适用于大数据的数据处理方法、装置、设备及介质
文献发布时间:2023-06-19 09:35:27
技术领域
本申请涉及到大数据技术领域,特别是涉及到一种适用于大数据的数据处理方法、装置、设备及介质。
背景技术
随着科技的发展,大数据得到越来越多的应用。现有大数据平台(包括数据管理系统、应用系统)的稳定性无法满足业务的需求,一旦系统宕机,数据需要重新同步;而且,现有大数据平台对需要实时计算的业务数据需求无法满足。
发明内容
本申请的主要目的为提供一种适用于大数据的数据处理方法、装置、设备及介质,旨在解决现有技术的大数据平台在系统宕机时需要重新同步数据、对需要实时计算的业务数据需求无法满足的技术问题。
为了实现上述发明目的,本申请提出一种适用于大数据的数据处理方法,所述方法包括:
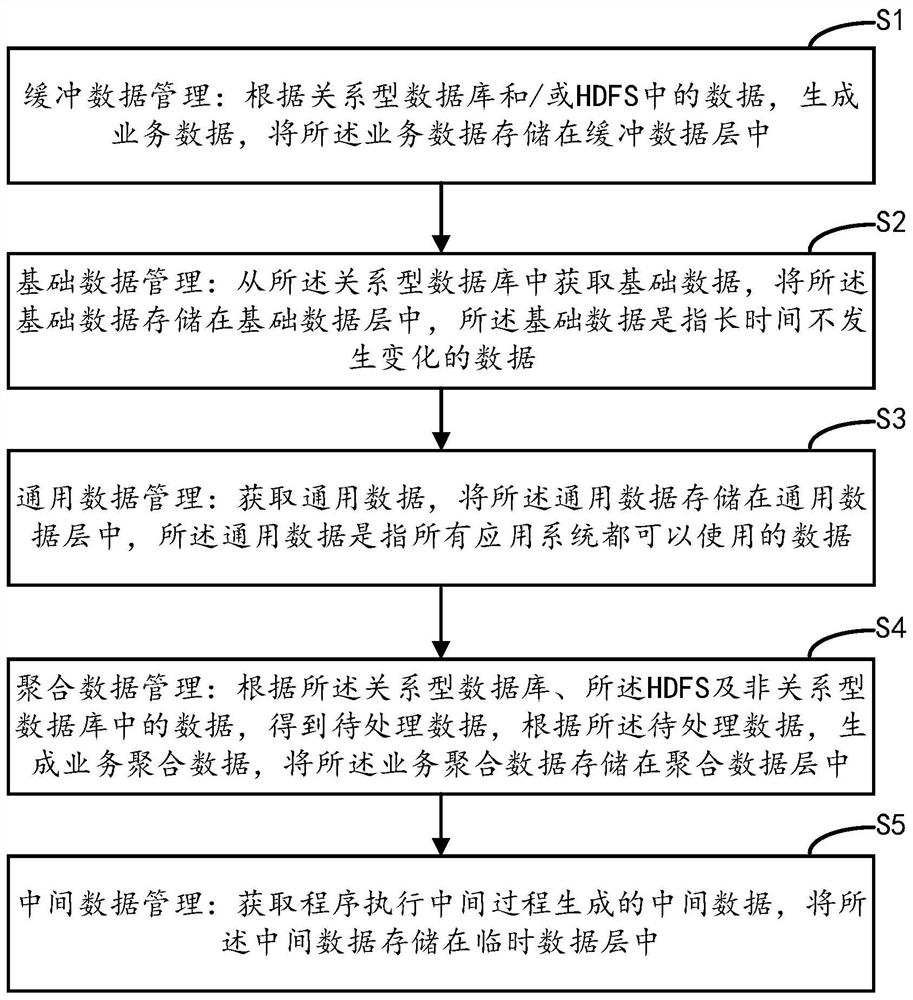
缓冲数据管理:根据关系型数据库和/或HDFS中的数据,生成业务数据,将所述业务数据存储在缓冲数据层中;
基础数据管理:从所述关系型数据库中获取基础数据,将所述基础数据存储在基础数据层中,所述基础数据是指长时间不发生变化的数据;
通用数据管理:获取通用数据,将所述通用数据存储在通用数据层中,所述通用数据是指所有应用系统都可以使用的数据;
聚合数据管理:根据所述关系型数据库、所述HDFS及非关系型数据库中的数据,得到待处理数据,根据所述待处理数据,生成业务聚合数据,将所述业务聚合数据存储在聚合数据层中;
中间数据管理:获取程序执行中间过程生成的中间数据,将所述中间数据存储在临时数据层中。
进一步的,所述根据关系型数据库和/或HDFS中的数据,生成业务数据,将所述业务数据存储在缓冲数据层中的步骤,包括:
获取业务数据生成请求;
根据所述业务数据生成请求,从所述关系型数据库和/或所述HDFS中获取数据,得到第一待处理数据;
根据所述第一待处理数据,生成所述业务数据;
将所述业务数据存储在缓冲数据层中。
进一步的,所述根据关系型数据库和/或HDFS中的数据,生成业务数据,将所述业务数据存储在缓冲数据层中的步骤之后,还包括:
获取业务数据查询请求;
根据所述业务数据查询请求,从所述缓冲数据层中进行查询,得到业务数据查询结果;
当所述业务数据查询结果为成功时,将所述业务数据查询结果对应的所述业务数据,作为目标业务数据。
进一步的,所述缓冲数据层设置在堆外内存中,所述堆外内存是指装载应用系统的服务器的内存。
进一步的,所述从所述关系型数据库中获取基础数据,将所述基础数据存储在基础数据层中,所述基础数据是指长时间不发生变化的数据的步骤之后,还包括:
获取基础数据查询请求;
根据所述基础数据查询请求,从所述基础数据层中进行查询,得到基础数据查询结果;
当所述基础数据查询结果为成功时,将所述基础数据查询结果对应的所述基础数据,作为目标基础数据;
当所述基础数据查询结果为失败时,根据所述基础数据查询请求,从所述关系型数据库中进行查询,得到所述目标基础数据。
进一步的,所述获取程序执行中间过程生成的中间数据,将所述中间数据存储在临时数据层中的步骤之后,还包括:
通过数据处理模块获取数据分析请求;
通过所述数据处理模块根据所述数据分析请求,调用Spark程序根据所述关系型数据库和/或所述HDFS中的数据进行数据分析,生成所述数据分析结果;
将所述数据分析结果存储在Hive库中。
进一步的,所述获取程序执行中间过程生成的中间数据,将所述中间数据存储在临时数据层中的步骤之后,还包括:
对于所述业务数据和所述业务聚合数据采用拉链表的方式进行存储。
本申请还提出了一种适用于大数据的数据处理装置,所述装置包括:
缓冲数据管理模块,用于根据关系型数据库和/或HDFS中的数据,生成业务数据,将所述业务数据存储在缓冲数据层中;
基础数据管理模块,用于从所述关系型数据库中获取基础数据,将所述基础数据存储在基础数据层中,所述基础数据是指长时间不发生变化的数据;
通用数据管理模块,用于获取通用数据,将所述通用数据存储在通用数据层中,所述通用数据是指所有应用系统都可以使用的数据;
聚合数据管理模块,用于根据所述关系型数据库、所述HDFS及非关系型数据库中的数据,得到待处理数据,根据所述待处理数据,生成业务聚合数据,将所述业务聚合数据存储在聚合数据层中;
中间数据管理模块,用于获取程序执行中间过程生成的中间数据,将所述中间数据存储在临时数据层中。
本申请还提出了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述任一项所述方法的步骤。
本申请还提出了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述任一项所述的方法的步骤。
本申请的适用于大数据的数据处理方法、装置、设备及介质,通过根据关系型数据库和/或HDFS中的数据,生成业务数据,将业务数据存储在缓冲数据层中,从关系型数据库中获取基础数据,将基础数据存储在基础数据层中,将通用数据存储在通用数据层中,根据关系型数据库、HDFS及非关系型数据库中的数据,得到待处理数据,根据待处理数据,生成业务聚合数据,将业务聚合数据存储在聚合数据层中,获取程序执行中间过程生成的中间数据,将中间数据存储在临时数据层中,因为数据存储在缓冲数据层、基础数据层、通用数据层、聚合数据层、临时数据层中,所以在系统宕机时,不需要对数据进行重新同步,缩短了宕机恢复服务的时间;又因为通过根据关系型数据库和/或HDFS中的数据,生成业务数据,将业务数据存储在缓冲数据层中,根据关系型数据库、HDFS及非关系型数据库中的数据,得到待处理数据,根据待处理数据,生成业务聚合数据,将业务聚合数据存储在聚合数据层中,所以能满足需要实时计算的业务数据需求,提高了系统的实时响应性能。
附图说明
图1为本申请一实施例的适用于大数据的数据处理方法的流程示意图;
图2为本申请的大数据平台的软件结构示意图;
图3为本申请一实施例的适用于大数据的数据处理装置的结构示意框图;
图4为本申请一实施例的计算机设备的结构示意框图。
本申请目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
本申请使用到的专业术语如下:
本申请的关系型数据库,是指采用了关系模型来组织数据的数据库,其以行和列的形式存储数据,以便于用户理解,关系型数据库这一系列的行和列被称为表,一组表组成了数据库。用户通过查询来检索数据库中的数据,而查询是一个用于限定数据库中某些区域的执行代码。关系模型可以简单理解为二维表格模型,而一个关系型数据库就是由二维表及其之间的关系组成的一个数据组织。
本申请的HDFS,也就是Hadoop分布式文件系统(HDFS),是指被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File System)。它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。HDFS是Apache Hadoop Core项目的一部分。
本申请的非关系型数据库,也称为NoSQL,不保证关系数据的ACID特性。NoSQL有如下优点:易扩展,NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。无形之间也在架构的层面上带来了可扩展的能力。大数据量,高性能,NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的无关系性,数据库的结构简单。
本申请的Hbase,是一个分布式的、面向列的开源数据库,Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PCServer上搭建起大规模结构化存储集群。与FUJITSU Cliq等商用大数据产品不同,HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。
本申请的Redis,也称为Remote Dictionary Server,即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set--有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
本申请的Hive,是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。
为了解决现有技术的大数据平台在系统宕机时需要重新同步数据、对需要实时计算的业务数据需求无法满足的技术问题,本申请提出了适用于大数据的数据处理方法,所述方法适用于大数据技术领域,所述方法同时适用于分布式存储技术领域。本申请可用于众多通用或专用的计算机系统环境或配置中。例如:个人计算机、服务器计算机、手持设备或便携式设备、平板型设备、多处理器系统、基于微处理器的系统、置顶盒、可编程的消费电子设备、网络PC、小型计算机、大型计算机、包括以上任何系统或设备的分布式计算环境等等。本申请可以在由计算机执行的计算机可执行指令的一般上下文中描述,例如程序模块。一般地,程序模块包括执行特定任务或实现特定抽象数据类型的例程、程序、对象、组件、数据结构等等。也可以在分布式计算环境中实践本申请,在这些分布式计算环境中,由通过通信网络而被连接的远程处理设备来执行任务。在分布式计算环境中,程序模块可以位于包括存储设备在内的本地和远程计算机存储介质中。所述方法将数据存储在缓冲数据层、基础数据层、通用数据层、聚合数据层、临时数据层中,所以在系统宕机时,不需要对数据进行重新同步,缩短了宕机恢复服务的时间;通过将业务数据存储在缓冲数据层中,将业务聚合数据存储在聚合数据层中,从而能满足需要实时计算的业务数据需求,提高了系统的实时响应性能。
参照图1,所述适用于大数据的数据处理方法包括:
S1:缓冲数据管理:根据关系型数据库和/或HDFS中的数据,生成业务数据,将所述业务数据存储在缓冲数据层中;
S2:基础数据管理:从所述关系型数据库中获取基础数据,将所述基础数据存储在基础数据层中,所述基础数据是指长时间不发生变化的数据;
S3;通用数据管理:获取通用数据,将所述通用数据存储在通用数据层中,所述通用数据是指所有应用系统都可以使用的数据;
S4:聚合数据管理:根据所述关系型数据库、所述HDFS及非关系型数据库中的数据,得到待处理数据,根据所述待处理数据,生成业务聚合数据,将所述业务聚合数据存储在聚合数据层中;
S5:中间数据管理:获取程序执行中间过程生成的中间数据,将所述中间数据存储在临时数据层中。
本实施例通过根据关系型数据库和/或HDFS中的数据,生成业务数据,将业务数据存储在缓冲数据层中,从关系型数据库中获取基础数据,将基础数据存储在基础数据层中,将通用数据存储在通用数据层中,根据关系型数据库、HDFS及非关系型数据库中的数据,得到待处理数据,根据待处理数据,生成业务聚合数据,将业务聚合数据存储在聚合数据层中,获取程序执行中间过程生成的中间数据,将中间数据存储在临时数据层中,因为数据存储在缓冲数据层、基础数据层、通用数据层、聚合数据层、临时数据层中,所以在系统宕机时,不需要对数据进行重新同步,缩短了宕机恢复服务的时间;又因为通过根据关系型数据库和/或HDFS中的数据,生成业务数据,将业务数据存储在缓冲数据层中,根据关系型数据库、HDFS及非关系型数据库中的数据,得到待处理数据,根据待处理数据,生成业务聚合数据,将业务聚合数据存储在聚合数据层中,所以能满足需要实时计算的业务数据需求,提高了系统的实时响应性能。
参照图2,示意出了大数据平台的软件结构,步骤S1至步骤S5的方法步骤适用于图2的大数据平台,所述大数据平台包括:数据管理系统、应用系统。所述数据管理系统用于管理所述大数据平台的所有数据,所述应用系统用于满足各种业务需求和所述大数据平台的部分数据。
对于步骤S1至步骤S5还可以有其他排列顺序,在此不做具体限定。
对于S1,从所述数据管理系统的关系型数据库和/或HDFS中获取数据,根据获取的数据生成业务数据,将所述业务数据存储在缓冲数据层中。也就是说,在查询业务数据前,业务数据已经生成并且存储在缓冲数据层中,查询业务数据只需要在缓冲数据层进行查询,从而提高了系统的实时响应性能。
所述业务数据,是指根据业务需求进行加工得到的数据。
对于S2,所述基础数据,是指静态数据,该数据长时间不发生变化。比如,身份证号码可以设置为基础数据,在此举例不做具体限定。
优选的,如图2所示,所述基础数据层设置在数据管理系统的数据集市的数据缓存模块(图2中的数据缓存)中。
对于S3,所述通用数据,是指所有所述应用系统都可以使用的数据。比如,城市信息可以设置为通用数据,在此举例不做具体限定。
优选的,当所述通用数据的数据量大于预设数据阈值时将所述通用数据层设置在装载所述应用系统的服务器的内存中,否则将所述通用数据层设置在所述数据管理系统的公共数据库中。
对于S4,通过所述数据管理系统的Disruptor服务组件和/或所述数据管理系统的实时抽取模块根据待处理数据,生成业务聚合数据,也就是说,业务聚合数据包括多条业务数据,多条业务数据包含至少一个维度的数据。
所述Disruptor服务组件,也就是图2中的Disruptor服务,也称为数据处理组件,是一个异步组件,类似中间件,用于针对大数据平台的数据源中的数据进行读功能、清洗功能、写入功能。可以供应用系统使用,也可以大数据平台的其他模块使用。
所述大数据平台的数据源包括关系型数据库、非关系型数据库。
优选的,所述业务聚合数据应用于描述同一个业务场景的数据。所述业务场景包括但不限于:广告、推荐。
优选的,所述聚合数据层设置在所述数据管理系统的关系型数据库、非关系数据库、Hbase、Redis中的一个或多个。
对于S5,其中,获取数据管理系统和/或应用系统在程序执行中间过程生成的中间数据,将所述中间数据存储在临时数据层中。也就是说,将所述临时数据层作为中转使用的,如果不设置临时数据层,在运行过程中生成的中间数据比较大,导致程序占用内存比较大,有可能出现内存溢出的异常。
优选的,所述临时数据层可以设置在大数据平台的关系型数据库和/或非关系型数据库中。从而有利于提升大数据平台的性能。
优选的,所述临时数据层还可以设置在大数据平台的HDFS、HBase、Redis、Hive中。
在一个实施例中,上述根据关系型数据库和/或HDFS中的数据,生成业务数据,将所述业务数据存储在缓冲数据层中的步骤,包括:
S111:获取业务数据生成请求;
S112:根据所述业务数据生成请求,从所述关系型数据库和/或所述HDFS中获取数据,得到第一待处理数据;
S113:根据所述第一待处理数据,生成所述业务数据;
S114:将所述业务数据存储在缓冲数据层中。
本实施例实现了生成业务数据,从而实现了在查询业务数据前,业务数据已经生成并且存储在缓冲数据层中,查询业务数据只需要在缓冲数据层进行查询,从而提高了系统的实时响应性能。
对于S111,数据管理系统获取所述业务数据生成请求。
所述业务数据生成请求,是指生成业务数据的请求。
所述业务数据生成请求,可以是应用系统发送的,也可以是数据管理系统的程序文件生成的,还可以是用户通过数据管理系统输入的。
对于S112,根据所述业务数据生成请求确定业务数据生成规则,根据所述业务数据生成规则从从所述关系型数据库和/或所述HDFS中获取数据,将获取到的数据作为第一待处理数据。也就是说,第一待处理数据中包括多个数据。
可以理解的是,所述业务数据生成规则,可以是业务数据生成请求携带的,也可以是提前存储在数据管理系统中的。
所述业务数据生成规则,是根据业务需求确定的生成业务数据规则。
对于S113,根据所述第一待处理数据按所述业务数据生成规则,生成所述业务数据。
对于S114:将所有所述业务数据存储在缓冲数据层中。
可以理解的是,所有所述业务数据还可以存储在数据管理系统的其他存储单元中,比如,关系型数据库,在此举例不做具体限定。
在一个实施例中,上述根据关系型数据库和/或HDFS中的数据,生成业务数据,将所述业务数据存储在缓冲数据层中的步骤之后,还包括:
S121:获取业务数据查询请求;
S122:根据所述业务数据查询请求,从所述缓冲数据层中进行查询,得到业务数据查询结果;
S123:当所述业务数据查询结果为成功时,将所述业务数据查询结果对应的所述业务数据,作为目标业务数据。
本申请实现了通过缓冲数据层响应业务数据查询请求,不需要加载数据库,从而提高了查询和获取业务数据的效率。
对于S121,数据管理系统获取所述业务数据查询请求。
所述业务数据查询请求,是指查询业务数据的请求。
业务数据查询请求可以是用户直接在数据管理系统输入的,也可以是数据管理系统的程序文件生成的,也可以是应用系统向数据管理系统发送的请求,还可以是所述大数据平台以外的系统通过所述大数据平台以外的系统与所述大数据平台的通信连接发送给数据管理系统的请求。
优选的,所述业务数据查询请求携带有业务数据查询请求标识。
所述业务数据查询请求标识可以是ID、名称等唯一标识一个业务数据查询请求的标识。
对于S122,根据所述业务数据查询请求,确定业务数据查询规则,根据所述业务数据查询规则从所述缓冲数据层中进行查询,当在所述缓冲数据层中查询到匹配的数据时确定业务数据查询结果为成功,否则确定业务数据查询结果为失败。
对于S123,当所述业务数据查询结果为成功时,将所述业务数据查询结果对应的所述业务数据,作为目标业务数据,可以理解的是,目标业务数据中包括至少一个业务数据。
优选的,将所述目标业务数据发送与业务数据查询请求标识对应的系统。
优选的,根据所述业务数据下载信息封装并发送所述目标业务数据。
优选的,所述业务数据下载信息可以是所述业务数据查询请求携带的,还可以是存储在所述数据管理系统中的。
所述业务数据下载信息包括:下载方式、存放地址。所述下载方式包括但不限于:按预设文件格式下载、直接发送。所述存放地址可以是所述数据管理系统中的存储地址,还可以是所述数据管理系统以外的系统的存储地址。
优选的,当所述业务数据查询结果为失败时,根据所述业务数据查询指令,从数据存储单元进行查询,得到所述目标业务数据,其中,所述数据存储单元包括:关系型数据库、HDFS、Hbase中的一个或多个。数据存储单元设置在所述数据管理系统中。
在一个实施例中,上述缓冲数据层设置在堆外内存中,所述堆外内存是指装载应用系统的服务器的内存。
本实施例通过将缓冲数据层设置在堆外内存中,从而有利于进一步提高查询和获取业务数据的效率。
可以理解的是,缓冲数据层还可以设置在所述数据管理系统中,在此不做具体限定。
在一个实施例中,上述从所述关系型数据库中获取基础数据,将所述基础数据存储在基础数据层中,所述基础数据是指长时间不发生变化的数据的步骤之后,还包括:
S21:获取基础数据查询请求;
S22:根据所述基础数据查询请求,从所述基础数据层中进行查询,得到基础数据查询结果;
S23:当所述基础数据查询结果为成功时,将所述基础数据查询结果对应的所述基础数据,作为目标基础数据;
S24:当所述基础数据查询结果为失败时,根据所述基础数据查询请求,从所述关系型数据库中进行查询,得到所述目标基础数据。
本实施例实现了通过基础数据层响应基础数据查询请求,从而提高了查询和获取基础数据的效率;而且在基础数据查询结果为失败时,继续在所述关系型数据库中进行查询,从而可以在基础数据层存放部分数据,提高了基础数据层响应基础数据查询请求的速度。
对于S21,数据管理系统获取所述基础数据查询请求。
所述基础数据查询请求,是指查询基础数据的请求。
基础数据查询请求可以是用户直接在数据管理系统输入的请求,也可以是数据管理系统的程序文件生成的,也可以是应用系统向数据管理系统发送的请求,还可以是所述大数据平台以外的系统通过所述大数据平台以外的系统与所述大数据平台的通信连接发送给数据管理系统的请求。
优选的,所述基础数据查询请求携带有基础数据查询请求标识。
所述基础数据查询请求标识可以是ID、名称等唯一标识一个基础数据查询请求的标识。
对于S22,根据所述基础数据查询请求,确定基础数据查询规则,根据所述基础数据查询规则从所述基础数据层中进行查询,当在所述基础数据层中查询到匹配的数据时确定基础数据查询结果为成功,否则确定基础数据查询结果为失败。
对于S23,当所述基础数据查询结果为成功时,将所述基础数据查询结果对应的所述基础数据,作为目标基础数据,可以理解的是,目标基础数据中包括至少一个基础数据。
优选的,将所述目标基础数据发送与所述基础数据查询请求标识对应的系统。
优选的,根据所述基础数据下载信息封装并发送所述目标基础数据。
优选的,所述基础数据下载信息可以是所述基础数据查询请求携带的,还可以是存储在所述数据管理系统中的。
所述基础数据下载信息包括:下载方式、存放地址。所述下载方式包括但不限于:按预设文件格式下载、直接发送。所述存放地址可以是所述数据管理系统中的存储地址,还可以是所述数据管理系统以外的系统的存储地址。
在一个实施例中,上述获取程序执行中间过程生成的中间数据,将所述中间数据存储在临时数据层中的步骤之后,还包括:
S51:通过数据处理模块获取数据分析请求;
S52:通过所述数据处理模块根据所述数据分析请求,调用Spark程序(也就是图2中的Spark)根据所述关系型数据库和/或所述HDFS中的数据进行数据分析,生成所述数据分析结果;
S53:将所述数据分析结果存储在Hive库中。
本申请通过响应数据分析请求,以实现数据挖掘,将挖掘得到的所述数据分析结果存储在Hive库,后续查询的时候只需要在所述Hive库中进行查找,避免每次根据查询进行计算,提高了响应速度。
其中,所述数据处理模块还包括:MapReduce、YARN。
所述MapReduce,是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
所述YARN(Yet Another Resource Negotiator,另一种资源协调者)是一种新的Hadoop资源管理器,它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
所述Hive库,是指把Hive当成一个“数据库”,它也具备传统数据库的数据单元,数据库(Database/Schema)和表(Table)。
所述Spark程序,也就是计算引擎,Spark是一种与Hadoop相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使Spark在某些工作负载方面表现得更加优越,换句话说,Spark启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。Spark是在Scala语言中实现的,它将Scala用作其应用程序框架。与Hadoop不同,Spark和Scala能够紧密集成,其中的Scala可以像操作本地集合对象一样轻松地操作分布式数据集。
在一个实施例中,上述获取程序执行中间过程生成的中间数据,将所述中间数据存储在临时数据层中的步骤之后,还包括:
对于所述业务数据和所述业务聚合数据采用拉链表的方式进行存储。
通过拉链表的方式,可以维护数据的历史状态有利于快速、高效的获取历史上任意一天的快照数据。
所述拉链表,是指维护历史状态,以及最新状态数据的一种表,拉链表根据拉链粒度的不同,实际上相当于快照,只不过做了优化,去除了一部分不变的记录,通过拉链表可以很方便的还原出拉链时点的客户记录。
在一个实施例中,所述缓冲数据层、所述基础数据层、所述通用数据层、所述聚合数据层、所述临时数据层中的一个或多个采用数据分拣技术进行数据存储。增加数据管理系统的数据库的读写能力,提高数据库的查询效率,提高大数据平台的数据吞吐量。
所述数据分拣技术包含分区表或分库。
所述分区表是将大表的数据分成称为分区的许多小的子集,另外,分区表的种类划分主要有:range(范围)、list(列表)和hash(散列)分区。划分依据主要是根据其表内部属性。同时,分区表可以创建其独特的分区索引。
数据库分布式核心内容就是数据切分(Sharding),以及切分后对数据的定位、整合。数据切分就是将数据分散存储到多个数据库中(也就是分库),使得单一数据库中的数据量变小,通过扩充服务器的数量缓解单一数据库的性能问题,从而达到提升数据库操作性能的目的。
数据切分根据其切分类型,可以分为两种方式:垂直(纵向)切分和水平(横向)切分;比横向切分是按属性划分为多张表,纵向按数据量划分为多张表。
在一个实施例中,所述数据管理系统采用数据集市进行数据查询。
数据集市是基于以上架构设计构建的面向业务条线的数据生产环境,为各条线提供了查询服务,包括:广告、推荐、搜索、财务、营销、运营等十几个部门,上千个用户提供数据服务。
参照图3,本申请还提出了一种适用于大数据的数据处理装置,所述装置包括:
缓冲数据管理模块100,用于根据关系型数据库和/或HDFS中的数据,生成业务数据,将所述业务数据存储在缓冲数据层中;
基础数据管理模块200,用于从所述关系型数据库中获取基础数据,将所述基础数据存储在基础数据层中,所述基础数据是指长时间不发生变化的数据;
通用数据管理模块300,用于获取通用数据,将所述通用数据存储在通用数据层中,所述通用数据是指所有应用系统都可以使用的数据;
聚合数据管理模块400,用于根据所述关系型数据库、所述HDFS及非关系型数据库中的数据,得到待处理数据,根据所述待处理数据,生成业务聚合数据,将所述业务聚合数据存储在聚合数据层中;
中间数据管理模块500,用于获取程序执行中间过程生成的中间数据,将所述中间数据存储在临时数据层中。
本实施例通过根据关系型数据库和/或HDFS中的数据,生成业务数据,将业务数据存储在缓冲数据层中,从关系型数据库中获取基础数据,将基础数据存储在基础数据层中,将通用数据存储在通用数据层中,根据关系型数据库、HDFS及非关系型数据库中的数据,得到待处理数据,根据待处理数据,生成业务聚合数据,将业务聚合数据存储在聚合数据层中,获取程序执行中间过程生成的中间数据,将中间数据存储在临时数据层中,因为数据存储在缓冲数据层、基础数据层、通用数据层、聚合数据层、临时数据层中,所以在系统宕机时,不需要对数据进行重新同步,缩短了宕机恢复服务的时间;又因为通过根据关系型数据库和/或HDFS中的数据,生成业务数据,将业务数据存储在缓冲数据层中,根据关系型数据库、HDFS及非关系型数据库中的数据,得到待处理数据,根据待处理数据,生成业务聚合数据,将业务聚合数据存储在聚合数据层中,所以能满足需要实时计算的业务数据需求,提高了系统的实时响应性能。
参照图4,本申请实施例中还提供一种计算机设备,该计算机设备可以是服务器,其内部结构可以如图4所示。该计算机设备包括通过系统总线连接的处理器、存储器、网络接口和数据库。其中,该计算机设计的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机程序和数据库。该内存器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的数据库用于储存适用于大数据的数据处理方法等数据。该计算机设备的网络接口用于与外部的终端通过网络连接通信。该计算机程序被处理器执行时以实现一种适用于大数据的数据处理方法。所述适用于大数据的数据处理方法,包括:缓冲数据管理:根据关系型数据库和/或HDFS中的数据,生成业务数据,将所述业务数据存储在缓冲数据层中;基础数据管理:从所述关系型数据库中获取基础数据,将所述基础数据存储在基础数据层中,所述基础数据是指长时间不发生变化的数据;通用数据管理:获取通用数据,将所述通用数据存储在通用数据层中,所述通用数据是指所有应用系统都可以使用的数据;聚合数据管理:根据所述关系型数据库、所述HDFS及非关系型数据库中的数据,得到待处理数据,根据所述待处理数据,生成业务聚合数据,将所述业务聚合数据存储在聚合数据层中;中间数据管理:获取程序执行中间过程生成的中间数据,将所述中间数据存储在临时数据层中。
本实施例通过根据关系型数据库和/或HDFS中的数据,生成业务数据,将业务数据存储在缓冲数据层中,从关系型数据库中获取基础数据,将基础数据存储在基础数据层中,将通用数据存储在通用数据层中,根据关系型数据库、HDFS及非关系型数据库中的数据,得到待处理数据,根据待处理数据,生成业务聚合数据,将业务聚合数据存储在聚合数据层中,获取程序执行中间过程生成的中间数据,将中间数据存储在临时数据层中,因为数据存储在缓冲数据层、基础数据层、通用数据层、聚合数据层、临时数据层中,所以在系统宕机时,不需要对数据进行重新同步,缩短了宕机恢复服务的时间;又因为通过根据关系型数据库和/或HDFS中的数据,生成业务数据,将业务数据存储在缓冲数据层中,根据关系型数据库、HDFS及非关系型数据库中的数据,得到待处理数据,根据待处理数据,生成业务聚合数据,将业务聚合数据存储在聚合数据层中,所以能满足需要实时计算的业务数据需求,提高了系统的实时响应性能。
本申请一实施例还提供一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现一种适用于大数据的数据处理方法,包括步骤:缓冲数据管理:根据关系型数据库和/或HDFS中的数据,生成业务数据,将所述业务数据存储在缓冲数据层中;基础数据管理:从所述关系型数据库中获取基础数据,将所述基础数据存储在基础数据层中,所述基础数据是指长时间不发生变化的数据;通用数据管理:获取通用数据,将所述通用数据存储在通用数据层中,所述通用数据是指所有应用系统都可以使用的数据;聚合数据管理:根据所述关系型数据库、所述HDFS及非关系型数据库中的数据,得到待处理数据,根据所述待处理数据,生成业务聚合数据,将所述业务聚合数据存储在聚合数据层中;中间数据管理:获取程序执行中间过程生成的中间数据,将所述中间数据存储在临时数据层中。
上述执行的适用于大数据的数据处理方法,通过根据关系型数据库和/或HDFS中的数据,生成业务数据,将业务数据存储在缓冲数据层中,从关系型数据库中获取基础数据,将基础数据存储在基础数据层中,将通用数据存储在通用数据层中,根据关系型数据库、HDFS及非关系型数据库中的数据,得到待处理数据,根据待处理数据,生成业务聚合数据,将业务聚合数据存储在聚合数据层中,获取程序执行中间过程生成的中间数据,将中间数据存储在临时数据层中,因为数据存储在缓冲数据层、基础数据层、通用数据层、聚合数据层、临时数据层中,所以在系统宕机时,不需要对数据进行重新同步,缩短了宕机恢复服务的时间;又因为通过根据关系型数据库和/或HDFS中的数据,生成业务数据,将业务数据存储在缓冲数据层中,根据关系型数据库、HDFS及非关系型数据库中的数据,得到待处理数据,根据待处理数据,生成业务聚合数据,将业务聚合数据存储在聚合数据层中,所以能满足需要实时计算的业务数据需求,提高了系统的实时响应性能。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来请求相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的和实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可以包括只读存储器(ROM)、可编程ROM(PROM)、电可编程ROM(EPROM)、电可擦除可编程ROM(EEPROM)或闪存。易失性存储器可包括随机存取存储器(RAM)或者外部高速缓冲存储器。作为说明而非局限,RAM以多种形式可得,诸如静态RAM(SRAM)、动态RAM(DRAM)、同步DRAM(SDRAM)、双速据率SDRAM(SSRSDRAM)、增强型SDRAM(ESDRAM)、同步链路(Synchlink)DRAM(SLDRAM)、存储器总线(Rambus)直接RAM(RDRAM)、直接存储器总线动态RAM(DRDRAM)、以及存储器总线动态RAM(RDRAM)等。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、装置、物品或者方法不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、装置、物品或者方法所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、装置、物品或者方法中还存在另外的相同要素。
以上所述仅为本申请的优选实施例,并非因此限制本申请的专利范围,凡是利用本申请说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本申请的专利保护范围内。
- 适用于大数据的数据处理方法、装置、设备及介质
- 基于大数据的薪酬数据处理方法、装置、设备及存储介质