一种电力信号模型训练文件的合并方法
文献发布时间:2023-06-19 10:41:48
技术领域
本发明属于中文训练模型训练方法技术领域,具体涉及一种电力信号模型训练文件的合并方法。
背景技术
Tesseract文字识别引擎自带的中文训练模型识别率较低,通过重新训练用户常用文字提高文字识别率是用户的常用做法。由于训练需要大量调整图片中文字的位置、文字框大小,为文字训练带来极大的工作量,若不对训练文件进行合并处理,处理时间长,识别效率低。
发明内容
本发明要解决的技术问题是:提供一种电力信号模型训练文件的合并方法,以解决现有技术中存在的问题。
本发明采取的技术方案为:一种电力信号模型训练文件的合并方法,该方法包括以下步骤:
1)选择已进行人工标记且已生成.box文本文件和后缀为.tif的图片文件;
2)设置各个文件的训练参数,包括训练用语言、页面模式参数,默认为中文训练语言;
3)根据选择的文件名称和需生成的模型名称,对后缀为tif的图片文件和box文件自动进行命名,形成符合规范的训练文件,后缀为.tif的图片文件规范命名如下:
对应的后缀为.box的文本文件规范命名如下:
4)根据所有后缀为.tif的图片文件名称,将名称第一个“.”和第二个“.”间的名称作为字体名称,每个字体为一行,按以下格式写入文件名为font_properties的文本文件中。
font 0 0 0 0 0
5)调用tesseract命令为每一个后缀为.tif的文件生成一个后缀为.tr的文本文件,命令如下:
tesseract power.font.exp0.tif power.font.exp0–psm 6nobatch box.train
6)将所有后缀为.box的文本文件名称组合成按空格分隔的字符串,作为unicharset_extractor命令的参数,调用并执行unicharset_extractor命令;将所有后缀为.tr的文本文件名称组合成按空格分隔的字符串,作为shapeclustering、mftraining、cntraing命令的参数,调用并执行shapeclustering、mftraining、cntraing命令;
7)最后调用tessract的combine_tessdata命令,生成.traineddata文件,即为最终合并的文字模型。
步骤1)中.box文本文件和后缀为.tif的图片文件的生成方法,包括以下步骤:
1)读取txt或excel文件;
2)设置训练文字的字体、大小、模型名称的参数;
3)按行读取选择的txt或excel文件,获取文字总行数,记为num_lines,以及这些行中字数最多的行的字数,记为max_length;
4)根据设置的字符间距(gap)、行间距(linespacing)、页面边距(padding)、图片最大宽度、单个文字宽度(width)、单个文字高度(height),计算生成文字图片的宽度及高度;
5)若计算的图片宽度大于设置的图片最大宽度,则以图片最长宽度作为待生成图片的宽度,根据字符间距(gap)、行间距(linespacing)、页面边距(padding)重新计算图片高度;
6)根据步骤5)计算的图片大小,记为imgsize,调用Qt的QImage类生成全白的图片,保存为到一个后缀为.tif的图片文件;
7)在全白的图片上按顺序绘制单个文字;
8)根据步骤7)中记录的每个字符位置及矩形长宽数据,分别以从上至下、从下至上、从左至右、从右至左四个方向扫描该矩形框内的图片的像素值;
9)将步骤8)的文字最小外接矩形的坐标[(x,y),(end_x,endy)]位置转换为tesseract训练的文字坐标系[(t_x,t_y),(t_end_x,t_endy)],转换公式如下:
t_x=x
t_y=height_image–y-(endy-y)
t_endx=x+width_image
t_endy=height_image–y;
10)将每个文字按步骤9)进行坐标转换计算,并将每个文字的数据按以下格式写入并保存到一个后缀为.box的文本文件中,每个文字数据占一行:
文字t_x t_y t_endx t_endy。
本发明的有益效果:与现有技术相比,本发明通过多模型的合并方法,将实际应用中的人工标记的文字图片以及本发明生成的文字图片进行合并,将识别错误文字通过实际应用中的人工标记数据进行调整,在减少训练工作量的同时提高了文字识别的准确度。
附图说明
图1为模型训练方法流程图;
图2为合并方法流程图;
图3为坐标系转换示意图。
具体实施方式
下面结合具体的附图和实施例对本发明进行进一步介绍。
实施例1:如图1所示,一种高效的模型训练方法,包括以下步骤:
1)将电力调度主站系统中的各站点名称、状态名称等形成txt格式或execl格式的文件,读取txt或excel文件;由于中文文字数量庞大,本步骤将实际应用中需识别的文字进行整理,一方面减小了需识别的文字数量,另一方面减少了生成模型的大小,可提高文字的识别速度;
2)设置训练文字的字体、大小、模型名称的参数,提高文字识别的准确度;
3)按行读取选择的txt或excel文件,获取文字总行数(记为num_lines)以及这些行中字数最多的行的字数(记为max_length);本步骤主要为下述步骤计算训练图片的生成大小获取初始数据;
4)根据设置的字符间距(gap)、行间距(linespacing)、页面边距(padding)、图片最大宽度、单个文字宽度(width)、单个文字高度(height),计算生成文字图片的宽度及高度,计算公式如下:
图片宽度(width_image)=padding*2+max_length*(gap+width)
图片高度(height_image)=padding*2+num_lines*(linespacing+height)
5)若计算的图片宽度大于设置的图片最大宽度,则以图片最长宽度作为待生成图片的宽度,根据字符间距(gap)、行间距(linespacing)、页面边距(padding)重新计算图片高度。计算流程如下:
a)计算图片一行可容纳的文字数量max_words_num
words_num=(width_image–padding*2)/(gap+width)
max_word_length取大于或等于words_num的最小整数
b)计算文字行数及图片高度
lines_word=文字总数量/max_word_length
文字行数(num_lines)取大于或等于lines_word的最小整数(向上取整)
图片高度=padding*2+num_lines*(linespacing+height)
6)根据步骤5)计算的图片大小(记为imgsize),调用Qt(跨平台C++图形用户界面应用程序开发框架)的QImage类生成全白的图片,调用代码如下:
QImage img(imgsize,QImage::Format_RGB888);
img.fill(QColor(255,255,255));
7)在全白的图片上按顺序绘制单个文字。绘制步骤如下:
a)设置第一个文字位置(横坐标为startx,纵坐标为starty),位置初始值如下:
startx=padding;starty=padding;
b)在以坐标(startx,starty)为起点、单个文字宽度(width)为矩形宽度、单个文字高度(height)为矩形高度的矩形内居中绘制第一个文字。
c)计算下一个文字的startx和starty,取值如下:
startx=startx+width+gap
starty=padding
若(startx+页面边距)>图片宽度,则:
starty=starty+已绘制的文字行数*(height+linespacing)
startx=padding
d)记录并保存,每个字符的startx,starty,width,height重复a-c步骤,直至完全绘制完图片。
8)根据步骤7)中记录的每个字符位置及矩形长宽数据,分别以从上至下、从下至上、从左至右、从右至左四个方向扫描该矩形框内的图片的像素值,本步骤通过四个方向的扫描计算文字的外接矩形,较从上至下、左至右两个方向扫描文字计算外接矩形的方法速度更快,计算速度得到提升;
a)以行为单位从上至下扫描文字矩形的像素,直至扫描到整行像素存在不为白色的像素,将该行行数记为y。
b)以列为单位从左至右扫描文字矩形的像素,直至扫描到整列像素存在不为白色的像素,将该列列数记为y。
c)以行为单位从下至上扫描文字矩形的像素,直至扫描到整行像素存在不为白色的像素,将该行行数记为end_y。
d)以列为单位从右至左扫描文字矩形的像素,直至扫描到整列像素存在不为白色的像素,将该列列数记为end_x。
e)根据a-d)计算的数据作为该文字的最小外接矩形,矩形左上角顶点坐标为(x,y),右下角顶点坐标为(end_x,endy);
9)由于QImage图像坐标系与Tesseract训练用的文字坐标系不一致(见下图),且tesseract需要文字最小外接矩形的左下角和右上角顶点坐标作为训练数据,因此将步骤8)的文字最小外接矩形的坐标[(x,y),(end_x,endy)]位置转换为tesseract训练的文字坐标系[(t_x,t_y),(t_end_x,t_endy)],如图3所示,转换公式如下:
t_x=x
t_y=height_image–y-(endy-y)
t_endx=x+width_image
t_endy=height_image–y
10)将每个文字按9)进行计算,并将每个文字的数据按以下格式写入并保存到一个后缀为.box的文本文件中,每个文字数据占一行:
文字t_x t_y t_endx t_endy
本步骤生成的.box文件为tesseract训练中必要的字符位置文件,通过训练工具自动处理生成,较传统需手动调整文字外接矩形位置的方法更为便捷;
11)根据设置参数,如训练语言、分页模式等,使用tesseract命令生成后缀为.tr的文本文件,命令如下:
tesseract power.font.exp0.tif power.font.exp0–psm 6nobatch box.train
本步骤生成的.tr文件为tesseract训练中必要的字符特征文件,通过工具自动调用tesseract命令生成,较传统需要手动调用命令生成的方法更便捷;
12)读取人工标记文件夹内所有后缀为.tif、.box、.tr文件,同时检测文件夹中文件名为font_properties的文本文件是否存在,若不存在,则根据所有后缀为.tif的图片文件名称,将名称第一个“.”和第二个“.”间的名称作为字体名称,过滤重复的字体名称,将每个字体作为一行,按以下格式写入文件名为font_properties的文本文件中。格式如下:
font 0 0 0 0 0
例如后缀为.tif的图片文件名称为power.userfont.exp0.tif,则写入font_properties文件的内容为:
userfont 0 0 0 0 0
生成的font_properties文件为tesseract训练中必要的字体文件,较传统方法中需人工依次查找不同tif的文件名、手动创建font_properties文件、人工输入字体的方法更快速便捷;
13)依次执行tesseract的unicharset_extractor、shapeclustering、mftraining、cntraing训练命令,生成后缀为.traineddata的文件,该文件即为文字模型文件;通过工具自动按顺序调用执行上述命令,较传统方法中人工依次输入上述命令并执行的方法更快速便捷;
14)完成训练后,训练工具自动调用tesseract命令识别7)步骤生成的图片,并将识别结果和录入的文字进行对比,提示识别错误文字、文字召回率和准确率;通过训练工具自动检测文字的召回率和准确率,较传统方法中需要人工查找和计算错误文字的方法更加快速便捷;
15)若用户想继续提高文字识别率,可继续将含有错误文字的实际应用图片利用图片工具转换为后缀为.tif的图片文件,并使用标记工具人工标记生成.box文本文件,加入到人工标记文件夹,重新进行训练。
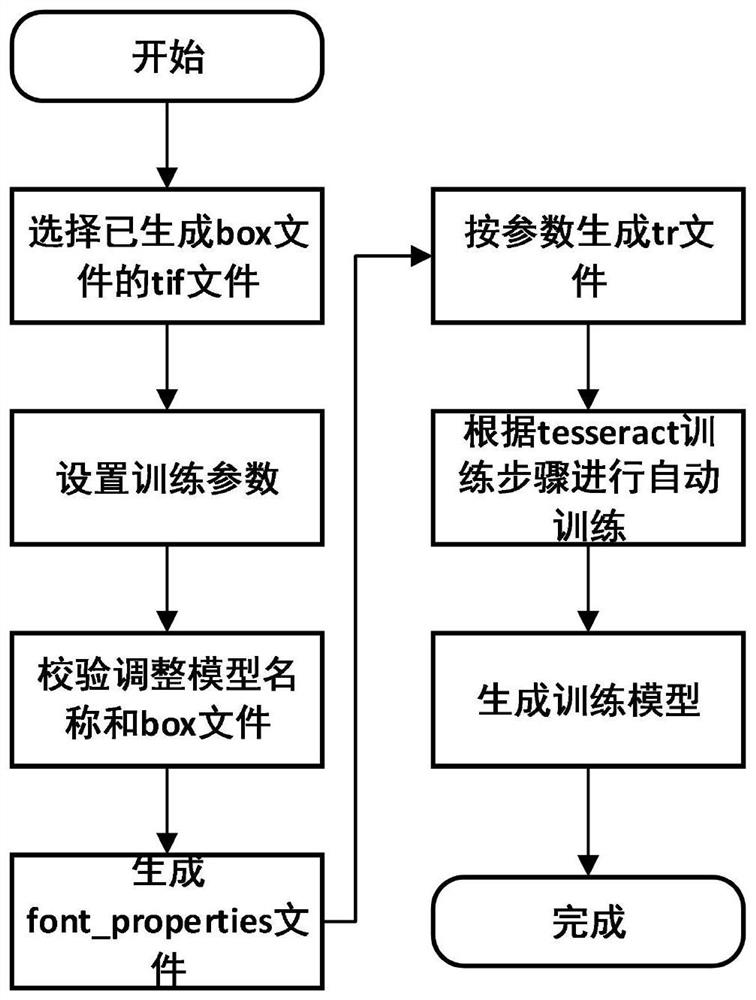
实施例2:如图2所示,一种电力信号模型训练文件的合并方法,该方法包括以下步骤:
1)选择已进行人工标记且已生成.box文本文件和后缀为.tif的图片文件,可以是实施例1中步骤1)-10)生成的.box文本文件和后缀为.tif的图片文件,也可以是通过其他方法或工具调整的;可选择不同路径下的.tif格式的图片文件,较传统方法需人工将合并文件复制到同一路径下的方法更为便捷;
2)设置各个文件的训练参数,包括训练用语言、页面模式参数,默认为中文训练语言;可以针对每个选择的文件设置不同参数,较传统方法需要对每个文件单独录入参数和执行命令的方法更为直观便捷;
3)根据选择的文件名称和需生成的模型名称,对后缀为tif的图片文件和box文件自动进行命名,形成符合规范的训练文件,后缀为.tif的图片文件规范命名如下:
对应的后缀为.box的文本文件规范命名如下:
通过合并工具自动对.tif格式文件和.box格式文件进行重命名,较传统方法需要人工进行重命名并拷贝到同一个文件夹下的操作更加快速便捷;
4)根据所有后缀为.tif的图片文件名称,将名称第一个“.”和第二个“.”间的名称作为字体名称,每个字体为一行,按以下格式写入文件名为font_properties的文本文件中;
font 0 0 0 0 0
font_properties为tesseract训练模型时需要的必要字体文件,本发明通过合并工具自动获取每个.tif的字体名称并写入font_properties文件,较传统方法需要人为判断字体、人为创建font_properties文件、并将字体写入文件中的操作更便捷,且不易出错;
5)调用tesseract命令为每一个后缀为.tif的文件生成一个后缀为.tr的文本文件,命令如下:
tesseract power.font.exp0.tif power.font.exp0–psm 6nobatch box.train
.tr格式文件为tesseract训练模型是需要的必要字符特征文件,本发明通过合并工具自动根据文件数量调用命令执行,较传统方法需要人工根据文件数量文件名称依次调用的操作方法更快速便捷;
6)将所有后缀为.box的文本文件名称组合成按空格分隔的字符串,作为unicharset_extractor命令的参数,调用并执行unicharset_extractor命令;将所有后缀为.tr的文本文件名称组合成按空格分隔的字符串,作为shapeclustering、mftraining、cntraing命令的参数,调用并执行shapeclustering、mftraining、cntraing命令;
通过合并工具自动组合成执行命令语句,并自动调用训练命令,较传统方法需要人工依次编写检查命令、执行命令的操作方法更快速便捷;
7)最后调用tessract的combine_tessdata命令,生成.traineddata文件,即为最终合并的文字模型。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内,因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 一种电力信号模型训练文件的合并方法
- 一种高效的电力信号描述模型训练方法