一种知识图谱的本体创建方法
文献发布时间:2023-06-19 11:08:20
技术领域
本发明涉及知识图谱技术领域,尤其涉及一种知识图谱的本体创建方法。
背景技术
知识图谱在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
知识图谱,是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。
知识图谱主要由本体、知识、数据构成,其中本体作为抽象层面是知识图谱建立的框架与导向。目前在本体创建过程中,只针对文本数据进行知识提取,并且本体构建后缺乏质检环节,容易出现差错。
发明内容
本发明的目的在于克服现有技术存在的以上问题,提供一种知识图谱的本体创建方法。
为实现上述技术目的,达到上述技术效果,本发明通过以下技术方案实现:
一种知识图谱的本体创建方法,包括以下步骤:
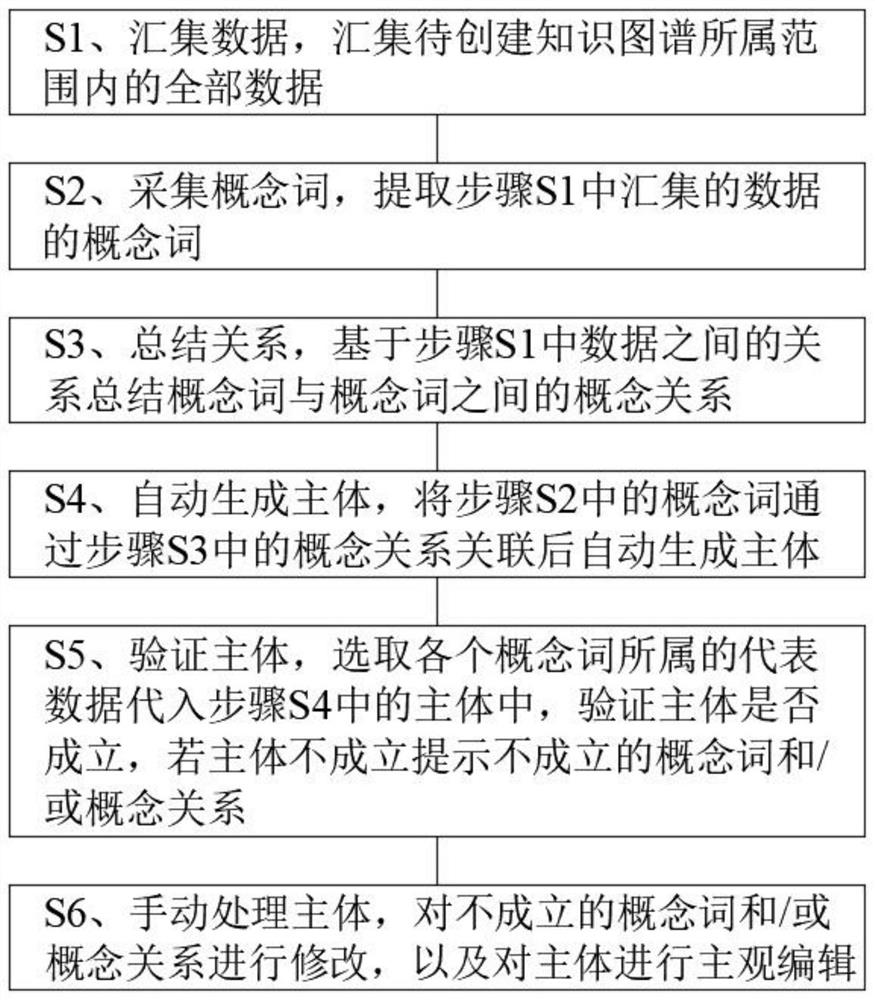
S1、汇集数据,汇集待创建知识图谱所属范围内的全部数据;
S2、采集概念词,提取步骤S1中汇集的数据的概念词;
S3、总结关系,基于步骤S1中数据之间的关系总结概念词与概念词之间的概念关系;
S4、自动生成主体,将步骤S2中的概念词通过步骤S3中的概念关系关联后自动生成主体;
S5、验证主体,选取各个概念词所属的代表数据代入步骤S4中的主体中,验证主体是否成立,若主体不成立提示不成立的概念词和/或概念关系;
S6、手动处理主体,对不成立的概念词和/或概念关系进行修改,以及对主体进行主观编辑。
其中,所述步骤S2中采集概念词具体包括:
S21、将步骤S1中的全部数据按照数据来源进行一级分类,然后将数据按照数据类型进行二级分类,形成若干个数据集;
S22、采用配置有语义搜索引擎的分词器对文本数据进行分词处理,以提取文本数据中的文本数据概念词;
S23、对数值数据按照数据来源与对象类相结合的方式归纳总结提取数值数据概念词,对声音数据按照数据来源与对象类相结合的方式归纳总结提取声音数据概念词,对图像数据按照数据来源与对象类相结合的方式归纳总结提取图像数据概念词。
其中,所述步骤S3中总结关系具体包括:
S31、采用配置有语义搜索引擎的分词器对文本数据进行分词处理,以总结文本数据概念词与文本数据概念词之间的文-文概念关系;
S32、采用语义搜索引擎分别搜索文本数据概念词与数值数据概念词、文本数据概念词与声音数据概念词、文本数据概念词与图像数据概念词、声音数据概念词与数值数据概念词、图像数据概念词与数值数据概念词、声音数据概念词与图像数据概念词、声音数据概念词与声音数据概念词、图像数据概念词与图像数据概念词之间的文-数概念关系、文-声概念关系、文-图概念关系、声-数概念关系、图-数概念关系、声-图概念关系、声-声概念关系、图-图概念关系;
S33、根据数学、物理、化学原理总结数值数据概念词与数值数据概念词之间的数-数概念关系。
其中,所述步骤S4中自动生成主体具体包括:
S41、将具有概念关系的两个概念词通过对应的概念关系组合成一个关系小组;
S42、将所有关系小组中相同的概念词合并,从而生成主体。
其中,所述主体或为树状或为网状或为放射状结构。
其中,所述步骤S5中验证主体具体包括:从每个概念词所属的数据集中选取至少三组代表数据,将代表数据代入自动生成的主体中,利用概念关系验证该概念关系两边的概念词之间是否符合该概念关系;若一个概念词所属数据集中的代表数据与周围所有概念词所属数据集中的代表数据均不符合对应的概念关系,则该概念词提取存在问题,提示该概念词不成立;若一个概念词所属数据集中的代表数据与周围部分概念词所属数据集中的代表数据不符合对应的概念关系,则提示该概念关系不成立。
其中,所述步骤S6中手动处理主体具体包括:
S61、调取不成立的概念词的数据集、与其有概念关系的全部概念词的数据集、及与其有关的概念关系,首先判断该不成立的概念词的数据集组合是否正确,若数据集组合有问题则手动对数据集进行重新组合,数据集重新组合后人工拟定新的概念词,若数据集合无问题则直接人工拟定新的概念词,梳理新的概念词与原不成立的概念词周围的概念词之间的概念关系,替换原本体中不成立的概念词及其周围不成立的概念关系;
S62、调取不成立的概念关系两边的概念词的数据集,选取数据集中对应的数据逐对梳理数据关系,集合所有梳理的数据关系总结出两个概念词之间的概念关系,替换原本体中不成立的概念关系。
S63、人工筛除多余的概念词,并将这些多余的概念词及其与其他所需概念词之间的概念关系一同删除。
本发明的有益效果是:能够从各类型数据进行概念词提取与概念关系提取,使本体的构成全面丰富;在本体生成后进行检验,并将不成立的概念词和/或概念关系反馈给工作人员,工作人员人工进行修改和编辑处理,以提高生成的本体的准确性和可用性。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本申请的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
图1是本发明实施例中本体创建方法的流程图。
具体实施方式
下面将参考附图并结合实施例,来详细说明本发明。
如图1所示,一种知识图谱的本体创建方法,包括以下步骤:
S1、汇集数据,汇集待创建知识图谱所属范围内的全部数据;
S2、采集概念词,提取步骤S1中汇集的数据的概念词;
S3、总结关系,基于步骤S1中数据之间的关系总结概念词与概念词之间的概念关系;
S4、自动生成主体,将步骤S2中的概念词通过步骤S3中的概念关系关联后自动生成主体;
S5、验证主体,选取各个概念词所属的代表数据代入步骤S4中的主体中,验证主体是否成立,若主体不成立提示不成立的概念词和/或概念关系;
S6、手动处理主体,对不成立的概念词和/或概念关系进行修改,以及对主体进行主观编辑。
其中,所述步骤S2中采集概念词具体包括:
S21、将步骤S1中的全部数据按照数据来源进行一级分类,然后将数据按照数据类型进行二级分类,形成若干个数据集;
S22、采用配置有语义搜索引擎的分词器对文本数据进行分词处理,以提取文本数据中的文本数据概念词;
S23、对数值数据按照数据来源与对象类相结合的方式归纳总结提取数值数据概念词,对声音数据按照数据来源与对象类相结合的方式归纳总结提取声音数据概念词,对图像数据按照数据来源与对象类相结合的方式归纳总结提取图像数据概念词。
其中,所述步骤S3中总结关系具体包括:
S31、采用配置有语义搜索引擎的分词器对文本数据进行分词处理,以总结文本数据概念词与文本数据概念词之间的文-文概念关系;
S32、采用语义搜索引擎分别搜索文本数据概念词与数值数据概念词、文本数据概念词与声音数据概念词、文本数据概念词与图像数据概念词、声音数据概念词与数值数据概念词、图像数据概念词与数值数据概念词、声音数据概念词与图像数据概念词、声音数据概念词与声音数据概念词、图像数据概念词与图像数据概念词之间的文-数概念关系、文-声概念关系、文-图概念关系、声-数概念关系、图-数概念关系、声-图概念关系、声-声概念关系、图-图概念关系;
S33、根据数学、物理、化学原理总结数值数据概念词与数值数据概念词之间的数-数概念关系。
其中,所述步骤S4中自动生成主体具体包括:
S41、将具有概念关系的两个概念词通过对应的概念关系组合成一个关系小组;
S42、将所有关系小组中相同的概念词合并,从而生成主体。
其中,所述主体或为树状或为网状或为放射状结构。
其中,所述步骤S5中验证主体具体包括:从每个概念词所属的数据集中选取至少三组代表数据,将代表数据代入自动生成的主体中,利用概念关系验证该概念关系两边的概念词之间是否符合该概念关系;若一个概念词所属数据集中的代表数据与周围所有概念词所属数据集中的代表数据均不符合对应的概念关系,则该概念词提取存在问题,提示该概念词不成立;若一个概念词所属数据集中的代表数据与周围部分概念词所属数据集中的代表数据不符合对应的概念关系,则提示该概念关系不成立。
其中,所述步骤S6中手动处理主体具体包括:
S61、调取不成立的概念词的数据集、与其有概念关系的全部概念词的数据集、及与其有关的概念关系,首先判断该不成立的概念词的数据集组合是否正确,若数据集组合有问题则手动对数据集进行重新组合,数据集重新组合后人工拟定新的概念词,若数据集合无问题则直接人工拟定新的概念词,梳理新的概念词与原不成立的概念词周围的概念词之间的概念关系,替换原本体中不成立的概念词及其周围不成立的概念关系;
S62、调取不成立的概念关系两边的概念词的数据集,选取数据集中对应的数据逐对梳理数据关系,集合所有梳理的数据关系总结出两个概念词之间的概念关系,替换原本体中不成立的概念关系。
S63、人工筛除多余的概念词,并将这些多余的概念词及其与其他所需概念词之间的概念关系一同删除。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。
- 一种知识图谱的本体创建方法
- 一种知识图谱的创建方法、装置、存储介质和服务器