基于多级残差卷积与注意力机制的中文命名实体识别方法
文献发布时间:2023-06-19 11:19:16
技术领域
本发明属于自然语言处理领域,特别涉及一种基于多级残差卷积与注意力机制的中文命名实体识别方法。
背景技术
命名实体识别一直是自然语言处理研究的重点,其主要目标是从文本中识别人名、地名、组织机构名等实体。作为NLP(Natural Language Processing,自然语言处理)中一项基本任务,命名实体识别对自动问答、关系抽取等任务有着重要作用。目前,中文命名实体识别主要分为基于词语和基于字符的两类方法。由于实体大多以词语的形式出现,所以基于词语的方法可以充分利用词语信息进行实体识别,但是词语需由句子经过分词获得,而分词工具的表现参差不齐,很难获得理想的分词效果。相较而言,基于字符的命名实体识别方法以单个字符为单位,不存在分词错误的情况。因此,本发明采用基于字符的方法,针对其效率低下和难以获取上下文信息的问题,提出独特的多级残差卷积和注意力方法来有效提高中文命名实体识别效果。
目前,基于字符的命名实体识别方法主要使用循环神经网络及其变体,例如长短时记忆网络和门控循环单元,并且发展势头十分强劲。虽然循环神经网络可以充分利用历史信息及未来信息处理当前信息,但仍面临以下问题:(1)如何在不引入复杂的外部知识的前提下,使模型获得更多的语义信息。(2)如何克服原有模型的缺陷,有效地获取全局上下文信息。(3)如何在提高模型效率的同时,不降低模型的精度。
基于以上考虑,本发明提出一个基于多级残差卷积与注意力机制的网络用于中文命名实体识别。首先通过数据增强和多模态向量简化语义信息的利用过程;其次,使用多级残差卷积替代循环神经网络,获取不同范围内的局部上下文信息,并降低模型复杂度;然后使用自注意力机制突出重要的字符,获取全局上下文信息;最后使用条件随机场计算字符标签的转移概率,获得合理的预测结果。
发明内容
本发明的主要目的是提出一种基于多级残差卷积与注意力机制(Multi-levelCNN with Residual structure and Attention mechanism,RAMCNN)的中文命名实体识别方法,更好地处理句子序列,获取文本信息,以进行高效的命名实体识别。
为了实现上述目的,本发明提供如下技术方案:
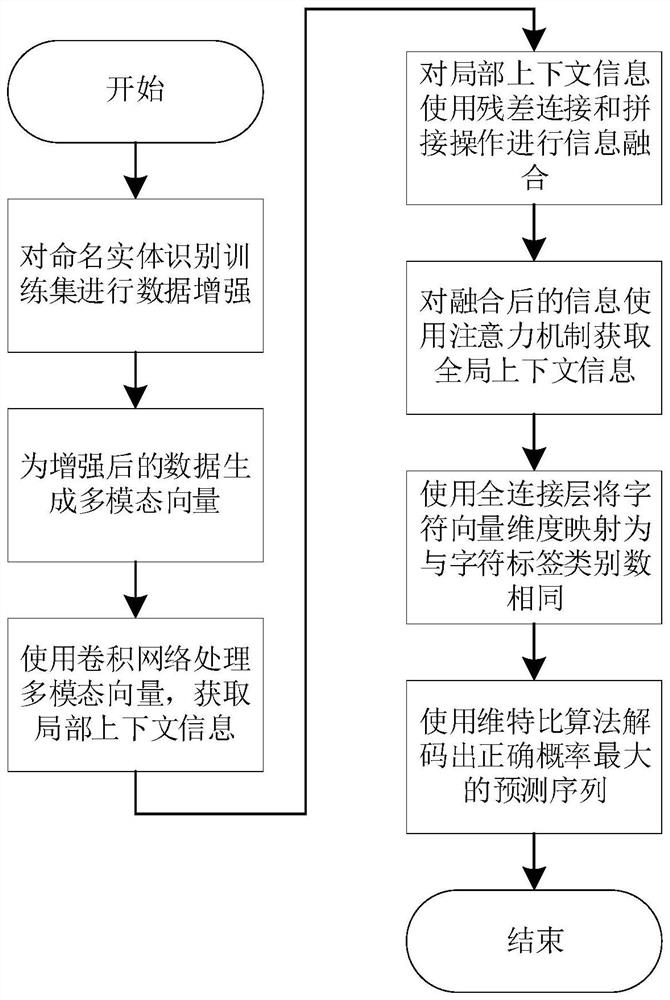
步骤一、扩充训练集:对现有的数据进行增强,获得最终的训练集
步骤二、生成多模态向量:对每个句子
步骤三、获取局部上下文信息:使用卷积神经网络对每个句子S
步骤四、获取融合的局部上下文信息:多级残差卷积网络使用残差连接将原始特征图
步骤五:获取全局上下文信息:首先将步骤四中拼接后的特征图
步骤六、特征图维度映射:使用全连接层将步骤五中输出的特征图映射为维度与字符标签类别数相同的特征图。
步骤七、条件随机场输出预测序列:使用维特比算法解码出文本序列对应的正确概率最大的标签序列。
与现有的技术相比,本发明具有以下有益效果:
1.步骤一中提出的数据增强算法完全基于现有的训练集扩充数据量,与传统的引入带有大量噪声的外部知识的方法相比,该增强算法无需对数据进行处理即可直接使用,有助于模型充分学习数据之间的联系,减少过拟合,提升识别精度。
2.步骤二中使用的多模态向量由预训练好的字符向量查找表生成,与现有的使用神经网络抽取并增加特征的方法相比,更简单高效地增加了字符特征,便于模型利用更丰富的语义知识进行实体识别。
3.步骤三和步骤四中构建的多级残差卷积网络通过尺度不同的卷积核有效地学习到不同范围内的上下文信息,并通过残差连接对其进行融合以获取更丰富的文本信息。由于卷积网络可以充分利用硬件的计算加速能力,所以该网络比循环神经网络有更高的效率,极大地提高了实体识别速度。
4.步骤五中注意力机制通过计算每个字符与句子之间的关系计算字符对句子的重要程度,学习全局上下文信息。与计算两两字符之间关系的方法相比,该注意力机制有效地减少了计算量并提升了模型识别精度。
附图说明
图1为本发明的算法流程图;
图2为本发明的整体模型图;
图3为多级残差卷积框架图;
图4为注意力机制框架图。
具体实施方式
以下根据实施例和附图对本发明的技术方案进行进一步说明。
图2表示本发明的算法模型图。模型包括数据增强、多模态向量层、多级残差卷积、注意力机制、条件随机场5个关键部分。为了对本发明进行更好的说明,下面以公开的中文命名实体识别数据集Resume为例进行阐述。
上述技术方案中步骤一中数据增强算法为:
把训练集样本中具有相同类型的实体交换位置,生成新的训练集。然后将原始训练集和新生成的训练集合并作为新的训练集,即可达到扩充数据量的目的。例如,训练集中有两个样本分别包含“南京人大代表”和“北京欢迎您”,由于“南京”和“北京”都是被标注为“地点”类型的实体,所以经过数据增强后会生成两个新样本,里面分别包含“北京人大代表”和“南京欢迎您”。因此数据增强可以让相同的实体具有不同的上下文,从而更好地学到语义知识。算法如表1所示。
表1数据增强算法
其中E
步骤二中字符向量查找表是由语言模型在大规模语料库上训练而来,查找表以文本文件形式存储,每行是一个字符串,字符串的内容为字符以及字符对应的向量。经多次实验证明,本发明采用两个字符向量查找表生成多模态向量的效果最佳。本示例中用于生成字符向量的模型为skip-gram模型,但本发明并不限于使用该模型生成字符向量。
步骤三和步骤四中多级残差卷积的构建方法为:
首先利用卷积网络对步骤二中由多个字符的多模态向量组成的特征图进行卷积池化操作,使得每个字符向量融合了邻近字符的信息;然后使用残差连接对卷积前后的特征图进行融合,作为下一卷积层的输入,目的在于使模型可以同时利用卷积特征和原始特征;最后将每一卷积层的结果拼接,作为多级残差卷积网络的最终输出。多级残差卷积中卷积核的个数可根据硬件环境和实验效果而定,具体而言,本发明运行在内存为12GB的GTX1080Ti显卡上,经多次实验证明,当卷积核个数为128时,模型取得最高精度。多级残差卷积框架如图3所示。
步骤五中注意力网络的构建方法为:
首先将步骤四中多级残差卷积输出的特征图按列维度求平均,将其转为一个句子向量;然后构建特征图中每个字符向量与句子向量之间的关系,计算出每个字符对于句子的重要程度;最后使用softmax函数对重要程度进行归一化,计算出每个字符的重要性权重。注意力机制框架如图4所示。
步骤六中特征图维度映射的目的是将特征图中每个字符向量映射为维度与标签类型数相同的概率向量。步骤七中使用条件随机场输出预测序列的具体方法如下:
在实体识别任务中,标签之间普遍存在依赖关系。例如人名实体不会以“I-PER”作为起始;多数情况下,“B-PER”后面应该紧接“I-PER”,“I-PER”后面因该紧接“I-PER”或“O”。因此,在做序列标注时需要使用条件随机场构建标签之间的依赖关系,从而得到更合理的预测结果。
假设输入序列S对应输出序列y,其得分可以由下式算出。
其中U是状态转移矩阵,V是概率向量,n是标签类别数。
假设所有输出序列集合为Y
其中
由于正确序列y
-log(P(y
求出模型参数后,即可对文本序列进行解码,预测标签序列。最直观的方法是穷举所有可能的标签序列并计算出它们的得分,将得分最高的标签序列作为预测序列。该过程可以用维特比算法进行简化。
维特比算法是一种动态规划算法,其对于每个位置的字符,分别计算出与当前字符的各个标签组合后s(S,y)最大的标签序列y。因为虽然有多个标签序列可以与当前字符的各个标签组成新的标签序列,但只有与各个标签组合后得分最高的标签序列才是最有可能正确的标签序列。然后记录组合后s(S,y)最大的标签序列y以便最后进行回溯。当计算出最后一个字符对应的所有标签的分数后,得分最高的标签序列即为最合理的预测序列。
为验证本发明的准确性和鲁棒性,本发明在公开的Resume数据集和MSRA数据集上进行了实验。Resume数据集由[Zhang Y,Yang J.Chinese NER Using LatticeLSTM.InProceedings of the 56th Annual Meeting of the Association forComputational Linguistics,Vol.1,pp.1554-1564,2018.]发布,其中实体有八种类型,分别是人名、地名、组织机构名、国家名、教育机构名、职业、职称和种族背景。MSRA数据集由[Levow GA.The third international Chinese language processing bakeoff:Wordsegmentation and named entity recognition.InProceedings of the Fifth SIGHANWorkshop on Chinese Language Processing,pp.108-117,2006.]发布,其中实体有三种类型,分别是人名、地名和组织机构名。数据集详细数据统计如表2所示。
表2数据集详细数据统计
Resume数据集的类别是丰富的,并且实体间存在复杂的包含关系,例如职业、职称实体中往往包含组织机构名,因此在该数据集进行命名实体识别是具有挑战性的。MSRA数据集数据量较大,包含最常规的三种类别,且地名和组织机构名之间也存在复杂的包含关系,可以有效地测试模型在常用场景下的效果,具有代表性。
实验参数设置:
表3数据库实验参数设置
表4为本发明提出的方法在Resume数据集和MSRA数据集上的测试结果,本发明在这两个数据集上都取得了较高的识别率,分别是95.01%和93.02%。尽管这两个数据集的实体间存在复杂的包含关系,但本发明提出的方法对该问题具有很好的鲁棒性,因此表现相对较好。
表4在UCF101和Penn Action上的识别率
本发明提出的模型主要包含两个部分,多级残差卷积和注意力机制。从表5可以看出,针对Resume数据集,单纯使用由全连接层组成的基线网络,精度可达到92.96%。在基线网络中加入多级残差卷积,精度提升至94.30%。在此基础上再加入注意力机制,精度进一步提升至95.01%。实验结果显示,多级残差卷积可以有效地获取并融合不同范围内的局部上下文信息,而注意力机制则进一步获取全局上下文信息。这两种方法对命名实体识别的性能都产生了积极的影响,有效地提升了识别精度。
表5在Resume数据集上的两个方法的影响
上面结合附图对本发明的具体实施方式做了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 基于多级残差卷积与注意力机制的中文命名实体识别方法
- 基于注意力机制的残差型全卷积神经网络的医学图像分割方法