一种基于深度卷积的水稻知识文本分类方法
文献发布时间:2023-06-19 09:38:30
技术领域
本发明涉及数据处理技术领域,特别涉及一种基于深度卷积的水稻知识文本分类方法。
背景技术
从农业文本数据中提取出水稻的草害药害、病虫害以及栽培管理等数据是典型的文本分类问题,其对文本关键信息抽取、文本数据挖掘以及农业智能问答等均具有十分重要的意义。魏芳芳等根据农业文本数据特征,构建农业行业词库,并通过特征词筛选和权重计算,构建一种基于线性支持向量机的中文农业文本分类模型,该方法并未考虑数据集线性不可分的情况,存在一定的局限性。对于中文文本分类,尤其是农业文本,存在着数据冗余性、稀疏性和规范性差等特征,采用传统的机器学习方法对大数据量的农业文本进行分类难度较大,且适应性差,特征工程复杂。
随着计算机技术的迅猛发展,深度卷积神经网络(CNN)、循环神经网络(RNN)和胶囊网络(CapsNet)等深度学习技术逐渐成为目前主流的分类方法。现今国内外学者采用深度学习技术在英文和中文文本分类上开展了大量的研究。金宁等使用TF-IDF和Word2Vec方法相结合生成词向量,构建BiGRU_MulCNN农业问答问句分类模型。贾旭东等采用多头注意力胶囊网络对英文文本进行分类,分类准确率较高。以上研究表明,相比传统的文本分类方法,深度学习技术在文本分类中具有更好的分类效果。
文本分词处理:相对英文文本,中文文本的处理相对复杂。中文字与字之间没有间隔,并且单个汉字具有的意义也明显弱于词组,因此采用Jieba方法对水稻知识文本进行分词处理,并去除文本中无用符号和停用词等。与此同时,中文分词结果深受分词词库的影响,为提高水稻知识文本分词精度,减少错分、漏分和误分情况,在搜狗农业语料库基础上构建水稻相关语料库,进而扩大Jieba分词基础词库,提高对水稻病虫害、草害药害和栽培管理等专业词汇的辨识度。
文本向量化处理:由于网络模型无法对自然语言进行直接训练学习,并且中文文本语句中存在大量的语义信息、上下文依赖信息和语序信息等,直接采用中文文本将无法保留这些信息的完整性,因此将中文文本转换为多维且连续的向量至关重要。采用Word2Vec[27]的Skip-Gram模型对水稻知识文本进行向量化处理。
ResNet-18网络结构:建立特征提取层网络是解决文本分类问题的前提基础,而CNN在图像和文本特征提取问题上取得了较好的提取精度。ResNet是CNN的典型代表,其残差模块(包括直接映射和残差部分)的设计理念使得随着网络层数的增加,网络发生退化的现象得以解决,且在ILSVRC 2015竞赛中其分类和特征提取的效果上得到了充分肯定。
ResNet-18网络多用于图像分类,其采用多个3×3的二维卷积核Conv2D从图像矩阵的行维度和列维度进行特征提取,但文本向量是由规定长度的词向量按一定顺序构建的向量矩阵,所以从矩阵的行维度卷积(即从左至右移动)没有实际意义。因此采用多个大小为n的一维卷积核(Conv1D)仅从向量矩阵的列维度进行卷积。但由上图可知,ResNet-18被采用一维最大池化方法(Maxpooling1D)的池化层分割为3个部分,前两部分由17个大小为7和3、通道数为8、16、32和64的卷积层构成,后一部分仅采用1个通道数为4的全连接层。显然直接将上述ResNet网络结构用于水稻知识文本特征提取有较多不适的地方。首先相比图像具有颜色和形状等规律性特征,水稻知识每一类数据均由几十个甚至更多的关键词组成,生成的文本向量具有一定复杂性,因此仅采用[3Conv1D,3Conv1D]结构的残差模块无法较为精准地提取文本特征。其次水稻知识文本向量具有较大离散性和稀疏性,直接采用18个权重层的ResNet网络结构易造成过拟合。
发明内容
为解决以上所述的技术问题,本发明提供了一种基于深度卷积的水稻知识文本分类方法,解决了文本特征提取不准确和网络层次加深导致模型分类性能变差的技术问题。
本发明的技术方案为:
一种基于深度卷积的水稻知识文本分类方法,包括以下步骤:
S1.通过采用Python爬虫框架,爬取知网专家在线系统和种植问答网的关于水稻病虫害、草害药害以及栽培管理的中文文本问答数据;
S2.采用Word2Vec中的Skip-Gram模型对水稻知识文本进行向量化处理,词向量维度大小为100,训练窗口设置为5,同时与One-Hot、TF-IDF和Hashing向量化模型进行对比分析;
S3.构建文本特征提取网络;
S4.构建文本分类网络。
可优选地,所述步骤S3包括步骤:
S31.面向卷积通道对ResNet的残差模块进行更改与设计:
首先将ResNet的单通道卷积组调整为多通道卷积组,用以减少文本特征的表征性瓶颈,即减少信息损失;
其次通过增加大小为1的卷积核对文本向量进行降维,并加入非线性,进而降低网络模型参数和提高网络的表达能力,共设计了4种残差模块结构;
S32.为对比残差模块结构对文本分类的影响,共配置了4种水稻知识文本分类网络结构,并通过后续试验分析,筛选分类性能较高的残差结构;
与此同时,在保持较优残差结构不变的前提下,通过增加残差模块数量探究网络层次对分类精度的影响。
可优选地,所述4种残差模块结构的结构式分别为(1)(2)(3)(4)所示:
基于上述4种残差模块结构,配置了4种水稻知识文本分类网络结构,
残差模块结构(1)配置网络结构Embedding-A-Maxpool/2-FC/128-FC/4-softmax,
残差模块结构(2)配置网络结构Embedding-B-Maxpool/2-FC/128-FC/4-softmax,
残差模块结构(3)配置网络结构Embedding-C-Maxpool/2-FC/128-FC/4-softmax,
残差模块结构(4)配置网络结构Embedding-D-Maxpool/2-FC/128-FC/4-softmax。
可优选地,所述步骤S4采用所述4种水稻知识文本分类网络结构,采用胶囊网络替代池化层,并结合所述4种残差网络结构,构建面向问答系统的水稻知识文本分类模型。
本发明相对于现有技术,有以下有益效果:
发明为解决文本特征提取不准确和网络层次加深导致模型分类性能变差等问题。
本发明基于ResNet[24]和Inception V[25]网络结构的基本原理,以Top-1准确率为判断标准,分别从网络模块结构和网络层次进行分析,筛选具有最佳特征提取性能的CNN网络结构。
本发明以提高准确率、召回率、F1值和正确率为目标,将筛选出的CNN网络结构与CapsNet相结合,建立水稻知识文本分类模型,以期为水稻知识文本的精准分类提供科学和理论依据。
附图说明
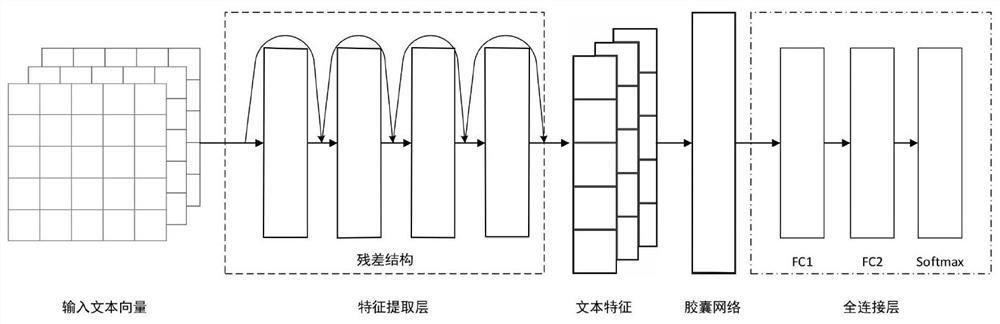
图1为本发明的面向问答系统的水稻知识文本分类模型网络结构;
图2为本发明的多种分类模型训练误差比较图。
具体实施方式
下面结合具体实施例对本发明做进一步说明,但本发明不受实施例的限制。
本发明提供了一种基于深度卷积的水稻知识文本分类方法,包括步骤如下:
S1.通过采用Python爬虫框架,爬取知网专家在线系统和种植问答网的关于水稻病虫害、草害药害以及栽培管理的中文文本问答数据。
S2.采用Word2Vec中的Skip-Gram模型对水稻知识文本进行向量化处理,词向量维度大小为100,训练窗口设置为5。同时与One-Hot、TF-IDF和Hashing向量化模型进行对比分析。
S3.构建文本特征提取网络:
S31.首先,受Inception V系列网络结构的启发,面向卷积通道对ResNet的残差模块进行更改与设计。首先将ResNet的单通道卷积组调整为多通道卷积组,用以减少文本特征的表征性瓶颈,即减少信息损失,其次通过增加大小为1的卷积核对文本向量进行降维,并加入非线性,进而降低网络模型参数和提高网络的表达能力,因此共设计了4种残差模块结构,如表1所示:
表1 面向通道的4种残差模块结构
S32.为对比残差模块结构对文本分类的影响,共配置了4种水稻知识文本分类网络结构,如表2所示,并通过后续试验分析,筛选分类性能较高的残差结构。与此同时,在保持较优残差结构不变的前提下,通过增加残差模块数量探究网络层次对分类精度的影响。
表2 基于4种残差模块结构的网络结构
S4.构建文本分类网络:
如果采用上述分类网络直接用于水稻知识文本分类,均需要采用池化层进行下采样操作。虽然池化层具有降低特征维度,减小模型参数等作用,但是在池化过程中丢失了一定的文本中词组相对位置特征,影响模型分类精度。因此本发明采用胶囊网络(CapsNet)替代池化层,并结合前文的4层残差网络结构,构建面向问答系统的水稻知识文本分类模型,简称为RIC-Net,其网络架构如图1所示。
本实施例通过采用Python爬虫框架,爬取知网专家在线系统和种植问答网等关于水稻病虫害、草害药害以及栽培管理等中文文本问答数据。
同时,对所获数据进行初步人工筛选,最终获得14527条有效数据,其中水稻病虫害、草害药害、栽培管理和其他数据分别为5640、1335、1492和6060条。水稻知识数据主要用于文本分类网络的模型训练与测试,每次试验从各类数据集中随机抽取80%作为训练集,10%作为验证集,剩余10%作为测试集。
本实施例采用Word2Vec中的Skip-Gram模型对水稻知识文本进行向量化处理,词向量维度大小为100,训练窗口设置为5。同时与One-Hot、TF-IDF和Hashing向量化模型进行对比分析。对4种模型训练得到的文本向量进行浅层神经网络建模,其精准率、召回率和F1值的宏平均结果如表3所示:
表3 4种文本向量化建模结果
Table 3 The results of four kinds of text vectorization modeling
由表3可知,4种基于文本向量化方法构建的浅层神经网络中,Word2Vec方法相比其他方法具有最高的分类精度,正确率为86.44%,Hashing方法的分类效果最差。这可能是由于One-Hot所产生的向量维度较高,存在稀疏性,影响了神经网络的分类效果,TF-IDF和Hashing虽然考虑字词间的语义信息,但问题也较为明显,这两种方法没有解决向量维度高和数据稀疏的问题,并且随着提取连续字的集合的增大,维度将会变得更高。从每一类的分类效果来看,基于4种向量化方法的浅层神经网络在栽培管理和病虫害上分类效果较好,在其他两个类别上效果较差,原因在于草害药害和其他类别的数据量较小所致。但相较而言,Word2Vec在草害药害和其他两个类别上向量化效果较好,网络模型能较为准确地提取到一定的文本特征,因此本发明采用Word2Vec模型构建文本向量作为后续研究的数据基础。
采用Word2Vec生成的4类14527条水稻知识文本向量作为样本,随机选取80%数据作为训练集,10%作为验证集,并根据表2中4种模块结构,分别构建分类模型,开展相关试验与分析。采用Top-1准确率作为评价指标,建模结果如表4:
表4 基于4种残差模块结构的网络分类性能
Table 4 Network classification performance based on 4 kinds ofresidual modules
注:Top-1准确率为判断概率最大的类别与实际类别相符的准确率。
由表4可知,基于4种残差模块构建的网络模型均具有较好的分类精度,Top-1准确率达95%以上,其中残差模块C所构建的分类模型具有最高的分类精度,Top-1准确率为99.59%,残差模块D、A和B的分类性能逐渐降低。这可能是由于残差模块C在各个通道卷积的第一层均采用了大小为1的卷积核,其能够在一定程度上增加非线性激励,提高了网络的表达能力,同时卷积通道数的增加使卷积核的数量增大,能够更充分地从数据中获取更多的文本特征。因此残差模块C具有最佳的文本特征提取能力。与此同时,本实施例在保持残差模块C的基本结构不变的基础上,通过增加残差模块的数量(即增大网络深度)进行进一步训练与分析,结果如表5:
表5 基于不同残差模块数量的网络分类性能
Table 5 Network classification performance based on the number ofdifferent residual modules
注:C×2等表示连续2个残差模块A,下同。
Note:C×2 and so on represent continuous 2 residual module A,the sameas below.
由表5可以看出,针对水稻知识文本样本,在保持残差结构相同的情况下,网络III的分类效果最佳,Top-1准确率为99.79%,网络I和II的分类效果略差,说明当残差模块较少时,可适当增加模块数量,提高文本分类精度。但在网络III的基础上,再增加残差模块数量时,网络的整体性能开始趋于饱和,分类精度有所下降。可能原因在于水稻知识数据中存在“共享词汇”,随着残差模块的增加,卷积数增大,模型训练得到一定共享词汇等的非主要文本特征,从而影响模型测试精度。
但是如果采用上述分类网络直接用于水稻知识文本分类,均需要采用池化层进行下采样操作。虽然池化层具有降低特征维度,减小模型参数等作用,但是在池化过程中丢失了一定的文本中词组相对位置特征,影响模型分类精度。因此本实施例采用胶囊网络(CapsNet)替代池化层,并结合前文的4层残差网络结构,构建面向问答系统的水稻知识文本分类模型,简称为RIC-Net。
在RIC-Net模型中,特征提取层的卷积滤波器数量分别为8、16、32和64,CapsNet的输出数量和维度均为50,动态路由轮数为3,在全连接层中FC1和FC2神经元个数分别设置为128和4。另外,采用Nadam算法(Nesterov-accelerated Adam)[32]对模型进行训练,初始学习率为0.002,一阶和二阶指数衰减率分别为0.9和0.999。与此同时,经多次实验得出,经过50代训练,网络模型的训练损失均收敛到稳定值。为对比本文方法的分类效果,利用同一样本数据,分别训练FastText、BiLSTM、DPCNN和RCNN等6种常用文本分类模型,训练误差结果如图2。
由图2可以看出,随着训练次数的增加,各个模型的训练误差均呈现不同程度的降低,当降低到一定程度后训练损失均收敛到稳定。在训练初始阶段,RIC-Net的训练误差下降最快,说明RIC-Net能够较为精准地提取文本特征,模型更易收敛。同时,RIC-Net、TextCNN和RCNN训练效果较好,当训练到45次时不仅达到收敛状态,且训练损失值在(0,0.036)之间,基本达到训练要求。
采用余下的10%作为测试集分别采用RIC-Net和其他6种文本分类方法进行测试与分析,并采用精准率、召回率、F1值以及正确率作为模型分类性能评价指标,结果如表6:
表6 不同分类网络的测试结果比较
Table 6 Comparison of test results with different classificationnetworks
注:类1、类2、类3和类4分别代表栽培管理、病虫害、草害药害和其他4个水稻知识类别。
Note:Categories 1,2,3and 4 respectively represent cultivationmanagement,pests and diseases,weeds and drugs,and four other rice knowledgeclassifications.
由表6可知,RIC-Net与FastText、BiLSTM和DPCNN等6种分类模型相比,RIC-Net在栽培管理、病虫害、草害药害和其他类别上均具有较高的分类性能,对水稻知识的4种文本类型分类的精准率、召回率和F1值分别大于95.10%、95.80%和97.50%,在测试集的正确率方面,RIC-Net同样高于其他模型,正确率为98.62%。这是由于RIC-Net借鉴了ResNet和Inception V的基本思想,采用多通道和残差模块的结构构建特征提取层,精准提取水稻知识文本特征,同时将CapsNet替换池化层,保留了词组间相对位置特征,从而提高了模型分类精度。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进,这些改进也应视本发明的保护范围。
- 一种基于深度卷积的水稻知识文本分类方法
- 融合知识图谱的深度学习文本分类方法