共享计算资源的抢占方法、装置、用户设备及存储介质
文献发布时间:2023-06-19 09:51:02
技术领域
本发明涉及图形处理器技术领域,尤其涉及一种GPU多核处理器共享计算资源的抢占方法、装置及用户设备及存储介质。
背景技术
GPU采用流式并行计算模式,为了增加数据的并行处理效率,提升对底层计算资源(SIMD/DIMD)的充分利用,都会通过一个多核/多线程处理器来建立数据流处理计算通道,对计算任务的命令解析,配置相关信息,让计算资源(SIMD/DIMD)对数据进行计算处理。
每个核/线程都对应一个线程池(如图2的虚线),线程池中有多个线程(线程和所执行计算任务的优先级一一对应),每个核/线程都会从自己管理的线程池中选择一个线程来执行,调度方式主要是优先级与时间片,这样每个线程池中的线程都能实现重要计算任务优先分发,同等优先级的按时间片切换,确保重要任务执行后,普通任务再正常执行,以达到计算效率的最大化。
在实现本发明的过程中,发明人发现现有技术中至少存在如下技术问题:
现有技术中没有考虑多核/线程之间的线程调度。每个核/线程都执行各自线程池中最高优先级的计算任务,就存在当前线程池的高优先级任务将计算资源(SIMD/DIMD)耗尽,导致其他核/线程池中比当前线程高的优先级任务由于获取不到计算资源而无法执行的情况。
发明内容
本发明提供GPU多核处理器共享计算资源的抢占方法、装置及用户设备及存储介质,能够确保所有线程池中高优先级任务能够得到及时执行。
一方面,提供一种GPU多核处理器共享计算资源的抢占方法,包括:
步骤1,管理调度线程从至少一个业务核或线程接收业务核或线程对应的线程池中的线程的优先级;
步骤2,所述管理调度线程判断是否所有的所述线程的优先级都一样;如果为是,则退出抢占处理流程,否则执行步骤3;
步骤3,所述管理调度线程获取当前执行的所有线程对应的优先级中的最低优先级;
步骤4,所述管理调度线程判断是否有比所述最低优先级高的所述线程没有获取到计算资源而执行;如果没有,则退出抢占处理流程;如果有,则进入步骤5;
步骤5,按优先级从低到高的顺序,所述管理调度线程选取正在执行的所述最低优先级对应的至少一个业务核或线程的任务,对选取的所述任务发起中止操作,保存中止的所述任务的现场,并释放对应的计算资源,以使得比所述最低优先级高的任务被执行。
可选的,所述方法还包括:
步骤6,跳转到所述步骤1。
可选的,所述方法步骤6之前,所述方法还包括:
所述管理调度线程提高被中止的所述线程的优先级。
可选的,所述步骤2之前,所述方法还包括:
所述管理调度线程根据所述优先级,对所述线程进行排序。
可选的,所述的步骤1之前,所述方法还包括:
GPU多核处理器创建管理调度线程。
另一方面,提供一种GPU多核处理器共享计算资源的抢占装置,包括:
接收单元,用于从至少一个业务核或线程接收业务核或线程对应的线程池中的线程的优先级;
第一判断单元,用于断是否所有的所述线程的优先级都一样;如果为是,则退出抢占处理流程,否则启动获取单元;
获取单元,用于获取当前执行的所有线程对应的优先级中的最低优先级;
第二判断单元,用于判断是否有比所述最低优先级高的所述线程没有获取到计算资源而执行;如果没有,则退出抢占处理流程;如果有,则启动选择单元;
选择单元,用于按优先级从低到高的顺序,所述管理调度线程选取正在执行的所述最低优先级对应的至少一个业务核或线程的任务,对选取的所述任务发起中止操作,保存中止的所述任务的现场,并释放对应的计算资源,以使得比所述最低优先级高的任务被执行。
所述的装置,还包括:
提高单元,用于提高被中止的所述线程的优先级。
另一方面,提供一种用户设备,所述用户设备包括所述的GPU多核处理器共享计算资源的抢占装置。
另一方面,提供一种GPU多核处理器共享计算资源的抢占装置,包括:
存储器;
以及耦接至所述存储器的处理器,所述处理器被配置为基于存储在所述存储器中的指令,执行所述的GPU多核处理器共享计算资源的抢占方法。
另一方面,提供一种计算机可读存储介质,其中,所述计算机可读存储介质存储有计算机指令,所述计算机指令被处理器执行时实现所述的GPU多核处理器共享计算资源的抢占方法。
本发明实施例中,在GPU流处理器的多核/多线程之间增加了抢占流程,确保所有线程池中高优先级任务能够得到及时执行。
附图说明
图1为本发明一实施例所述的GPU多核处理器共享计算资源的抢占方法的流程图;
图2为本发明另一实施例所述的GPU多核处理器共享计算资源的抢占方法所用的系统框架示意图;
图3为本发明另一实施例所述的GPU多核处理器共享计算资源的抢占方法的流程图;
图4为本发明一实施例所述的GPU多核处理器共享计算资源的抢占装置的结构示意图;
图5为本发明另一实施例所述的GPU多核处理器共享计算资源的抢占装置的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
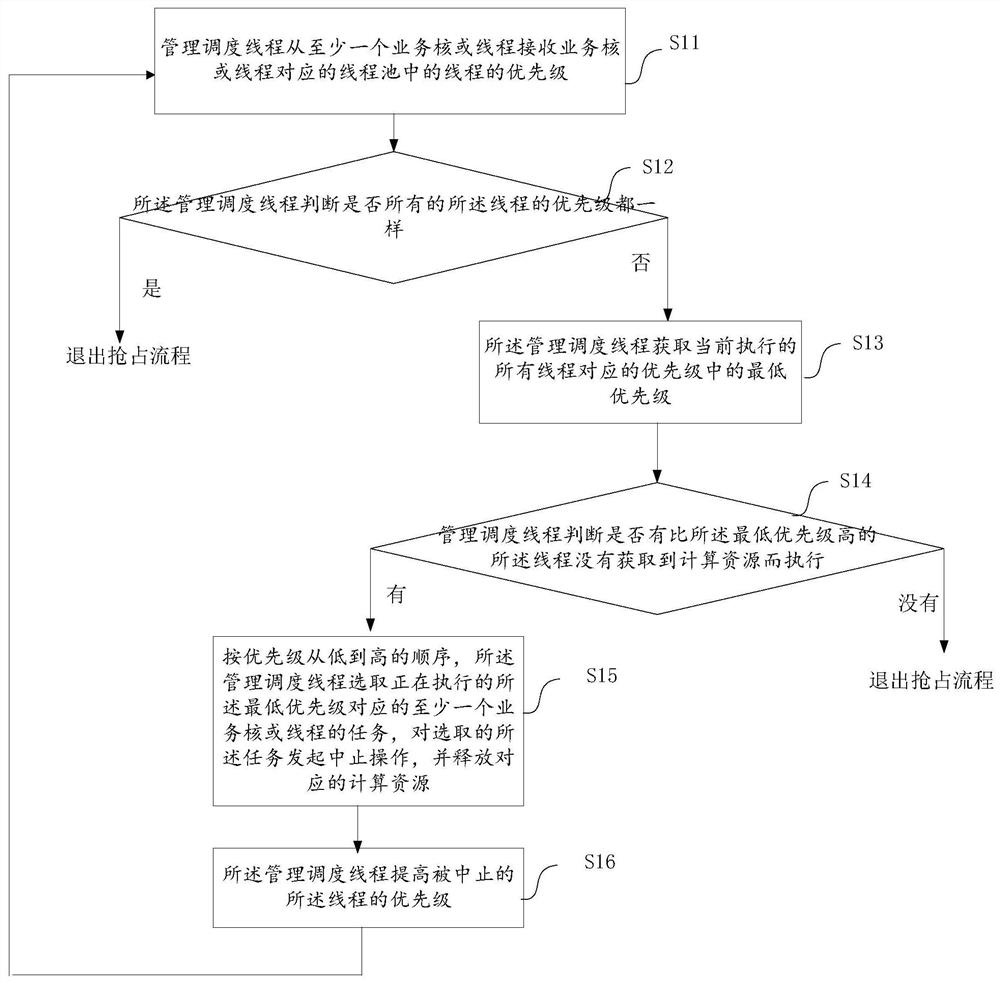
如图1所示,为本发明所述的一种GPU多核处理器共享计算资源的抢占方法,包括:
步骤11,管理调度线程从至少一个业务核或线程接收业务核或线程对应的线程池中的线程的优先级;该步骤之前,所述方法还包括:GPU多核处理器创建管理调度线程。业务核/线程在按“时间片+优先级”执行线程池中计算任务时,将当前执行任务的优先级告知管理核/线程,使得调度管理的核/线程可以统计所有核/线程执行任务的优先级。
步骤12,所述管理调度线程判断是否所有的所述线程的优先级都一样;如果为是,则退出抢占处理流程,否则执行步骤3;可选的,所述步骤12之前,所述方法还包括:所述管理调度线程根据所述优先级,对所述线程进行排序。
步骤13,所述管理调度线程获取当前执行的所有线程对应的优先级中的最低优先级;
步骤14,所述管理调度线程判断是否有比所述最低优先级高的所述线程没有获取到计算资源而执行;如果没有,则退出抢占处理流程;如果有,则进入步骤15;
步骤15,按优先级从低到高的顺序,所述管理调度线程选取正在执行的所述最低优先级对应的至少一个业务核或线程的任务,对选取的所述任务发起中止操作,并释放对应的计算资源,以使得比所述最低优先级高的任务被执行。同时,保存中止的所述任务的现场,使得下次根据保存的现场重新发起执行。
步骤16,所述管理调度线程提高被中止的所述线程的优先级。提高优先级可以提高一级或者几级,根据实际情况设定。确保高优先级任务被及时执行,低优先级任务又不会被“饿死”。
可选的,所述方法还包括:跳转到所述步骤11,继续进行处理。由于多核/多线程是并行执行的,所以可能出现高优先级仍然获取不到计算资源的情况,所以需要回到步骤11进行重新检查。
本发明具有以下有益效果:
1、本发明主要是针对在GPU多核/多线程的流处理器中,增加多核/多线程之间按优先级顺序实现抢占功能,确保所有线程池中高优先级的任务能够及时得到计算资源(SIMD/DIMD)而被及时执行。
2)对低优先级的线程采取了“中止+提升优先级”策略,保证了低优先级不会出现被“饿死”的情况。
也就是说,本发明避免了当计算资源(SIDM/DIMD)被低优先级任务耗尽,核/线程分发的高优先级计算任务无法执行的情况,同时杜绝了因抢占所导致低优先级计算任务被“饿死“的情况。支持优先级的GPU多核处理器中,所有核/线程执行的最高优先级任务能够优先交给计算资源(SIMD/MIMD)进行计算处理。不仅能实现线程池内部按优先级与时间片进行线程调度,线程池之间也能按照优先级进行线程调度,确保高优先级的线程的计算任务执行的同时,最大化GPU的计算效率。
本发明公开了一种实现GPU多核处理器共享计算资源(SIMD/MIMD)的抢占方法,针对图2虚线范围内的多核/多线程之间进行调度。本发明的主要设计理念为:通过对所有核/线程优先级进行统计,按照优先级从高到底进行排序,然后检查优先级最高核/线程的计算任务是否正在执行;如果没有执行,那么将正在执行的最低优先级核/线程的计算任务停止执行,保存现场,进入ready状态;然后最高优先级核/线程的计算任务就会得到执行,并将被替换的低优先级核/线程的优先级提升一级,确保高优先级任务被及时执行,低优先级任务又不会被“饿死”;如果最高优先级核/线程的任务已经在执行,则根据排序结果继续检查次高优先级,进行上述相同的操作,直到所有高优先级核/线程的计算任务都被执行,或者所有核/线程优先级相同,则退出抢占流程。在GPU多核/多线程处理器的多核/多线程之间增加优先级调度机制,通过对多核/多线程所执行任务的优先级进行调度,确保所有并行执行核/线程中高优先级任务能够优先得到计算资源(SIMD/MIMD)执行。
在本发明设计中,多核/多线程分别针对各自线程池的任务采取“优先级+时间片”的策略不变,针对多核/多线程之间增加了按优先级抢占的策略,对当前所有正在执行线程的高优先级的计算任务的运行情况进行跟踪,确保高优先级任务能够得到及时执行。
以下描述本发明另一实施例。如图3所示,所述方法包括的步骤如下:
步骤1,创建一个调度管理的核/线程,用于接受线程池中所有的业务线程发送过来的优先级信息,以根据接受到的信息,按照优先级的方式进行线程的管理调度。业务核/线程在按“时间片+优先级”执行线程池中计算任务时,将当前执行任务的优先级告知管理核/线程。调度管理的核/线程统计所有核/线程执行任务的优先级。
步骤2,管理调度线程对上报的线程优先级信息按照优先级从高到低进行排序,然后检查排好序的优先级信息。如果所有的业务线程优先级都一样,那么说明不需要进行线程的抢占,退出抢占的流程,否则执行步骤3;
步骤3,依次获取高优先级任务;
步骤4,根据从高到底的优先级顺序,依次检查执行次高优先级任务的业务核/线程是否获取到计算资源而执行。如果是,则进入步骤5。如果不是,则进入步骤6。
步骤5,检测是否所有的高优先级任务的核/线程都获取到了计算资源。如果是,则退出抢占流程;如果不是,则进入步骤4,选择次一高优先级线程重复上述过程;
步骤6,按优先级从低到高的顺序,选取低优先级且正在执行的核/线程,发起停止操作,保存低优先级线程对应计算任务的现场,释放对应的计算资源。
步骤7,提高被中止线程的优先级,防止由于抢占任务导致低优先级线程永远无法执行,出现“饿死“的情况。停止低优先级的核/线程的任务之后,再从步骤3执行。由于多核/多线程是并行执行的,所以可能出现高优先级仍然获取不到计算资源的情况,所以需要回到步骤3进行重新检查。
如图4所示,为本发明实施例所述的一种GPU多核处理器共享计算资源的抢占装置,包括:
接收单元,用于从至少一个业务核或线程接收业务核或线程对应的线程池中的线程的优先级;
第一判断单元,用于断是否所有的所述线程的优先级都一样;如果为是,则退出抢占处理流程,否则启动获取单元;
获取单元,用于获取当前执行的所有线程对应的优先级中的最低优先级;
第二判断单元,用于判断是否有比所述最低优先级高的所述线程没有获取到计算资源而执行;如果没有,则退出抢占处理流程;如果有,则启动选择单元;
选择单元,用于按优先级从低到高的顺序,所述管理调度线程选取正在执行的所述最低优先级对应的至少一个业务核或线程的任务,对选取的所述任务发起中止操作,保存中止的所述任务的现场,并释放对应的计算资源,以使得比所述最低优先级高的任务被执行。
本实施例的装置,可以用于执行上述方法实施例的技术方案,其实现原理和技术效果类似,此处不再赘述。
本发明实施例还提供一种用户设备,所述用户设备包括上述GPU多核处理器共享计算资源的抢占装置。
如图5所示,为本发明实施例还提供一种GPU多核处理器共享计算资源的抢占装置,包括:
存储器602;
以及耦接至所述存储器的处理器601,所述处理器被配置为基于存储在所述存储器中的指令,执行所述的GPU多核处理器共享计算资源的抢占方法。
本发明实施例还提供一种计算机可读存储介质,其中,所述计算机可读存储介质存储有计算机指令,所述计算机指令被处理器执行时实现所述的GPU多核处理器共享计算资源的抢占方法。
本领域普通技术人员可以理解实现上述方法实施例中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(Read-Only Memory,ROM)或随机存储记忆体(Random AccessMemory,RAM)等。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
- 共享计算资源的抢占方法、装置、用户设备及存储介质
- 共享服务用户数据处理方法、装置、电子设备及存储介质