基于改进PSPNet的语义分割方法
文献发布时间:2023-06-19 09:54:18
技术领域
本发明属于计算机视觉技术领域,尤其是涉及一种基于改进PSPNet的语义分割方法。
背景技术
语义分割涵盖了机器学习、计算机视觉、图像处理和人机交互等众多科学领域,有着广泛的应用前景和巨大的经济价值。随着人工智能和深度学习的飞速发展,人体语义分割也取得了突破性的进展。
语义分割是指使用一些算法让计算机可以自动的将图像中不同的类别分割出来。近年来有很多不同的深度学习框架的语义分割方法,其中包括全卷积网络(FullyConvolutional Networks,FCN)、完全对称的卷积网络(UNet)、以及基于空间金字塔的DeepLabV3等方法来进行图像的语义分割是目前研究的热门话题。
基于深度学习的语义分割方法在性能上相比于传统分割方法有很大提升,但仍存在一些问题:1.分割边缘不准的问题,相邻临的像素对应感受野内的图像信息太过相似,如果是不同类的像素点特征相似,那么很大程度的影响分割效果。2.传统的PSPNet使用的网络结构为ResNet网络,适用于深层网络,由于参数量过大等问题并不适用于轻量级网络。3.传统语义分割模型在特征提取的过程中会导致特征模糊、特征丢失等问题,进而影响实验结果。
发明内容
本发明的目的是针对现有技术中存在的问题和不足,提供了一种基于改进PSPNet的语义分割方法,将PSPNet做了相关的改进,有效的提升了网络模型对复杂图像中类别分割的效果,提升了网络模型的性能。
本发明的基于改进PSPNet的语义分割方法,其特征在于包括如下步骤,
步骤1:在相关网站上下载MobileNetV2预训练模型文件:mobilenetV2.h5放到模型预训练文件夹\PSPNet\pre_training下,将其作为网络的初始化参数模型;
步骤2:在相关网站上下载Baidu People segmentation dataset相关数据集,将其区分好训练集与测试集,训练集的图片名称与其标签名称对应;
步骤3:利用调整后数据集训练网络模型,对模型的参数进行微调,设置的最大迭代次数为50周期,初始的学习率设置为0.001,学习率衰减方式为连续3周期准确率没有提升,那么折半减小学习率继续训练;训练时将训练集分割成两部分,90%的训练图片用于模型训练,其余10%的图片用于模型每一周期的验证;模型每训练一周期保存一次模型文件,训练完成后模型的准确率达到90%以上,达到训练要求;
步骤4:将最终生成的网络模型放在指定的文件夹下,编写测试文件Test.py对模型的性能进行测试,查看网络的整体结构;
步骤5:选取待检测的图像,放入到指定的\PSPNet\demojPg文件夹,供后续测试使用;
步骤6:提取图像中的特征,将输入图像通过MobileNetV2网络提取特征;
步骤7:将反残差单元生成的特征图,通过双线性插值,将长宽统一定义到与输出尺寸一致之后在通道维数上进行融合,得到全新的特征结果。
步骤8:将得到的特征图首先使用卷积来获取最后的特征映射,然后将特征图划分为1×1、2×2、3×3、6×6四个不同的子区域,并对每个子区域进行池化;
步骤9:进行上采样和连接层以形成最终的特征表示,最后输入到卷积层来获得最终的每个像素的预测;
步骤10:优化误差,如果训练结果的误差较大,设置学习率降低的方式,采用训练中连续三轮的准确率没有上升,则折半下降学习率的方式,使训练准确率稳步提升,最终达到平稳;
步骤11:将网络预测的结果进行二值化、填充、边缘轮廓提取等处理;
步骤12:设置水平集方法的参数,迭代之后输出本发明的最终结果。
所述的步骤12,水平集后处理部分将迭代次数设置为5次,初始水平集轮廓设置为自定义的方式,由网络预测的结果生成;平滑系数常用设置为4,数值越大则曲线越平滑,阈值设置为0.4,小于阈值将认为是边界,曲线将在此停止;轮廓线演变方式为缩小,正数则会使轮廓扩大;高斯滤波器的标准差设置为2。
本发明的优点:
(1)本发明的基于改进PSPNet的语义分割方法,网络模型在图像语义分割中鲁棒性强,无论是图像中存在严重的大小差异、低分辨率和多目标等恶劣的条件都不会对分割结果产生太大的影响,减少了分割错误情况的出现;
(2)本发明的基于改进PSPNet的语义分割方法,采用的是17个反残差单元的MobileNetV2网络作为+PSPNet的前置网络,使整个网络趋向于轻量级,大大减少了网络参数更加适用于小型设备;
(3)本发明的基于改进PSPNet的语义分割方法,引入了上下文语义特征补充模块,在原始的基础上,借助注意力机制,找到了在全局感受野下含有丰富特征的特征图进行融合,解决了在采样过程中特征丢失和模糊等问题,使网络模型在特征提取时效率更高,提取的特征更加有用,从而提升整个网络性能;
(4)本发明的基于改进PSPNet的语义分割方法,将水平集方法作为后处理的方式引入到整个模型中,在像素级的预测结果中再利用边界梯度信息,使分割结果通过迭代,一步一步逼近目标的真实边界,提高整个模型的分割精度。
附图说明
图1本发明的总体网络结构图。
图2本发明中水平集方法过程图。
图3本发明中引入的注意力原理图。
图4本发明中权重结果图。
图5本发明中金字塔池化结构图。
图6本发明中水平集初始轮廓图。
具体实施方式
下面结合附图进一步说明本发明的具体实施方式。
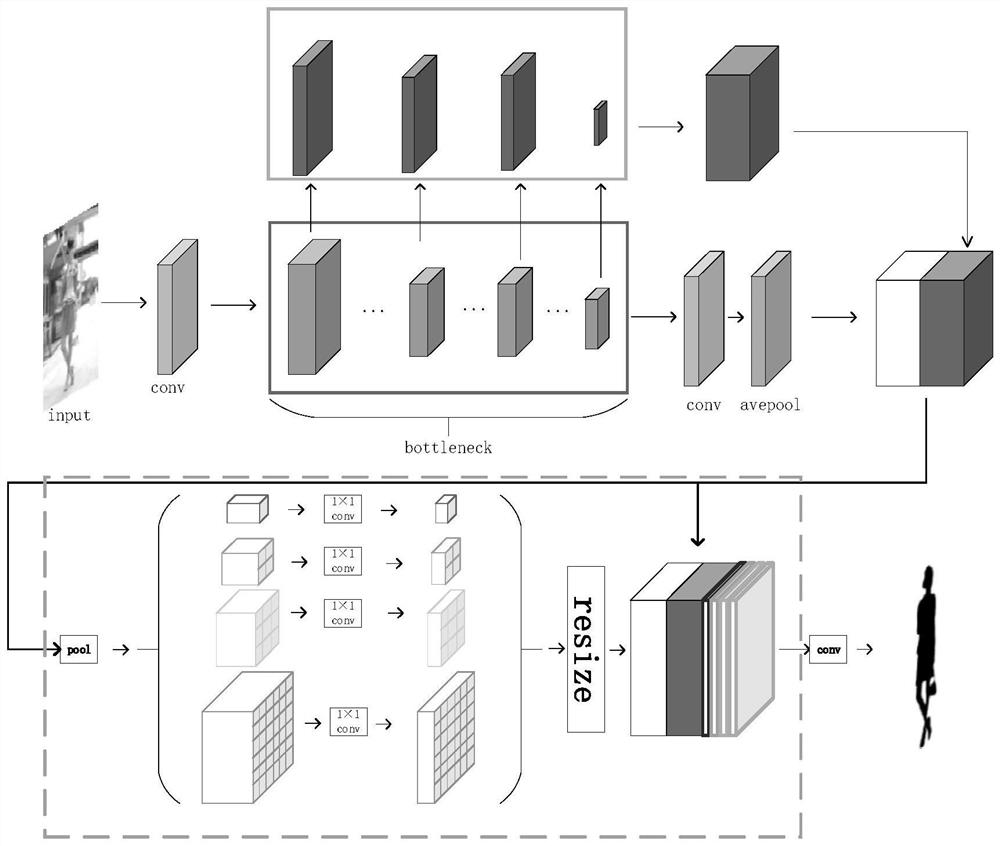
图1是本发明的总体网络结构图,包括特征提取部分;上下文语意特征补充部分;金字塔池化部分;预测每个像素点的类别。图2是本发明的水平集方法过程图,包含了从输入图像起到最终的演化结果。
a)本发明提出:使用轻量级的MobileNetV2网络来学习特征信息。引入上下文语义特征补充模块保留更多的特征,在网络对图像中的每个像素点进行分类预测后引入水平集方法作为网络后处理,使分割结果更加逼近目标真实轮廓,最终实现语义分割的目的。
第一步,为了解决由于深层网络带来的参数量过大,分割效率低的问题,本发明将传统PSPNet方法中用于提取图像特征的残差网络替换为具有更强表达能力更轻量级的MobileNetV2网络。
第二步,为了保留更多的特征信息,本发明引入上下文语义特征补充模块借助注意力机制,在特征提取过程中,为每个单元生成的特征图分配权重,保留在全局感受野下,对结果影响最大的几张特征图。最后通过双线性插值的方法,将特征图定义到统一的长宽并进行融合。
第三步,将上述重新定义的特征图通过金字塔池化结构,使全局语义信息与不同区域大小的局部语义信息完美结合。然后进行上采样和全连接层,得到最终的特征表示,最终输入卷积层以获得每个像素点的预测。
第四步,将网络预测的结果作为水平集方法的初始轮廓。通过二值化、填充等操作获取连续封闭的初始轮廓。通过GAC模型的迭代,使网络预测的结果继续收敛,更加逼近于目标真实轮廓。针对图像行为识别中交互目标定位不准确、存在将对象建立错误的行为关系的问题。最终完成本发明的全部分割过程。
b)发明的具体内容:
第一步中,本发明采用的是MobileNetV2网络,MobileNetV2网络保留了残差结构中的“跳跃连接”,且中间层使用深度可分离卷积,大大减少了网络整体的参数量。MobileNetV2的主要特点是反残差结构,传统的残差结构是先用1×1的卷积降维然后进行3×3的卷积最后再用1×1的卷积升维,产生了一种两边通道数多(“厚”),中间通道数少(“薄”)的类似“沙漏”一样的网络结构。而MobileNetV2中则是先用1×1的卷积升维再进行3×3的逐层卷积最后进行1×1的卷积降维,产生了一种两边通道数少(“薄”),中间通道数多(“厚”)的类似“纺锤”的网络结构。
MobileNetV2网络的前向传播是线性的,后层的输入是当前输入和每次反残差单元计算的残差和,在MobileNetV2网络的输入输出之间添加一个快捷连接,使前向传播是一个平滑的过程。经过多次计算得到深层的L单元的计算结果:
其中,X
反向传播的过程同前向传播一样都是一个平滑的过程。根据反向传播的链式法则,得到如下公式:
其中,大写字母E表示损失误差值,表达为
第二步中,为了使模型能够保留更过的特征信息,本发明在特征提取的过程中引入了上下文语义特征补充模块。本发明在特征提取时共有17个反残差单元,生成了17张不同尺寸的特征图。借助注意力机制来判断17张特征图的重要性并进行融合。注意力机制可以使网络执行特征重新校准,通过这种机制可以学习使用全局信息来选择性的强调某些特征并抑制不太用的特征。将17张特征图在进行1×1的卷积之后重新定义到统一长宽进行融合,最终生成一张17通道的特征图,每个通道代表了该特征图的特征。将这张特征图通过注意力模块来给各个通道分配权重,最终选择对全局结果影响较大的几张特征图进行融合。假设卷积核为V={v
u
其中*代表了卷积操作,输入一个通道上的空间特征,学习特征空间关系,但是由于对各个通道的卷积结果进行了融合,所以通道特征关系与卷积核学习到的空间关系混合在一起。注意力模块就是为了将这种混合在一起的特征分开,使得模型可以直接学习通道特征关系。注意力模块首先对卷积得到的特征图进行Squeeze操作,顺着空间维度来进行压缩,将每个特征通道变成一个实数,这个实数具有全局感受野,并且输出的维度和输入的通道数匹配,采用全局平均池化来实现:
其中,H,W分别表示特征图的长宽。这一步的结果相当于表明该层c个特征图的数值分布情况,就是在得到多个特征图之后采用全局平均池化操作对每个特征图进行压缩,使c个特征图最后变成1×1×c的实数列。然后对全局特征进行Excitation操作,通过参数W来为每个通道生成权重,其中参数W被学习用来显式的建模通道特征的重要性:
F
首先,将前面F
F
其中,u
第三步中,本发明延用了PSPNet中的金字塔池化结构,融合了四种不同尺度下的特征,将输入特征图划分成1×1,2×2、3×3、6×6个不同的子区域。对每个子区域进行池化,最后将包含位置信息的池化后的单个特征图组合起来。金字塔池化模块中不同层级输出不同尺度的特征图,为了保持全局特征的权重,在每个金字塔层级后使用1x1的卷积核,当某个层级维数为n时,即可将语义特征的维数降到原始特征的1/n。然后,通过双线性插值直接对低维特征图进行上采样,使其与原始特征图尺度相同。最后,将不同层级的特征图拼接为最终的金字塔池化全局特征。其中金字塔池化结构中每个层级的大小都可以修改,与输入金字塔池化层的特征图大小有关。该结构采用不同的池化核,即可提取不同子区域的特征。
第四步中,为了进一步提升模型的分割精度,本发明引入了水平集方法作为网络预测结果的后处理。水平集方法作为传统的图像分割方法,其主要思想是利用高维曲面的演化来表示低维曲线的演化过程,可以有效地利用图像的边缘信息。本发明将水平集方法作为后处理,将之前得到的结果作为初始轮廓,通过水平集方法的演化,更加逼近图像边界。
由于网络输出的结果,含有丰富的边界信息,所以直接采用GAC模型对结果进行后处理。推广GAC模型的水平集方法对应的PDE为:
通过上式可以看出曲线在GAC模型式演化时将受两种力的推进:其一是来自与曲线自身的几何形变,故称为内力
式中K是选定的常数,它可以控制g的下降速率。第二种力来自于g(α
上述公式分别是中心差分,向前单边差分和向后单边差分。根据公式:
进行迭代运算通过u
本发明的一种基于改进的PSPNet语义分割方法的具体实现步骤如下:
步骤1、在相关网站上下载MobileNetV2预训练模型文件:mobilenetV2.h5放到模型预训练文件夹\PSPNet\pre_training下,将其作为网络的初始化参数模型。
步骤2、在相关网站上下载Baidu People segmentation dataset相关数据集,将其区分好训练集与测试集,训练集的图片名称与其标签名称对应,为了方便区分,本发明对图片命名方式为“序号.jpg”,与之对应的标签命名方式为“序号.png”。
步骤3、利用调整后数据集训练网络模型,对模型的参数进行微调,设置的最大迭代次数为50周期,初始的学习率设置为0.001,学习率衰减方式为连续3周期准确率没有提升,那么折半减小学习率继续训练。训练时将训练集分割成两部分,90%的训练图片用于模型训练,其余10%的图片用于模型每一周期的验证。模型每训练一周期保存一次模型文件,训练完成后模型的准确率达到90%以上,达到训练要求。
步骤4、将最终生成的网络模型放在指定的文件夹下,编写测试文件Test.py对模型的性能进行测试,查看网络的整体结构。
步骤5、选取待检测的图像,放入到指定的\PSPNet\demojpg文件夹,供后续测试使用。
步骤6、提取图像中的特征。将输入图像通过MobileNetV2网络提取特征,MobileNetV2网络共有17个反残差单元如表1所示,输入图像为416×416的RGB图像,在经过不断地采样、池化等操作最终生成52×52长宽的特征图。在此过程中,借助注意力机制,如图3所示,将17个反残差单元生成的特征图统一定义长宽,生成一张17通道的特征图x,每个通道代表了对应的反残差单元生成的特征图的特征映射。最终得到了带有各自权重的17通道的特征图
表1本发明中MobileNetV2网络结构
步骤7、将第1、2、4、17个反残差单元生成的特征图,通过双线性插值,将长宽统一定义到与输出尺寸一致之后在通道维数上进行融合,得到全新的特征结果。
步骤8、将得到的特征图首先使用卷积来获取最后的特征映射,然后将特征图划分为1×1、2×2、3×3、6×6四个不同的子区域,并对每个子区域进行池化,如图5所示。
步骤9、进行上采样和连接层以形成最终的特征表示,最后输入到卷积层来获得最终的每个像素的预测。
步骤10、优化误差,如果训练结果的误差较大,设置学习率降低的方式,采用训练中连续三轮的准确率没有上升,则折半下降学习率的方式。使训练准确率稳步提升,最终达到平稳。
步骤11、将网络预测的结果进行二值化、填充、边缘轮廓提取等处理,如图6所示,作为水平集方法的初始轮廓。
步骤12、设置水平集方法的参数,本发明水平集后处理部分将迭代次数设置为5次,初始水平集轮廓设置为自定义的方式,由网络预测的结果生成。平滑系数常用设置为4,数值越大则曲线越平滑,阈值设置为0.4,小于阈值将认为是边界,曲线将在此停止。轮廓线演变方式为缩小,正数则会使轮廓扩大。高斯滤波器的标准差设置为2。迭代之后输出本发明的最终结果。
从上述技术方案可以看出,本发明根据现实生活中图像语义分割中面临的问题,如:分辨率低、多目标、背景复杂,对基于PSPNet的语义分割方法进行了改进。采用轻量级MobileNetV2网络,保证特征提取能力的基础上,大大减少了网络整体的参数量,更加适用于小型设备,进而使得网络训练更容易、更高效;在此基础上提出上下文语意特征补充模块来保留更丰富的语义特征;最后使用水平集方法作为网络的后处理部分,使得分割结果更加逼近于目标的真实轮廓,是整个模型分割精度有明显的提升。经过大量实验表明,本发明对于语义分割具有较高的准确度和较强的鲁棒性。
- 基于改进PSPNet的语义分割方法
- 基于语义分割网络PSPNet的甲状腺结节超声图像的分割方法