基于拼音约束联合学习的汉语语音识别方法
文献发布时间:2023-06-19 09:51:02
技术领域
本发明涉及基于拼音约束联合学习的汉语语音识别方法,属于自然语言处理技术领域
背景技术
在自动语音识别领域,当前的语音识别模型在英语、法语等表音文字中已经取得很好的效果。然而,汉语是一种典型的表意文字,汉字与语音没有直接的对应关系,但拼音作为汉字读音的标注符号,与汉字存在相互转换的内在联系。将语音特征识别为音节(拼音)单元、再通过一个转换模型将拼音变换为汉字的级联方法存在错误传播,为了避免这种问题,汉字-拼音识别模型在训练时使用拼音帮助对汉字的识别,但是这种方法识别效果不佳,对此,基于音节(包含1400个拼音)的贪婪级联解码器模型,取得相对较好的效果。在汉语语音识别中,引入拼音作为对汉字解码的约束,能够促使模型学习更好的语音特征。因此,提出基于拼音约束联合学习的汉语语音识别方法,在汉语语音识别中引入拼音语音识别任务作为辅助任务联合训练,共同学习,相互促进。
发明内容
本发明提供了基于拼音约束联合学习的汉语语音识别方法,以用于在汉语语音识别总引入拼音作为对汉字解码的约束,能够促使模型学习更好的语音特征,缓解了当前系统对汉字识别难以收敛的问题。
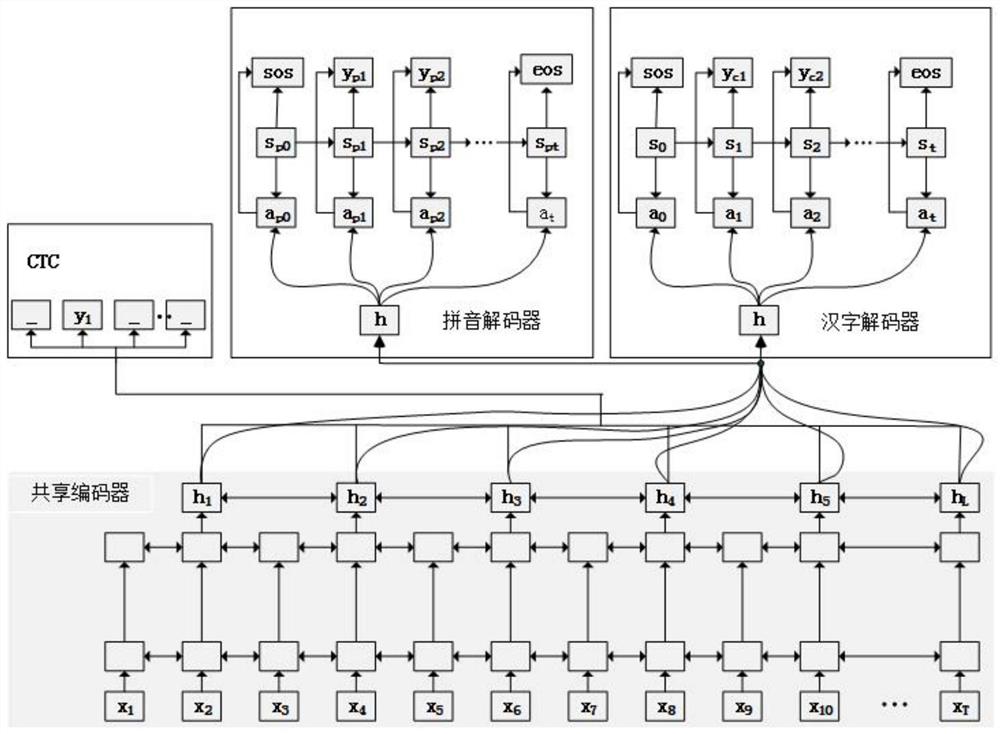
本发明的技术方案是:基于拼音约束联合学习的汉语语音识别方法,首先从公开中文语料集data_aishell中收集与语音、文本对应的拼音文本,其次通过共享编码器对语音特征编码,再以拼音语音识别为辅助任务,然后,在解码过程中利用拼音作为解码约束,基于共享编码器将拼音语音识别语汉语语音识别联合学习,引入一种更接近语音的归纳偏置,增强编码器对汉语语音的表达能力。所述基于拼音约束联合学习的汉语语音识别方法具体步骤如下:
Step1、收集与语音、汉字文本相对应的拼音文本;在公开训练语料data_aishell上,收集与语音、汉字文本相对应的拼音文本,从而得到语音、汉语文本、拼音文本训练集、测试集和验证集。
Step2、共享编码器;共享编码器采用4层的卷积网络和5层的双向LSTM,双向LSTM每个方向有512个隐状态单元,在模型训练时,能同时感知到拼音、汉字的监督信号、从而引入一种更接近汉语语音的归纳偏置。
Step3、拼音语音识别;在解码过程中,拼音语音识别解码器基于共享编码器的输出状态,以前一时刻的输出和当前时刻的上下文向量作为当前时刻的输入进行解码,输出拼音。
Step4、基于拼音约束联合学习的汉字识别;以拼音语音识别为辅助任务,汉语语音识别为主要任务,拼音语音识别和汉语语音识别分别有一个解码器,训练时,模型的交叉熵是两个解码器分别计算损失后正则求和;反向传播时,编码器的参数被两个任务同时更新,两个任务共同促进的效果。
其中,模型共享一个编码器,编码器采用双向长短期记忆网络(Long Short TermMemory networks,LSTM)。共享编码器将语音信号特征x=(x
x=(x
拼音语音识别模型采用当前流行的基于注意力机制的编码器-解码器框架,编码过程如上所述。其中,解码器采用单向LSTM,以共享编码器的输出h作为输入,基于当前时刻t以前的输出标签序列,得到每一个t时刻预测拼音p标签y
y
对于每一时间步t,基于所有的输入语音特征h和注意力机制权重a
这里的a
e
f
这里,训练参数有ω、W、V、U和F,γ是模型的锐化因子,*表示一维卷积,f
解码器使用c
s
y
这里LSTM代表单向循环神经网络,Generate代表前馈网络。
结合以上公式,拼音语音识别的损失函数可以通过以下公式计算:
L
这里拼音序列y
基于拼音约束联合学习的汉字识别,以拼音语音识别为辅助任务,汉语语音识别为主要任务,拼音语音识别和汉语语音识别分别有一个解码器,基于共享编码器的输出h,汉字解码器同样以h作为输入,结合当前时刻t以前的输出标签序列,通过简单的前馈网络和一个softmax激活函数,得到每一个时刻t预测汉字c标签y
L
这里汉字序列y
在多任务学习框架下,本文模型的交叉熵通过拼音解码器和汉字解码分别计算损失后的正则求和联合训练。拼音语音识别作为辅助任务帮助模型对汉语的识别能力,与此同时,汉语语音识别促进模型对拼音监督信号的感知。反向传播时,通过共享编码器,能同时感知拼音和汉字的监督信号,编码器的参数被拼音语音识别和汉字语音识别同时更新,基于拼音语音识别联合学习的汉字识别交叉熵损失函数表示为
L
这里λ为模型可微调的超参数:λ∈(0,1)。
考虑CTC具有使模型快速收敛的优势,且不需要对输入序列和输出序列做一一标注和对齐。通常情况下,CTC与RNN结合,RNN作为编码器,对语音特征序列x抽取特征,编码器过程如上所述。CTC假设输出汉语标签之间条件独立,标签之间允许插入空白表示(-),求不同时刻可能出现的标签路径π=(π
L(h,y
这里λ
本发明的有益效果是:
1、本发明所述方法通过一个共享编码器,将拼音语音识别与汉语语音识别联合学习,有效的提高对汉字的识别效果,通过对比实验分析,结果表明本发明的方法均优于其他模型。
附图说明
图1为本发明中的总的流程图;
具体实施方式
实施例1:如图1所示,基于拼音约束联合学习的汉语语音识别方法,所述基于拼音约束联合学习的汉语语音识别方法的具体步骤如下:
Step1、收集与语音、汉字文本相对应的拼音文本;在公开训练语料data_aishell上,收集与语音、汉字文本相对应的拼音文本,从而得到语音、汉语文本、拼音文本训练集、测试集和验证集;
Step2、共享编码器;共享编码器采用4层的卷积网络和5层的双向LSTM,双向LSTM每个方向有512个隐状态单元,在模型训练时,能同时感知到拼音、汉字的监督信号、从而引入一种更接近汉语语音的归纳偏置。
Step3、拼音语音识别;在解码过程中,拼音语音识别解码器基于共享编码器的输出状态,以前一时刻的输出和当前时刻的上下文向量作为当前时刻的输入进行解码,输出拼音。
Step4、基于拼音约束联合学习的汉字识别;以拼音语音识别为辅助任务,汉语语音识别为主要任务,拼音语音识别和汉语语音识别分别有一个解码器,训练时,模型的交叉熵是两个解码器分别计算损失后正则求和;反向传播时,编码器的参数被两个任务同时更新,两个任务共同促进的效果。
其中,模型共享一个编码器,编码器采用双向长短期记忆网络(Long Short TermMemory networks,LSTM)。共享编码器将语音信号特征x=(x
x=(x
拼音语音识别模型采用当前流行的基于注意力机制的编码器-解码器框架,编码过程如上所述。其中,解码器采用单向LSTM,以共享编码器的输出h作为输入,基于当前时刻t以前的输出标签序列,得到每一个t时刻预测拼音p标签y
y
对于每一时间步t,基于所有的输入语音特征h和注意力机制权重a
这里的a
e
f
这里,训练参数有ω、W、V、U和F,γ是模型的锐化因子,*表示一维卷积,f
解码器使用c
s
y
这里LSTM代表单向循环神经网络,Generate代表前馈网络。
结合以上公式,拼音语音识别的损失函数可以通过以下公式计算:
L
这里拼音序列y
基于拼音约束联合学习的汉字识别,以拼音语音识别为辅助任务,汉语语音识别为主要任务,拼音语音识别和汉语语音识别分别有一个解码器,基于共享编码器的输出h,汉字解码器同样以h作为输入,结合当前时刻t以前的输出标签序列,通过简单的前馈网络和一个softmax激活函数,得到每一个时刻t预测汉字c标签y
L
这里汉字序列y
在多任务学习框架下,本文模型的交叉熵通过拼音解码器和汉字解码分别计算损失后的正则求和联合训练。拼音语音识别作为辅助任务帮助模型对汉语的识别能力,与此同时,汉语语音识别促进模型对拼音监督信号的感知。反向传播时,通过共享编码器,能同时感知拼音和汉字的监督信号,编码器的参数被拼音语音识别和汉字语音识别同时更新,基于拼音语音识别联合学习的汉字识别交叉熵损失函数表示为L
这里λ为模型可微调的超参数:λ∈(0,1)。
考虑CTC具有使模型快速收敛的优势,且不需要对输入序列和输出序列做一一标注和对齐。通常情况下,CTC与RNN结合,RNN作为编码器,对语音特征序列x抽取特征,编码器过程如上所述。CTC假设输出汉语标签之间条件独立,标签之间允许插入空白表示(-),求不同时刻可能出现的标签路径π=(π
L(h,y
这里λ
其中,在模型参数设置时,设置的参数如下所示:
对于未登录字,使用特殊字符“UNK代替”,超参数λ,λ
本发明使用词错误率作为模型的评价指标,词错误率简称WER(Word ErrorRate),将模型预测的输出序列与监督信号序列进行比较,计算WER的公式:
这里S、D、I表示替换、删除和插入的字数,N为监督信号字序列的总字数,词错误率越低,说明方法越有有效。
为了验证本发明的有效性,实验中,将混合S2S+CTC语音识别系统、中文语音识别级联系统以及本发明进行比较。如表1所示。
表1本文模型对比基线模型的实验结果
从表1中可以看出:本文模型对比基线模型S2S+CTC在验证集上的WER值减少2.5个百分点,在测试集上的WER值减少2.24个百分点,说明了在当前的汉语语音识别中引入拼音语音识别作为辅助任务联合训练,增强了模型对汉字的表达能力,提高了模型的识别效果;对比级联系统,本文模型的识别效果在验证集上提高1.31个百分点,在测试集上提高1.05个百分点,说明了在对汉字的识别中引入拼音语音识别任务,本文的方法避免了级联系统导致的错误传播问题,很好地利用了拼音语音识别任务的优势,取得比级联系统更好的识别效果。
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 基于拼音约束联合学习的汉语语音识别方法
- 基于全局和局部联合约束迁移学习的室内定位方法