一种城市数据分类方法及系统
文献发布时间:2023-06-19 10:06:57
技术领域
本发明涉及城市数据分析技术领域,特别是涉及一种城市数据分类方法及系统。
背景技术
为了能够进行高效快速的数据检索,针对城市数据存储成本高,信息检索效率低的特点对城市数据进行分类。城市中大量的数据需要经过存储、处理、查询和分析才能充分应用于各类应用,传统的存储系统只对数据进行简单的采集和存储,而对这些信息缺乏有效的分类研究。在大数据时代,城市数据规模的急剧扩大进一步凸显了传统方法的困境。如何对城市数据进行有效分类并提高数据的检索效率成为亟需解决的问题。
发明内容
本发明的目的是提供一种城市数据分类方法及系统,能够提高对城市数据检索效率和对城市数据分类的准确性。
为实现上述目的,本发明提供了如下方案:
一种城市数据分类方法,包括:
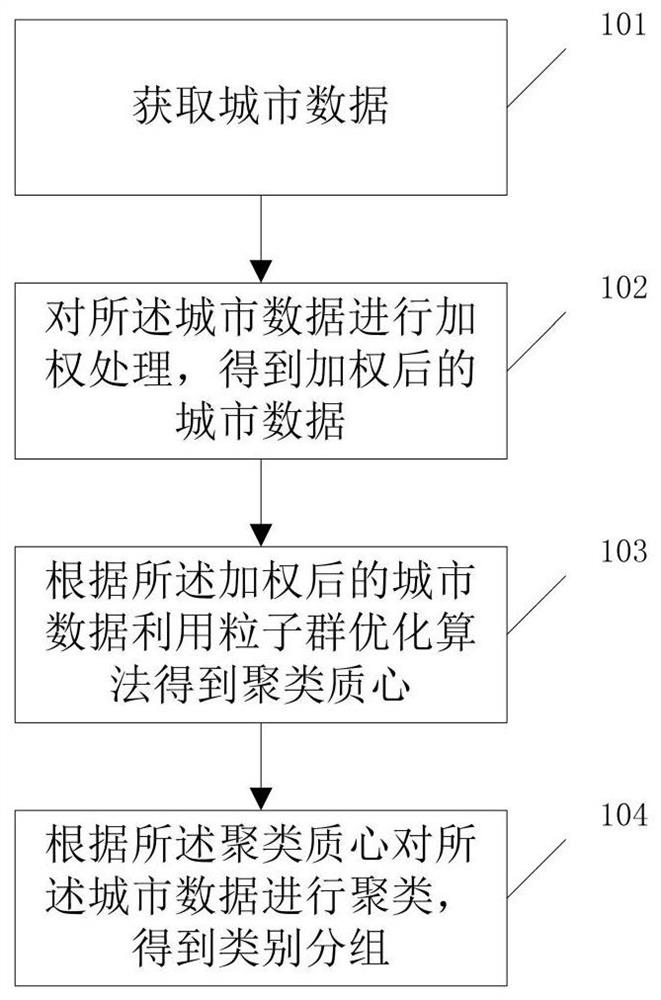
获取城市数据;
对所述城市数据进行加权处理,得到加权后的城市数据;
根据所述加权后的城市数据利用粒子群优化算法得到聚类质心;
根据所述聚类质心对所述城市数据进行聚类,得到类别分组。
可选的,所述对所述城市数据进行加权处理,得到加权后的城市数据,具体包括:
利用信息增益和信息增益比对所述城市数据进行加权处理,得到加权后的城市数据。
可选的,所述根据所述加权后的城市数据利用粒子群优化算法得到聚类质心,具体包括:
确定所述加权后的城市数据的相似度;
将k-mean聚类算法的初始聚类质心作为粒子群优化算法的粒子;
根据所述相似度确定粒子的适应度;
根据所述粒子的适应度确定平均适应度;
根据所述粒子的适应度和所述平均适应度更新粒子群优化算法的惯性权重;
根据所述惯性权重确定聚类质心。
可选的,所述相似度根据如下公式计算:
其中,R
可选的,所述根据所述聚类质心对所述城市数据进行聚类,得到类别分组,具体包括:
确定所述城市数据与每个所述聚类质心的欧式距离;
根据所述欧氏距离利用最近邻原则确定聚类结果;
重新计算所述聚类结果中的每个类别的新聚类质心;
判断所述新聚类质心和所述聚类质心的距离是否小于设定阈值,得到第一判断结果;
若所述第一判断结果表示为是,则确定所述聚类结果为最终的类别分组;
若所述第一判断结果表示为否,则将新聚类质心作为聚类质心,并返回步骤“确定所述城市数据与每个所述聚类质心的欧式距离”。
一种城市数据分类系统,其特征在于,包括:
获取模块,用于获取城市数据;
加权模块,用于对所述城市数据进行加权处理,得到加权后的城市数据;
质心确定模块,用于根据所述加权后的城市数据利用粒子群优化算法得到聚类质心;
类别分组模块,用于根据所述聚类质心对所述城市数据进行聚类,得到类别分组。
可选的,所述加权模块,具体包括:
加权单元,用于利用信息增益和信息增益比对所述城市数据进行加权处理,得到加权后的城市数据。
可选的,所述质心确定模块,具体包括:
相似度确定单元,用于确定所述加权后的城市数据的相似度;
粒子确定单元,用于将k-mean聚类算法的初始聚类质心作为粒子群优化算法的粒子;
适应度确定单元,用于根据所述相似度确定粒子的适应度;
平均适应度确定单元,用于据所述粒子的适应度确定平均适应度;
更新模块,用于根据所述粒子的适应度和所述平均适应度更新粒子群优化算法的惯性权重;
聚类质心确定单元,用于根据所述惯性权重确定聚类质心。
可选的,所述相似度根据如下公式计算:
其中,R
可选的,所述类别分组模块,具体包括:
欧式距离确定单元,用于确定所述城市数据与每个所述聚类质心的欧式距离;
确定聚类结果单元,用于根据所述欧氏距离利用最近邻原则确定聚类结果;
重新计算单元,用于重新计算所述聚类结果中的每个类别的新聚类质心;
判断单元,用于判断所述新聚类质心和所述聚类质心的距离是否小于设定阈值,得到第一判断结果;
类别分组确定单元,用于当所述第一判断结果表示为是时,则确定所述聚类结果为最终的类别分组;
返回单元,用于当所述第一判断结果表示为否时,则将新聚类质心作为聚类质心,并返回欧式距离确定单元。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明提供了一种城市数据分类方法,通过对城市数据进行加权处理,得到加权后的城市数据;根据加权后的城市数据利用粒子群优化算法得到聚类质心;根据聚类质心对所述城市数据进行聚类,得到类别分组。城市数据分类方法按照k-means聚类的基本原理,根据数据与数据的相似度进行分组,极大地提高了数据的检索效率。利用粒子群优化算法优化得到初始聚类质心,进一步提高城市数据分类准确性,使算法能更好的适用于城市数据分类。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明城市数据分类方法流程图;
图2为本发明城市数据分类系统示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种城市数据分类方法及系统,能够提高对城市数据检索效率和对城市数据分类的准确性。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
如图1所示,本发明提供的一种城市数据分类方法,包括:
步骤101:获取城市数据。
步骤102:对所述城市数据进行加权处理,得到加权后的城市数据。步骤102,具体包括:利用信息增益和信息增益比对所述城市数据进行加权处理,得到加权后的城市数据。从而进一步提高分类准确性。
信息增益是一种基于熵的特征重要度估计方法。它通过在分类过程中携带的信息量来决定一个特征的分类贡献率。一个特定特征承载的信息越多,该特征对分类的贡献就越大,因此该特征的权重也就越大。信息增益比是基于信息增益和一个惩罚参数,惩罚参数是某一特征的熵的倒数,当特征包含更多的信息时,惩罚参数越小,信息增益比越小,赋予该特征的权重就越小。结合两者的特点为数据进行加权。
步骤1.计算类别D的熵,计算公式如下:
其中,H(D)表示类别D的熵,P(D
步骤2.计算特征A
其中,q表示第q个特征值,
步骤3.计算特征A
g(D,A
步骤4.计算特征A
其中,m表示特征的个数,A
步骤5.计算特征A
其中,M表示特征的总个数,W
步骤6.计算特征A
其中,M表示特征的总个数。W
步骤7.计算特征A
W=W
其中,W为表示特征A
步骤8.根据计算得到的每个特征的最终权重为城市数据进行加权,并将加权后的数据用于k-means聚类算法中。
步骤103:根据所述加权后的城市数据利用粒子群优化算法得到聚类质心。利用粒子群优化算法优化k-means得到聚类质心,同时为提高搜索效率,对粒子群算法中粒子的惯性权重进行改进。计算数据与每个聚类质心的欧氏距离作为相似度,按照相似度对数据集进行分组。
步骤103,具体包括:
确定所述加权后的城市数据的相似度。所述相似度根据如下公式计算:
其中,R
将k-mean聚类算法的初始聚类质心作为粒子群优化算法的粒子。
根据所述相似度确定粒子的适应度。
根据所述粒子的适应度确定平均适应度。
根据所述粒子的适应度和所述平均适应度更新粒子群优化算法的惯性权重。
根据所述惯性权重确定聚类质心。
步骤104:根据所述聚类质心对所述城市数据进行聚类,得到类别分组。
步骤104,具体包括:
确定所述城市数据与每个所述聚类质心的欧式距离。
根据所述欧氏距离利用最近邻原则确定聚类结果。
重新计算所述聚类结果中的每个类别的新聚类质心。
判断所述新聚类质心和所述聚类质心的距离是否小于设定阈值,得到第一判断结果。若所述第一判断结果表示为是,则确定所述聚类结果为最终的类别分组;若所述第一判断结果表示为否,则将新聚类质心作为聚类质心,并返回步骤“确定所述城市数据与每个所述聚类质心的欧式距离”。
为了提高粒子群算法的搜索效率,克服固定惯性权重对算法的影响,利用粒子的适应度对惯性权重的设置进行了改进。
首先定义粒子的适应度函数。通过计算类内距离和类外距离得到相似度,并选择某个类与其他类之间的最大相似度作为适应度。相似度越小,粒子的适应度值越小,选择适应度值较小的粒子作为k-means的初始聚类质心。
类内距离是指类内数据到聚类中心的平均距离,表示同一类内数据的分散程度。计算公式为:
其中,S
类外距离计算公式为:
其中,n表示质心取值的个数,c
相似度计算公式为:
其中,S
根据相似度计算公式得到第i个类与其他类相似度的最大值,粒子群算法选择k-means初始聚类质心作为粒子进行优化选择,该最大值即第i个粒子的适应度f
然后计算每个粒子的适应度并计算得到平均适应度:
其中,f
最后,通过比较每个粒子的适应度和平均适应度来计算粒子的惯性权重。设置w
A
如图2所示,本发明提供的一种城市数据分类系统,包括:
获取模块201,用于获取城市数据。
加权模块202,用于对所述城市数据进行加权处理,得到加权后的城市数据;所述加权模块202,具体包括:加权单元,用于利用信息增益和信息增益比对所述城市数据进行加权处理,得到加权后的城市数据。
质心确定模块203,用于根据所述加权后的城市数据利用粒子群优化算法得到聚类质心;所述质心确定模块203,具体包括:相似度确定单元,用于确定所述加权后的城市数据的相似度;粒子确定单元,用于将k-mean聚类算法的初始聚类质心作为粒子群优化算法的粒子;适应度确定单元,用于根据所述相似度确定粒子的适应度;平均适应度确定单元,用于据所述粒子的适应度确定平均适应度;更新模块,用于根据所述粒子的适应度和所述平均适应度更新粒子群优化算法的惯性权重;聚类质心确定单元,用于根据所述惯性权重确定聚类质心。
类别分组模块204,用于根据所述聚类质心对所述城市数据进行聚类,得到类别分组。所述类别分组模块204,具体包括:欧式距离确定单元,用于确定所述城市数据与每个所述聚类质心的欧式距离;确定聚类结果单元,用于根据所述欧氏距离利用最近邻原则确定聚类结果;重新计算单元,用于重新计算所述聚类结果中的每个类别的新聚类质心;判断单元,用于判断所述新聚类质心和所述聚类质心的距离是否小于设定阈值,得到第一判断结果;类别分组确定单元,用于当所述第一判断结果表示为是时,则确定所述聚类结果为最终的类别分组;返回单元,用于当所述第一判断结果表示为否时,则将新聚类质心作为聚类质心,并返回欧式距离确定单元。
其中,所述相似度根据如下公式计算:
其中,R
对输入城市数据集进行加权是进行城市数据分类的基础,数据的权重能够反映各特征对分类结果的贡献,提高k-means聚类的精度。本发明还提供了一种城市数据分类方法的流程,具体步骤如下:
1、分析城市数据,为数据加权。
2、在已加权的数据中随机选择多个初始聚类质心。
3、利用改进的粒子群优化算法得到已优化的初始聚类质心。
4、计算数据集中每个样本数据与每个质心的欧氏距离,并根据最近邻原则将其划分为最近邻类。
5、重新计算每个新生成类的质心。
6、如果新计算的质心与原质心的距离小于设定的阈值(说明重新计算的质心的位置变化不大,趋于稳定或收敛),则聚类达到了预期的结果,算法终止。如果新质心与原质心的距离大于设定的阈值,则将新质心替换原质心,并返回步骤4。
本发明提供的一种城市数据分类方法,以k-means算法为基础,针对城市数据存储成本高,信息检索效率低的特点提出一种改进的分类方法,以提高城市数据的搜索效率。城市中大量的数据需要经过存储、处理、查询和分析才能充分应用于各类应用,传统的存储系统只对数据进行简单的采集和存储,而对这些信息缺乏有效的分类研究。由于城市数据数量规模大且分散,而且对城市数据的处理、查询以及分析的实时性要求越来越高,为城市数据的高效检索带来挑战。首先提出利用一种数据加权方法对算法进行改进。城市数据分类方法按照k-means聚类的基本原理,根据数据与数据的相似度进行分组,极大地提高了数据的检索效率。但是由于k-means聚类对初始选择值比较敏感,随机选择初始聚类质心会影响聚类精度。为进一步提高城市数据分类准确性,本方法利用改进的粒子群优化算法优化得到初始聚类质心,使算法能更好的适用于城市数据分类。对输入的城市数据进行加权,并对其进行初始聚类质心选择以进行分类。采用粒子群优化算法对初始聚类质心进行优化选择,通过调整粒子的惯性权重来改进初始聚类质心的选择。用来解决由于k-means聚类对初始选择值敏感导致的随机选择初始聚类质心会影响分类精度的问题。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 一种城市数据分类方法及系统
- 一种融合多源卫星遥感数据的城市建筑物材质分类方法