一种降低Turbo并行译码复杂度的实现方法及系统
文献发布时间:2023-06-19 10:00:31
技术领域
本发明涉及一种降低Turbo并行译码复杂度的实现方法及系统,涉及通信编译码技术领域。
背景技术
1993年C.Berrou等人提出的Turbo码的概念,由于很好的应用了香农信道编码定理中的随机性编译码条件,从而获得了几乎接近香农理论极限的译码性能。随着近年来各学者对Turbo码的不断研究,作为3GPP标准中LTE信道编码的主流方案之一,Turbo码已经进入了实用化阶段。
虽然Turbo码算法在不断的研究中逐渐趋于成熟,但应用中到实际的系统中仍然存在较多需要解决的问题,尤其是在硬件实现方面,问题主要归根于Turbo码译码算法复杂度较高,内部存在反馈,多次迭代时存在较大的时延。
为了降低时延,Turbo译码首先需要解决的是并行交织/解交织地址的问题,交织地址的产生一般采用两种方案,第一种是根据帧长预先生成特定的交织表进行存储,若支持不同的帧长,需存储不同的交织表,资源占用较多;第二种是采用实时计算,需通过计算机搜索获取交织系数,进行交织地址的实时计算。现有的并行交织方案一般是针对分组后的子块进行分别交织,交织和解交织采用不同的交织地址,增加计算复杂度或占用较多存储资源。
根据MAX-LOG-MAP算法可知,译码算法核心是计算分支状态度量、前向状态度量和后向状态度量,而前向状态度量和后向状态度量内部计算均存在反馈,且需进行多次迭代,对二者进行求最大值的算法实现复杂度较高,译码时延与计算复杂度和迭代次数成正比关系。
现有技术亟待解决的问题是有效降低译码算法复杂度,提高译码吞吐率的同时降低译码延时,减少硬件资源开销。
发明内容
发明目的:一个目的是提出一种降低Turbo并行译码复杂度的实现方法,以解决现有技术存在的上述问题。进一步目的是提出一种实现上述方法的系统。
技术方案:一种降低Turbo并行译码复杂度的实现方法,包括以下步骤:
步骤1,输入乒乓缓存单元,将输入的软信息序列根据分量译码器状态进行乒乓RAM缓存。
步骤2,交织/解交织地址索引单元,对内交织系数进行顺序存储,通过特定的计算,根据帧长信息索引RAM地址,实时获取不同帧长对应的交织系数,将交织地址通过特定计算,生成固定的交织并行索引地址并存储,交织和解交织采用同一索引地址。
进一步的,根据下式,获取并行交织RAM索引地址:
其中,k表示并行度,L表示子块长度,i满足0≤i≤k-1,j满足0≤j≤L-1,x满足0≤x≤N-1。
步骤3,第一分量译码器单元,设输入信息帧长为N,分为P块,每块数据长度L=N/P,实现中采用P路并行,采用P个子分量译码器,即分为P个窗实现,每个窗处理L个数据,译码采用MAX-LOG-MAP算法实现,本发明对该算法作进一步改进,对分支度量求最大值,降低译码复杂度。
进一步的,当检测到乒或乓RAM缓存完成指示信号,译码迭代开始,反馈一个乒或乓RAM当前被占用的指示信号occupy1,表示从乒或乓RAM中读取数据。
进一步的,设译码当前时刻为k,则k时刻的状态为s
其中,由于接收到信息位和校验位的不确定性,分支状态度量共有四个可能的状态值,用γ
进一步的,开始计算当前状态分支度量gamma及其最大值,对计算结果分别进行顺序存储。同时第二个窗对后向状态度量进行初始化,采用第二块数据预计算后向状态度量,并将边界值保存,作为下一时刻后向状态度量计算的初始值。
步骤4,计算前向状态度量。前向状态度量当前时刻的值由其前一时刻的值、当前时刻的分支转移度量值及最大值决定,当完成第一个gamma最大值计算时,第一个窗开始正向计算前向状态度量。计算方法如下式所示:
α
其中,α
进一步的,首先对alpha采用均匀分布进行初始化,并利用前一状态alpha、当前分支状态度量及gamma的最大值进行加和运算,获取前向状态度量alpha值。
步骤5,计算后向状态度量,简称beta。后向状态度量当前时刻的值由其后一时刻的值、当前时刻的分支转移度量值及其最大值决定,如式所示:
β
进一步的,beta采用第二个窗对第二块数据预计算beta保存的边界值作为初始值,通过beta的后向状态(初始值)、分支状态度量及gamma的最大值进行加和运算,获取后向状态度量beta值。
步骤6,计算外信息Le,外信息Le和beta的计算同时进行,先从缓存中按顺序读取alpha、gamma值,通过alpha、gamma和实时计算的beta值进行加和比运算,获取外信息Le值。
第二分量译码与第一分量译码工作原理相同,区别1在于二者分量译码工作存在一个窗长的延时,相比于传统的译码,译码时延降低了P倍;区别2在于其输入的软信息序列不同,以至于其输出的外信息序列不同。
进一步的,将原输入的系统软信息序列和第一分量译码器第一块数据输出的外信息Le采用并行交织索引,得到第二分量译码输入的系统信息和先验信息。当检测到第一分量译码第一块数据外信息计算完成指示信号时,第二分量译码反馈输入缓存模块一个指示信号occupy2信号,表示从输入缓存RAM读取系统校验信息
进一步的,当第二分量译码单元完成第一块数据的外信息Le2和LLR计算,进行交织/解交织地址索引计算单元进行解交织,作为第一分量译码输入的先验信息La1。
步骤7,剩余P-1个窗的计算重复步骤2-6,当P个窗的数据迭代满足一定次数,停止迭代,第二分量译码器按顺序输出最终似然比信息LLR,LLR通过交织地址索引单元进行解交织,硬判决后进行输出缓存处理,待下一模块读取数据。
基于上述实现方法,本发明提出一种降低Turbo并行译码复杂度的系统,该系统包括用于输入乒乓缓存单元,将输入的软信息序列根据分量译码器状态进行乒乓RAM缓存的第一模块;用于交织/解交织地址索引单元的第二模块;
用于对分支度量求最大值、以降低译码复杂度的第三模块;用于计算前向状态度量的第四模块;用于计算后向状态度量的第五模块;用于计算外信息Le的第六模块;以及用于在第二模块、第三模块、第四模块、第五模块、第六模块中重复迭代,当P个窗的数据迭代满足预定次数,停止迭代的第七模块。
进一步的,所述第二模块进一步用于对内交织系数进行顺序存储,根据帧长信息索引RAM地址,实时获取不同帧长对应的交织系数:
其中,addr
将交织地址通过计算生成固定的交织并行索引地址并存储,交织和解交织采用同一索引地址:
f(x)=(f1*x+f2*x
其中,f1和f2分别表示内交织系数,x表示交织前的信息地址,f(x)表示交织后的信息地址,mod表示求余,N表示帧长,也即交织深度;
所述第三模块进一步用于设定输入信息帧长为N,分为P块,每块数据长度L=N/P,采用P路并行,采用P个子分量译码器,即分为P个窗实现,每个窗处理L个数据;
当检测到乒或乓RAM缓存完成指示信号,译码迭代开始,反馈一个乒或乓RAM当前被占用的指示信号occupy1,表示从乒或乓RAM中读取数据;
设定译码当前时刻为k,则k时刻的状态为s
其中,由于接收到信息位和校验位的不确定性,分支状态度量共有四个可能的状态值,用γ
计算当前状态分支度量及其最大值,对计算结果分别进行顺序存储;同时第二个窗对后向状态度量进行初始化,采用第二块数据预计算后向状态度量,并将边界值保存,作为下一时刻后向状态度量计算的初始值;
所述第四模块进一步用于对前向度量值采用均匀分布进行初始化,并利用前一状态前向度量值、当前分支状态度量及分支度量的最大值进行加和运算,获取前向状态度量前向度量值;前向状态度量当前时刻的值由其前一时刻的值、当前时刻的分支转移度量值及最大值决定,当完成第一个分支度量最大值计算时,第一个窗开始正向计算前向状态度量,计算方法如下式所示:
α
其中,α
进一步的,所述第五模块进一步采用第二个窗对第二块数据预计算后向度量值保存的边界值作为初始值,通过后向度量值的后向状态、分支状态度量及状态分支度量的最大值进行加和运算,获取后向状态度量后向度量值;后向状态度量当前时刻的值由其后一时刻的值、当前时刻的分支转移度量值及其最大值决定,如式所示:
β
式中,β
所述第七模块中外信息Le和后向状态度量值的计算同时进行,先从缓存中按顺序读取前向状态度量值、状态分支度量值,通过前向状态度量值、状态分支度量值和实时计算的后向状态度量值值进行加和比运算,获取外信息Le值;
剩余P-1个窗的计算重复步骤2-6,当P个窗的数据迭代满足一定次数,停止迭代,第二分量译码器按顺序输出最终似然比信息LLR,LLR通过交织地址索引单元进行解交织,硬判决后进行输出缓存处理,待下一模块读取数据;
Λ(s
Λ(s
LLR=max
其中,Λ(s
有益效果:本发明涉及一种降低Turbo并行译码复杂度的实现方法及系统,通过特定的计算在FPGA内部实现了仅依据帧长信息即可索引内交织系数f1、f2,从而进行交织地址的实时简化计算,计算过程中无需对交织地址进行存储。经过大量的仿真验证,本发明在现有算法的基础上进行改进,因分支状态度量内部不存在反馈,采用对分支状态度量求最大值,相比现有方案,每次迭代均可节约2次计算分支度量的过程,有效的降低了计算复杂度。可兼容LTE协议的全部188种帧长,适应多种速率。针对目前译码实现复杂度较高和具有较大时延的问题,本发明有效降低了计算复杂度和时延,同时该方案也具有较低的误比特率。
附图说明
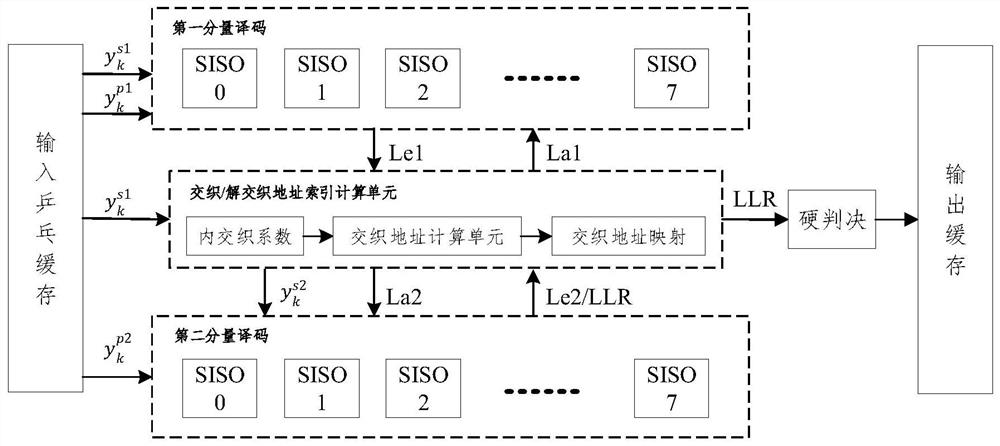
图1为本申请实施例提供的一种有效降低Turbo并行译码复杂度方法的结构示意图。
图2为本申请实施例提供的一种有效降低Turbo并行译码复杂度方法的流程示意图。
图3为本申请实施例提供的一种分量译码子译码器流程示意图。
图4为本申请实施例提供的一种有效降低Turbo并行译码复杂度方法的时序示意图。
图5为本申请实施例提供的一种有效降低Turbo并行译码复杂度方法的性能曲线图。
图6为本发明的整体工作流程图。
具体实施方式
在下文的描述中,给出了大量具体的细节以便提供对本发明更为彻底的理解。然而,对于本领域技术人员而言显而易见的是,本发明可以无需一个或多个这些细节而得以实施。在其他的例子中,为了避免与本发明发生混淆,对于本领域公知的一些技术特征未进行描述。
在一个实施例中,本申请实施例提供的一种低复杂度Turbo并行译码原理结构示意图。如图1所示,该方法包括:步骤S101至步骤S105。
步骤S101,输入乒乓缓存单元,采用乒乓RAM对输入的译码软信息根据分量译码器状态进行缓存,如帧长288,8路并行,每组软信息的个数为36,则采用2组RAM分别对输入的译码外信息进行乒乓缓存,译码外信息包括系统外信息、校验外信息1和校验外信息2,每组为8个RAM,每个RAM的深度均为36。
步骤S102,交织/解交织地址索引计算单元,采用深度为188的RAM对3GPP LTE协议的188组内交织系数进行顺序存储,每组包含3个参数信息,帧长及2个交织系数f1和f2。
进一步的,利用下式,根据不同的帧长索引RAM地址:
其中,addr
进一步的,可通过交织系数f1和f2获取不同帧长的交织地址:
f(x)=(f1*x+f2*x
其中,f1和f2分别表示内交织系数,x表示交织前的信息地址,f(x)表示交织后的信息地址,mod表示求余,N表示帧长,也即交织深度。
进一步的,将上式通过进一步变换可得到下式:
f(x)=(f(x-1)+f1+f2+2f2*(x-1))mod N 0≤x≤N-1
进一步的,优化后的计算复杂度明显降低,利于硬件实现。
进一步的,根据下式,获取并行交织RAM索引地址:
其中,k表示并行度,L表示子块长度,i满足0≤i≤k-1,j满足0≤j≤L-1,x满足0≤x≤N-1。
进一步的,通过索引地址对系统外信息进行分组交织。
步骤S103,第一分量译码单元,实现中采用8路并行,采用8个子分量译码器,即分为8个窗实现,每个窗处理一块数据即36个,译码采用MAX-LOG-MAP算法实现,本发明对该算法作进一步改进。
进一步的,当检测到乒或乓RAM缓存完成指示信号,译码迭代开始,反馈一个乒或乓RAM当前被占用的指示信号occupy1,表示从乒或乓RAM中读取数据。
进一步的,开始计算当前状态分支度量gamma及其最大值,对计算结果分别进行顺序存储。同时第二个窗对后向状态度量进行初始化,采用第二块数据预计算后向状态度量,并将边界值保存,作为下一时刻后向状态度量计算的初始值。
进一步的,对alpha采用均匀分布进行初始化,并利用前一状态alpha、当前分支状态度量及gamma的最大值进行加和运算,获取前向状态度量alpha值。
进一步的,beta采用第二个窗对第二块数据预计算beta保存的边界值作为初始值,通过beta的后向状态(初始值)、分支状态度量及gamma的最大值进行加和运算,获取后向状态度量beta值。
进一步的,如下式所示,计算外信息Le,外信息Le和beta的计算同时进行,先从缓存中按顺序读取alpha、gamma值,通过alpha、gamma和实时计算的beta值进行加和比运算,获取外信息Le值。
Λ(s
Λ(s
LLR=max
其中,Λ(s
步骤S104,第二分量译码单元,第二分量译码与第一分量译码工作原理相同,区别1在于二者分量译码工作存在一个窗长的延时,相比于传统的译码,译码时延降低了P倍;区别2在于其输入的软信息序列不同,以至于其输出的外信息序列不同。
进一步为,将原输入的系统软信息序列和第一分量译码器第一块数据输出的外信息Le采用并行交织索引地址进行交织,得到第二分量译码输入的系统信息
进一步的,根据并行交织索引公式可知,P个RAM地址为1的系统外信息,通过索引地址可得到交织后的数据需存放在P个交织RAM的地址19。
进一步的,当检测到第一分量译码第一块数据的外信息计算完成指示信号时,第二分量译码单元则反馈输入缓存模块一个occupy2指示信号信号,表示从输入缓存RAM读取系统校验信息
进一步的,当第二分量译码单元完成第一块数据的外信息Le2和LLR计算,进行交织/解交织地址索引计算单元进行解交织,作为第一分量译码输入的先验信息La1。
步骤S105,剩余P-1个窗的计算重复步骤2-8,当P个窗的数据迭代满足一定次数,停止迭代,第二分量译码器按顺序输出最终似然比信息LLR,LLR通过交织索引单元进行解交织,通过硬判决模块后进行输出缓存处理,待下一模块读取数据。
在一个实施例中,本申请实施例提供的一种低复杂度Turbo并行译码流程示意图。如图2所示,该方法包括:步骤S106至步骤S110。
步骤S106,根据分量译码工作状态进行输入译码信息的乒乓缓存。
步骤S107,译码开始时,第一分量译码器开始工作,判断其是否完成第P块数据外信息Le1的计算,若完成则进入交织地址索引单元进行并行交织得到第二分量译码的先验信息La2,若未完成,则继续进行第一分量译码。
步骤S108,读取输入乒乓缓存中的系统信息位
步骤S109,第二分量译码工作时,判断其是否完成第P块数据外信息Le2和LLR的计算,若完成,则进入交织地址索引单元进行并行解交织,得到第一分量译码的先验信息La1,若未完成,则继续进行第二分量译码。
步骤S110,当迭代满足达到一定次数,停止迭代,第二分量译码器按窗顺序输出最终似然比信息LLR交织地址索引单元进行解交织,通过硬判决单元后进行输出缓存处理。
在一个实施例中,本申请实施例提供的一种分量译码子译码器实现流程示意图。如图3所示,该方法包括:步骤S111至步骤S115。
步骤S111,计算当前4种可能状态的gamma值,同时将结果进行顺序缓存。
步骤S112,计算4种可能状态的gamma最大值,同时将结果进行顺序缓存。
步骤S113,正序读取缓存的gamma值和gamma最大值,计算alpha并将结果进行顺序缓存。
步骤S114,逆序读取缓存的gamma值和gamma最大值,计算beta。
步骤S115,正序读取alpha缓存值和gamma缓存值,结合当前beta值共同计算外信息Le及似然比信息LLR。
在一个实施例中,本申请实施例提供的一种低复杂度Turbo并行译码时序示意图。如图4所示,横坐标表示译码时间,单位为一个滑窗计算时间,纵坐标为窗长,单位为一个滑窗长度,蓝色表示第一分量译码时序,橙色表示第二分量译码时序,二者存在一个滑窗的延时,该方法包括:步骤S116至步骤S118。
步骤S116,T0时刻之前,第一个分量译码的第一个窗口W0正向计算gamma、gamma最大值和alpha,第二个窗W1反向预计算beta,T0时刻,顺序保存gamma、gamma最大值和alpha值。
步骤S116,T1时刻,第一分量译码第一个窗W0反向计算beta、外信息Le和似然比信息LLR。beta的初始值采用第一分量译码T0时刻反向预计算的beta值,第二个窗W1正向计算gamma、gamma最大值和alpha,第三个窗W2反向预计算beta。
进一步的,T1时刻,第二分量译码的第一个窗W0开始正向计算gamma、gamma最大值和alpha值,T0时刻第一分量译码保存的外信息经过交织地址索引单元进行交织,得到第二分量译码计算gamma需要的外信息La2。第二个窗W1反向预计算beta,T1时刻,保存gamma、gamma最大值和alpha值。
步骤S117,T2时刻,第一分量译码第二个窗W1反向计算beta、外信息Le和似然比信息LLR,beta的初始值采用第一分量译码T1时刻反向预计算的beta值,第三个窗W2正向计算gamma、gamma最大值和alpha,第四个窗W3反向预计算beta。
进一步的,T2时刻,第二分量译码第一个窗W0反向计算beta、外信息Le和似然比信息LLR,beta的初始值采用第二分量译码T1时刻反向预计算的beta值,第二个窗W1正向计算gamma、gamma最大值和alpha,第三个窗W2反向预计算beta。
步骤S118,依次类推,即可完成全部LLR似然比信息的计算。
在一个实施例中,本申请实施例提供的一种低复杂度Turbo并行译码性能曲线图。
如图5所示,为在AWGN信道下,BPSK调制,1/3码率,经过迭代6次的误比特率性能曲线,分别采用MAX-LOG-MAP算法和改进后的MAX-LOG-MAP算法仿真对比,可以看出两条曲线几乎完全吻合。
如上所述,尽管参照特定的优选实施例已经表示和表述了本发明,但其不得解释为对本发明自身的限制。在不脱离所附权利要求定义的本发明的精神和范围前提下,可对其在形式上和细节上做出各种变化。
- 一种降低Turbo并行译码复杂度的实现方法及系统
- 一种低复杂度近性能限的Turbo译码器的实现方法