基于矿物相与神经网络复合模型预测煤灰熔融温度的方法
文献发布时间:2023-06-19 11:11:32
技术领域
本发明涉及一种基于矿物相与神经网络复合模型预测煤灰熔融温度的方法。
背景技术
我国煤炭资源丰富,其产量与消耗量均居世界首位,2015年原煤产量达到36.8亿吨,消耗量达39.65亿吨,我国煤炭生产量和消费量分别占国内能源生产总量和消费总量的72.1%和64%。据中国工程院预测,按现在能源需求计算,到2030年中国煤炭消费量将达到45亿t以上。根据我国资源状况和煤炭在能源生产及消费结构中的比例,以煤炭为主体的能源结构在相当长一段时间内不会改变。因此如何更加合理高效地利用现有的煤炭资源成为一个相当重要而迫切需要解决的问题。尽管我国煤炭资源丰富,但煤灰成分的组成差异较大,煤灰组成的不同则造成了煤灰熔融温度的差异。在煤炭综合利用中,煤灰熔融特性是一项重要的煤质指标。
煤燃烧时,其中矿物质转变成灰分,而煤灰的熔融特性是动力用煤和气化用煤的一项重要指标。同时,煤灰熔融性也是影响煤灰性能的一个重要因素。煤灰的熔融温度是煤灰熔融特性的直接表现,主要包括四个特征温度值:变形温度、软化温度、半球温度和流动温度。按照排渣方式不同,在煤炭燃气化过程中分成固态排渣和液态排渣两大类。固态排渣技术要求原料煤的灰熔融温度高于操作温度,灰渣以固态形式排出;液态排渣技术要求煤灰在较低的温度下熔融,灰渣能以熔融状排出。所以,煤灰熔融性直接决定着煤炭气化过程排渣方式的选择,是影响炉况能否正常运行的一个重要因素。因此,为了寻求改善煤灰熔融性的方法,以适应不同排渣方式的燃烧、气化技术或扩大适用的煤种范围,对煤灰熔融性进行深入研究显得尤为必要。
目前,工业上测量煤灰熔融温度的主要方法是实验室内测量,这种方法需要先获取煤种的各元素含量,进一步通过调配、高温加热等的方法获取熔融温度。实验法测量需要的步骤较多,耗时长且测定费用高。更为重要的是,在煤灰熔融温度进行改善时,就需要反复测量,这个缺点就会显得十分突出,因此,在煤灰熔融性进行改善的过程中,一套准确、可靠的煤灰灰熔点预测模型就显得非常重要。
发明内容
本发明的目的是提供一种基于矿物相与神经网络复合模型预测煤灰熔融温度的方法,简便可行,准确度高。
为实现上述目的,本发明采用的技术方案如下:一种基于矿物相与神经网络复合模型预测煤灰熔融温度的方法,包括以下步骤:
(1)收集某一煤种在温度T下的XRD图谱,从而得到此温度下煤灰矿物相实际组成;
(2)将硅、铝、铁、钙、镁五种元素在煤灰中的含量以及温度T作为影响煤灰-矿物相预测子模型的参数;使用热力学方法,利用高温下化学组分相互反应产生的吉布斯自由能变化,建立线性规划问题,再使用Matlab工具,建立求解指定温度T下的煤灰-矿物相组成预测子模型;
(3)向煤灰-矿物相组成预测子模型中输入硅、铝、铁、钙、镁的含量以及温度T,预测出在此温度下的矿物相组成;
(4)将预测出的矿物相组成与实际组成对比,验证煤灰-矿物相组成预测子模型的准确性;
(5)将煤灰-矿物相组成预测子模型的输出数据作为下一个煤灰-灰熔点预测子模型的输入参数,同时还需设置的参数有:流动温度的最大值T
(6)利用BP神经网络,建立煤灰-灰熔点预测子模型;
(7)收集煤灰的原始数据,所述原始数据包括K
采用部分真实煤灰数据对煤灰-灰熔点预测子模型进行训练,同时用另一部分真实煤灰数据做模拟,验证模型的精确性;
(8)引入修正值,对Ti和Na/K元素对模型的影响进行修正,修正公式如下:
式中,θ
再使神经网络的训练反复引入修正值,以摆脱修正值对其的预测影响,同时反复求解新的修正值关系式,从而使整个预测模型精确化;
(9)分析煤灰-灰熔点预测子模型预测煤灰数据的精确度,检验模型预测精度。
步骤(6)中,所述BP神经网络的输入层为如下矿物相的含量数据:硅钙石(3CaO·2SiO
进一步地,步骤(7)对煤灰-灰熔点预测模型进行训练的步骤是:使用BayesianRegularization算法以及10层的隐藏层数,选择使用Matlab中的神经网络工具箱,将训练次数设置为500代以内。
进一步地,步骤(9)中,评判精确度的指标主要分为平均绝对百分比误差以及均方误差,计算公式如下:
其中,MAPE为平均绝对百分比误差,MSE为均方误差,x
同时,用线性相关系数来表示预测拟合程度的指标,其公式为:
其中,r表示线形相关系数,xi和yi分别为数据的预测值和实际值,
与现有技术相比,本发明将煤灰矿物相组成和神经网络模型进行耦合建立了复合模型,经验证,本复合模型具有较高的精确度和可靠性,可以用于实际生产中预测煤灰熔融温度。
附图说明
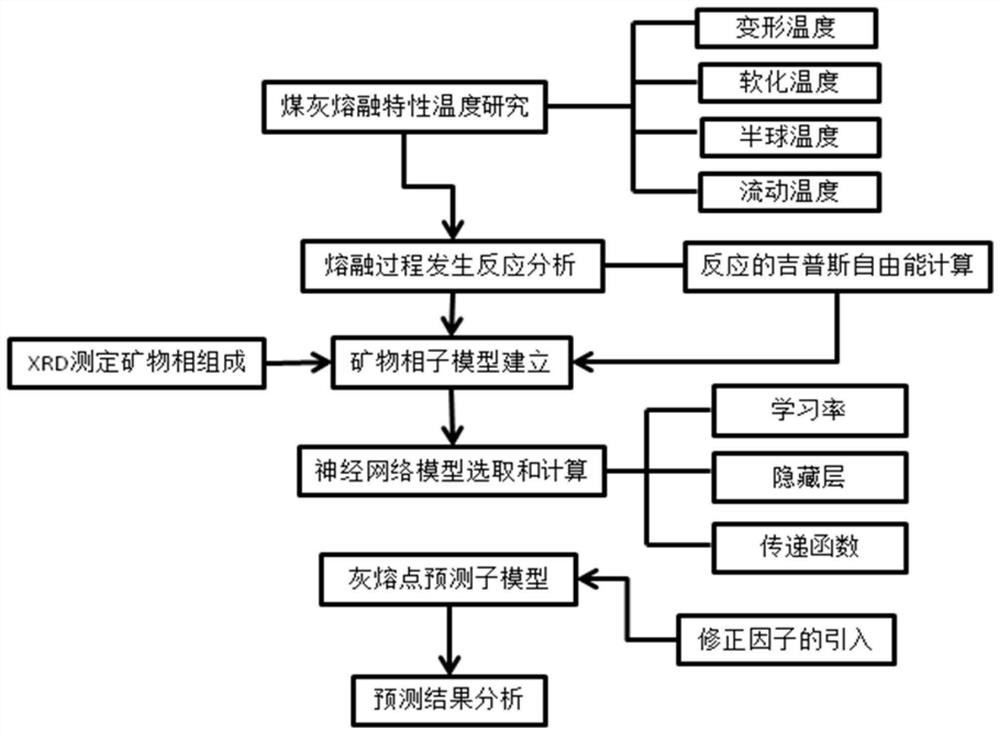
图1为本发明预测煤灰熔融温度方法的流程图;
图2为神经网络结合矿物相子模型预测灰熔点算法流程图;
图3为修正值重引入算法流程图;
图4为大同石炭二叠纪原煤煤灰在1500℃温度下的XRD衍射图谱。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细说明。
本发明提供一种基于矿物相与神经网络复合模型预测煤灰熔融温度的方法,首先建立煤灰矿物相组成子模型,利用高温下化学组分相互反应产生的吉布斯自由能变化,建立线性规划问题,建立求解指定温度下煤灰矿物相组成的预测模型,并对此模型的一致性进行检验;在矿物相组成子模型的基础上,建立灰熔点预测子模型;建立神经网络模型,对神经网络的各项训练参数进行调校,并采用迭代算法进一步加强预测模型的预测精度,同时加入修正值,用以表示煤灰中次要元素对煤灰熔融性的影响,最后对所建立的模型的精确度和可靠性进行分析,确立预测结果精确性指标,并与支持向量机预测方式的预测结果进行比较。
具体流程如图1所示,具体步骤是:
(1)收集大同石炭二叠纪原煤煤灰化学组成,见表1:
表1大同石炭二叠纪原煤煤灰化学组成
收集大同石炭二叠纪原煤在1500℃的XRD图谱,如图4所示,从而得到这种状态下煤灰矿物相组成;
(2)将硅、铝、铁、钙、镁的含量以及温度作为煤灰-矿物相预测子模型的输入参数;使用热力学方法,利用高温下化学组分相互反应产生的吉布斯自由能变化,建立线性规划问题,数学表达式如下:
N为在煤灰熔融的反应体系中可能存在的反应个数;
n
T为反应所发生的温度,单位为K;
ΔG
β
吉布斯自由能的计算采用以下公式:
其中
使用Matlab工具中的linprog函数编写计算程序,求解上述线性规划问题,并编译为DLL动态链接库,使用Visual Studio 2015程序进行调用,建立求解指定温度下煤灰-矿物相预测子模型;
(3)向煤灰-矿物相预测子模型中输入硅、铝、铁、钙、镁的含量(数据参见表2)以及温度T=1500℃,得出在这一温度下的矿物相组成,见表2:
表2大同石炭二叠纪原煤煤灰在1500℃下矿物相成分预测结果
(4)将预测出的矿物相组成与实际组成对比,验证煤灰-矿物相预测子模型的准确性;
分析图4可知,大同石炭二叠纪原煤的煤灰在1500℃温度下时,其矿物相的主要组成为莫来石,其次为石英。这与矿物相预测子模型的预测结果是一致的。说明此煤灰-矿物相预测子模型具有较高的可靠性。
(5)将煤灰-矿物相预测子模型的输出数据作为煤灰-灰熔点预测子模型的输入参数,同时还需设置的参数有:流动温度的最大值T
(6)利用BP神经网络,建立煤灰-灰熔点预测模型,如图2;
本实施例所用的BP神经网络的输入层为如下矿物相的含量数据:硅钙石(3CaO·2SiO
(7)收集335组煤灰的原始数据,这些数据包括K
表3包括了这些数据的基本数据分布状况;
表3 355组煤灰数据的组分取值变化范围
在一般的煤灰中,SiO
与表3进行比较,发现本实施例所收集煤灰数据中的主要成分的含量,基本覆盖了一般煤灰中相应组分含量的范围。并且,其各组分平均值都处在含量变化区间靠近中心的位置。因此本实施例所收集的煤灰数据当对可靠,具有随机性,并且分布均匀、分布广泛。
采用70%真实煤灰数据对煤灰-灰熔点预测模型进行训练,同时用30%真实煤灰数据做模拟,验证模型的精确性;对煤灰-灰熔点预测模型进行训练的步骤是:使用Bayesian Regularization算法以及10层的隐藏层数,选择使用Matlab R2015b中的神经网络工具箱,将训练次数设置为500代以内;
(8)引入修正值,对Ti和Na/K元素对模型的影响进行修正,修正公式如下:
式中,θ
Ti元素在预测模型中的修正关系式为:
w
Na/K元素在预测模型中的修正关系式为:
w
可以看出,煤灰的灰熔点随着Ti元素的增加而增加,大体来说,每增加1%的TiO
(9)分析煤灰-灰熔点预测子模型预测煤灰数据的精确度,评判精确与否的指标主要分为平均绝对百分比误差以及均方误差。计算公式如下:
其中,MAPE为平均绝对百分比误差,MSE为均方误差,x
同时,用线性相关系数来表示预测拟合程度的指标,其公式为:
其中,r表示线形相关系数,xi和yi分别为数据的预测值和实际值,
将模型所预测的煤灰灰熔点与其实际灰熔点进行比较,求得其误差,并整理成表3。1500℃以上的数据由于难以获取,记为1500℃。
分析表4可知,DT的绝对误差大约在-86~79K之间,ST的绝对误差大约在-45~70K之间,FT的绝对误差大约在-50~60K之间。
对于线性相关系数,一般来说,0.7<r<0.8时是可接受的,0.8<r<0.9时是比较好的,r>0.9是非常好的。
本发明的煤灰灰熔点预测模型的相关系数分别为r(DT)=0.807,r(ST)=0.843,r(FT)=0.856,说明预测的线性相关度比较好。DT的MAPE值为3.32%,ST的MAPE值为2.98%,FT的MAPE值为3.01%。DT的MSE值为2306,ST的MSE值为2164,FT的MSE值为1978。
表4煤灰熔融性预测及误差单位(℃)
(10)与支持向量机预测数据比较
支持向量机与神经网络类似,都是学习型的机制,但与神经网络不同的是SVM使用的是数学方法和优化技术。
支持向量机的原理是将数据投射到一个高维的空间,并且在这个空间里建立模型:
再用此模型来回归函数。可以直接使用Matlab R2015b来实现支持向量机的预测功能。
为了区别于本实施例,支持向量机的输入量设置为几种化学成分(Si、Al、Fe、Ca、Mg、Na、K、Ti),输出量设置为DT、ST与FT。
与模型使用完全相同的33组数据进行比较。表5是支持向量机的预测结果,1500℃以上的数据由于难以获取,记为1500℃。
表5支持向量机的煤灰熔融性预测及误差单位(℃)
分析表5可以得知,对于支持向量机的预测结果进行评估,DT的MAPE值为4.62%,ST的MAPE值为4.06%,FT的MAPE值为4.81%,而DT的绝对误差大约在-107~89K之间,ST的绝对误差大约在-60~80K之间,FT的绝对误差大约在-60~85K之间。DT的MSE值为4306,ST的MSE值为3164,FT的MSE值为4978。
表6本实施例模型与支持向量机的预测结果比较
根据表6的对比结果,本发明所建立的煤灰熔融性预测模型,在各方面全面优于支持向量机的预测结果。说明本模型的预测精度具有较高的可靠性。
- 基于矿物相与神经网络复合模型预测煤灰熔融温度的方法
- 一种脱硫灰-粉煤灰复合矿物掺合料及其制备方法