一种发电厂故障数据诊断项目中的随机森林分类方法
文献发布时间:2023-06-19 09:54:18
技术领域
本发明涉及一种发电厂故障数据诊断项目中的随机森林分类方法。
背景技术
随着电网的发展和社会的进步,电力系统的规模也随之越来越大,结构越来越复杂,这就使得对电网的运行提出了更高的要求,加强对电网故障的诊断处理显得尤为重要。一般当电网发生故障时,监控设备会及时产生报警信息并上传,例如开关跳闸、自动保护装置动作、欠电压、过电流、设备过负荷等这些信息。特别是当一些结构、规模巨大的电力系统出现故障时,一时间系统会产生大量的报警信息,而这些信息中包括大量的由保护或断路器误动、拒动,信道传输干扰错误,保护动作时间偏差等因素造成的不确定性的知识和数据。
目前国内外提出了许多电力系统故障诊断的技术和方法主要有专家系统、人工神经网络、优化算法技术、petri网络、模糊集理论、粗糙集理论等,以上智能技术在应用于故障诊断时各有不同优点,但同时也暴露出许多的问题,例如专家系统的维护难度高,容错性差;人工神经网络缺乏对自身行为的解释能力,同时需要大量训练样本等。目前已有的发电厂故障数据诊断分类方法存在问题,无法同时保证准确率与效率,而在现实发电厂故障数据诊断系统的使用中,对诊断速度与准确率的要求都较高。
发明内容
为了克服现有技术的不足,本发明提供一种发电厂故障数据诊断项目中的分层随机森林分类方法,在决策树的基础上采用集成学习的思想,并在随机森林算法的基础上采用分层模型。通过一级随机森林对故障数据中大概率存在的误报、漏报,再由二级随机森林对故障进行分类。其中每层通过随机选择样本和随机选择特征进行训练生成随机森林。
本发明解决其技术问题所采用的技术方案是:
一种发电厂故障数据诊断项目中的随机森林分类方法,从发电厂故障数据诊断系统中提取数据,对数据进行预处理,得到原始样本集;所述的方法包括以下步骤:
(1)建立随机森林模型,过程如下:
(1.1)设Y为原始样本集,其中总共有x个样例,则每轮从原始样本集Y中通过Bootstraping(有放回抽样)的方式抽取x个样例,得到一个大小为x的训练集Y
(1.2)建立决策树,包括以下步骤:
(1.2.1)设每个样本有N个特征,指定一个数n=|log
(1.2.2)每个节点都按照步骤(1.2.1)来分裂,直到不能够再分裂为止。利用CART方法使每棵树最大限度地生长,不进行剪枝;
(1.3)重复步骤(1.1)和(1.2).直到所有CART树都经过训练,组合所有决策树,构建成一级随机森林模型P
(2)对原始样本集Y进行处理,筛选并去除每项样本中对应类别为漏报、误报的项,数据处理操作后余下的样本集作为新的样本集Z,同时对测试集进行相同数据处理操作;
(3)将Z作为原始样本集,重复步骤(1)中所有操作,得到二级随机森林模型P
(4)利用测试集对二层随机森林模型进行测试,评估模型性能并进行调试;
(5)用随机森林分类器对新的数据进行判别与分类,分类结果按树分类器的投票多少而定,并将分类结果储存到数据库中。
进一步,所述发电厂故障数据诊断系统为SCADA或EMS系统。
本发明的工作原理是:本发明提出了一种发电厂故障数据诊断中的随机森林分类方法。从电网公司中获取数据,在建立决策树过程中,用基尼指数最小化准则,进行特征选择,生成二叉树:使用原始样本集建立一级随机森林模型,处理原始样本集,筛选留下非漏报误报故障样本项。使用新样本集建立二级随机森林模型,组合二层模型。最终随机森林分类模型通过投票规则得出分类结果。
本发明的有益效果主要表现在:1、对于存在大量误报、漏报的故障数据进行分层分类,有效解决问题。2、分类性能好。3、避免过拟合。
附图说明
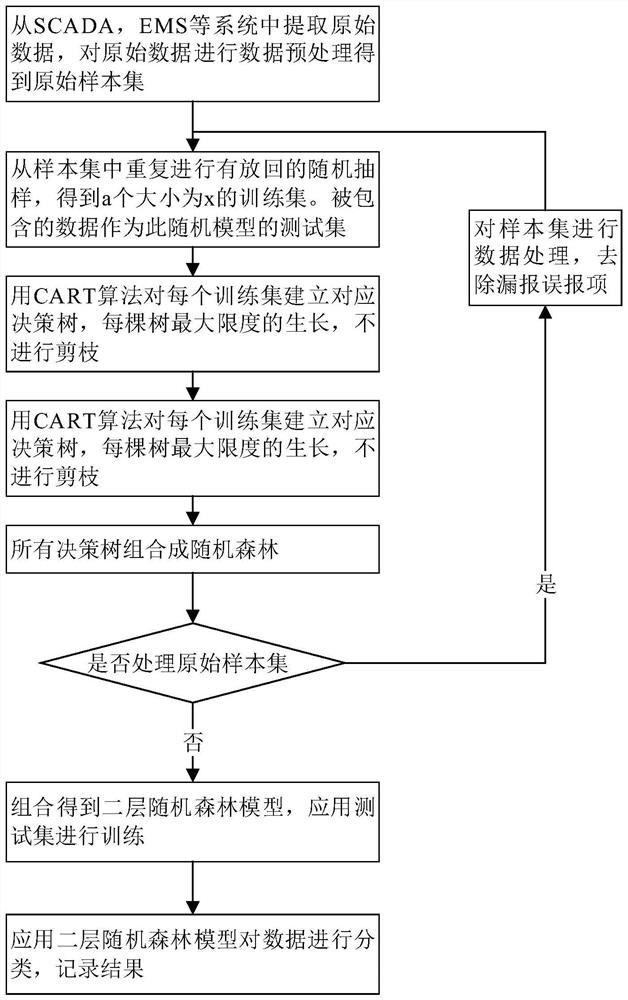
图1为发电厂故障数据诊断项目中的随机森林分类方法的流程图。
图2为发电厂故障数据的随机森林分类系统。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1,一种发电厂故障数据诊断项目中的随机森林分类方法,包括以下步骤:
第一步:从SCADA、EMS等系统中提取原始数据;
第二步:对原始数据进行数据预处理得到原始样本集Y,预处理包括:
2.1)将非数值类型的数据转换为数值类型
2.2)若样本中含缺失值,删除该样本
2.3)若存在两个或多个样本,属性值与类别均完全相同,只存留一个,删除其余重复样本
2.4)若存在两个或多个样本,属性值完全相同但类别不同,删除这些无效样本。
第三步:Y为原始样本集,其中总共有x个样例,则每轮从原始样本集Y中通过Bootstrap Sample(有放回抽样)的方式抽取x个样例,得到一个大小为x的训练集Y
第四步:依照训练集Y
每个样本有N个特征,指定一个数n=|log
每个节点都按照以上步骤来分裂,直到不能够再分裂为止,利用CART算法使每棵树最大限度地生长,不进行剪枝;
第五步:将a个决策树组合起来,每一颗决策树权重相同,构建得到随机森林模型P
第六步:利用测试集对随机森林模型P
第七步:对原始样本集Y进行处理,筛选并去除每项样本中对应结果类别为漏报、误报的项,数据处理操作后余下的样本集作为新的样本集Z。
第八步:使用新样本集Z,重复以上建立随机森林模型的步骤(即第三步至第五步),得到二级随机森林模型P
第九步:利用P
第十步:组合P
第十一步:用随机森林分类器对新的数据进行分类,并将分类结果储存到数据库中。
参照图2,应用本方法实现的发电厂故障数据识别项目中的二层随机森林分类系统,主要包括:分类模块、用户交互模块。所述分类模块根据模型进行分类,计算分类正确率。所述用户交互模块实现数据可视化展示,Web界面配置,应用程序配置。
本说明书的实施例所述的内容仅仅是对发明构思的实现形式的列举,仅作说明用途。本发明的保护范围不应当被视为仅限于本实施例所陈述的具体形式,本发明的保护范围也及于本领域的普通技术人员根据本发明构思所能想到的等同技术手段。
- 一种发电厂故障数据诊断项目中的随机森林分类方法
- 特征数据构建方法、数据集构建方法、数据分类方法、EMC故障的诊断方法和系统