap3]it[gap4]”。
在模型训练阶段,训练样本数据应尽可能包括多种语言的原文与译文,使得训练得到的翻译质量评估模型10可以对多种语言的互译进行翻译质量评估。
在一些实施例中,文本预处理层可用于对接收到的翻译评估文本进行处理,得到计算机可处理的数字序列。翻译评估文本包括待翻译的原文及与该原文对应的译文,文本预处理层可以对原文与译文分别进行分词和词表映射的处理,得到与原文对应的第一数字序列及与译文对应的第二数字序列。假设,第一数字序列的长度为m,与原文对应的第一数字序列可以表示为[Src
在一些实施例中,不同的语言的语句可具有不同的分词处理方式,可以采用现有的分词工具对语句进行分词处理,例如中文分词工具为jieba分词器,通过jieba分词器将中文语句划分为单个的词或者词语,英文语句可以以空格进行分词,将英文语句划分为多个单词。词表映射可以是指将分词处理得到的词或者词语映射为数字,可以采用现有的词-数字映射库将分词处理得到的词或者词语映射为数字。词-数字映射库建立有多个词、多个词语与数字之间的一一对应的映射关系。
举例而言,待翻译的原文为:“我在北京西站门口的肯德基店里等你。”,由翻译APPA_1翻译得到的译文为:“I'll be waiting for you at the KFC in front of BeijingWest Station.”。
对待翻译的原文进行分词,将原文切分为单个词和/或词语的序列,例如分词得到的序列为:“我”、“在”、“北京西站”、“门口”、“的”、“肯德基”、“店里”、“等你”、“。”。假设“我”对应的数字为477,“在”对应的数字为32,“北京西站”对应的数字为5789,“门口”对应的数字为134,“的”对应的数字为30,“肯德基”对应的数字为1233,“店里”对应的数字为799,“等你”对应的数字为477,“。”对应的数字为12,即与待翻译的原文对应的第一数字序列为:[477,32,5789,134,30,1233,799,477,12],第一数字序列的长度m为9。
对由翻译APP A_1翻译得到的译文进行分词处理,得到的序列为:“I'll”、“be”、“waiting”、“for”、“you”、“at”、“the”、“KFC”、“in”、“front”、“of”、“Beijing”、“West”、“Station”、“.”。假设,“I'll”对应的数字为352,“be”对应的数字为48,“waiting”对应的数字为269,“for”对应的数字为312,“you”对应的数字为87,“at”对应的数字为59,“the”对应的数字为47,“KFC”对应的数字为1424,“in”对应的数字为108,“front”对应的数字为197,“of”对应的数字为754,“Beijing”对应的数字为6952,“West”对应的数字为845,“Station”对应的数字为1520,“.”对应的数字为121,即与译文对应的第二数字序列为:[352,48,269,312,87,59,47,1424,108,197,754,6952,845,1520,121],第二数字序列的长度n为15。
特征提取层可以基于输入的第一数字序列与第二数字序列,得到用于表征译文中的n个词的n个特征向量,例如为[v_1,v_2,v_3,…,v_n],实现以向量来表征译文中的每个词。例如,译文被划分为n个词,向量v_1对应译文中的第一个词,向量v_n对应译文中的第n个词。
在一些实施例中,特征提取层可以包括注意力神经网络,注意力神经网络可以采用如图3b所示的Transfromer模型,或者采用其他具备注意力机制的语言模型结构,本申请对此不作限定。
如图3b所示,Transfromer模型包括编码器及解码器,解码器包括编码器-解码器关注(Encoder-Decoder Attention)模块。编码器及解码器均可以是一个N层的神经网络,解码器的输出可由激励函数(Softmax)进行非线性化处理。编码器的输入由源端词汇编码与源端位置编码这两个部分的和组成。假设,原文进行分词处理得到m个词和/或词语,源端词汇编码可以是指原文中的每个词或词语用一个向量进行表示,源端位置编码可以是指原文中的每个词或词语的位置用一个向量进行表示,以实现区分不同位置的词或词语。解码器的输入可以由目的端词汇编码和目的端位置编码这两个部分的和组成。假设,译文进行分词处理得到n个词和/或词语,目的端词汇编码可以是指译文中的每个词或词语用一个向量进行表示,目的端位置编码可以是指译文中的每个词或词语的位置用一个向量进行表示。解码器还可利用Encoder-Decoder Attention模块实现将编码器的输出作为额外的输入,从而将源端的编码结果融合到目的端的预测中。
举例而言,原文为:“It likes fish”。原文被划分为3个词“It”、“likes”、“fish”。假设,“It”的向量表示是[0.1,-0.2],“It”是第一个词,对应的位置1的编码是[0.2,0.1],则“It”对应的编码器的输入为[0.1,-0.2]+[0.2,0.1]=[0.3,-0.1];“likes”的向量表示是[-0.3,-0.1],“likes”是第二个词,对应的位置2的编码是[0.1,-0.4],则“likes”对应的编码器的输入为[-0.3,-0.1]+[0.1,-0.4]=[-0.2,-0.5];“fish”的向量表示是[0.5,0.2],“fish”是第三个词,对应的位置3的编码是[-0.1,-0.3],则“fish”对应的编码器的输入为[0.5,0.2]+[-0.1,-0.3]=[0.4,-0.1]。编码器的输入为三个二维向量:[0.3,-0.1],[-0.2,-0.5],[0.4,-0.1]。N层的神经网络可通过已定义的神经网络进行运算得到编码器的输出,编码器的输出同样也是三个二维向量,只是经过N层的神经网络的处理后,向量的值会与输入有所不同。
通过图3b所示的Transfromer模型可以得到n个特征向量,实现将译文表征为特征向量[v_1,v_2,v_3,…,v_n]。
对于译文的n个特征向量([v_1,v_2,v_3,…,v_n]),特征生成层可以基于n个特征向量生成2n+1个特征向量,例如该2n+1个特征向量为[v_1’,v_2’,v_3’,…,v_2n+1’]。其中,该2n+1个特征向量中的n个特征向量用来表征译文中的每个词,该2n+1个特征向量中的n+1个特征向量用来表征译文中的每个词左右两边的空隙。
在一些实施例中,特征生成层可以使用各类型的神经网络模型,实现基于译文的n个特征向量生成2n+1个特征向量。例如可以采用包含有双向长短记忆循环神经网络(bidirectional long short-term memory recurrent neural network,Bi-LSTM RNN)的神经网络模型。
在一些实施例中,译文的n个特征向量可以用一个n*k的矩阵A进行表示,k为向量的维度,例如向量v_1、v_2、v_3、…、v_n均为2维向量,则k=2,若向量v_1、v_2、v_3、…、v_n均为1024维向量,则k=1024。特征生成层可以通过以下方式实现基于译文的n个特征向量生成2n+1个特征向量:
1)假设译文的n个特征向量用一个n*k的矩阵A进行表示,对矩阵A进行上采样得到2n+1个向量,2n+1个向量用(2n+1)*k的矩阵A*表示,A*可以表示为由向量s
举例而言,对矩阵A进行上采样的过程可以包括:
a1).构建一个(2n+1)*k的基准矩阵A*’,假设该基准矩阵A*’为全为0的矩阵;
a2).基于矩阵A的第一个特征向量对基准矩阵A*’的编号为首位的特征向量进行赋值,赋值的数学形式为:A*’[1,j]=A[1,j]/2,其中j=1,2,…,k,即将矩阵A的第一个特征向量的二分之一赋值给基准矩阵A*’的编号为首位的特征向量,s
a3).基于矩阵A的n个特征向量对基准矩阵A*’的编号为偶数位的特征向量进行赋值,赋值的数学形式为:A*’[2i,j]=A[i,j],其中i=1,2,…,n;j=1,2,…,k,即将矩阵A的每个特征向量依次赋值给基准矩阵A*’的编号为偶数位的特征向量,例如,s
a4).基于矩阵A的n个特征向量对基准矩阵A*’的编号为奇数位(该奇数位不包括首位及末位)的特征向量进行赋值,赋值的数学形式为:A*’[2i+1,j]=(A[i,j]+A[i+1,j])/2,其中i=1,2,…,n-1;j=1,2,…,k,即将矩阵A的相邻两个特征向量进行求平均值,并依次赋值给基准矩阵A*’的编号为奇数位(该奇数位不包括首位及末位)的特征向量,例如,s
a5).基于矩阵A的第n个特征向量对基准矩阵A*’的编号为末位的特征向量进行赋值,赋值的数学形式为:A*’[2n+1,j]=A[n,j]/2,其中j=1,2,…,k,即将矩阵A的第n个特征向量的二分之一赋值给基准矩阵A*’的编号为末位的特征向量,s
a6).经过上述步骤a1~a5对基准矩阵A*’进行赋值操作,即可实现将基准矩阵A*’转换为矩阵A*。
2)对矩阵A*进行两次二维卷积计算,每次卷积计算后可以进行一次激活操作。第一次卷积可以将通道数增多到大于1的数量,第二次卷积再将通道数降为1,经过激活处理得到(2n+1)*k的矩阵B,对矩阵A*进行卷积与激活操作得到矩阵B可以表示为:A*_1=Conv(A*);A*_2=Activate(A*_1);A*_3=Conv(A*_2);B=Activate(A*_3);其中,Conv是二维卷积操作,Activate是激活函数,激活函数可以是Relu激活函数、Sigmod激活函数、Tanh激活函数等,本申请对此不作限定。
3)将矩阵B与矩阵A*进行相加得到矩阵C,及将矩阵C输入至Bi-LSTM RNN进行Bi-LSTM运算,得到矩阵D,矩阵D为(2n+1)*k的矩阵,矩阵D作为特征生成层的输出,其中C=B+A*,D=Bi-LSTM(C),Bi-LSTM(C)为对矩阵C进行Bi-LSTM运算。
在一些实施例中,矩阵D即为用来表征2n+1个特征向量([v_1’,v_2’,v_3’,…,v_2n+1’])的矩阵。
在一些实施例中,输出层可以基于矩阵D对译文进行翻译评估,以待翻译的原文为中文,译文为英语为例,输出层可以基于矩阵D预测译文中的每个单词及其左右两边的空隙的翻译结果标签、译文的翻译出错得分及译文出现的翻译错误类型。输出层可以包括分类网络模型,输出层可以通过以下方式实现基于矩阵D对译文进行翻译评估:
b1).将矩阵D的奇数行与偶数行的向量分离出来,假设奇数行的向量用向量组G表示,偶数行的向量用向量组W表示。向量组G为译文中n+1个空隙的描述特征,向量组W为n个单词的描述特征。
b2).利用分类网络模型对向量组W中的每个向量进行三分类计算操作,例如向量组W经过输出为3的全链接神经元,及经过Softmax计算操作,得到n*3的矩阵。矩阵中的每行选择数值最大的序号,按行顺序进行排列作为最后每个词的分类标签,得到长度为n的数组Wt。假设数组Wt为[0,0,0,1,2,2,…,0],在数组Wt中,“0”表示翻译正确,“1”表示错译,“2”表示过译。数组Wt中的第一位为“0”,表明输出层预测译文的第一个单词翻译正确,数组Wt中的第四位为“1”,表明输出层预测译文的第四个单词错译,数组Wt中的第五位为“2”,表明输出层预测译文的第五个单词过译。
b3).利用分类网络模型对向量组G中的每个向量进行二分类计算操作,例如向量组G经过输出为2的全链接神经元,及经过Softmax计算操作,得到(n+1)*2的矩阵。矩阵中的每行选择数值最大的序号,按行顺序进行排列,作为最后每个空隙的分类标签,得到长度为n+1的数组Gt。假设数组Gt为[0,0,0,1,1,0,…,0],在数组Gt中,“0”表示翻译正确,“1”表示错译。数组Gt中的第一位为“0”,表明输出层预测译文的第一个空隙(位于第一个单词的左边)翻译正确,数组Gt中的第四位为“1”,表明输出层预测译文的第四个空隙错译。
在一些实施例中,当得到数组Wt与数组Gt时,输出层还可以通过统计数组Wt和数组Gt中非0的个数p,基于非0的个数p计算得到译文的翻译出错得分score,其中score=p/(2n+1)*100。例如,可以将2个数组Wt、Gt串接成2n+1长度的数组Nt,统计数组Nt中非0的个数p,再基于非0的个数p计算得到译文的翻译出错得分score。
在一些实施例中,当得到数组Wt与数组Gt时,输出层还可以通过统计数组Wt中出现的翻译错误类型和数组Gt中出现的翻译错误类型,汇总得到译文出现的翻译错误类型。例如,数组Wt为[0,0,0,1,2,2,…,0],数组Gt为[0,0,0,1,1,0,…,0],输出层可以统计得到数组Wt中出现的翻译错误类型包括错译与过译,数组Gt中出现的翻译错误类型包括错译,即可得到译文出现的翻译错误类型包括错译与过译。
若数组Wt与数组Gt均无非0的数字,输出层可以输出“译文翻译正确”的信息。
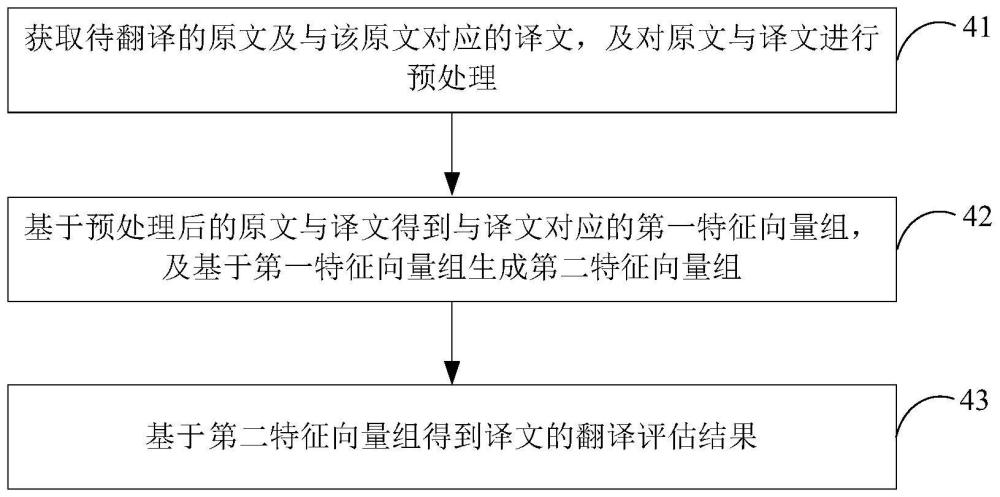
如图4所示,为本申请实施例提供的翻译质量评估方法,应用于电子设备100,电子设备100运行有翻译质量评估模型10。本实施例中,翻译质量评估方法可以包括:
41、获取待翻译的原文及与该原文对应的译文,及对原文与译文进行预处理。
在一些实施例中,当获取得到待翻译的原文及译文时,可以将原文与译文输入至翻译质量评估模型10,实现对原文及译文进行预处理,将文本转换为计算机可处理的数字序列。例如,预处理可以包括对原文与译文分别进行分词和词表映射的处理,得到与原文对应的第一数字序列及与译文对应的第二数字序列。假设原文被划分为m个词,译文被划分为n个词。
在一些实施例中,如图5所示,步骤41可以划分为步骤411及步骤412:
411:获取待翻译的原文及与该原文对应的译文;
412:对原文与译文进行预处理,得到与原文对应的第一数字序列及与译文对应的第二数字序列。
42、基于预处理后的原文与译文得到与译文对应的第一特征向量组,及基于第一特征向量组生成第二特征向量组。
在一些实施例中,翻译质量评估模型10可以包括如图3b所示的Transfromer模型,原文及译文经由Transfromer模型得到第一特征向量组[v_1,v_2,v_3,…,v_n],第一特征向量组包括n个特征向量v_1、v_2、v_3、…、v_n,实现将译文的n个词表征为n个特征向量。
当得到第一特征向量组时,可以对第一特征向量组进行上采样,得到第二特征向量组[v_1’,v_2’,v_3’,…,v_2n+1’]。第二特征向量组包括2n+1个特征向量,该2n+1个特征向量中的n个特征向量用来表征译文中的n个词,该2n+1个特征向量中的n+1个特征向量用来表征译文中的n+1个空隙。例如,第二特征向量组[v_1’,v_2’,v_3’,…,v_2n+1’]中的奇数位向量用于表征译文中的n+1个空隙,偶数位向量用于表征译文中的n个词。
43、基于第二特征向量组得到译文的翻译评估结果。
在一些实施例中,翻译质量评估模型10可以对第二特征向量组中的奇数位与偶数位的向量分别进行分类预测。例如,对的奇数位进行二分类计算操作,得到每个空隙的分类标签,对偶数位进行三分类计算操作,得到每个词的分类标签。
翻译评估结果可以包括译文中的每个词及其左右两边的空隙的翻译结果标签、译文的翻译出错得分及译文出现的翻译错误类型。当得到译文中的每个空隙的分类标签及每个词的分类标签时,翻译质量评估模型10还可基于这些分类标签信息计算得到译文的翻译出错得分及统计得到译文出现的翻译错误类型。
在一些实施例中,如图5所示,步骤43可以划分为步骤431、步骤432及步骤433:
431、对第二特征向量组中的对应n+1个空隙的向量进行二分类计算操作,对第二特征向量组中的对应n个词的向量进行三分类计算操作;
432、基于n+1个空隙的二分类结果及n个词的三分类结果计算译文的翻译出错得分;
433、基于n+1个空隙的二分类结果及n个词的三分类结果统计译文出现的翻译错误类型。
在一些实施例中,步骤432与步骤433可以为并列执行的步骤,或者先执行步骤433,在执行步骤432。
如图6所示,为本申请实施例提供的步骤42的细分流程示意图。
421、基于预处理后的原文与译文得到与译文中的n个词对应的n个特征向量。
422、对n个特征向量进行上采样,得到的2n+1个特征向量。
423、将2n+1个特征向量以矩阵A*进行表示,对矩阵A*进行两次卷积与两次激活操作,得到矩阵B。
在一些实施例中,矩阵A*为(2n+1)*k的矩阵,k为特征向量的维度。每次卷积计算后可以进行一次激活操作。第一次卷积可以将通道数增多到大于1的数量,第二次卷积再将通道数降为1,经过激活处理得到(2n+1)*k的矩阵B。
424、将矩阵B与矩阵A*进行相加运算,得到矩阵C。
在一些实施例中,矩阵C为(2n+1)*k的矩阵。
425、对矩阵C进行Bi-LSTM运算,得到矩阵D。
在一些实施例中,可以将矩阵C输入至Bi-LSTM RNN进行Bi-LSTM运算,得到矩阵D,矩阵D为(2n+1)*k的矩阵。第二特征向量组包括2n+1个特征向量,矩阵D即为用来表示第二特征向量组中的2n+1个特征向量的矩阵。
如图7所示,为本申请实施例提供的翻译质量评估方法,应用于电子设备100,电子设备100运行有翻译APP A_1。本实施例中,翻译质量评估方法可以包括:
70、获取待翻译的原文及与原文对应的译文。
在一些实施例中,可以响应于翻译评估指令,获取待翻译的原文及与原文对应的译文。翻译评估指令可以是由用户触发产生,也可以是自动产生(无需用户介入),例如在翻译得到译文时,自动对译文进行评估。当获取到待翻译的原文及译文时,可以对原文进行分词处理与词表映射,得到与原文对应的第一数字序列,及对译文进行分词处理与词表映射,得到与译文对应的第二数字序列。其中第一数字序列包括m个数字,m个数字与对原文进行分词得到的m个词相对应,第二数字序列包括n个数字,n个数字与对译文进行分词得到的n个词相对应。
71、基于原文与译文得到与译文对应的第一特征向量组。
在一些实施例中,第一特征向量组包括n个特征向量,n个特征向量与对译文进行分词得到的n个词相对应。例如,将第一数字序列与第二数字序列输入至注意力神经网络,得到与译文对应的第一特征向量组;其中,注意力神经网络包括编码器及解码器,编码器的输入包括用于表征第一数字序列中的每个数字的第一向量及用于表征第一数字序列中的每个数字的位置的第二向量,解码器的输入包括用于表征第二数字序列中的每个数字的第三向量、用于表征第二数字序列中的每个数字的位置的第四向量及编码器的编码结果。
72、基于第一特征向量组生成第二特征向量组。
在一些实施例中,第二特征向量组包括2n+1个特征向量,2n+1个特征向量包括与译文中的n个词相对应的n个特征向量及与译文中的n+1个空隙相对应的n+1个特征向量。例如,可以通过对第一特征向量组进行上采样处理,得到第二特征向量组。
在一些实施例中,对第一特征向量组进行上采样处理,得到第二特征向量组可以包括:对第一特征向量组进行上采样得到2n+1个第一向量,及基于2n+1个第一向量得到第一矩阵;对第一矩阵进行卷积与激活操作,得到第二矩阵;将第一矩阵与第二矩阵进行相加,得到第三矩阵;对第三矩阵进行双向长短记忆Bi-LSTM运算,得到第四矩阵,及基于第四矩阵得到第二特征向量组。
73、对第二特征向量组中的每个特征向量进行分类预测,得到每个特征向量的翻译结果标签。
在一些实施例中,译文中的词的翻译结果标签包括三个分类:0、1、2,其中0表示翻译正确,1表示错译,2表示过译。译文中的词旁边的空隙的翻译结果标签包括两个分类:0、1,其中0表示翻译正确,1表示错译。
在一些实施例中,对第二特征向量组中的每个特征向量进行分类预测可以包括:对第二特征向量组中的奇数位置的特征向量进行二分类预测,得到译文中的每个空隙的翻译结果标签;对第二特征向量组中的偶数位置的特征向量进行三分类预测,得到译文中的每个词的翻译结果标签。
74、基于每个特征向量的翻译结果标签,输出译文的翻译评估结果。
在一些实施例中,翻译评估结果可以包括译文中的每个词的翻译结果标签、译文中的每个空隙的翻译结果标签、译文的翻译出错得分及所述译文出现的翻译错误类型。
在一些实施例中,可以基于译文中的每个词的翻译结果标签及译文中的每个空隙的翻译结果标签统计总翻译出错数量,及基于总翻译出错数量计算得到译文的翻译出错得分。总翻译错误数量为词的翻译出错数量与空隙的翻译出错数量之和。
在一些实施例中,还可以基于译文中的每个词的翻译结果标签及译文中的每个空隙的翻译结果标签统计得到译文出现的翻译错误类型。
在一些实施例中,可以由电子设备100的输出设备输出译文的翻译评估结果。例如,原文与译文显示在翻译APP A_1的第一页面,第一页面可以包括接收用户的翻译评估指令的图标,当用户点击该图标时,译文的翻译评估结果显示在翻译APP A_1的第二页面。例如,在第一页面以弹窗页面的形式打开第二页面,第二页面部分覆盖第一页面。
参考图8,为本申请一实施例提供的电子设备100的硬件结构示意图。如图8所示,电子设备100可以包括处理器1001、存储器1002及通信总线1003。存储器1002用于存储一个或多个计算机程序1004。一个或多个计算机程序1004被配置为被处理器1001执行。该一个或多个计算机程序1004包括指令,处理器1001执行上述指令可以实现在电子设备100中执行上述翻译质量评估方法。
可以理解的是,本实施例示意的结构并不构成对电子设备100的具体限定。在另一些实施例中,电子设备100可以包括比图示更多或更少的部件,或者组合某些部件,或者拆分某些部件,或者不同的部件布置。
处理器1001可以包括一个或多个处理单元,例如:处理器1001可以包括调制解调器,图形处理器(graphics processing unit,GPU),图像信号处理器(image signalprocessor,ISP),控制器,视频编解码器,数字信号处理器(digital signal processor,DSP),基带处理器,和/或神经网络处理器(neural-network processing unit,NPU)等。其中,不同的处理单元可以是独立的器件,也可以集成在一个或多个处理器中。
处理器1001还可以设置有存储器,用于存储指令和数据。在一些实施例中,处理器1001中的存储器为高速缓冲存储器。该存储器可以保存处理器1001刚用过或循环使用的指令或数据。如果处理器1001需要再次使用该指令或数据,可从该存储器中直接调用。避免了重复存取,减少了处理器1001的等待时间,因而提高了系统的效率。
在一些实施例中,处理器1001可以包括一个或多个接口。接口可以包括集成电路(inter-integrated circuit,I2C)接口,集成电路内置音频(inter-integrated circuitsound,I2S)接口,脉冲编码调制(pulse code modulation,PCM)接口,通用异步收发传输器(universal asynchronous receiver/transmitter,UART)接口,移动产业处理器接口(mobile industry processor interface,MIPI),通用输入输出(general-purposeinput/output,GPIO)接口,SIM接口,和/或USB接口等。
在一些实施例中,存储器1002可以包括高速随机存取存储器,还可以包括非易失性存储器,例如硬盘、内存、插接式硬盘,智能存储卡(Smart Media Card,SMC),安全数字(Secure Digital,SD)卡,闪存卡(Flash Card)、至少一个磁盘存储器件、闪存器件、或其他非易失性固态存储器件。
本实施例还提供一种计算机存储介质,该计算机存储介质中存储有计算机指令,当该计算机指令在电子设备上运行时,使得电子设备执行上述相关方法步骤实现上述实施例中的翻译质量评估方法。
本实施例还提供了一种计算机程序产品,当该计算机程序产品在计算机上运行时,使得计算机执行上述相关步骤,以实现上述实施例中的翻译质量评估方法。
另外,本申请的实施例还提供一种装置,这个装置具体可以是芯片,组件或模块,该装置可包括相连的处理器和存储器;其中,存储器用于存储计算机执行指令,当装置运行时,处理器可执行存储器存储的计算机执行指令,以使芯片执行上述各方法实施例中的翻译质量评估方法。
其中,本实施例提供的电子设备、计算机存储介质、计算机程序产品或芯片均用于执行上文所提供的对应的方法,因此,其所能达到的有益效果可参考上文所提供的对应的方法中的有益效果,此处不再赘述。
通过以上的实施方式的描述,所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,仅以上述各功能模块的划分进行举例说明,实际应用中,可以根据需要而将上述功能分配由不同的功能模块完成,即将装置的内部结构划分成不同的功能模块,以完成以上描述的全部或者部分功能。
在本申请所提供的几个实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,该模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个装置,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
该作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是一个物理单元或多个物理单元,即可以位于一个地方,或者也可以分布到多个不同地方。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
该集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个可读取存储介质中。基于这样的理解,本申请实施例的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该软件产品存储在一个存储介质中,包括若干指令用以使得一个设备(可以是单片机,芯片等)或处理器(processor)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:U盘、移动硬盘、只读存储器(Read-Only Memory,ROM)、随机存取存储器(Random Access Memory,RAM)、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何在本申请揭露的技术范围内的变化或替换,都应涵盖在本申请的保护范围之内。