一种基于前馈神经网络的实时角色服装布料动画模拟方法
文献发布时间:2023-06-19 11:02:01
技术领域
本发明涉及计算机科学技术学科的两个领域。一方面,它属于计算机图形学领域,进一步,它属于计算机动画分野的布料模拟问题,特别的,本发明是一种针对给定角色与服装的实时布料动画模拟方法。另一方面,它属于人工智能领域,机器学习的神经网络方法,特别的,它涉及前馈神经网络和自编码器。
背景技术
在游戏、虚拟仿真等实时交互应用中,布料动画是重要的视觉表现效果之一:角色服装随着人物动作出现褶皱,或因阵风吹过而上下翻飞。作为日常生活中最常见的现象之一,真实的布料动画可以显著地提升虚拟世界的真实感。目前已有许多基于物理和非物理的研究被提出,如Mass-Spring System、Position Based Dynamics、Projective Dynamics等。这些方法取得了很好的视觉效果,但存在性能问题。为了尽可能获得细节动画,需要建立细密的网格模型,使得表达顶点间相互作用的运动方程的解算规模过大,同时方程求数值解涉及复杂的矩阵运算,复杂的网格也给角色碰撞造成性能问题。对此,一些加速计算的优化算法被提出。游戏在每一帧中都有许多运算需要进行,真正留给布料模拟的时间预算并不多,因此它难以出现在产品级的实时应用中落地。
数据驱动方法,作为另一种思路,目标是用数据学习真实值的近似。此类方法离线生成大量动画数据,在运行时进行插值,或者与传统方法的模拟结果混合。近年来出现了基于神经网络的方法,这些研究体现了一定的运行效率提升,更加重要的是,通过调整网络超参数,可以让模型规模可控,而工业应用往往面临运算时长受限、内存有限等诸多限制,因此该方法可以适应这种需求。但该方法仍然存在效果不佳的问题。
发明内容
为了解决上述现有解决方案中的不足,即运算过慢问题,本发明提出一种基于前馈神经网络的实时服装布料模拟方法。本发明的优点在于,在速度快且计算规模可控的前提下,保持较好的布料动画效果。这是传统方法做不到的。
具体来讲,对于给定角色与服装,在游戏等实时交互应用中,用户输入当前时刻角色动画,本方法可以实时输出当前时刻服装模型(即布料顶点),从而满足实时交互的目的。即,对于三维欧几里得空间下有N个顶点的服装,第t帧时服装的状态用顶点位置
本发明包括两部分,一部分是一个由服装特征提取和动画推断两部分组成的模型(Neural Cloth Simulation,简称NCS),另一部分是数据集生成管线。因为使用了神经网络模型,在运行时之前需要对网络参数进行训练,为此需要构建数据集,所以本说明书不光在“发明内容”一节介绍两部分发明,还在“具体实施方式”中介绍了实际使用时的三个步骤。
一、Neural Cloth Simulation
Neural Cloth Simulation模型由Garment Feature Auto-Encoder(GFE)和Animation Inference Network(AIN)两个神经网络模型构成。接下来介绍两个部分。
1)服装特征提取网络
服装特征提取网络(Garment Feature Auto-Encoder,GFE)是一种自编码器(Auto-Encoder),它可以提取服装顶点数组V在低维空间的表达v。提取的特征v显著减小了表达服装网格所需的数据量,为后续AIN的运算降低了运算量,从而使模型达到实时应用的性能需求。
说明书附图3表示了GFE的结构。GFE由变换χ
接下来解释四部分的细节。创建实例时参数的设定请见“具体实施方式”的“步骤二”。
a.变换χ
编码器φ
其中U
b.编码器φ
φ
其中i是前馈网络φ中全连接层所在的层数。W
φ
其中θ是四层全连接网络的参数,它包含每个全连接层中的矩阵W和偏移量b。令每层的输出维度为上一层的20%-40%,最终
为了得到由φ
重建误差
需要额外说明的是,在运行时,编码器φ
2)服装动画推断网络
服装动画推断网络(Animation Inference Network,AIN)基于前馈神经网络模型构建,说明书附图4展示了AIN的结构。输入当前帧及过去W帧的角色动画,输出当前时刻的服装特征v
第二步进行变换。本变换与U
公式中给出的裁剪操作和变换都是单帧的情况,接下来需要将当前及过去W帧的数据堆叠在一起,最终得到
误差函数使用MSE误差,使用Adam算法对其进行优化:
二、数据集生成管线
作为一种神经网络方法,需要用数据集对神经网络模型进行参数训练,为此以给定的角色和服装的三维模型构建数据集D={V,M}。
流程图见说明书附图5。标记“输入”的内容是数据集的输入。标记“采样”的流程是增加采样的部分,其余流程是中间处理过程,“输出”是数据集所包含的最终内容。在一个数据集中,角色模型与服装作为输入是固定的(“输入”部分),在确定输入后,为了增加数据量,需要尽可能多地制作角色动画和选取合适的模拟参数(“采样”部分)。对于角色动画,需要根据应用目标采样相关动作,并且同一动作采样有不同微调的多个版本,保证数据覆盖尽量多的情况。对于出现次数少的动作也要采样。确定了采样后,需要在不同结果之间进行中间处理(白色部分)。在制作好角色模型后,因为使用骨骼动画,所以需要角色绑定,确定骨骼的数量与位置。根据绑定结果制作的动画,一方面参与之后的数据生成,一方面成为数据集的结果M。在服装动画方面,制作好的角色服装需要“穿”在角色身上,为此需要为角色动画开头添加从Tpose开始到原先动作的过渡帧。匹配好的角色与服装根据不同的模拟参数采样使用选择的模拟器进行服装动画的生成,最后将服装动画数据V储存。
附图说明
图1是NCS整体结构
图2是本发明的技术路线图
图3是Garment Feature Auto-Encoder结构图
图4是AIN网络结构
图5是数据集生成流程图
图6是数据集使用的服装和角色三维模型
图7是数据集的部分动画序列采样
图8是在测试集上的实验结果
图9是不同时间的实验结果
图10是损失函数值随着训练下降的过程
具体实施方式
附图2展示了本发明的技术路线框架。为了实现这个方法,需要进行以下三个步骤:
1-对于给定服装与角色三维模型,制作对应服装与角色的数据集。
2-构建NCS实例,进行参数训练与验证,直到获取满意的效果为止。
3-在运行时,加载NCS模型参数,输入当前时刻角色动画,输出当前时刻布料顶点。
步骤1对应了本发明的数据集生成管线部分,步骤2和3对应NCS模型的部分。接下来以三个步骤的顺序讲解本发明的细节。同时,为了验证该方法的可行性,在阐述具体实施方式的同时,描述实验结果。结果表明本发明能取得可信的视觉效果,且满足实时交互的性能需求。
步骤一:生成数据集
此步骤对应图2的“生成数据集”部分。
1.“给定角色”和“给定服装”:是使用者要模拟的对象,不是本发明生成的内容。角色的三维模型可以拥有任意精度,仅影响生成数据集的时间长短,以人类模型为例,建议模型面数达到10000顶点以上。服装模型建议制作1500~5000个顶点。本实验使用如图6所示的角色“Woman-1”(13662顶点)与服装“T-shirt”(1891顶点)。
2.“采样角色动画”:使用DCC(Digital Contents Creation)软件生成角色模型的骨骼绑定(Rigging),并生成若干段骨骼动画。在角色绑定时,考虑到不需要手指、脚趾等动画内容,本实验使用27根骨骼进行绑定:{Hips,Spine,Spine1,Spine2,Neck,Head,RightEye,LeftEye,HeadTop_end,LeftShoulder,LeftArm,LeftForeArm,LeftHand,RightShoulder,RightArm,RightForeArm,RightHand,LeftUpLeg,LeftLeg,LeftFoot,LeftToeBase,LeftToe_end,RightUpLeg,RightLeg,RightFoot,RightToeBase,RightToe_end}。骨骼动画的生成可以使用网络上提供的动画库,能应用到自己的骨架即可。本实验使用Adobe Mixamo在线动画库获取角色动画,一共获取了50段动画序列,总计30029帧,如图7所示。
3.“使用传统方法生成服装动画”:为了获取给定服装模型穿在角色身上的动画,将角色动画和服装模型导入其他可以计算布料动画的软件,批量生成服装模型的顶点动画。本实验使用Marvelous Designer的算法生成。在解算时,采用了较大的碰撞间隔(skinoffset)参数,增加角色与布料之间的距离,使得推断网络能容忍一定的误差,防止布料与角色交叠(penetration)。
4.“数据集”:将角色动画(每一帧每根骨骼的三维空间位置及旋转,实验取得大小30029*27*12的三维数组,最后一维度的12是3维表示位置,9维表示旋转矩阵)与服装动画(每一帧服装每个顶点的位置,实验取得大小30029*1891*3的三维数组)转换为“.npy”格式。
5.“测试集”和“训练集”:将30029帧结果的一部分设定为训练集(80%-95%),另一部分作为测试集。本实验将90%作为训练集。
步骤二:参数训练与验证
此步骤对应图2的“训练与验证”部分,需要构建NCS实例,在训练集上进行训练,在测试集上验证,调整参数多次实验,最终得到神经网络实例的参数。
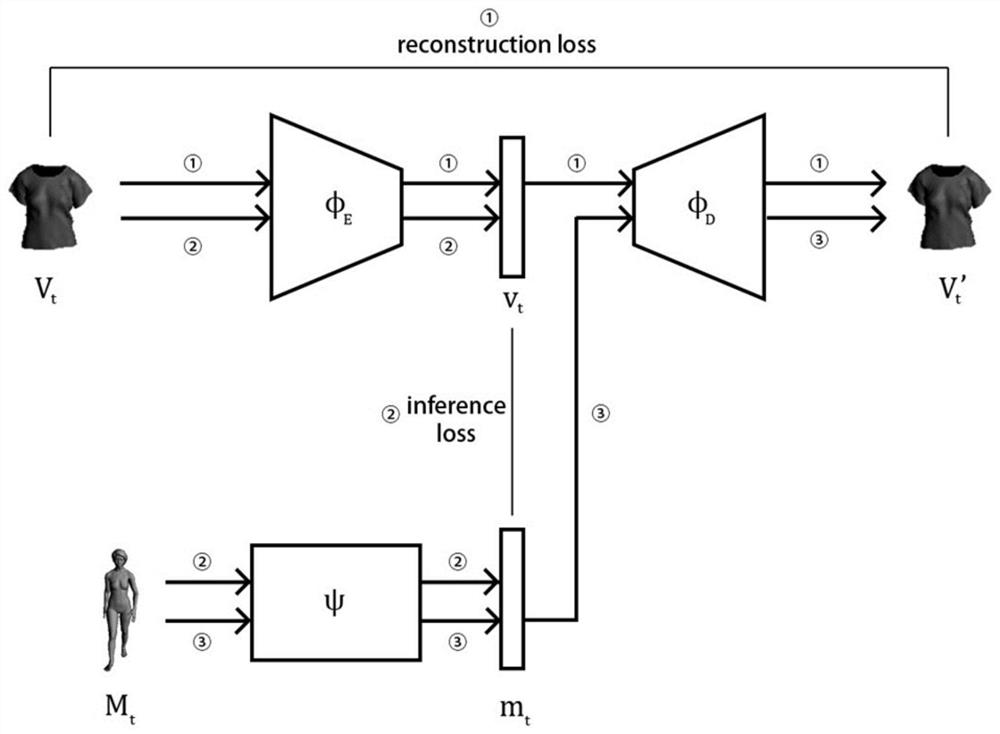
说明书附图1标记①、②的箭头展示了NCS的训练与运行时的数据流向,箭头③表示运行时流程。上方是服装特征提取部分,下方是动画推断部分。
首先按照箭头①的方向进行GFE的训练:
对于输入的V
在本实验中,我们使用基于Python语言的Pytorch框架构建。GFE的φ
第二阶段如图1箭头②所示,是AIN的训练:在t时刻,以角色在此时以及之前W帧的骨骼位置作为输入
步骤三:运行时
图1的箭头③是第三阶段,即运行时:由ψ代替φ
图8显示了预测结果,展示了该序列中的42帧,应用的帧率采用30帧/秒,深色是模型推断结果,浅色是真实值(ground truth)。可以看到,从整体来讲,模型推断结果与真实值基本一致,且有流畅的动态效果,无抖动(Jitter)现象。具体地,第一行的7帧体现了动作剧烈时褶皱较多的情况,第四行体现了动作较少时布料舒展的情况,最后一行体现了轻微褶皱的情况。褶皱少时,布料表面平滑,下摆的大褶皱和因盖到臀部产生的轻微凸起也有体现。在褶皱中等与褶皱多时,也没有丢失高频细节。如图9所示,在模型运行较长时间后依然能得到视觉可信的效果。表明该模型可以处理长时间序列的情况。
以上实验结果表明本章提出的方法满足了本课题提出的要求。它可以满足实时应用的需求:在一台2018年主流笔记本(Intel i7处理器,GTX 1060显卡)上单次运行平均耗时0.597毫秒(使用CUDA加速),在存储消耗方面,维度为[5673,1800,500,120,40]的GFE模型的大小是85.6MB,维度为[240,190,140,90,40]的AIN占用716KB。
以上实验证明了该发明的可行性,它取得了可实时交互的运行速率以及较低且稳定的误差。在实际应用中,开发者可以根据需求调整模型的超参数,达到所期望的效率与结果的平衡。
- 一种基于前馈神经网络的实时角色服装布料动画模拟方法
- 一种基于深度学习的3D角色面部表情动画实时生成方法