一种多音字识别方法、装置、电子设备及存储介质
文献发布时间:2023-06-19 09:51:02
技术领域
本公开涉及信息识别技术领域,尤其涉及一种多音字识别方法、装置、电子设备及存储介质。
背景技术
多音字识别是中文合成系统前端的重要技术,通过区分出文本序列中的多音字,实现基于文本序列对应得到正确的音节序列,所述音节序列为基于文本序列中各个文字的正确读音得到的可拼读序列。
现有技术下,通常使用人工标注的样本,对多音字识别模型进行训练,进而希望借助于训练完成的多音字识别模型,得到本文序列对应的音节序列。
然而,对于人工标注的训练样本来说,一方面其依赖于标注人员的经验,必然会存在标注不准确的情况,另一方面,人工标注所能够产生的样本数目有限,无法满足模型训练所需要的样本数量,使得人工标注的训练样本难以全方位的覆盖多音字识别模型需要学习的数据,这样,在耗费大量的人力成本和时间成本的同时,难以使多音字识别模型达到预期的学习效果,后续使用模型进行多音字识别的准确率很低。
有鉴于此,需要一种新的多音字识别方法,以克服上述缺陷。
发明内容
本公开实施例提供一种多音字识别方法、装置、电子设备及存储介质,用以解决现有技术中存在利用基于人工标注的样本完成训练的多音字识别模型,进行多音字识别时,准确率低的问题。
本公开实施例提供的具体技术方案如下:
第一方面,提出一种多音字识别模型的训练方法,包括:
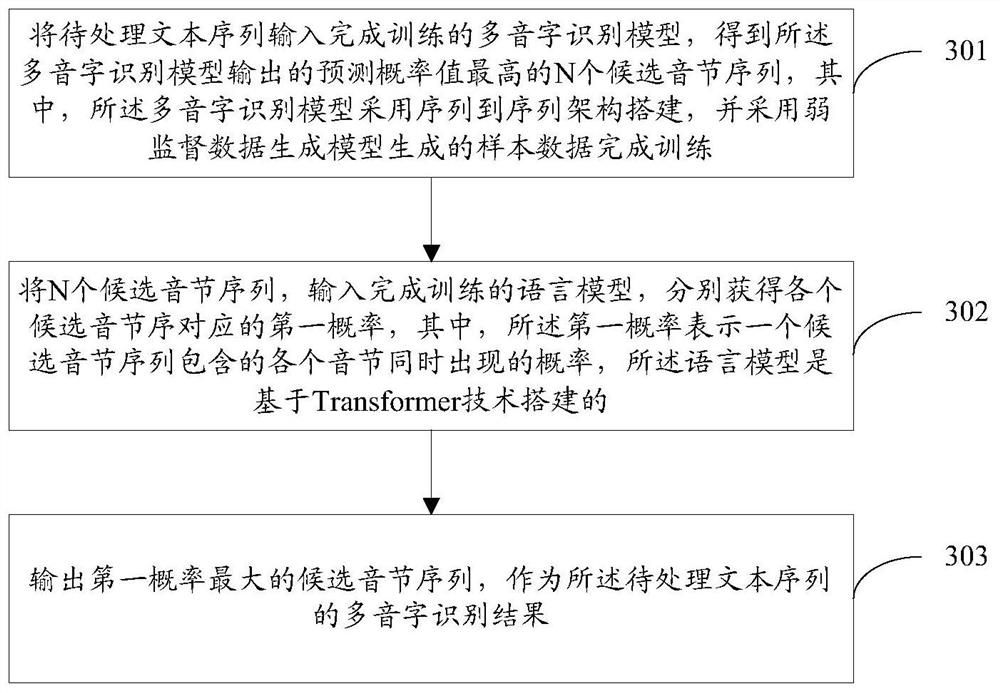
将待处理文本序列输入完成训练的多音字识别模型,得到所述多音字识别模型输出的预测概率值最高的N个候选音节序列,其中,所述多音字识别模型采用序列到序列架构搭建,并采用弱监督数据生成模型生成的样本数据完成训练;
将所述N个候选音节序列,输入完成训练的语言模型,分别获得各个候选音节序对应的第一概率,其中,所述第一概率表示一个候选音节序列包含的各个音节同时出现的概率,所述语言模型是基于转换器Transformer技术搭建的;
输出第一概率最大的候选音节序列,作为所述待处理文本序列的多音字识别结果。
可选的,所述将待处理文本序列输入完成训练的多音字识别模型之前,进一步包括,对多音字识别模型进行训练,包括:
获取各个语音数据以及对应的各个文本序列,采用预先训练的弱监督数据生成模型对所述各个语音数据进行语音识别处理,得到与所述各个文本序列各自对应的音节序列,生成相应的样本数据集合,其中,一个样本数据包括一个样本文本序列和对应的一个样本音节序列;
采用序列到序列架构,搭建多音字识别模型;
采用获得的各个样本数据,对所述多音字识别模型进行训练,直至满足预设的收敛条件,其中,在训练过程中,每读取一条样本数据,采用所述多音字识别模型对所述一条样本数中包括的样本文本序列进行处理,输出预测概率值最高的候选音节序列,并确定所述候选音节序列与样本音节序列之间的音节差异,采用交叉熵损失函数计算损失值,并基于所述损失值调整所述多音字识别模型中生成所述候选音节序列的参数值。
可选的,采用预先训练的弱监督数据生成模型对所述各个语音数据进行语音识别处理之前,进一步包括,对所述弱监督数据生成模型进行训练,包括:
获取训练样本集合,其中,一个训练样本包括一个样本语音数据,以及与所述一个样本语音数据对应的样本文本序列和样本音节序列;
采用预设的弱监督数据生成模型,对所述一个训练样本中包括的一个样本语音数据进行语音识别,输出与所述一个训练样本中包括的一个样本文本序列对齐的预测音节序列,其中,所述弱监督数据生成模型是基于带输入投影层的最小门控循环单元结构搭建的;
采用预设的损失函数,基于所述预测音节序列与所述样本音节序列的音节差异,计算模型损失值,并基于所述损失值调整所述弱监督数据生成模型中生成所述预测音节序列的模型参数;
确定所述模型损失值连续小于设定门限值的次数达到设定阈值,确定所述弱监督数据生成模型收敛,输出完成训练的所述弱监督数据生成模型。
可选的,确定满足以下任一种情况时,确定满足预设的收敛条件,包括:
计算所述多音字识别模型输出的目标音节序列的准确度,确定所述准确度连续达到准确度设定值的次数达到准确度阈值;或者,
确定所述损失值连续小于指定门限值的次数达到指定阈值。
可选的,采用所述弱监督数据生成模型输出的样本音节序列作为所述语言模型的训练样本。
第二方面,提出一种多音字识别装置,包括:
处理单元,将待处理文本序列输入完成训练的多音字识别模型,得到所述多音字识别模型输出的预测概率值最高的N个候选音节序列,其中,所述多音字识别模型采用序列到序列架构搭建,并采用弱监督数据生成模型生成的样本数据完成训练;
输入单元,将所述N个候选音节序列,输入完成训练的语言模型,分别获得各个候选音节序对应的第一概率,其中,所述第一概率表示一个候选音节序列包含的各个音节同时出现的概率,所述语言模型是基于转换器Transformer技术搭建的;
输出单元,输出第一概率最大的候选音节序列,作为所述待处理文本序列的多音字识别结果。
可选的,所述将待处理文本序列输入完成训练的多音字识别模型之前,所述处理单元进一步用于,对多音字识别模型进行训练,所述处理单元用于:
获取各个语音数据以及对应的各个文本序列,采用预先训练的弱监督数据生成模型对所述各个语音数据进行语音识别处理,得到与所述各个文本序列各自对应的音节序列,生成相应的样本数据集合,其中,一个样本数据包括一个样本文本序列和对应的一个样本音节序列;
采用序列到序列架构,搭建多音字识别模型;
采用获得的各个样本数据,对所述多音字识别模型进行训练,直至满足预设的收敛条件,其中,在训练过程中,每读取一条样本数据,采用所述多音字识别模型对所述一条样本数中包括的样本文本序列进行处理,输出预测概率值最高的目标音节序列,并确定所述目标音节序列与样本音节序列之间的音节差异,采用交叉熵损失函数计算损失值,并基于所述损失值调整所述多音字识别模型中生成所述目标音节序列的参数值。
可选的,采用预先训练的弱监督数据生成模型对所述各个语音数据进行语音识别处理之前,所述处理单元进一步用于,对所述弱监督数据生成模型进行训练,所述处理单元用于:
获取训练样本集合,其中,一个训练样本包括一个样本语音数据,以及与所述一个样本语音数据对应的样本文本序列和样本音节序列;
采用预设的弱监督数据生成模型,对所述一个训练样本中包括的一个样本语音数据进行语音识别,输出与所述一个训练样本中包括的一个样本文本序列对齐的预测音节序列,其中,所述弱监督数据生成模型是基于带输入投影层的最小门控循环单元结构搭建的;
采用预设的损失函数,基于所述预测音节序列与所述样本音节序列的音节差异,计算模型损失值,并基于所述损失值调整所述弱监督数据生成模型中生成所述预测音节序列的模型参数;
确定所述模型损失值连续小于设定门限值的次数达到设定阈值,确定所述弱监督数据生成模型收敛,输出完成训练的所述弱监督数据生成模型。
可选的,确定满足以下任一种情况时,确定满足预设的收敛条件,所述处理单元用于:
计算所述多音字识别模型输出的目标音节序列的准确度,确定所述准确度连续达到准确度设定值的次数达到准确度阈值;或者,
确定所述损失值连续小于指定门限值的次数达到指定阈值。
可选的,采用所述弱监督数据生成模型输出的样本音节序列作为所述语言模型的训练样本。
第三方面,提出一种电子设备,包括:
存储器,用于存储可执行指令;
处理器,用于读取并执行存储器中存储的可执行指令,以实现上述任一项所述的多音字识别方法。
第四方面,一种存储介质,当所述存储介质中的指令由电子设备执行时,使得所述电子设备能够执行上述任一项所述的多音字识别方法。
本公开有益效果如下:
本公开实施例中,公开了一种多音字识别方法、装置、电子设备及存储介质,将待处理文本序列输入完成训练的多音字识别模型,得到所述多音字识别模型输出的预测概率值最高的N个候选音节序列,其中,所述多音字识别模型采用序列到序列架构搭建,并采用弱监督数据生成模型生成的样本数据完成训练,再将所述N个候选音节序列,输入完成训练的语言模型,分别获得各个候选音节序对应的第一概率,其中,所述第一概率表示一个候选音节序列包含的各个音节同时出现的概率,所述语言模型是基于转换器Transformer技术搭建的,然后输出第一概率最大的候选音节序列,作为所述待处理文本序列的多音字识别结果。这样,基于进行生成的弱监督样本数据生成模型生成的样本数据对多音字识别模型进行训练,能够实现样本数据的快速生成,而且提高了样本的数量和覆盖面,并考虑到弱监督样本数据可能引入的噪声,采用语言模型对多音字识别模型输出的预测结果进行重新评估,进而完成输出,保证训练后得到的多音字识别模型的可靠性,提高了对于多音字识别的准确率,保证了对于多音字的识别效果。
附图说明
图1a为本公开实施例中处理待处理文本序列的示意图;
图1b为本公开实施例中训练多音字识别模型的示意图;
图2为本公开实施例中对多音字识别模型进行训练的流程示意图;
图3为本公开实施例中对待处理文本序列进行多音字识别处理的流程示意图;
图4为本公开实施例中多音字识别装置的逻辑结构示意图;
图5为本公开实施例中多音字识别装置的实体结构示意图。
具体实施方式
为了解决现有技术中存在的利用基于人工标注的样本完成训练的多音字识别模型,进行多音字识别时,准确率低的问题,本公开提出将待处理文本序列输入完成训练的多音字识别模型,得到所述多音字识别模型输出的预测概率值最高的N个候选音节序列,其中,所述多音字识别模型采用序列到序列架构搭建,并采用弱监督数据生成模型生成的样本数据完成训练,再将所述N个候选音节序列,输入完成训练的语言模型,分别获得各个候选音节序对应的第一概率,其中,所述第一概率表示一个候选音节序列包含的各个音节同时出现的概率,所述语言模型是基于转换器Transformer技术搭建的,然后输出第一概率最大的候选音节序列,作为所述待处理文本序列的多音字识别结果。
需要说明的是,本公开实施例中,对待处理文本序列进行识别多音字识别的主体可以是服务器,或者,具有高性能处理能力的电子设备,本公开对此不作限定,在此不再赘述。
本公开实施例中,为解决利用基于人工标注的样本完成训练的多音字识别模型,进行多音字识别时,准确率低的问题,本公开提出采用弱监督数据生成样本数据,极大的扩大了样本数据的内容覆盖面,并采用得到的样本数据对多音字识别模型进行训练,使用完成训练完成的多音字识别模型,对待处理文本序列进行多音字识别处理,并考虑到多音字识别模型识别的准确性,将多音字识别模型输出的N个结果输入完成训练的语言模型,得到语言模型输出的对应N个结果的N个第一概率,进而将概率值最高的序列作为最终的多音字识别结果。
下面结合附图,对本公开优选的实施例进行进一步详细说明:
参阅图1a-1b所示,对本公开实施例中的多音字识别的架构进行说明:
多音字识别过程中,参阅图1a所示意的,将待处理文本序列输入预先完成训练的多音字识别模型中,得到多音字识别模型输出的预测概率值最高的N个候选音节序列,为保证识别结果的准确性,将得到的N个候选音节序列输入预先完成训练的语言模型,使得语言模型分别计算各个候选音节序列中,各个音节同时出现的概率值,进而所述N个候选音节序列中,概率值最大的候选音节序列作为所述待处理文本的识别结果。
多音字识别模型的训练过程中,参阅图1b所示意的,使用预先完成训练的弱监督数据生成模型,对样本文本序列对应的语音数据进行识别,得到所述弱监督数据生成模型输出的对应样本文本序列的样本音节序列,再将样本文本序列及其对应的样本音节序列作为样本数据,对多音字识别模型进行训练,进而得到训练完成的多音字识别模型。
下面参阅图2所示,本公开实施例中,基于弱监督数据生成模型生成的样本数据对多音字识别模型进行训练的流程如下:
步骤201:获取各个语音数据以及对应的各个文本序列,采用预先训练的弱监督数据生成模型对所述各个语音数据进行语音识别处理,得到与所述各个文本序列各自对应的音节序列,生成相应的样本数据集合,其中,一个样本数据包括一个样本文本序列和对应的一个样本音节序列。
具体的,获取语音数据后,采用预先训练的弱监督数据生成模型,对获取的文本序列对应的语音数据进行语音识别处理,其中,所述弱监督数据生成模型是基于带输入投影层的最小门控循环单元结构(minimal Gated Recurrent Unit with Input Projectionlayer,mGRUIP)搭建的,能够实现语音识别。
下面对本公开实施例中,对所述弱监督数据生成模型的训练过程进行说明:
S1:获取训练样本集合,其中,一个训练样本包括一个样本语音数据,以及与所述一个样本语音数据对应的样本文本序列和样本音节序列。
具体的,获取样本语音数据,以及与所述样本语音数据对应的样本文本序列和样本音节序列,并将得到的一个语音数据,以及与所述一个语音数据对应的一个样本文本序列和一个样本音节序列作为一个训练样本。
进一步的,基于得到的各个训练样本生成训练样本集合。
需要说明的是,本公开实施例中,在对弱监督数据生成模型进行训练的过程中,在一次的训练过程中,可以同时输入多个训练样本进行训练,一次训练过程中具体输入的训练样本数目可以根据实际的训练需要进行配置,在此不再赘述,在本公开以下的叙述中,将仅以对一个训练样本进行的操作为例进行说明。
S2:采用预设的弱监督数据生成模型,对所述一个训练样本中包括的样本语音数据进行语音识别,输出与所述一个训练样本中包括的一个样本文本序列对齐的预测音节序列。
具体的,将样本语音数据和样本文本序列输入弱监督数据生成模型中后,所述弱监督数据生成模型首先对所述样本语音数据进行分帧以及特征提取操作,得到所述样本语音数据的声学特征序列,具体的,本公开中,从样本语音数据中提取的特征可以为梅尔频率倒谱系数(MelFrequency CepstrumCoefficient,MFCC)特征序列、线性预测倒谱系数(LinearPredictiveCepstralCoefficient,LPCC)特征序列,以及感知线性预测系数(PerceptualLinearPredicive,PLP)特征序列等等。其中,针对语音数据进行特征提取的过程是本领域的公知技术手段,本公开在此不再赘述。
进一步的,在mGRUIP网络架构下,对所述声学特征序列进行处理,得到每帧声学特征序列的似然概率,进而基于各帧声学特征序列的似然概率得到概率矩阵,进而将所述概率矩阵以及所述样本文本序列送入有限状态机的图结构中进行维特比搜索,输出与所述样本文本序列对齐的预测音节序列。
需要说明的是,本公开实施例中涉及到的具体的声学特征提取的过程为将语音数据的采样点转换成诸如MFCC特征序列,涉及到的对其过程,具体为将样本文本序列利用决策树和高斯混合模型-隐马尔科夫模型的混合模型(Gaussian Mixture Model,GMM-HiddenMarkov Model,GMM-HMM)算法,转换成音节序列。
S3:采用预设的损失函数,基于所述预测音节序列与所述样本音节序列的音节差异,计算模型损失值,并基于所述损失值调整所述弱监督数据生成模型中生成所述预测音节序列模型参数。
具体的,确定弱监督数据生成模型得到与样本文本序列对齐的预测音节序列后,采用预设的损失函数,所述损失函数具体为交叉熵损失函数,基于所述预测音节序列与样本音节序列之间的音节差异,计算所述弱监督数据生成模型的模型损失值。
进一步的,基于所述模型损失值,调整所述弱监督数据生成模型中参与生成预测音节序列的模型参数。
S4:确定模型损失值连续小于设定门限值的次数达到设定阈值,确定所述弱监督数据生成模型收敛,输出完成训练的所述弱监督数据生成模型。
记录每次训练后得到的模型损失值,并基于记录的模型损失值,确定所述模型损失值连续小于预设门限值的次数达到设定阈值时,则可判定弱监督数据生成模型训练完成,否则,则判定还需进一步对所述弱监督数据生成模型进行训练。
例如,假设,预设门限值为0.25,设定阈值为5,在连续十次的训练过程中,记录的弱监督数据生成模型的模型损失值依次为0.75、0.72、0.68、0.56、0.47、0.32、0.24、0.23、0.20、0.17,可知,所述模型损失值连续小于预设门限值:0.25的次数为4次,小于设定阈值,则可判断需要继续对所述弱监督数据生成模型进行训练。
进一步的,确定弱监督数据生成模型训练完成后,采用所述弱监督数据生成模型,对获取的文本序列对应的语音数据进行语音识别处理,得到与所述文本序列具有对齐关系预测音节序列,并基于对齐的所述文本序列和所述预测音节序列,生成一个样本数据,进而得到样本数据集合。
需要说明的是,本公开实施例中,基于得到对齐的文本序列和音节序列的方式,包括但不限于搭建弱监督数据生成模型得到音节序列,还可以使用现有技术下已有的语音识别工具,得到具有对齐关系的文本序列以及音节序列,在此不再赘述。
这样,基于弱监督数据生成模型输出的预测文本序列和预测音节序列生成样本数据,避免了借助于人工标注得到样本数据,能够快速得到覆盖面较宽的样本数据,为后续模型训练过程的顺利进行提供基础。
需要说明的是,本公开实施例中,在对多音字识别模型的一次训练过程中,可以同时输入多个文本序列样本,其中,所述文本序列样本的数量可根据实际的训练情况配置,在此不再赘述,以下的说明中,仅以一个样本数据为例,对多音字识别模型的训练过程进行说明。
步骤202:采用获得的各个样本数据,对所述多音字识别模型进行训练,直至满足预设的收敛条件,其中,在训练过程中,每读取一条样本数据,采用所述多音字识别模型对所述一条样本数中包括的样本文本序列进行处理,输出预测概率值最高的候选音节序列,并确定所述候选音节序列与样本音节序列之间的音节差异,采用交叉熵损失函数计算损失值,并基于所述损失值调整所述多音字识别模型中生成所述候选音节序列的参数值。
具体的,获取样本数据集合后,将样本数据中包括的样本文本序列输入到预设的,采用序列到序列架构搭建的多音字识别模型中,对所述样本文本序列进行音节预测。
需要说明的是,本公开实施例中,所述多音字识别模型是基于卷积神经网络(Convolutional Neural Network,CNN)的序列到序列(Sequence-to-Sequence,Seq2Seq)技术搭建的。具体的,所述多音字识别模型对输入的样本文本序列进行处理时,首先采用word2vec字向量转换技术或linguistic语言学特性,将样本文本序列中的文字转换为向量表示的形式,有效考虑得到所述样本序列中各个字之间的语义特性,进而,基于Seq2Seq模型技术,对所述样本文本序列的向量表示进行处理,得到所述样本文本序列在各个可能的音节序列上的概率分布,输出概率值最大的音节序列。
进一步的,得到多音字识别模型输出的目标音节序列之后,采用预设的交叉熵损失函数,基于得到的目标音节序列与样本数中的样本音节序列之间的音节差异,计算损失值。
进而根据所述损失值,调整所述多音字识别模型中用于生成目标音节序列的模型参数,具体的,根据得到的损失值,利用适应性矩估计(adaptive moment estiment,Adam)算法调整所述多音字识别模型的模型参数,其中,在对模型参数进行调整的过程中,模型的学习率先增大后减小,且所述学习率增加的速率是预热学习率步长warmup-step数。
这样,基于弱监督数据生成模型生成的样本数据,即可实现对多音字识别模型的训练,极大简化了获得样本数据的难度,且保证了多音字识别模型学习的样本数据的数据覆盖面,提高了训练得到的所述多音字识别模型的可靠性。
需要说明的是,本公开实施例中,判定所述多音字识别模型满足以下任意一种情况时,可判定所述多音字识别模型收敛:
情况一、基于多音字识别模型输出的目标音节序列的准确度进行判断。
具体的,计算所述多音字识别模型输出的目标音节序列的准确度,确定所述准确度连续达到准确度设定值的次数达到准确度阈值。
例如,假设,多音字识别模型输入的样本文本序列为“我不喜欢抽雪茄,但我喜欢吃番茄”,输出的目标音节序列为:wo(3)bu(4)xi(3)huan(1)chou(1)xue(3)qie(2),dan(4)wo(3)xi(3)huan(1)chi(1)fan(1)qie(2),而样本音节序列具体为wo(3)bu(4)xi(3)huan(1)chou(1)xue(3)jia(1),dan(4)wo(3)xi(3)huan(1)chi(1)fan(1)qie(2),本公开实施例中,可以适应性的为具有多音字的文本设置较高的权值,如,为多音字配置权值为0.7,为不是多音字的字符配置权重为0.3,则多音字“茄”识别成功的概率为1/2,不是多音字的字符识别成功的概率为1,故最终得到的准确度为0.7*(1/2)+0.3*1=0.65。
进一步的,可以根据实际需要设置准确度设定值和准确度阈值,确定达到所述准确度设定值的次数达到所述准确度阈值时,可以确定所述多音字识别模型收敛。
方法二、基于损失值进行判断。
具体的,确定损失值连续小于指定门限值的次数达到指定阈值时,判断多音字识别模型收敛。
例如,假设,指定门限值为0.20,指定阈值为5,在连续十次的训练过程中,记录的弱监督数据生成模型的模型损失值依次为0.87、0.65、0.47、0.32、0.26、0.18、0.14、0.13、0.12、0.10,可知,所述模型损失值连续小于指定门限值:0.20的次数为5次,达到指定阈值,则可判断多音字识别模型训练完成。
下面结合附图3,对本公开实施例中,基于训练完成的多音字识别模型对待处理文本序列进行训练的过程进行说明:
步骤301:将待处理文本序列输入完成训练的多音字识别模型,得到所述多音字识别模型输出的预测概率值最高的N个候选音节序列,其中,所述多音字识别模型采用序列到序列架构搭建,并采用弱监督数据生成模型生成的样本数据完成训练。
具体的,获取待处理文本序列后,将待处理文本序列输入完成训练的多音字识别模型中,得到所述多音字识别模型输出的预测概率值最高的前N个候选音节序列,也就是说,在实际的多音字识别过程中,多音字识别模型将输出预测概率值最高的前N个候选音节序列,而不是固定的一个识别得到的音节序列结果。所述弱监督数据生成模型的训练过程已经在前述的叙述中进行详细说明,在此不再赘述。
这样,考虑到基于弱监督数据生成模型生成的样本数据,进行训练的多音字识别模型中可能会引入干扰因素,故使得多音字识别模型在实际的应用过程中输出多个识别结果,以便后续对识别结果进一步进行处理,起到了对可能引入的干扰因素的纠正效果,提高了对多音字识别的准确性。
步骤302:将N个候选音节序列,输入完成训练的语言模型,分别获得各个候选音节序对应的第一概率,其中,所述第一概率表示一个候选音节序列包含的各个音节同时出现的概率,所述语言模型是基于Transformer技术搭建的。
具体的,得到多音字识别模型输出的N个候选音节序列后,采用预先训练的语言模型,对所述N个候选音节序列进行处理,得到所述N个候选音节序列对应的第一概率值,所述语言模型时基于转换器Transformer-based language model架构搭建的,所述第一概率值表征音节序列中包括的各个音节同时出现的概率值,进而所述语言模型对基于对应的各个第一概率值,对所述N个候选音节序列进行重新排序。其中语言模型的训练方式是本领域的常规技术,本公开在此不再赘述。
这样,通过采用语言模型重新计算的各个候选音节序列的概率值,极大的纠正了由于采用弱监督数据生成模型生成的样本数据进行训练时,可能引入的噪声及干扰,借助于重新计算包含的音节同时出现的概率值,实现对候选音节序列的验证。
步骤303:输出第一概率最大的候选音节序列,作为所述待处理文本序列的多音字识别结果。
具体的,将获得的语言模型处理得到的第一概率最大的候选音节序列,作为待处理文本序列的多音字识别结果进行输出。
例如,假设,待处理文本序列为“我不喜欢抽雪茄,但我喜欢吃番茄”,输出的目标音节序列为:wo(3)bu(4)xi(3)huan(1)chou(1)xue(3)jia(1),dan(4)wo(3)xi(3)huan(1)chi(1)fan(1)qie(2),进而在基于目标音节序列以及待处理文本序列,对所述待处理文本序列进行中文-英文的翻译时,能够准确的将“我不喜欢抽雪茄,但我喜欢吃番茄”翻译为“Idonot like to smoke cigars,but I like to eat tomatoes”。
这样,虽然待处理文本序列中,存在会引起歧义的多音字,但是基于本公开提出的识别架构进行多音字识别处理,能够准确地确定待处理文本序列中字符的读音,能够对所述待处理文本序列的真正含义进行准确把握,保证了后续的其他处理诸如对待处理文本序列进行翻译处理的准确性。
基于同一发明构思,参阅图4所示,本公开实施例中,多音字识别装置400至少包括:处理单元401,输入单元402,输出单元403,其中,
处理单元401,将待处理文本序列输入完成训练的多音字识别模型,得到所述多音字识别模型输出的预测概率值最高的N个候选音节序列,其中,所述多音字识别模型采用序列到序列架构搭建,并采用弱监督数据生成模型生成的样本数据完成训练;
输入单元402,将所述N个候选音节序列,输入完成训练的语言模型,分别获得各个候选音节序对应的第一概率,其中,所述第一概率表示一个候选音节序列包含的各个音节同时出现的概率,所述语言模型是基于转换器Transformer技术搭建的;
输出单元403,输出第一概率最大的候选音节序列,作为所述待处理文本序列的多音字识别结果。
可选的,所述将待处理文本序列输入完成训练的多音字识别模型之前,所述处理单元进一步用于,对多音字识别模型进行训练,所述处理单元401用于:
获取各个语音数据以及对应的各个文本序列,采用预先训练的弱监督数据生成模型对所述各个语音数据进行语音识别处理,得到与所述各个文本序列各自对应的音节序列,生成相应的样本数据集合,其中,一个样本数据包括一个样本文本序列和对应的一个样本音节序列;
采用序列到序列架构,搭建多音字识别模型;
采用获得的各个样本数据,对所述多音字识别模型进行训练,直至满足预设的收敛条件,其中,在训练过程中,每读取一条样本数据,采用所述多音字识别模型对所述一条样本数中包括的样本文本序列进行处理,输出预测概率值最高的目标音节序列,并确定所述目标音节序列与样本音节序列之间的音节差异,采用交叉熵损失函数计算损失值,并基于所述损失值调整所述多音字识别模型中生成所述目标音节序列的参数值。
可选的,采用预先训练的弱监督数据生成模型对所述各个语音数据进行语音识别处理之前,所述处理单元401进一步用于,对所述弱监督数据生成模型进行训练,所述处理单元401用于:
获取训练样本集合,其中,一个训练样本包括一个样本语音数据,以及与所述一个样本语音数据对应的样本文本序列和样本音节序列;
采用预设的弱监督数据生成模型,对所述一个训练样本中包括的一个样本语音数据进行语音识别,输出与所述一个训练样本中包括的一个样本文本序列对齐的预测音节序列,其中,所述弱监督数据生成模型是基于带输入投影层的最小门控循环单元结构搭建的;
采用预设的损失函数,基于所述预测音节序列与所述样本音节序列的音节差异,计算模型损失值,并基于所述损失值调整所述弱监督数据生成模型中生成所述预测音节序列的模型参数;
确定所述模型损失值连续小于设定门限值的次数达到设定阈值,确定所述弱监督数据生成模型收敛,输出完成训练的所述弱监督数据生成模型。
可选的,确定满足以下任一种情况时,确定满足预设的收敛条件,所述处理单元401用于:
计算所述多音字识别模型输出的目标音节序列的准确度,确定所述准确度连续达到准确度设定值的次数达到准确度阈值;或者,
确定所述损失值连续小于指定门限值的次数达到指定阈值。
可选的,采用所述弱监督数据生成模型输出的样本音节序列作为所述语言模型的训练样本。
基于同一发明构思,参阅图5所示,基于生成的样本对多音字识别模型进行训练的装置500可以为服务器或具有处理功能的终端设备。参照图5,装置500包括处理组件522,其进一步包括一个或多个处理器,以及由存储器532所代表的存储器资源,用于存储可由处理组件522的执行的指令,例如应用程序。存储器532中存储的应用程序可以包括一个或一个以上的每一个对应于一组指令的模块。此外,处理组件522被配置为执行指令,以执行上述方法。
装置500还可以包括一个电源组件526被配置为执行装置500的电源管理,一个有线或无线网络接口550被配置为将装置500连接到网络,和一个输入输出(I/O)接口558。装置500可以操作基于存储在存储器532的操作系统,例如Windows ServerTM,Mac OS XTM,UnixTM,LinuxTM,FreeBSDTM或类似系统。
基于同一发明构思,本公开实施例中基于多音字识别方法的实施例中提供一种电子设备,包括:存储器,用于存储可执行指令;处理器,用于读取并执行存储器中存储的可执行指令,以实现上述任一种方法。
基于同一发明构思,本公开实施例中基于多音字识别的实施例中提供一种存储介质,当所述存储介质中的指令由电子设备执行时,使得所述电子设备能够执行上述任一种方法。
综上所述,本公开实施例中,公开了一种多音字识别方法、装置、电子设备及存储介质,将待处理文本序列输入完成训练的多音字识别模型,得到所述多音字识别模型输出的预测概率值最高的N个候选音节序列,其中,所述多音字识别模型采用序列到序列架构搭建,并采用弱监督数据生成模型生成的样本数据完成训练,再将所述N个候选音节序列,输入完成训练的语言模型,分别获得各个候选音节序对应的第一概率,其中,所述第一概率表示一个候选音节序列包含的各个音节同时出现的概率,所述语言模型是基于转换器Transformer技术搭建的,然后输出第一概率最大的候选音节序列,作为所述待处理文本序列的多音字识别结果。这样,基于进行生成的弱监督样本数据生成模型生成的样本数据对多音字识别模型进行训练,能够实现样本数据的快速生成,而且提高了样本的数量和覆盖面,并考虑到弱监督样本数据可能引入的噪声,采用语言模型对多音字识别模型输出的预测结果进行重新评估,进而完成输出,保证训练后得到的多音字识别模型的可靠性,提高了对于多音字识别的准确率,保证了对于多音字的识别效果。
本领域内的技术人员应明白,本公开的实施例可提供为方法、系统、或计算机程序产品。因此,本公开可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本公开可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、CD-ROM、光学存储器等)上实施的计算机程序产品的形式。
本公开是参照根据本公开实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
尽管已描述了本公开的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本公开范围的所有变更和修改。
显然,本领域的技术人员可以对本公开实施例进行各种改动和变型而不脱离本公开实施例的精神和范围。这样,倘若本公开实施例的这些修改和变型属于本公开权利要求及其等同技术的范围之内,则本公开也意图包含这些改动和变型在内。
- 一种多音字识别方法、装置、电子设备及存储介质
- 一种多音字消歧方法、装置、电子设备和存储介质