一种基于知识图谱的智慧城市数据构建方法
文献发布时间:2023-06-19 10:27:30
技术领域
本发明涉及智慧城市技术领域,尤其是一种基于知识图谱的智慧城市数据构建方法。
背景技术
云计算、大数据、互联网等技术的飞速发展,智慧城市已经成为一种城市发展理念,智慧城市建设也从感知智能到认知智能稳步提升。而5G技术的到来更是加快提升城市的感知能力。数据的获取更快、更多、更全,并且数据呈现多模态趋势,包含了文字、图像、音视频等非结构化数据。而想要更好的处理这些数据,就需要把这些数据整合成一个大型知识库,并将其作为智慧城市的基础资源。
事实上,现有的智慧城市建设存在很多问题。例如各个部门之间的数据共享问题,虽然想要实现数据集中采集、多处共享,但就目前来说还没有一座城市能够真正做到这一点。例如:病人在A医院的检查化验单却无法在B医院使用,理论上来说,化验结果是属于患者的个人数据,无论患者在哪个医院就诊都可以使用,现实中却并不能做到。另外,政府间的数据“烟囱”现象依然严重,即便有顶层设计、总体设计,但大部分还是各自为政,系统间的协调共享不足。
发明内容
针对国内智慧城市建设的现状,因而提出一种基于知识图谱的智慧城市数据构建方法。城市数据的核心是关于自然人的数据,像智慧教育、智慧医疗等板块都是围绕自然人的数据展开的,因此智慧城市知识图谱建设的核心问题是构建以城市自然人为核心的本体,同时构建民生、教育、医疗、交通、维稳、社保等领域的子本体,形成多领域多模态的知识图谱结构,实现智慧城市知识图谱的应用生态。
本发明的技术方案为:一种基于知识图谱的智慧城市数据构建方法,包括如下步骤:
步骤1、获取自然人在城市生活中相关联的N个领域,包括教育、医疗、交通;
步骤2、针对上述N个领域,分别构建该领域下的领域子本体人;
步骤3、对由N个领域知识图谱相叠加,实体消歧以及去重,从而构成一个完整的领域知识图谱,所述实体消歧分为:基于聚类的实体消歧系统和基于实体链接的实体消歧。
有益效果:
①本发明的新型智慧城市知识图谱的本体是围绕城市自然人设计的,紧密围绕以人为本的管理理念,让智慧城市更好的为人的服务展开。目前大多数的大数据中心并未形成以人为核心的数据框架,而是将自然人数据、法人数据、地理数据以及经济运行数据等都放在一个层面上。
②数据不会与具体业务出现交叉现象,获取城市数据后,首先会对其进行属性分类以及关系分析,再将其提到更高的知识库,从而做到真正的数据共享。
③图数据库技术和语义网描述体系、标准和工具的结合,有利于提升计算机系统对大规模知识库的的存储以及检索计算的速度,以及便于人工智能模型的有机结合,特别在智能客服以及问答系统等方面的应用。
附图说明
图1:知识图谱的数据人的概念示意图;
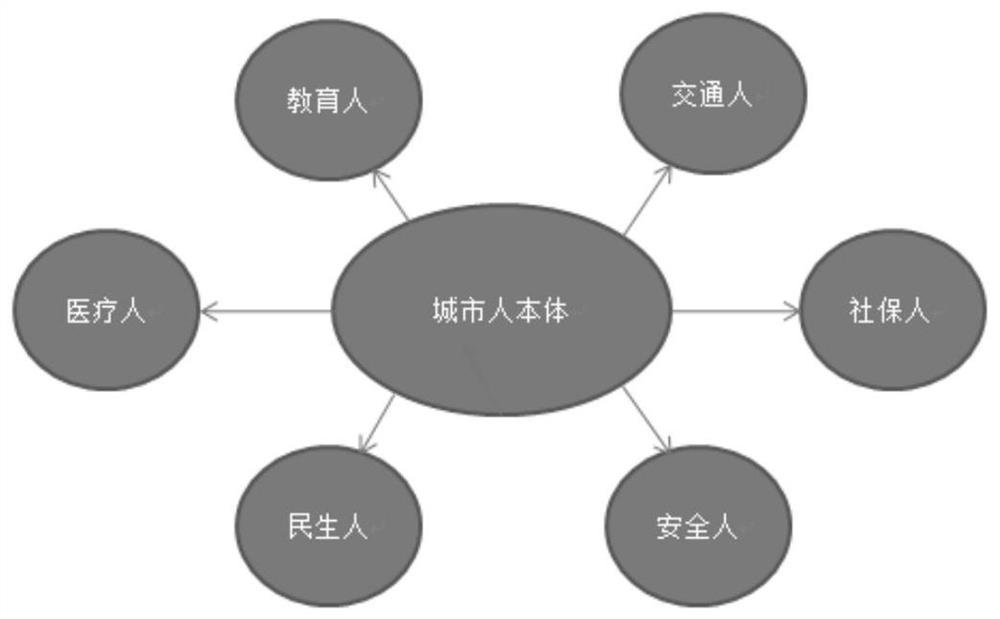
图2:智慧城市知识图谱本体示意图;
图3:智慧城市知识图谱模型示意图;
图4:类的建立示意图;
图5:对象及对象属性设置示意图;
图6:数据及数据属性设置示意图;
图7:本体图像示意图;
图8:医疗人本体设计;
图9:就诊轨迹本体设计;
图10:医疗公益本体设计;
图11:医疗保险本体设计;
图12:身体素质本体设计;
图13:医疗人的构建过程;
图14:导入数据库效果图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅为本发明的一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域的普通技术人员在不付出创造性劳动的前提下所获得的所有其他实施例,都属于本发明的保护范围。
本发明提出一种基于知识图谱的智慧城市数据构建方法,针对目前的智慧城市结构,从具体的事物中抽象出来,重新组合数据,形成新的数据结构S,这种新型的数据结构可以从知识图谱的三元组(实体、属性、关系)来表示以及存储,即S={E,A,R}。
为此,提出新型知识图谱的数据人的概念(如图1所示),一个人出生就像一个树苗一样,包含有出生地、父母等基础信息,随着年龄的增大,树苗也枝繁叶茂,从而有就学、任职、配偶、子女等旁枝。一个人就是一棵树,一个城市的人就像一片森林一样。而城市的道路交通、医院、学校、以及企业等作为一个城市的基础信息,如同一片森林的土地一样,维持着城市的正常运行。而城市的管理、服务、维稳等功能则相当于森林的天空,时刻监管城市的各项运动,为市民创造出安全、和谐、民主、便利的城市生活。
知识图谱对知识数据的描述和定义称之为本体。本体是重要的知识库,知识图谱的类型包括对象的类型、属性的类型和关系的类型。具体可以表示为:O
由于目前的知识库并没有按照领域的数据划分,唯一的根类型就是实体,因而无法表达文本、视频、图片等数据的关联,因此领域知识图谱的本体的对象根类型B
如图2所示为智慧城市知识图谱本体示意图,若自然人在城市生活中与N个领域相关联(如:教育、医疗、交通等),那么就可以由N个领域知识图谱相叠加,从而构成一个完整的领域知识图谱。针对城市自然人的本体,提出构建子本体,再将子本体相互叠加,形成完整主本体的思路。
例如,针对城市居民的医疗情况设计一套医疗人本体MED(O
根据本发明的一个实施例,提出一种基于知识图谱的智慧城市数据构建方法,包括如下步骤:
步骤1、获取自然人在城市生活中相关联的N个领域,包括教育、医疗、交通;
步骤2、针对上述N个领域,分别构建该领域下的领域子本体人;
步骤3、对由N个领域知识图谱相叠加,消歧以及去重,从而构成一个完整的领域知识图谱。
所述步骤2中,构建该领域下的领域子本体人具体包括:
使用protege构建本体
步骤2.1:修改自定义的IRI
将Active Ontology界面的Ontology IR修改为预定的IR:
步骤2.2:创建对应的类
在Entities界面下的Classes的Things中新建子本体中对应的类。如针对医疗领域新建医疗保险、医疗公益、就诊轨迹、身体素质,并针对每个类建立小的类。并针对每个类设置限制条件。如图4所示。
步骤2.3:设置对象属性,以及每个对象属性的描述
在Entities的Object properties中设置对象属性以及每个对象属性的描述。如Inverse of为逆的关系,Domains\Ranges则表示属于\拥有的关系,如图5所示,为对象及对象属性设置示意图
步骤2.4:设置数据属性以及每个数据属性的描述
在Entities的Data properties中设置数据属性以及每个数据属性的描述。在Data property hierarchy中设置数据名,在Description_achiem里添加数据属性。如图6所示为数据及数据属性设置示意图;
步骤2.5:显示本体图像
在Window模块中找到Tabs,勾选OntoGraf,调出界面后即可显示出本体图像。如图7为本体图像示意图。
所述步骤3中,对由N个领域知识图谱相叠加,消歧以及去重具体包括,图谱叠加:
两个完整图谱的融合本质上就是不同领域实体词之间的实体对齐,从而形成语义上的链接。基于字符串相似的实体对齐大致分为两种,一种是与实体相关的语义字符串相似度,如定义,属性。第二种就是基于知识表示的实体对齐方法。
RDF-AI实现了一个由预处理、匹配、融合、互连和后处理模块组成的对齐框架,因此提出一个基于属性的实体对匹配算法:基于序列对齐的模糊字符串匹配算法和词义相似度算法。对此我们可以用基于WordNet的同义词比较算法来实现,具体表示如下:
feature(SW)={{W
{W
{W
{W
其中:
W
SW
NO(SW):W意义的顺序,对于第一个SW意义,其顺序=1,第二个SW意义,其顺序=2…;
IDF(W
K
K
K
Q
K为词i,j的权重,W
通过上述方法计算属性匹配相似度,得到图谱中所有可能对齐的属性对,再通过属性对相似度求和得到实体相似度。最终实体相似度最高者被认为是一个实体。
还包括实体消歧与去重:
针对实体可能存在同一实体在文本中会有不同的指称以及相同的实体指称在不同的上下文中可以指不同的实体。按照目标实体列表是否给出,实体消歧可以分为:基于聚类的实体消歧方法和基于实体链接的实体消歧方法。
1、基于聚类的实体消歧方法
在未给定目标实体的情况下,对于给定待消歧的实体,以聚类方式实现消歧的系统按以下步骤进行:
1)对每一个实体指称项O
2)计算实体指称项之间的相似度
2.1基于表层特征的实体指称项相似度计算
特征表示:将实体指称项表示为Term向量形式,其中每个Term的权重通常采用TF-IDF算法进行计算。
相似度计算:采用Cosine计算相似度
2.2基于社会化网络的实体指称项相似度计算
基于社会化网络的实体指称项相似度通常使用基于图的算法,能够充分利用社会化关系的传递性,从而考虑隐藏的关系知识,更能够为准确的实体指称项相似度计算结果。过程如下:
表示成社会化关系图G=(V,E),其中实体指称项和实体均被表示为节点,节点之间的边表示它们之间的社会化关系。
相似度计算:采用图算法中的随机游走算法来计算。
2、实体链接方法
给定一个指称项m及其链接实体候选E=e
对于计算Score(e,m)可以用向量空间模型、主题模型等等。
1)向量空间模型
相似度计算依据:实体指称项上下文与目标实体上下文特征的共现信息来确定过程:实体概念和实体指称项都被表示为上下文中Term组成的向量。基于Term向量表示,向量空间模型通过计算两个向量之间的相似度对实体概念和指称项之间的一致性进行打分。
2)主题一致模型
实体指称项的候选实体概念与指称项上下文中的其他实体概念的一致性程度:
上下文实体的重要程度:与主题的相关程度。传统方法使用实体与文本内其他实体的语义关联的平均值作为重要程度的打分。
其中,0是实体指称项上下文所有实体的结合,sr(e,e
计算一致性:将目标实体与上下文中其他实体的加权语义关联平均作为一致性打分。
其中,o是实体指称项,w(e,o)是实体e的权重,而sr(e,e
根据本发明的一个实施例,在城市医疗领域,具体设计如下:
在城市医疗领域,城市自然人的子本体为医疗人本体MED(O
如图9所示,医疗人P
如图10所示,医疗人P
如图11所示,在市民城市生活中,每个市民都会有医保问题,医疗保险又分为商业医疗保险和社会医疗保险,这些医疗保险C与医疗人P
如图12所示,医疗人P
如图13所示,医疗人本体设计完成后,对其进行构建。首先,定义实体,新增个人、组织、证件、医院、科室、病例、报告等实体对象。其次,定义属性,为各个实体对象定义属性。个人的属性包括姓名、身份证号码、户籍地址、居住地地址、既往病史等等。组织的属性包括名称、类型、组织机构代码、税务登记证号、地址、法定代表人等。再定义
关系及事件,为实体对象间添加关系和事件。个人之间添加亲属、同医院、同症状等关系,个人与组织之间添加属于关系,个人与病例、报告之间添加拥有关系等。实体、属性、关系及事件定义完后,通过抽取工具对现有的抽取工具进性抽取,并导入知识库,再经过实体对齐和属性填充后,最终形成一套完整的医疗人领域知识图谱。
医疗领域知识图谱构建完成后,同理构建教育、交通、民生、安全、社保等5个领域的子本体,再经过动态本体技术将子本体融合为一个主本体。动态本体允许对任何不再使用的对象、属性和关系进行移除,并且可以根据需求添加新的对象、属性和关系。动态本体的具体思路如下:
1.通过一个对象类型编辑器来生成数据类型和数据类型的特征。
2.通过一个属性类型编辑器生产属性类型并定义该属性类型的特征。
3.每个属性类型都有一个解析器,该解析器将一些输入的数据跟本体做一个映射,并且把输入数据添加到数据库中。
构建完单领域知识图谱,并通过图谱叠加的方式形成一个面向城市的多领域的知识图谱。将知识图谱中的实体-属性名称-属性数值导入mysql数据库中,如图14所示。
再通过根据query,通过NER识别出实体,再根据实体名称去查询,获取多条记录。
示例如下:
1.Query=高等数学出版社是哪家?
2.NER识别:高等数学
3.sql=“select*from nlpcc_qa where entity=‘高等数学’”
结果如下:
高等数学出版社武汉大学出版社
高等数学书名高等数学一(微积分)
根据query,我们的答案是“武汉大学出版社”,则解决方案就是:
Query和出版社
Query和书名
上述对应的
通过以上内容,已经满足QA检索的服务。总结如下:
1.query=xxxxxx
2.query->调用NER模型,返回多个元组列表
3.多个元组列表–>依次通过文本相似度模型进行打分,提取相关度最高的三元组为符合条件的内容,然后抽取predicate。
4.根据实体名称subject+关系predicate->知识库检索答案
如上,即为一个图数据库技术和语义网描述体系、标准和工具的结合的实例,有利于提高计算机系统对大型知识库的检索以及存储速度。而在智能客服和语义搜索上,同样可以识别出实体后,找到对应的三元组,返回相应的答案,即可完成智能回答。
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,且应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
- 一种基于知识图谱的智慧城市数据构建方法
- 基于知识图谱的数据保存方法及知识图谱的构建方法