一种基于多模态特征融合的高安全性身份验证方法
文献发布时间:2023-06-19 10:16:30
技术领域
本发明属于身份验证领域,尤其涉及一种基于多模态特征融合的高安全性身份验证方法。
背景技术
社矫人员按照规定需要定期利用“无人矫正亭”在进行身份验证后进行打卡并且汇报思想和行踪。身份验证时,如果单纯采用基本的人脸识别,可能存在利用照片、录制视频、制作三维模型等方法进行欺骗,实现冒名打卡的情况。为了解决此类问题,同时考虑到使用的简便性和建设经费有限性,需要考虑以较低的成本,实现方便可靠的身份识别方法。
目前,活体检测是应对的基本方法,其主要的防范策略可以分为三类:基于红外光谱的人脸识别、RGB静默人脸识别和基于交互的人脸识别。其中,红外光谱识别要用到的专用摄像头,很大程度提高了检测成本并限制其适用的范围。对于RGB人脸识别,照片和视频的清晰度越来越高,其光学特征与人脸可以做得很接近。而基于交互的人脸识别过程繁琐、人机交互不够友好、不能防范3D人脸模型攻击。
发明内容
发明目的:针对以上问题,本发明提出一种基于多模态特征融合的高安全性身份验证方法,综合运用人脸识别、唇语识别、语音识别、说话人确认等身份验证技术进行有机融合,在进行基本的人脸识别同时也采取了等其他验证手段,实现交叉验证,从而有效防止照片攻击、视频攻击和三维模型攻击,提高身份验证的可靠性。
上述的目的通过以下技术方案实现:
一种基于多模态特征融合的高安全性身份验证方法,该方法包括如下步骤:
(1)采集使用者读取验证码时的音视频资料;
(2)对收集到的音视频资料进行人脸识别验证;
(3)对收集到的音视频资料进行图像识别判断,用户的唇部动作与读实时数字的唇部动作是否相仿,如果相仿,则通过比照;
(4)对收集到的音视频资料进行进行语音验证,验证说话人声纹是否与注册时说话人声纹相仿,并且根据声音再判断用户读的数字是不是屏幕上随机出现的验证码。
所述的基于多模态特征融合的高安全性身份验证方法,步骤(3)中所述图像识别判断包括如下步骤:
(31)对于人脸区域的检测,本实施例采用采用的是Dlib进行人脸68个关键点的检测;
(32)采用68特征点中的第49-68特征点对唇部区域进行定位,作为唇语识别的特征数据进行训练输入;
(32)采用3D-CNN模型从已经提取好的唇语图像序列中提取特征,通过执行3D卷积在时间和空间上提取特征,进行训练得到输出。
所述的基于多模态特征融合的高安全性身份验证方法,步骤(4)中所述对收集到的音视频资料进行进行语音验证包括声纹的特征提取和学习模型的选择,在声纹的特征提取方面,采取的声纹的MFCC特征,将声纹预处理后划分成许多单独的帧,并通过短时傅里叶变换将每帧声纹都转化为对应的频谱,之后对频谱进行梅尔频率分析和倒谱分析,便可获得声纹的MFCC特征;在学习模型选择方面,采用卷积神经网络和连接性时序分类模型相结合的方法,其中CTC模型用于合并声纹中相同的音素符号来保证输出序列的正确性,在模型的实现方面采用TensorFlow和Keras框架来构建网络模型并训练,在预测过程中计算对应音频的特征向量并使用对应模型对特征向量进行计算便可获得音频中的拼音数据。
有益效果:本发明与现有技术相比有以下几个显著优点:
1.本发明提出的这一种方法无需专用设备,在普通电脑和手机上即可完成带活体检测的身份验证,成本低廉。
2.本发明操作便捷,用户只需读出屏幕上的数字即可通过验证。
3.本发明提出的这一种方法安全性非常高。单纯的照片攻击无法通过语音及唇语识别验证。视频攻击对本发明也是不奏效的,因为几位数字组成的方式很多,不可能通过录制几万条视频进行攻击。而电脑3D模型以及仿真面具模型攻击也是不奏效的,因为按照此法攻击无法通过声纹验证。
附图说明
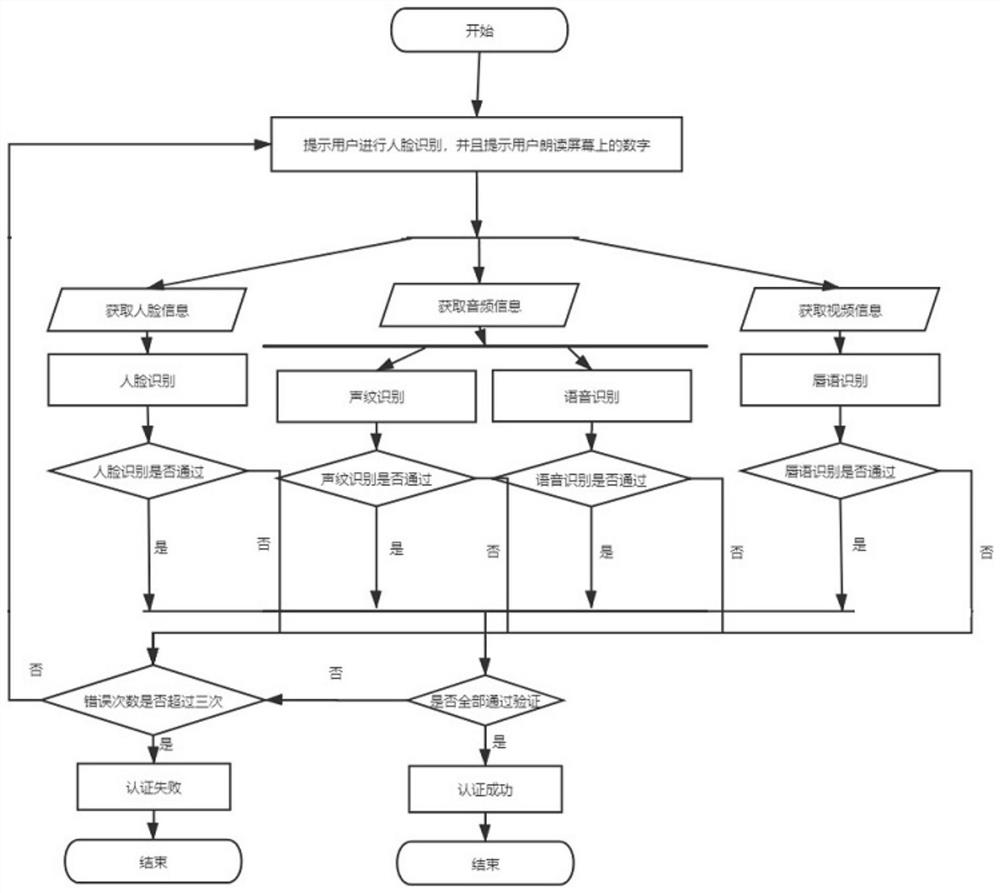
图1是本发明提供的高安全性身份验证方法的流程示意图。
图2是本发明的3D ResNet结构图。
图3是本发明的卷积神经网络结构定义图。
具体实施方式
下面结合附图和实施例对本发明作进一步详细说明。
如图1所示,本发明提供的一种基于多模态特征融合的高安全性身份验证方法,该方法包括如下步骤:
(1)采集使用者读取验证码时的音视频资料;
(2)对收集到的音视频资料进行人脸识别验证;
(3)对收集到的音视频资料进行图像识别判断,用户的唇部动作与读实时数字的唇部动作是否相仿,如果相仿,则通过比照;
(4)对收集到的音视频资料进行进行语音验证,验证说话人声纹是否与注册时说话人声纹相仿,并且根据声音再判断用户读的数字是不是屏幕上随机出现的验证码。
这四种方法可以根据实际需要和安全等级要求,自由组合,如要求高时,四种方式必须都要通过,安全要求适中时,只需要通过2-3项。
声纹识别
数据集
本实施例的数据集使用的是Free ST Chinese Mandarin Corpus数据集,这个数据集一共有855个人的语音数据,每人120条音频,共102600条语音数据。
训练过程
语音数据小而多,实施例中把这些音频文件生成TFRecord,加快训练速度。所以创建create_data.py用于生成TFRecord(TFRecord内部使用了“Protocol Buffer”二进制数据编码方案,它只占用一个内存块,只需要一次性加载一个二进制文件的方式即可,简单,快速,尤其对大型训练数据很友好。而且当我们的训练数据量比较大的时候,可以将数据分成多个TFRecord文件,来提高处理效率)文件。
首先是创建一个数据列表,数据列表的格式为<语音文件路径\t语音分类标签>,创建这个列表主要是方便之后的读取,也是方便读取使用其他的语音数据集,不同的语音数据集,可以通过编写对应的生成数据列表的函数,把这些数据集都写在同一个数据列表中,这样就可以在下一步直接生成TFRecord文件了。
有了上面创建的数据列表,就可以把语音数据转换成训练数据了,主要是把语音数据转换成梅尔频谱(Mel Spectrogram),使用librosa可以很方便得到音频的梅尔频谱,使用的API为librosa.feature.melspectrogram(),输出的是numpy值,可以直接用tensorflow训练和预测。在转换过程中,还使用了librosa.effects.split裁剪掉静音部分的音频,这样可以减少训练数据的噪声,提供训练准确率。实施例默认每条语音的长度为2.04秒,这个可以根据具体的情况修改语音的长度,如果要修改训练语音的长,需要根据注释的提示修改相应的数据值。如果语音长度比较长的,程序会随机裁剪20次,以达到数据增强的效果。
创建train.py开始训练模型,搭建一个ResNet50分类模型,input_shape设置为(128,None,1))主要是为了适配其他音频长度的输入和预测是任意大小的输入。class_dim为分类的总数,Free ST Chinese Mandarin Corpus数据集一共有855个人的语音数据,所以这里分类总数为855。
开始执行训练,本实施例在创建TFRecord文件时,已经把音频数据的梅尔频谱转换为一维list了,所以在数据输入到模型前,把数据reshape为之前的shape,操作方式为reshape((-1,128,128,1))。要注意的是如果使用了其他长度的音频,需要根据梅尔频谱的shape修改,训练数据和测试数据都需要做同样的处理。每训练200个batch执行一次测试和保存模型,包括预测模型和网络权重。
声纹对比
下面开始实现声纹对比,创建infer_contrast.py程序,在加载模型时,不要直接加载整个模型,而是加载模型的最后分类层的上一层,这样就可以获取到语音的特征数据。通过使用netron查看每一层的输入和输出的名称。
然后编写两个函数,分类是加载数据和执行预测的函数,在这个加载数据函数中并没有限定输入音频的大小,只是不允许裁剪静音后的音频不能小于0.5秒,这样就可以输入任意长度的音频。执行预测之后数据的是语音的特征值。
有了上面两个函数,就可以做声纹识别了。输入两个语音,通过预测函数获取他们的特征数据,使用这个特征数据可以求他们的对角余弦值,得到的结果可以作为他们相识度。对于这个相识度的阈值,可以根据项目的准确度要求进行修改。
2)语音识别
语音识别包括声纹的特征提取和学习模型的选择,在声纹的特征提取方面,本实施例采取的声纹的MFCC特征,提取主要将声纹预处理后划分成许多单独的帧,并通过SFFT(短时傅里叶变换)将每帧声纹都转化为对应的频谱,之后对频谱进行梅尔频率分析和倒谱分析,便可获得声纹的MFCC特征。在学习模型选择方面,由于声音在时间上的连续性和相同间隔时间内信息范围的不确定性,本实施例选择采用卷积神经网络(CNN)和连接性时序分类模型(CTC)相结合的方法,其中CTC模型用于合并声纹中相同的音素符号来保证输出序列的正确性。在模型的实现方面本实施例选择采用TensorFlow和Keras框架来构建网络模型并训练。在预测过程中计算对应音频的特征向量并使用对应模型对特征向量进行计算便可获得音频中的拼音数据了。
3)唇语识别
唇语识别数据集预处理
唇语识别数据集预处理主要包括唇动视频中关键帧的提取、人脸区域的检测和唇部区域的定位与提取。
对于唇动视频,本实施例采用说话人与镜头无明显相对运动的正面人脸发音视频集,说话内容包括数字0-9,每个发音序列大约持续一秒并且不同的数字发音间隔大于0.3秒。由此可通过语音分析在音频信号上精确定位每个独立发音单元的开始时间和结束时间。因为每个发音序列持续约1秒,但截取的发音持续时间不相同。所以从每段独立的发音视频中采样出固定长度的序列,将该序列称为关键帧。
对于人脸区域的检测,本实施例采用采用的是Dlib进行人脸68个关键点的检测。
对于唇部区域的定位与提取,本实施例采用68特征点中的第49-68特征点对唇部区域进行定位,作为唇语识别的特征数据进行训练输入。其中包括了12个唇部外部轮廓特征点和8个内部轮廓特征点,而第49、51、53、55、58点分别为唇部的左右两个嘴角点,上嘴唇的两个最高点和下嘴唇的一个最低点。由这五个关键点可以确定一张图片中嘴唇的边界。之后将提取出的唇部区域进行统一化处理并将数据集预处理完毕。
本实施例提出3D-CNN模型从已经提取好的唇语图像序列中提取特征,通过执行3D卷积在时间和空间上提取特征,进行训练得到输出。
一般的CNN模型主要用于2D图像,但是对于视频的预测,需要结合视频的前后帧进行识别。要想将CNN用于视频中人体动作的识别,一种方法是可以将视频的每一帧视为精致图像,并且用CNN来识别单个帧的级别动作,但是这样忽略了多个连续帧的编码运动信息。为了有效的结合视频中的运动信息,可以在CNN卷积层中执行3D卷积,以便获取空间和时间维度的辨别特征。3D CNN架构可以从相邻的视频帧生成多个信息通道,并在每个通道中分别执行卷积和下采样,通过组合来自视频通道的信息获得最终特征表示。
实现过程
根据具体的实际情况,本实施例构造了3D ResNet模型来进行训练和预测。ResNet(深度残差神经网络),通过学习输入x和映射H(x)之间的残差模块F(x)=H(x)-x,引入了残差模块,并在对应元素的位置上执行假发运算,极大地简化了对于恒等层地学习。
3D ResNet的结构如图2。
根据前面工作中对于视频的切片和唇部特征的提取,我们对于卷积神经网络的结构进行如图3定义。
使用tensorflow搭建对应的神经网络结构其中内核kernel的深度和输入数据相同。此外,设置步长stride=2,增加了训练的鲁棒性。
以上显示和描述了本发明的基本原理、主要特征和优点。本领域的技术人员应该了解,本发明不受上述具体实施例的限制,上述具体实施例和说明书中的描述只是为了进一步说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护的范围由权利要求书及其等效物界定。
- 一种基于多模态特征融合的高安全性身份验证方法
- 基于进化策略的多模态生物特征融合的身份识别方法