一种基于深度强化学习的时空充电调度方法
文献发布时间:2023-06-19 10:55:46
技术领域
本发明涉及利用无线充电技术延长无线可充电传感器网络生存周期技术领域,具体的涉及一种无线可充电传感网中基于深度强化学习的时空充电调度方法。
背景技术
无线传感网(Wireless sensor network,WSN)由三大部分构成,包括传感器节点、传感网络和基站。作为实现物联网的重要基础设施,近年来发展迅速,并被广泛应用于电气自动化、农业、建筑物状态监控等领域。传感器节点电池能量限制使网络生存时间有限,而一些应用场景中希望WSN无期限工作。随着无线充电技术的日趋成熟,无线可充电传感网(Wireless rechargeable sensor network,WRSN)应运而生,有效改善了网络的生存时间。
无线可充电传感网在WSN的基础上增加了可移动充电装置(Mobile chargingunit, MC),通过充电算法的调度,MC自行移动到传感器节点位置为其进行无线充电。WRSN相较于WSN大大提高了网络的生存时间,因此需要考虑在WRSN中如何有效的调度 MC为节点补充能量。
Chao Sha等学者于2019年在IEEE Transactions on Vehicular Technology发表的“Research on Cost-Balanced Mobile Energy Replenishment Strategy forWireless Rechargeable Sensor Networks”提出了一种成本均衡的移动能量补充策略。首先,将节点按照剩余生命周期进行分组,保证在每个时隙中只对剩余能量较低的节点进行再充电。然后,以移动距离和能量消耗为约束条件,均衡多基站间的能量消耗,得到最优轨迹分配方案。
Jianxin Ma等学者于2019年在International Conference on ArtificialIntelligence for Communications and Networks发表的“Path Optimization withMachine-Learning Based Prediction for Wireless Sensor Networks”提出了一种基于机器学习的能量消耗预测方法 (ML-ECP),该方法利用机器学习预测无线传感器网络的能量消耗率。在此基础上,将传感器节点划分为多个簇,得到移动节点的最优轨迹。移动节点在网络中周期性地采集信息和充电时提高了传感器节点充电和数据采集的能量效率。
从出版的文献中,尚无这样的研究工作来利用深度强化学习技术来解决无线可充电传感网中对移动充电器调度策略的优化。现有无线了充电传感网中的能量补充方法大多只考虑对MC移动路径和节点充电序列的优化,而忽略了对节点充电时间的优化,只考虑了充电调度的空间维度,没有考虑到时间维度,因此对于充电调度方案还有可改进之处。为了提高网络生成时间,提高充电效率,本发明结合深度强化学习技术对时间和空间进行协同优化。
深度强化学习近期来发展迅速,并在机器学习领域得到了很多的关注。传统的强化学习局限于动作空间和样本空间较小,且一般是离散的情境下。然而比较复杂的、更加接近实际情况的任务则往往有着很大的状态空间和连续的动作空间。实现端到端的控制也是要求能处理高维数据,如图像、声音等的数据输入。而现有的深度学习,刚好可以应对高维的输入,将两者结合,使智能体同时拥有深度学习的理解能力和强化学习的决策能力。深度强化学习可以解决有着高维或连续动作空间的情境。它包含一个策略网络来生成动作,一个价值网络来评判动作的好坏,在动作输出方面采用一个网络来拟合策略函数,直接输出动作,可以应对连续动作的输出及大的动作空间。
为了解决WRSN中传感器节点的能量补充问题,本发明通过引入深度强化学习对其问题进行解决。传感器节点可以根据自身能耗预测剩余工作时间,在电量低于最小能量阈值时,节点向基站B发送请求,MC根据基于深度强化学习的时空充电算法规划充电序列和每个节点的充电时间。
发明内容
针对现有技术存在的上述问题,本发明提供了一种基于深度强化学习的时空充电调度方法,本发明的时空充电方案(Spatio-temporal charging scheme based on deepreinforcement learning,简称SCSDRL)的深度强化学习调度算法,在考虑路径成本最小的基础上特别考虑了充电时间对充电效果的影响,基于时间和空间两个维度对充电序列进行协同优化,通过对充电时间的动态调整,避免下一节点因等待时间多长而饥饿死亡,从而提高整个无线可充电传感网的生存时间。
为实现上述技术目的,达到上述技术效果,本发明是通过以下技术方案实现:
一种基于深度强化学习的时空充电调度方法,包括以下步骤:
S1:构建无线可充电传感器网络模型,使得MC(移动充电装置)是具有自主移动能力和计算能力的独立设备,可自行规划充电序列和在移动过程中避障,由基站为MC 补充能量;
S2:以最小化充电成本和减少节点死亡率为目标,设计基于深度强化学习的时空充电方案(SCSDRL);
S3:使用SCSDRL算法生成充电序列后,根据MC当前位置坐标(x
S4:完成一轮充电调度规划后,MC前往基站补充为自身补充能量,为下次调度做准备。
进一步的,所述S1无线可充电传感器网络模型的构建是在规划好的有障碍物的目标区域内按需求部署一定数量的传感器节点,X
C
整个无线可充电传感器网络部署在二维有障碍物的目标区域内,无线可充电传感器网络由三个部分组成,在一个二维平面区域内布置有一个基站(B),一个负责为节点充电的可移动充电装置(MC)和若干用来收集和传输数据的传感器节点,每个传感器节点装有相同容量的电池,传感器节点负责收集和传输数据并将数据通过多跳的方式转发到基站,由基站负责存储数据,且基站B通过远距离通信(如4G/5G通信技术)与 MC传输数据以及为MC补充能量,MC从基站出发,根据节点的充电请求依次遍历传感器节点进行无线充电,并在一轮充电完成后返回基站为下次调度补充能量。
进一步的,所述S2时空充电方案是:每个传感器节点可根据能耗速率计算自身剩余能量和平均剩余存活时间;当传感器节点剩余能量低于最小能量阈值时向基站发送充电请求,由MC首先根据充电请求中的节点信息进行充电序列的规划,再由规划的充电序列判断序列中的每个节点的平均剩余生存时间,通过后一节点的剩余生存时间动态调整前一节点的充电时间。
进一步的,所述S2的传感器节点的能耗模型为:
其中f
传感器节点按照剩余能量分为两种状态,当剩余能量小于0时节点被标记死亡:
节点计算出当前剩余能量后,当
其中λ(0<λ≤1)为充电参数,决定MC是为节点i进行完全或部分充电。
进一步的,所述S2的MC的剩余能量计算公式为:
上式中L
进一步的,所述S3中的SCSDRL算法具体步骤为:
首先根据t时刻待充电节点的请求集合D(t)=(S
在SCSDRL中,智能体是MC,负责做出充电决策;系统的状态空间包括基站和所有传感器节点的位置和待充电节点的能量需求,表示为S=S
策略由表达式a=π(s)表示,是从输入状态S到输出动作a的映射,SCSDRL的目标是找出一种最优策略来规划MC的充电序列;
在SCSDRL中,为了提高WRSN的充电效率,包括通过优化MC的充电路径来避免传感器故障和降低充电成本,SCSDRL以MC的总行程长度和死节点数作为奖励信号,把奖励定义为:
状态的具体更新过程如下:假设MC在0时刻位于基站B处;在每个步骤中,MC从传感器节点或基站B中选择下一步要访问的节点;访问传感器节点i后,更新传感器节点的需求和MC的剩余能量如下:
其次,SCSDRL中的网络模型为两个神经网络:其一是带有参数θ
接着,根据t时刻待充电节点的请求集合D(t)=(S
同时,由于随着充电时间的增加,电池接收的能量不是线性增加的,充电效率具有边际效应;若所有请求节点都进行完全充电,将影响充电效率;故在生成MC移动距离最短的充电序列后,判断为节点进行完全充电或部分充电,充电时间划分和电池获得能量计算如下:
在充电序列的基础上动态调整每个节点的充电时长;
最后,基于策略梯度,使用预期奖励的梯度对策略参数的估计来迭代地改进策略使得奖励最大化,从而生成近似最优解。
进一步的,所述S3中用于规划路径的Q-learning算法具体步骤为:
首先将无线可充电传感网区域转化为二维网格地图,其中基站、传感器节点、MC的位置均已知;将路径规划问题抽象为马尔科夫决策过程,由元组{S
根据Q值进行学习,采用时间差分方法进行Q-table的更新,更新过程如下:
Q(s,a)←Q(s,a)+α[r+γmax
通过Q-learning算法为MC规划出避开障碍物到达目标节点的路径,并自行避开障碍物移动到节点位置为其进行一对一无线充电。
本发明的有益效果是:
本发明通过对无线可充电传感网中传感器节点充电序列和充电时间的优化,尤其是使用深度强化学习方法同时从时间和空间两个维度对MC的充电规划进行协同优化,在减少MC在移动过程中能量损耗的同时,动态调整节点的充电时间,避免下一节点因等待时间过长而失效死亡。该方法可以有效的适应节点能耗不平衡的无线可充电传感器网络,提高整个无线可充电传感网的生存时间,避免因节点死亡带来的不良影响。
附图说明
图1是无线可充电传感网络模型图;
图2是充电曲线示意图;
图3是SCSDRL网络结构图;
图4是避障路径规划图。
图5是基于深度强化学习的时空充电调度方法原理图。
具体实施方式
为了更详细的描述本发明和便于本领域人员的理解,下面结合附图以及实施例对本发明做进一步的描述,本部分的实施例用于解释本发明,便于理解的目的,不以此来限制本发明。
实施例1
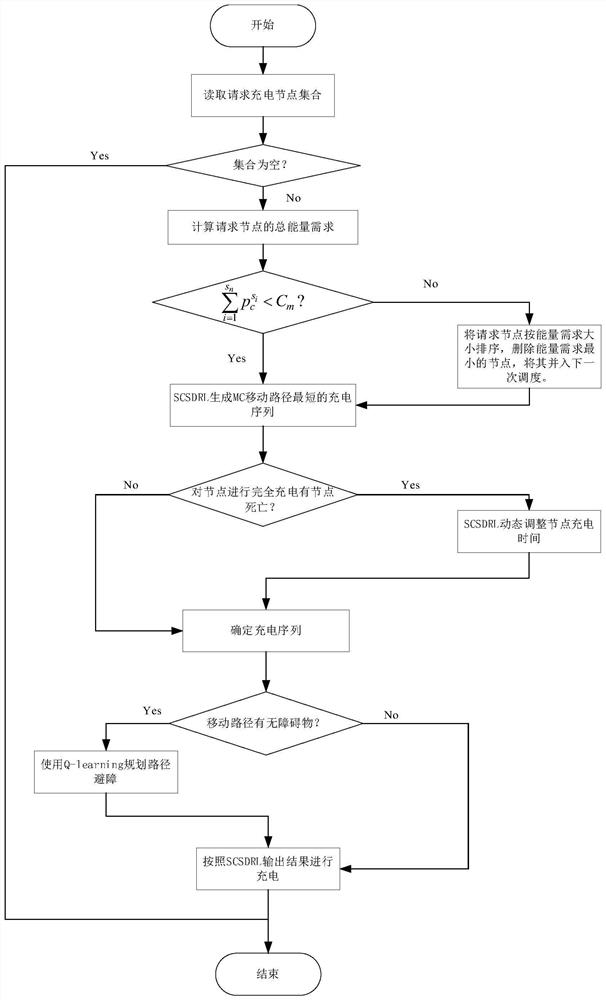
如图1-5所示,无线可充电传感网中一种基于深度强化学习的时空充电调度方法,包括如下步骤:
S1:建立无线可充电传感器网络模型:在规划好的有障碍物的目标区域内按需求部署一定数量的传感器节点,X
整个无线可充电传感器网络部署在二维有障碍物的目标区域内,传感器节点负责收集和传输数据并将数据通过多跳的方式转发到基站,由基站负责存储数据。基站B 通过远距离通信(如4G/5G通信技术)与MC传输数据,MC是具有自主移动能力和计算能力的独立设备,可自行规划充电序列和在移动过程中避障,由基站为MC补充能量。
S2:以最小化充电成本和减少节点死亡率为目标,设计一种基于深度强化学习的时空充电方案(Spatio-temporal charging scheme based on deep reinforcementlearning,简称SCSDRL),该方案的工作过程是:每个传感器节点可根据能耗速率计算自身剩余能量和平均剩余存活时间;当传感器节点剩余能量低于最小能量阈值时向基站发送充电请求,由MC首先根据充电请求中的节点信息进行充电序列的规划,再由规划的充电序列判断序列中的每个节点的平均剩余生存时间,通过后一节点的剩余生存时间动态调整前一节点的充电时间。
如图2所示,随着充电时间的增加,电池接收的能量不是线性增加的,充电效率具有边际效应。若所有请求节点都进行完全充电,将影响充电效率。故在生成MC移动距离最短的充电序列后,判断为节点进行完全充电或部分充电。
S3:使用SCSDRL算法生成充电序列后,根据MC当前位置坐标(x
具体地,传感器节点的能耗模型为:
其中f
传感器节点按照剩余能量分为两种状态,当剩余能量小于0时节点被标记死亡:
节点计算出当前剩余能量后,当
其中λ(0<λ≤1)为充电参数,决定MC是为节点i进行完全或部分充电。
具体地,所述Step3中MC的剩余能量计算公式为:
上式中L
首先根据t时刻待充电节点的请求集合D(t)=(S
在SCSDRL中,为了提高WRSN的充电效率,包括通过优化MC的充电路径来避免传感器故障和降低充电成本。SCSDRL以MC的总行程长度和死节点数作为奖励信号。把奖励定义为:
状态空间更新:状态的具体更新过程如下:假设MC在0时刻位于基站B处。在每个步骤中,MC从传感器节点或基站B中选择下一步要访问的节点。访问传感器节点i 后,更新传感器节点的需求和MC的剩余能量如下:
根据t时刻待充电节点的请求集合D(t)=(S
在生成MC移动距离最短的充电序列后,判断为节点进行完全充电或部分充电,充电时间划分和电池获得能量计算如下:
在充电序列的基础上动态调整每个节点的充电时长。
如图3所示,SCSDRL中的网络模型为两个神经网络:其一是带有参数θ
基于策略梯度,使用预期奖励的梯度对策略参数的估计来迭代地改进策略使得奖励最大化,从而生成最优解。
如图4所示,网络区域内有位置固定的障碍物,使用Q-learning算法为框架为MC在移动过程中进行避障规划,从而输出具体移动路径。具体步骤如下:
首先将无线可充电传感网区域转化为二维网格地图,其中基站、传感器节点、MC的位置均已知;将路径规划问题抽象为马尔科夫决策过程,由元组{S
求解最优路径就是求得一条到达终点获得最大奖励的策略,最优价值动作函数定义为:
根据Q值进行学习,采用时间差分方法进行Q-table的更新,更新过程如下:
Q(s,a)←Q(s,a)+α[r+γmax
实施例2
如图2所示,例如在一定时间内,四个低能量传感器节点n
以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 一种基于深度强化学习的时空充电调度方法
- 一种基于深度强化学习的移动充电车服务调度方法