一种基于机器学习的公共能源消耗预测方法
文献发布时间:2023-06-19 09:54:18
技术领域
本发明涉及能源消耗预测技术领域,更具体地说,涉及一种基于机器学习的公共能源消耗预测方法。
背景技术
在智慧城市的背景下,如何实现公共设施准确的能源消耗是一个亟待解决的重要问题,原因在于大型公共建筑物是主要的能源消费者,尤其是教育、卫生、政府等具有高使用频率的公共大型建筑,而准确的能耗预测模型能有效地为能耗监管和节能优化提供决策依据。但是,机器学习的最新发展在此领域中,大数据环境尚未得到充分利用。
经检索,中国专利申请号:201811519685.5,发明创造名称为:一种能源消耗预测方法及装置,该申请案公开了一种能源消耗预测方法及装置,包括:将获取的第一数据输入预先训练完成的ARIMA模型,将获取的第二数据输入预先训练完成的SVM模型;基于ARIMA模型,确定第一能源消耗预测值,基于SVM模型,确定第二能源消耗预测值;根据第一能源消耗预测值和第二能源消耗预测值,确定第一预测时间的目标能源消耗预测值。由于在进行能源消耗预测时,基于ARIMA模型,确定第一能源消耗预测值,基于SVM模型,确定第二能源消耗预测值。结合ARIMA模型确定的第一能源消耗预测值和SVM模型确定的第二能源消耗预测值,确定出目标能源消耗预测值。利用ARIMA模型和SVM模型的优点,使确定的目标能源消耗预测值更准确。该申请案仍有进一步优化的空间。
发明内容
1.发明要解决的技术问题
本发明的目的在于克服现有技术中公共能源消耗预测仍缺乏有效手段的现状,拟提供一种基于机器学习的公共能源消耗预测方法,主要解决如何将大数据平台和机器学习整合到用于管理能源的智能系统中,公共部门的效率是智慧城市概念的重要组成部分,本发明以在现有的MERIDA的智能系统中实现,为用户提供准确的能耗预测。
2.技术方案
为达到上述目的,本发明提供的技术方案为:
本发明的一种基于机器学习的公共能源消耗预测方法,包括以下步骤:
S101、数据收集;
S102、数据预处理,包括:
A、采用MAD算法进行离群值消除;
B、对缺失值进行替换;
C、采用PCA算法进行变量归约;
S103、预测建模;采用DNN深度神经网络进行计算,利用收集到的数据在Keras库里的R软件工具中将DNN与更多隐藏层一起使用,通过使用对称性评估所有DNN模型的准确性平均误差百分比;将训练样本进一步分为训练和测试子样本,神经网络在训练样本上进行k次迭代训练,并进行测试在测试子样本上;如果测试错误,则重复该过程子样本减少,或者最大迭代次数到达为100000,如果错误开始增加,则过程停止。
更进一步地,步骤S101中数据收集,包括从以下三种类型程序中进行数据收集:a、转让施工,每个公众的活力、地理空间、静态职业属性从EMIS信息系统获取;b、物联网网络中使用SCADA自动读取能耗传感器收集能耗数据和动态占用数据;c、收集网络中的环境数据,包括气温、风速、空气压力。
更进一步地,步骤S102中的离群值消除,具体包括以下过程:
A1、计算所有元素的中位值X
A2、计算所有元素与中位值的绝对偏差:bias=|X
A3、取得绝对偏差的中位值MAD=bias
A4、确定参数n,则可以对所有的数据作如下调整:
更进一步地,步骤S102中的对缺失值进行替换,具体包括以下过程:
B1、对无缺失值的n个样本样本求所有的阶差商公式;
B2、联立差商公式建立插值多项式f(x);
B3、将含有缺失值的样本对应的属性点x带入插值多项式f(x),获取近似值。
更进一步地,步骤S102中的变量归约,具体包括以下过程:
C1、一行为一个特征,对每个特征求平均值,用原来的数据减去每个特征的平均值,得到新的中心化之后的数据;
C2、求特征协方差矩阵;
C3、根据协方差矩阵,求特征值和特征向量;
C4、对特征值按照降序顺序排列,相应的给出特征向量,选择主成分,求投影矩阵;选择排序靠前的部分典型更精确数据进行投影矩阵;
C5、根据投影矩阵求出降维后的数据;
其中所有预处理步骤均与聚类一起执行程序,每个输入属性中的缺失值已被替换,通过该属性中其余值的平均值得出。
更进一步地,步骤S103中预测建模的具体过程如下:
采用人工神经网络,具有一个输入层、隐藏层和输出层,对于一个隐藏层,基本计算包括一个求和函数:输入层单元的加权输入;以及激活函数:通过使用线性函数或非线性函数计算隐藏层的输出;计算为:
其中yc是计算的输出,xi是输入向量的元素X,wi是权重向量W的元素,权重的值是最初从区间[-1,1]中随机确定,然后进行调整误差项,n是其中的隐藏节点数层;
利用收集到的数据在Keras库里的R软件工具中将DNN与第2、第3、第4隐藏层一起使用,重量调整为通过辍学方法进行泛化较好,辍学率为0.1,隐藏数通过交叉验证程序优化每个隐藏层中的单元,隐藏层的数量被选为随机间隔中的数字;激活函数应用于每个隐藏层和输出层,每个隐藏层的优化算法是Adam算法,学习率为0.001,最多训练200次;
通过使用对称性评估所有DNN模型的准确性平均误差百分比:
其中y
训练样本进一步分为训练和测试子样本,以便通过交叉验证确定DNN的训练时间程序;在该过程中,神经网络在训练样本上进行k次迭代训练,并进行测试在测试子样本上,如果测试错误,则重复该过程子样本减少,或者最大迭代次数为100000,如果错误开始增加,则过程停止。
3.有益效果
采用本发明提供的技术方案,与现有技术相比,具有如下有益效果:
(1)本发明的一种基于机器学习的公共能源消耗预测方法,将大数据平台和机器学习整整合应用在能源管理系统中,可以有效提高公共管理的能源效率,采用的预测模型集成了大数据收集和预测公共建筑中每种能源的能耗,预测模型建模方法简单,基于机器学习使能耗预测更准确。
(2)本发明的一种基于机器学习的公共能源消耗预测方法,所建模型可以在建议的名为MERIDA的智能系统中实现,该系统集成了大数据收集和预测公共建筑中每种能源的能耗模型,并实现他们的协同作用成为一个管理平台,以提高大数据中公共部门的能源效率环境,减少能源消耗以及成本。
(3)本发明的一种基于机器学习的公共能源消耗预测方法,将智能公共建筑连接为智能城市的一部分,这样的数字化转型能源管理可以提高公共管理的能源效率,更高的服务质量和更健康的环境。
附图说明
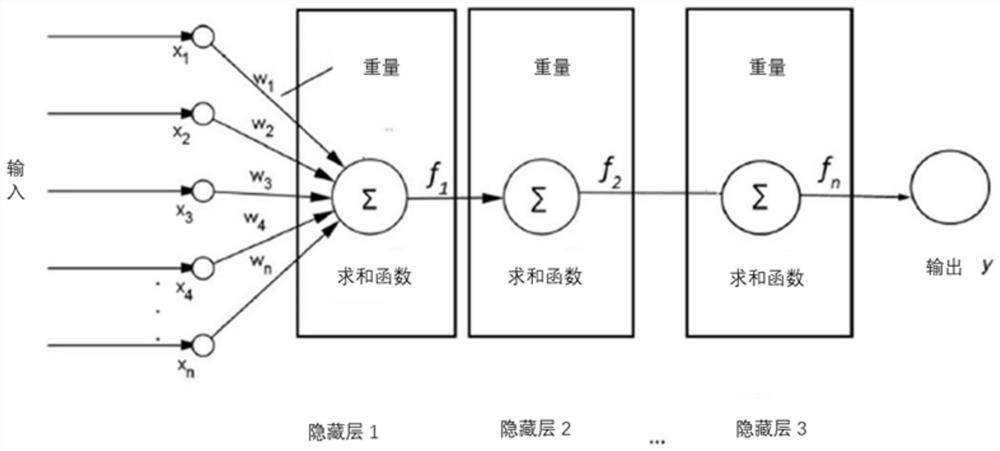
图1为本发明中具有三个隐藏层的DNN模型示意图。
具体实施方式
为进一步了解本发明的内容,结合附图对本发明作详细描述。
在本发明的描述中,需要说明的是,术语“中心”、“上”、“下”、“左”、“右”、“竖直”、“水平”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”、“第三”仅用于描述目的,而不能理解为指示或暗示相对重要性。
下面结合实施例对本发明作进一步的描述。
实施例1
本实施例的一种基于机器学习的公共能源消耗预测方法,包括以下步骤:
S101、数据收集;
架构中的大数据收集方法,包括从以下三种类型程序中进行数据收集:a、转让施工,每个公众的活力、地理空间、静态职业属性从EMIS信息系统获取;b、物联网网络中使用SCADA自动读取能耗传感器收集能耗数据和动态占用数据;c、收集网络中的环境数据,包括气温、风速、空气压力等等。
上述程序在每栋大楼内执行国家一级的公共部门可以创建大数据,存储在云中的数据集具有很高的数量、种类和速度。
S102、数据预处理,包括:
A、采用MAD算法进行离群值消除;具体包括以下过程:
A1、计算所有元素的中位值X
A2、计算所有元素与中位值的绝对偏差:bias=|X
A3、取得绝对偏差的中位值MAD=bias
A4、确定参数n,则可以对所有的数据作如下调整:
B、对缺失值进行替换;具体包括以下过程:
B1、对无缺失值的n个样本样本求所有的阶差商公式;
B2、联立差商公式建立插值多项式f(x);
B3、将含有缺失值的样本对应的属性点x带入插值多项式f(x),获取近似值。
C、采用PCA算法进行变量归约;具体包括以下过程:
C1、一行为一个特征,对每个特征求平均值,用原来的数据减去每个特征的平均值,得到新的中心化之后的数据;
C2、求特征协方差矩阵;
C3、根据协方差矩阵,求特征值和特征向量;
C4、对特征值按照降序顺序排列,相应的给出特征向量,选择主成分,求投影矩阵;选择排序靠前的部分典型更精确数据进行投影矩阵;
C5、根据投影矩阵求出降维后的数据;
其中所有预处理步骤均与聚类一起执行程序,每个输入属性中的缺失值已被替换,通过该属性中其余值的平均值得出。
S103、预测建模;采用DNN深度神经网络进行计算,利用收集到的数据在Keras库里的R软件工具中将DNN与更多隐藏层一起使用,通过使用对称性评估所有DNN模型的准确性平均误差百分比;将训练样本进一步分为训练和测试子样本,神经网络在训练样本上进行k次迭代训练,并进行测试在测试子样本上;如果测试错误,则重复该过程子样本减少,或者最大迭代次数到达为100000,如果错误开始增加,则过程停止。
具体过程如下:
采用人工神经网络,通常具有一个输入层、隐藏层和输出层,DNN可以添加许多隐藏层,更适合分析大数据集下样本的内在规律。对于一个隐藏层,基本计算包括一个求和函数:输入层单元的加权输入;以及激活函数:通过使用线性函数或非线性函数计算隐藏层的输出;计算为:
其中yc是计算的输出,xi是输入向量的元素X,wi是权重向量W的元素,权重的值是最初从区间[-1,1]中随机确定,然后进行调整误差项,n是其中的隐藏节点数层。
利用收集到的数据在Keras库里的R软件工具中将DNN与更多隐藏层如第2、第3、第4隐藏层一起使用,重量调整为通过辍学方法进行泛化较好,辍学率为0.1,隐藏数通过交叉验证程序优化每个隐藏层中的单元,隐藏层的数量被选为随机间隔中的数字;激活函数应用于每个隐藏层和输出层,每个隐藏层的优化算法是Adam算法,学习率为0.001,最多训练200次;具有三个隐藏层的DNN模型具体如图1所示。
通过使用对称性评估所有DNN模型的准确性平均误差百分比:
其中y
训练样本进一步分为训练和测试子样本,以便通过交叉验证确定DNN的训练时间程序;在该过程中,神经网络在训练样本上进行k次迭代训练,并进行测试在测试子样本上,如果测试错误,则重复该过程子样本减少,或者最大迭代次数为100000,如果错误开始增加,则过程停止。
本实施例将大数据平台和机器学习整合到用于管理能源的智能系统中。深度神经网络被用来创建特定的预测模型公共部门建筑物的能源消耗。所建模型可以在建议的名为MERIDA的智能系统中实现,该系统集成了大数据收集和预测公共建筑中每种能源的能耗模型,并实现他们的协同作用成为一个管理平台,以提高大数据中公共部门的能源效率环境,减少能源消耗以及成本。本实施例将此类智能公共建筑连接为智能城市的一部分,这样的数字化转型能源管理可以提高公共管理的能源效率,更高的服务质量和更健康的环境。
以下为具体案例,来自某地能源管理信息的真实数据集使用的EMIS系统最初包含17000多个带有大量变量的公共建筑物理,环境属性及其能耗。物理属性组包括建筑,供暖,冷却和能源数据,气象,地理空间和职业数据属性描述了环境因素。输入空间由82个属性以及能耗数据组成以下能源:电力,天然气和热,水以及2008年至2019年期间的二氧化碳排放量。
本模型中的变量是能源消耗Q1HNDREF代表单位能耗(SEC)(以kWh/(m2.a)表示)为每平方米加热所消耗的能量建筑物的建筑面积指令。它还包含了室内(19℃)和室外温度在采暖季节以及采暖季节的持续时间。数据也通过之间的距离进行归一化每个属性的最小值和最大值。之后预处理阶段,选择了575座公共建筑的样本用于创造机器学习价值。数据集随机分为训练和测试子集,以便将70%的数据用于训练,30%是用于验证所有三个结果的保留样本经过测试的机器学习方法。训练子集另外分为用于训练DNN的训练数据(占训练集的80%),而其余的训练集(20%)用于优化网络交叉验证中的体系结构,参数和学习时间程序。
以上示意性的对本发明及其实施方式进行了描述,该描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。所以,如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
- 一种基于机器学习的公共能源消耗预测方法
- 一种基于气候变化的能源消耗预测方法