基于回归注意力生成对抗网络数据增强的回归建模方法
文献发布时间:2023-06-19 09:29:07
技术领域
本发明属于工业过程软测量领域,尤其涉及一种基于回归注意力生成对抗网络数据增强的回归建模方法。
背景技术
在当今的大数据时代,数据驱动模型发挥了重要的作用。其中回归模型作为一种实用的工具被广泛应用于许多场景,如金融行业中的股票走势预测,流程工业中的软传感器等。数据的质量对于数据驱动模型是至关重要的。在数据积累量有限,数据难以获取,数据隐私保护等应用场景中,数据的缺乏影响着回归模型的预测精度。因此,如何在有限数据下提升回归模型的性能是一个重要的课题。
生成对抗网络(GAN)是由Goodfellow在2014年提出的生成模型。将训练完成的GAN的生成数据加入到真实数据集中并一起参与建模是数据增强的思路,它能够帮助原始数据得到信息的扩充,以改善数据驱动模型的效果。但是目前没有针对回归问题的GAN模型,来进行数据增强的回归建模。用已有的GAN模型进行数据生成时,简单的将自变量和因变量拼接重构,忽视了数据内部自变量和因变量的回归关系。另外,因变量由于是待预测的变量,获取方式往往更加严格,精确度会更高。但GAN的训练中没有给与到因变量足够的重视,会将自变量的误差传播到因变量上。因此,这些因素制约了数据增强的回归建模的效果。
发明内容
本发明的目的在于针对现有技术的不足,提供一种基于回归注意力生成对抗网络数据增强的回归建模方法。
本发明的目的是通过以下技术方案来实现的:一种基于回归注意力生成对抗网络数据增强的回归建模方法,包括以下步骤:
(1)收集原始数据,在去除离群值和数据归一化后得到自变量x
(2)将x
(3)用D无监督地训练一个RA-GAN,并直至其收敛。
(4)用训练好的RA-GAN生成虚拟的数据 D′=[X′,Y′]={[x′
(5)将生成数据加入到真实数据集D中,进行数据增强,得到增强数据集。
(6)将增强数据集D的数据分割成自变量{X,X′}和因变量{Y,Y′},用于训练回归模型。
(7)将测试数据的自变量输入到训练好的回归模型中,得到预测的因变量。
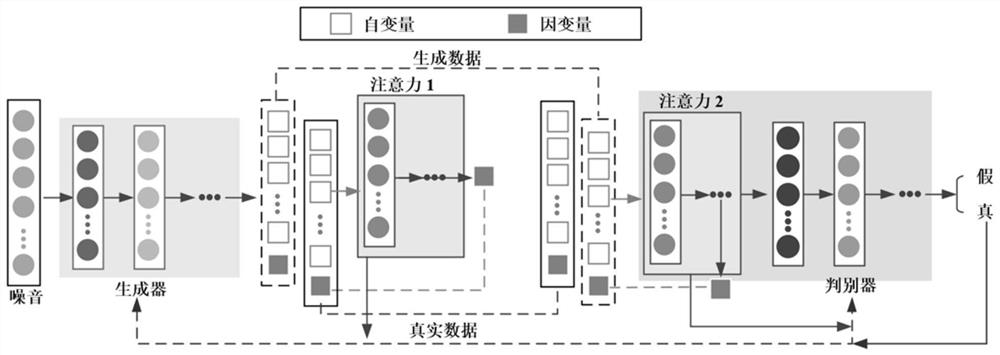
进一步地,所述回归注意力生成对抗网络引入了两个注意力模块,分别是生成器中的注意力模块1和判别器中的注意力模块2。
生成器是一个多层感知机,输入层输入的是随机噪声z,输出层输出生成数据D′。生成数据被分割成自变量x′
其中,D(·)是指判别器的输出,x~P
判别器也是一个多层感知机,用于判别输入的是真实数据还是生成数据。注意力模块2 设置在判别器网络的前端,也是一个多层感知机。输入的数据D或D’被分割成自变量和因变量,自变量被输入注意力模块2,经网络映射之后输出
其中,γ是注意力模块2的回归系数。之后,将
其中,D(·)是指判别器的输出,x~P
进一步地,所述注意力模块1的网络参数还可以由真实数据D进行微调,微调损失如下:
其中,M是真实数据的个数,α是微调系数。则生成器的损失函数还可以为L
本发明的有益效果是:本发明设计了一种回归注意力生成对抗网络(RA-GAN),将注意力机制引入生成对抗网络的生成器和判别器中,在网络参数训练时考虑了生成数据变量内部的关系。生成器中的注意力模块1利用生成器输出生成数据的自变量和因变量构建了回归损失;同时,真实数据也对注意力模块1进行了微调;判别器中的注意力模块2利用真实数据和生成数据回归损失的差值来构建新的损失;它通过最小化这个损失来提取包含最大回归信息的特征,并且这个特征包含了最大化的真实数据和生成数据之间的回归差异信息,有利于判别器对回归信息的考量。本发明基于回归注意力生成对抗网络利用生成的数据对原始数据进行增强,再利用数据驱动方法进行回归建模,有效得提升了回归模型的性能和预测精度。
附图说明
图1是基于回归注意力生成对抗网络(RA-GAN)的流程图;
图2是RA-GAN的生成器中注意力模块1流程图;
图3是RA-GAN的判别器中注意力模块2流程图;
图4是基于的RA-GAN的数据增强回归建模流程图;
图5是WGAN-GP和RA-GAN生成数据对支持向量回归模型数据增强的效果对比图。
具体实施方式
下面结合具体实施方式对本发明基于回归注意力生成对抗网络数据增强的回归建模方法作进一步的详述。
本发明提出的回归注意力生成对抗网络(RA-GAN)借鉴了带梯度惩罚项的Wasserstein 网络的基本结构,并引入了两个注意力模块,分别是生成器中的注意力模块1和判别器中的注意力模块2。本发明中的自变量为工业过程中的过程变量,因变量为对应的质量变量。
如图1所示,回归注意力生成对抗网络(RA-GAN)的生成器是一个多层感知机,输入层输入的是随机噪声z,隐含层的设置是[32,32],输出层输出生成数据 D′=[X′,Y′]={[x′
如图2所示,注意力模块1是一个多层感知机连接在生成器上,它的隐含层设置是[32];它的输入是生成数据的自变量x′
其中,D(·)是指判别器的输出,E表示期望,x~P
其中,M是真实数据的个数,α是微调系数;则生成器的损失函数还可以为L
如图3所示,注意力模块2设置在判别器网络的前端,RA-GAN的判别器也是一个多层感知机,它用于判别输入数据是真实数据还是生成数据,它的隐含层设置是[32,64,32]。
注意力模块2也是一个多层感知机,它的隐含层设置是[32]。输入的真实数据或生成数据被分割成自变量和因变量,真实数据的自变量x
其中,γ是注意力模块2的回归系数。
最小化L
其中,第一项是真实数据输入判别器后的输出的期望值,D(·)是指判别器的输出,x~P
如图4所示,基于上述RA-GAN,提出了工业过程中的数据增强的回归建模方法:
1、收集原始数据,在去除离群值和数据归一化后得到自变量x
2、将x
3、用D无监督地训练一个上述RA-GAN,直至其收敛。
4、用训练好的RA-GAN生成虚拟的数据D′=[X′,Y′]={[x′
5、将生成数据D’加入到真实数据集D中,进行数据增强,得到增强数据集{D,D’}。
6、将增强数据集的数据分割成自变量{X,X′}和因变量{Y,Y′},用于训练回归模型。
7、将测试数据的自变量输入到训练好的回归模型中,得到预测的因变量。
以下结合一个具体的二氧化碳吸收过程的例子来说明基于RA-GAN的数据增强回归建模的性能。二氧化碳吸收塔是尿素合成工业中的关键设备,它用来除去混合气体中的二氧化碳,防止其影响最后产品的质量。但是,二氧化碳含量是一种难以实时检测的变量,需要通过质谱仪离线分析才能得到。因此我们需要在小样本的情况下来建立二氧化碳的软测量模型。
表1:二氧化碳吸收过程自变量列表
二氧化碳吸收过程总共有11个自变量,如表1所示。我们收集了包含质变量和因变量在内的300个样本,将其中的100作为训练,剩余200个作为测试。在使用支持向量回归模型建立回归模型的基础上,分别用带梯度惩罚的Wasserstein生成对抗网络(WGAN-GP)和RA-GAN对其进行数据增强。WAGAN-GP和RA-GAN分别在相同的学习率和优化算法下迭代了12000个循环,图5展示了最后的结果,我们采用了回归模型预测结果与真实值的均方根误差(RMSE)来作为对比指标。
从图5中,我们可以看出,WGAN-GP由于没有考虑到生成数据变量间的回归关系,它所产生的生成数据增加新的回归信息,因此无法对原有的回归模型性能有所改善。然而RA-GAN在数据生成时,引入了对引变量的注意力机制,有效地保留了数据变量间的回归关系。因此它的数据增强效果是明显。此外,随着生成数据的增加,数据增强回归模型的性能也有相应的提升。
- 基于回归注意力生成对抗网络数据增强的回归建模方法
- 语音数据基于分簇聚类的分块高斯回归模型子集建模方法