一种基于地址编码和相似计算的地址匹配方法
文献发布时间:2023-06-19 11:05:16
技术领域
本发明涉及信息技术领域,具体为一种基于地址编码和相似计算的地址匹配方法。
背景技术
公安行业项目往往涉及到海量的文本挖掘,且由于行业的特殊性,往往需要快速准确地返回结果,这对算法的实时性和准确性提出了一定的要求,而地址匹配就是这样的一个典型场景。地方市级地址库往往涉及到数百万甚至上千万条地址,在实际的业务场景中,往往需要将不规则的地址信息匹配到标准地址库从而进行精准的定位以便进行后续专题业务应用。在这种情况下,而传统的基于字符的的地址匹配方式往往会因为耗时高、匹配度低等问题无法满足业务需求。
而标准地址库的构建往往会依赖于地址编码,通过给特定的地理要素指定唯一的标识码,使数据库的构建更加具有规律性。通过这一规律,依赖地址编码对数据进行有效地初步过滤,能极大减少匹配工作量,从而提升工作效率。
因此一种基于地址编码与相似计算的地址匹配方法能更快速准确地进行地址匹配,从而推动人工智能在实际业务中的落地情况。
发明内容
本发明的目的在于提供一种基于地址编码和相似计算的地址匹配方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:一种基于地址编码和相似计算的地址匹配方法,包括如下步骤:
S1、首先将标准地址库中已有的“ID-地址要素”的地址编码进行重构建,将ID所对应的道路、村委、小区信息利用正则表达式将镇、村委、村庄不同级别地址分级抽取处理形成新的地址依赖表,并将抽取后的信息构成自定义词典;
S2、基于自定义词典与新地址库依赖地对原始标准地址库进行数据初步过滤筛选;
S3、通过地址标准化模块对数字转换、数字中文的分开提取与地址层级归一化处理,经过地址标准化模块后的地址信息会输入地址匹配模块进行后续操作;
S4、地址匹配模块对提取的中文和数字分别基于WMD算法和最小编辑距离算法对数据进行加权匹配,返回准确度最高的标准地址库信息。
优选的,所述步骤S1中先由预提取模块对原有标准地址库进行提取简化,得到新的地址库查询依赖与词库依赖。
优选的,所述步骤S3中输入的地址信息首先经过基于自定义词库与新地址库依赖的预匹配模块进行预匹配,经过预匹配操作后的地址信息经过标准化模块对输入的非标准数据进行数据标准化处理,然后将进行经过标准化的数据输入地址匹配模块。
优选的,所述步骤S4中地址匹配模块对处理后的非标准化的数据进行匹配,输出地址库中对应相似度最高的单条地址信息,即为准确度最高的标准地址库信息。
与现有技术相比,本发明的有益效果是:本发明经过输入非标准化地址进行测试及业务人员进行结果对比,算法整体准确度较高,过滤掉准确度低于阈值(0.75)与不存在与标准地址库中的记录,整体算法的准确度可以达到96%,相比于tf-idf算法,解决了稀疏词向量导致的内存不够的问题,也避免了大量无效匹配值的产生。
附图说明
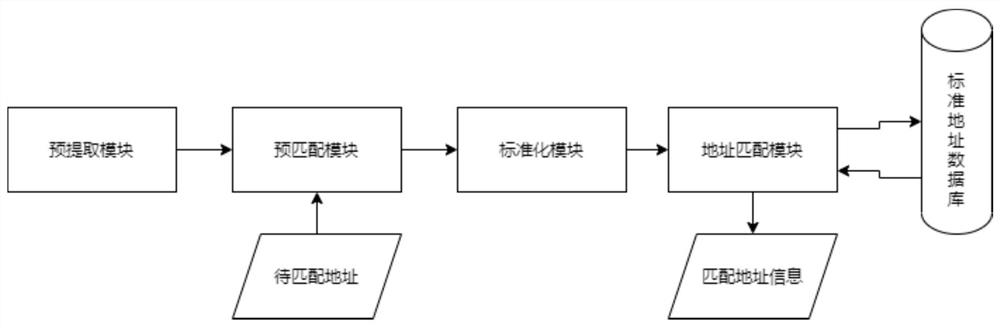
图1为本发明基于地址编码和相似计算的地址匹配流程图;
图2为本发明预提取模块流程图;
图3为本发明标准化模块流程图;
图4为本发明地址匹配模块流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明主要有四个模块,先由预提取模块对原有标准地址库进行提取简化,得到新的地址库查询依赖与词库依赖;输入的地址信息首先经过基于自定义词库与新地址库依赖的预匹配模块进行预匹配,经过预匹配操作后的地址信息经过标准化模块对输入的非标准数据进行数据标准化处理,然后将进行经过标准化的数据输入地址匹配模块,最后由地址匹配模块对处理后的非标准化的数据进行匹配,输出地址库中对应相似度最高的单条地址信息。
本发明提供一种技术方案:一种基于地址编码和相似计算的地址匹配方法,包括如下步骤:
S1、加载预提取模块,利用正则将区县、乡镇、村组、小区、道路等信息分级抽取处理形成新的地址依赖表,其中区县为第一级、村镇为第二级、小区与道路为第三级,并将抽取后的信息构成自定义词典。具体流程如图2所示。如地址编码为“200914”对应的“尧塘镇汤庄村委大南头”,通过正则提取抽取为“尧塘”、“汤庄”、“大南头”三个层级,生成新的地址依赖表。如图2所示。
S2、加载地址标准化模块,具体步骤为基于自定义词库分词,再从左至右将分词结果匹配到新地址依赖表,匹配到表中小层级即停止匹配并返回该层级的地址编码,再过滤出地址库中对应该地址编码的地址记录。
S3、加载地址标准化模块,将输入信息标准化,包含地址的层级标准化与数字的文本的处理两个部分。如输入为“江苏省常州市新北区春江镇圩塘村委南园里22号”的地址信息,通过标准化模块的处理,会先归一化到标准地址库中的最高层级(如:村镇),得到“春江镇圩塘村委南园里22号”的结果,并分别对数字、文本进行进一步提取,得到“春江镇圩塘村委南园里号”与“22”的结果,具体流程如图3所示。
S4、加载地址匹配模块。对于文本和数字分别采用WMD和最小编辑距离的算法进行地址的匹配,将步骤S1中筛选出的标准地址库的文本与数字部分抽取出来,并分别分别按照0.2与0.8的权重基于WMD与最小编辑距离计算相似度,最终返回相似对最高的对应记录。具体流程如图4所示。WMD算法是基于word2vec的准确度较高的相似度算法,但其无法区分不同位置的数字问题,可能会导致相同数字的不同组合相似度值相同的问题;而最小编辑距离算法衡量的是两个字符之间的最小操作次数,能有效的解决上述问题,使结果更加精准。
本发明基于地址编码,构建自定义分词词典与新的数据库依赖,利用自定义分词将地址进行分词匹配,对标准地址库进行初步筛选,然后对输入的地址信息进行标准化,并分别提取文本与数字加权计算相似度,返回准确度最高的记录。利用本发明,能够实行快速准确地地址匹配,且相比于其他地址匹配算法,能更针对性地解决实际问题中门牌号匹配度不高的问题。
本发明的主要特点:
1、构建新的自定义词典与新数据库依赖能极大降低数据级从而加快匹配速度。
2、对地址中的文本和数字片段分别进行处理,增加算法的准确度。
本发明与现有技术相比具有如下优点和有益效果:
首先,与基本的tf-idf相似度匹配方法相比,本发明充分利用地址编码的信息,结合正则与自定义分词词典,对原始标准地址库进行筛选,极大地减少待匹配数据的数据量,提升了匹配效率也提高了匹配准确度。
其次,本发明充分考虑数字与文本匹配情况的不同,分别用不同算法进行针对性处理,并结合实际情况赋予不同权重,极大地提高了匹配的准确度。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
- 一种基于地址编码和相似计算的地址匹配方法
- 一种基于多维度向量化编码的文本相似度计算方法及装置