一种面向多可疑代码文件的缺陷定位方法
文献发布时间:2023-06-19 09:49:27
技术领域
本发明涉及一种面向多可疑代码文件的缺陷定位方法,属于软件开发过程中软件缺陷定位与修复的技术领域。
背景技术
软件缺陷定位是软件缺陷修复的一个关键步骤,对于保障软件质量具有重要作用。对于缺陷修复人员来说,缺陷定位也是一项耗时且痛苦的过程。为了帮助软件开发人员更好的修复软件缺陷,研究人员提出了一系列静、动态的缺陷定位方法。动态缺陷定位方法通常通过执行测试用例分析软件运行结果来定位缺陷,其往往要求可运行的软件程序和相应的测试用例集;静态缺陷定位方法主要通过挖掘软件制品的一些静态信息进行定位,其通常可应用于软件制品开发和维护的各个阶段。本发明也主要专注于提出一种静态的面向多可疑代码文件的软件缺陷定位方法。
在软件开发实践中,一个软件缺陷的修复可能涉及到多个代码文件的修改。这种涉及多可疑代码文件修改的软件缺陷修复在真实软件开发过程中非常普遍。根据我们对六个主流软件项目(包括Tomcat、ZooKeeper、Lucene、AspectJ、Hibernate和OpenJPA)的4587个软件缺陷的修复统计结果,我们发现,多达2453(53.48%)个软件缺陷的修复涉及到了最少两个代码文件的修改。然而,通过实验分析,我们发现目前的静态缺陷定位技术并不能对这种涉及多可疑代码文件的缺陷进行有效定位:我们分析了当前最主流的三种静态缺陷定位技术(包括BugLocator、LR和Blizzard)的定位结果,发现它们均不能很好地将这2453个软件缺陷的多个可疑代码文件准确定位。在2453个软件缺陷中,有1538个软件缺陷的可疑代码文件未被三种技术准确识别,其中,868个软件缺陷只有一个可疑代码文件被准确定位。
发明内容
本发明为了解决已有定位技术无法较好处理涉及多可疑代码文件的软件缺陷定位问题,提供了一种面向多可疑代码文件的缺陷定位方法,采用基于多源特征的机器学习模型和基于代码控制流、数据流等代码依赖的程序分析技术,对涉及多个可疑代码文件的软件缺陷进行有效定位,进而帮助开发者更高效、完备地修复软件缺陷,提升软件的质量。本发明适用于软件缺陷的修复涉及到修改多个可疑代码文件的应用场景。其目的在于为软件开发人员在修复涉及多个可疑代码文件的软件缺陷时提供指导,是一种辅助软件开发人员在有限时间内完备修复软件缺陷的缺陷定位方法。
本发明为解决上述技术问题采用以下技术方案:
一种面向多可疑代码文件的缺陷定位方法,具体步骤如下:
步骤1、初始可疑代码文件列表生成
1.1、对给定的一个缺陷报告及其对应的软件项目代码,分别通过LR(Learning-to-Rank)、Blizzard和BugLocator三种基于信息检索的缺陷定位算法得到三个可疑代码文件推荐列表;
1.2、利用机器学习中的Ensemble集成方法将三个可疑代码文件推荐列表进行整合,得到整合后的可疑代码文件推荐列表;
1.3、将整合后的可疑代码文件推荐列表中的前N个可疑代码文件作为初始可疑代码文件列表;
步骤2、真实可疑代码文件子集获取
基于缺陷报告质量特征、文本相似性特征和缺陷报告者经验特征三种特征构建一个基于多源特征的机器学习预测模型,从初始可疑代码文件列表中抽取真实可疑代码文件子集;
步骤3、可疑代码文件列表优化
3.1、利用程序分析技术,对真实可疑代码文件子集分别进行控制流依赖、数据流依赖和共现依赖分析,得到三个可疑代码文件候选列表;
3.2、对三个可疑代码文件候选列表进行线性加权组合,将组合后得到的列表追加在真实可疑代码文件子集后面,形成最终的可疑代码文件列表,该列表将作为最终的推荐列表输出给开发人员帮助其进行缺陷定位。
进一步,步骤2中缺陷报告质量特征包括软件行为、重现步骤和可读性,基于wordnet扩展的文本相似性特征包括tf-idf、主题和词嵌入语义向量相似性,缺陷报告者的经验特征包括历史代码贡献、缺陷修复经验和缺陷报告经验。
进一步,步骤2中基于多源特征的机器学习预测模型是一个卷积神经网络CNN,CNN的输入层为每个可疑代码文件的三维特征,隐藏层为5个全连接层,输出层使用逻辑回归函数,CNN的输出是可疑代码文件是否为真实的可疑代码文件,通过历史代码文件集对CNN进行训练,其中,历史代码文件集中包括真实可疑代码文件以及真实无缺陷代码文件。
进一步,对于初始可疑代码文件列表中的每个可疑代码文件,在获取其对应的缺陷报告质量特征、文本相似性特征和报告者经验特征后,输入训练完成的CNN,根据CNN的输出结果从初始可疑代码文件列表中抽取真实可疑代码文件子集。
进一步,5个全连接层的节点数为512、256、128、64、32。
进一步,步骤3中线性加权组合的公式为:
S=∑w
其中,w
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
1)本发明提出了一种新的方法,该方法能有效对涉及多个可疑代码文件的软件缺陷进行分析并定位;
2)本发明针对已有技术忽略文件代码依赖导致定位不准的问题,提出了整合代码控制流依赖、数据流依赖和共现依赖三种代码关系的多可疑代码文件排序机制;
3)本发明提出了基于多源特征的真实可疑文件子集预测模型,结合主流信息检索定位技术,以缺陷报告、开发人员经验等多源特征为数据基础,构建了能有效缩小可疑代码文件搜索空间的预测机制。
附图说明
图1是本发明的方法流程图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
本发明中提出了一种面向多可疑代码文件的软件缺陷定位方法,旨在使用基于多源特征的机器学习技术和基于多种代码依赖的程序分析技术有效完备地定位涉及多个可疑代码文件的软件缺陷,辅助软件开发人员高效且准确的修复软件缺陷。
本发明的基本思想为:先利用基于多源特征的机器学习模型抽取真实可疑的代码文件子集,随后利用该子集,通过基于代码控制流和数据流等依赖的程序分析技术,定位剩余的可疑代码文件。具体而言,在本发明中,我们首先利用三种基于信息检索的主流缺陷定位技术获取一个初始的可疑代码文件列表。随后基于三种特征(包括缺陷报告质量特征、文本相似性特征和缺陷报告者经验特征)构建机器学习模型,从初始的可疑代码文件列表抽取真实的可疑代码文件子集。考虑到软件缺陷可能随着程序元素的各种依赖关系如控制流依赖传播到代码的各个地方,针对这部分可疑代码文件子集,我们利用程序分析技术,对代码文件间的三种依赖关系(包括控制流依赖、数据流依赖和共现(同时出现)依赖)进行分析,从而定位到剩余的可疑代码文件。通过该方法,可以帮助软件开发人员在有限的时间内,及时准确地明晰缺陷修复所需处理的各个问题点,提高缺陷修复的效率和完备性,为软件质量的保障提供技术支持。
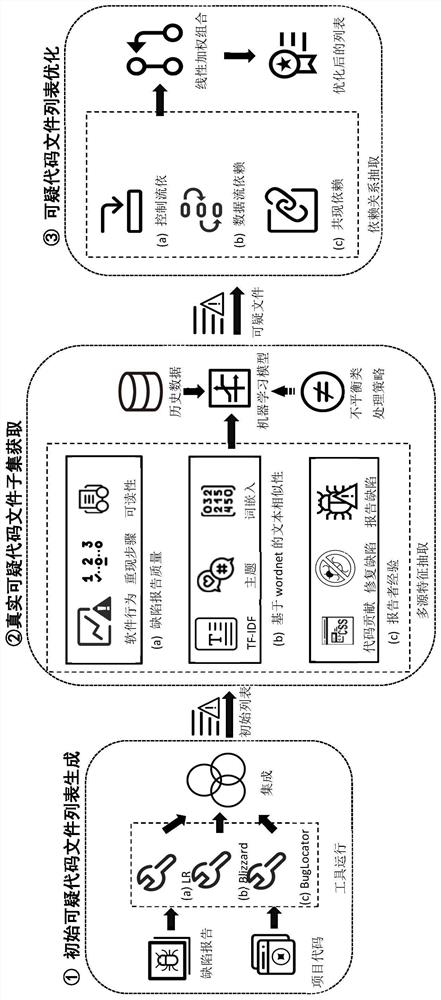
如图1所示,本发明的技术方案包括初始可疑代码文件列表生成、真实可疑代码文件子集获取、可疑代码文件列表优化三部分。
在初始可疑代码文件列表生成部分,我们主要通过运行三种算法LR、Blizzard和BugLocator并对三种算法的结果进行集成得到初始的可疑代码文件列表。在真实可疑代码文件子集获取部分,我们构建一个基于多源特征的机器学习预测模型以从初始的可疑文件列表中获取真实的可疑代码文件子集。在优化可疑代码文件列表部分,我们基于前一步获取的真实可疑代码文件子集,利用代码依赖关系对推荐列表进行优化以获取剩余的可疑代码文件列表。下面对每一步进行稍微详细的介绍。
初始可疑代码文件列表生成
给定一个缺陷报告及其对应的软件项目代码,首先运行三种基于信息检索的缺陷定位工具LR、Blizzard和BugLocator。这三种工具将分别输出一个可疑代码文件列表。随后利用机器学习中的Ensemble集成方法将三种列表进行整合,得到一个新的可疑代码文件推荐列表。Ensemble技术能较好的整合三种工具的优点,使所得到的初始代码文件列表质量更高,从而能较好的作为本发明所提面向多可疑代码文件的缺陷定位技术的定位基础。
具体来说,该部分的输入包括缺陷报告和项目代码。这两部分数据是运行BugLocator、LR和Blizzard的输入。对于缺陷报告,抽取其概括性标题(title)和详细问题描述(description)两个条目内容。其中,对于BugLocator和Blizzard,缺陷报告的title和description无需预处理;LR要求title和description进行按空格分词、去停用词(使用nltk停用词列表)、切词、去特殊符号、去数字、去词干(使用Porter)的预处理操作。对于项目代码部分,Blizzard的输入为原始的项目代码库,BugLocator需将项目代码的文件名转换成包名表示的形式(即xx.xx.xx.java)。LR要求代码文件抽成一个个函数(使用JDT接口实现)。在运行LR、Blizzard和BugLocator时,需额外为LR和BugLocator提供相应的参数设置。在本发明中,LR的数据集折数M建议设置为10(如果数据集相对较小,如每折少于100个实例,可将M设置为5),LR的另一个参数capacity C设置为300。BugLocator的权重因子alpha设置为0.2。这些参数设置被实验证明能帮助获取较好的实验结果。运行三个工具得到三个可疑代码文件推荐列表后,使用机器学习中的集成学习Ensemble方法对其进行整合,本发明使用已在实践中被证实具有良好效果的AdaBoostM1方法进行推荐序列的组合,实现手段为调用Weka工具中的AdaBoostM1方法。随后将整合后的推荐列表作为本发明所提技术的初始可疑代码文件推荐列表。考虑到BugLocator等三种工具在推荐可疑文件数为20的时候,基本能确保推荐列表中至少有一个真实的可疑代码文件。为此,在用AdaBoostM1获取到整合后的可疑代码文件推荐列表后,在尽量保证推荐列表中包含真实可疑代码文件和降低其搜索空间的情况下,将列表中的前N(N可以取20或者根据使用者的需求取更大值)个可疑代码文件作为初始可疑代码文件列表,输入到下一个处理环节,即真实可疑代码文件子集获取环节。
真实可疑代码文件子集获取
在经过上述步骤得到初始的可疑代码文件初始列表后,针对该列表的前N个推荐结果,构建一个基于多源特征的机器学习预测模型。该模型用于从初始可疑代码文件列表中,预测真实的可疑代码文件子集。为构建预测模型所利用的多源特征包括缺陷报告质量特征(即软件行为、重现步骤和可读性)、基于wordnet扩展的文本相似性特征(即tf-idf、主题和词嵌入语义向量相似性)、缺陷报告者的经验特征(即历史代码贡献、缺陷修复经验和缺陷报告经验)。使用主流的机器学习算法基于这些特征进行预测模型的训练,在训练过程中,针对不平衡类问题,使用不平衡类处理策略如抽样等进行处理。在构建好预测模型后,抽取推荐列表的N个实例的上述特征,进行其是否是真实可疑代码文件的预测。
具体来说,在得到长度为N的初始可疑代码文件列表后(该列表大概率包含了真实的可疑代码文件但尚未知道列表中的具体哪个(些)文件为真实可疑的),该部分的主要工作为构建一个模型,将该初始列表中的真实可疑代码文件在列表中的位置锁定。本发明拟构建一个基于多源特征的机器学习模型来预判初始列表中一个可疑代码文件是否是真实可疑的。为了构建这一模型,针对每个候选的可疑代码文件(即实例),抽取三方面的特征,包括其对应的缺陷报告的质量特征、其与项目代码之间的文本相似性特征和其对应缺陷报告者的经验特征。对于缺陷报告的质量特征,主要考虑三方面。一个是对缺陷报告中的软件行为(包括观察到的行为和期望的行为),记录其存在与否并用ELMO预训练模型进行语义表示。另一个是重现步骤,同样记录其是否存在并使用ELMO预训练模型对其语义特征进行表示。最后一个是缺陷报告的可读性,使用七个可读性指标特征对其进行刻画,包括Kincaid,Automated Readability Index(ARI),Coleman-Liau,Flesh,Fog,Liw,和SMOG Grade。这些可读性指标通过调用R包quanteda的textstat_readability函数获取。其调用方式为:textstat_readability(miss,measure=c('Flesch.Kincaid','ARI','Coleman.Liau.short','Flesch','FOG','LIW','SMOG.simple'),remove_hyphens=TRUE)。
针对可疑代码文件和缺陷报告之间的文本相似性,主要计算三种文本相似性,包括tf-idf文本相似性、主题相似性(本发明使用LDA主题模型)、和词嵌入语义相似性。三者均需先分别将可疑代码文件和缺陷报告表示成tf-idf向量、LDA主题向量、词嵌入向量。随后,针对这些向量,计算cosine值来度量其相似性,两个向量R1和R2的cosine值的计算方式如下:
其中,w
其中,tft
考虑到不同的用户在表达相似或相关的概念时,可能使用不同的自然语言文本,这将导致基于文本相似性的定位技术定位不准。为了帮助解决这一问题,本发明提出引入wordnet,使用同义词扩充缺陷报告和代码文件文本的方案。具体地,本发明对缺陷报告的title部分和代码文件的函数名部分进行分词、切词、去停用词、去词干后的实体词,使用wordnet将这些词的同义词加入到原来的文本集中。对扩充后的文本集(即缺陷报告和代码文件),额外计算tf-idf、LDA主题、词嵌入语义向量的相似性,其计算方法与上述不扩充的文本相似性计算方法相同。如此,将最终计算得到的六个文本相似性指标(原始的三个相似性指标和wordnet扩充后的三个相似性指标)作为预测模型的文本相似性特征。
对于报告者经验部分,主要从三个维度来刻画一个缺陷报告者的经验,一个是该报告者在本项目的历史代码贡献,包括代码提交(commits)数、代码行数、所提pullrequest数、被接收的pull request数、最近3/6/9/12个月的活跃度(有代码提交的天数、平均提交数/代码行数)、参与的模块数。另一个是修复缺陷的经验,包括修复缺陷的数目、缺陷的平均复杂度(所需修改的代码量和涉及的文件、模块数)/优先级/严重程度、所修复缺陷的重开启数。第三个维度是报告缺陷的经验,包括以往提交的缺陷报告的数目、所提缺陷报告中有效的缺陷数目、其所提缺陷报告关闭的平均周期。
对于初始可疑列表中的每个代码文件,在获取其对应的缺陷报告质量特征、文本相似性特征和报告者经验特征后,使用深度学习框架卷积神经网络CNN(其能从原始的低层次语义特征中较好的抽取高层次语义)对其是否与给定缺陷报告相关进行模型的训练和预测,实例的标签为二元标签,即相关和不相干。在训练的过程中,考虑到与缺陷报告相关的可疑代码文件的数目通常远远小于正常代码文件的数目,这种类不平衡问题将使得模型倾向于大类(即正常代码文件类)。为了解决这一问题,本发明提出使用随机过采样的方法(random over-sampling)进行处理。其实现可通过调用Keras库的SMOTE函数实现。在训练CNN的过程中,历史代码文件集(因为一个训练集同时需要正、反两类实例,因此历史代码文件集中包括真实的可疑代码文件(truly buggy files)以及正常的代码文件(即真实无缺陷代码文件truly non-buggy files)将按照训练集:验证集:测试集=8:1:1的比例进行切分。输入层为每个代码文件的三维特征,隐藏层为5个全连接层,每层的节点数为512、256、128、64、32,输出层使用逻辑回归函数。训练得到CNN模型后,针对初始可疑代码文件列表中的代码文件,模型将输出其认为的真实可疑的代码文件,从而从初始可疑代码文件列表中抽取真实可疑代码文件子集。
可疑代码文件优化
在得到步骤二所预测的真实可疑代码文件的子集后,为了获得较完备的可疑代码文件列表。针对现有技术孤立考虑单个代码文件而忽略了代码间依赖关系导致定位不准的问题,本发明提出通过利用代码间的依赖关系来优化可疑文件推荐列表,优化后的推荐列表将包含更多的真实可疑代码文件,从而能有效定位涉及多可疑代码文件的软件缺陷。在优化的过程中,主要使用了三种代码依赖,即控制流依赖、数据流依赖和共现依赖。使用程序分析技术,对可疑代码文件列表分别进行上述三种依赖分析后将得到三个推荐列表序列,对这三个序列进行线性加权组合,将组合后得到的可疑代码文件列表追加在真实可疑代码文件子集后面,得到最终的可疑代码文件推荐列表。该列表将作为最终的推荐列表输出给开发人员。
具体来说,在拿到CNN输出的真实可疑代码文件子集后,该部分则主要根据这些子集抽取出剩余的尚未被准确识别的可疑代码文件。本发明主要利用代码文件之间的控制流依赖、数据流依赖和共现依赖来抽取与给定真实可疑代码文件子集相关的其他真实可疑代码文件。通常来说,一个缺陷往往会通过上述三种依赖流转到项目代码的其他地方。相较于其他代码文件,与给定真实可疑代码文件在控制流、数据流和共现上有依赖关系的代码文件往往更可能是真实可疑的(即buggy)。在分析控制流和数据流依赖的过程中,将借助Understand等工具对源码进行分析。而对于共现依赖,主要通过分析代码仓库的历史提交记录来实现。如果两个文件涉及到相同的开发者,或者在进行代码提交时被同时修改后提交,则认为这两个文件存在共现依赖。
通过对真实可疑代码文件子集进行上述三种代码依赖分析后,将得到三个可疑代码文件候选列表,对这三个候选列表,本发明将使用线性组合的方式对这三个列表进行整合。线性整合公示如下:
S=∑w
其中,S表示的是组合后一个代码文件的可疑度,值越大可疑度越高,越排在列表的前面。w表示的是三个列表的排名权重,其中w
以上所述,仅为本发明中的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉该技术的人在本发明所揭露的技术范围内,可理解想到的变换或替换,都应涵盖在本发明的包含范围之内,因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 一种面向多可疑代码文件的缺陷定位方法
- 一种面向缺陷定位的代码搜索方法