一种基于领域适应的少样本实体识别方法
文献发布时间:2023-06-19 11:19:16
技术领域
本发明涉及实体识别领域,尤其涉及一种基于领域适应的少样本实体识别方法。
背景技术
在文本信息抽取的应用场景中,场景多样、细化,缺少标注样本,标注样本获取成本高是工业应用上面临的现状,目前的技术针对少量标注样本的场景还没有成熟的方案,面对这样的现状,能否巧妙地利用现有标注资源,将模型学习到的知识迁移到少量样本场景下,是一个热门的研究方向。
目前的文本信息抽取方法中,基于模型训练的方法需要大量的标注样本,虽然有一些深度模型呈现准确度越来越高,需要的标注样本量越来越少的趋势,但仍然需要一定量的标注样本才能训练得到可用的模型,在获得样本前,无法开展工作,这样的过程相当于将开发成本转嫁到样本的标注上,整体开发效率仍然低下。
本发明用于实体抽取,利用相近领域的大量标注资源,在目标领域上不需要标注样本就可得到准确率较高的抽取模型。
发明内容
本发明目的在于针对现有技术的不足,提出一种基于领域适应的少样本实体识别方法,本发明用不同领域的语料之间的相同特征作为支点特征,建立领域间特征的映射,使得在具有大量标签的源领域上训练的模型能够在没有标签的目标领域上同样表现出良好的准确率,将其应用在实体识别任务上,在相似领域间的迁移学习中,能够得到无标签目标领域实体识别较高的准确率。
本发明的目的是通过以下技术方案来实现的:一种基于领域适应的少样本实体识别方法,该方法包括如下步骤:
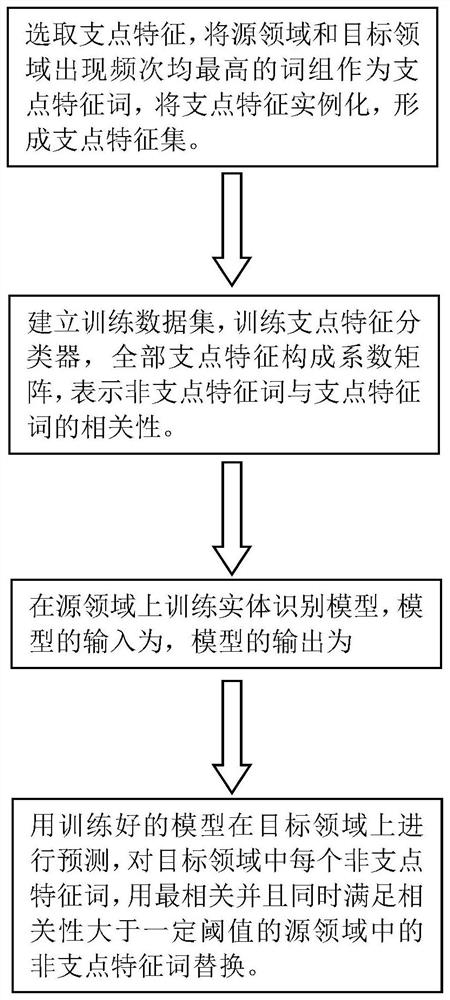
(1)选取支点特征
统计n-gram在源领域和目标领域的语料中出现的频次,选取在两个领域同时出现,且频次超过阈值词组作为支点特征词,通过支点特征词将模板“支点特征词w在右面”、“支点特征词w在左面”、“支点特征词w在中间”实例化,每个实例代表一个维度的支点特征,形成支点特征集,w表示文本句子中的支点特征词。
(2)建立训练数据集,训练支点特征分类器
将步骤(1)中的支点特征集作为训练数据集,训练一组预测样本句子中是否存在支点特征词的支点特征分类器,具体为:对每一维支点特征i训练一个逻辑回归模型作为支点特征分类器,对样本句子中的词判断是否存在支点特征,训练后得到逻辑回归模型的系数w
支点特征分类器的样本输入:计算两个领域全部句子的n-gram形成n-gram列表,每个句子的特征为n-gram列表中的词是否存在于句子中的支点特征词和非支点特征词的二值向量,然后去掉句子中全部支点特征词对应的维度,得到句子的特征向量。
支点特征分类器的样本输出:输出维度为1,由于计算了句子的n-gram特征,如果句子中的某个非支点特征词的左面或右面是支点特征词,那么句子必然至少包含了该支点特征词的2-gram,此时这条句子样本的标签为1,否则标签为0,同时在该支点特征词的w
(3)在源领域上训练实体识别模型
在源领域语料上训练实体识别模型,模型的输入为一个句子,输出为与句子长度相同的标签序列,标记了句子中每个字的类别。
(4)在目标领域上进行实体识别
用步骤(3)中训练好的模型在目标领域上进行预测,利用w矩阵中的相关性信息,对目标领域中每个非支点特征词,用与支点特征词最相关并且同时满足相关性大于一定阈值的源领域中的非支点特征词替换。
进一步地,所述源领域具有带标签语料和无标签语料,所述目标领域只含有无标签语料。
进一步地,所述n-gram中的n取值为2。
进一步地,步骤(2)中,w
进一步地,步骤(2)中,针对中文语料,对两个领域语料分词,取所有可能的分词结果形成lattice,之后对全部lattice词建立n-gram,再用步骤(1)过程建立样本,此时每个句子包含了句子中全部分词结果对应的n-gram。
进一步地,步骤(3)中,针对中文语料,用lattice分词作为输入。
进一步地,步骤(4)中,针对中文语料,将每个lattice分词对应的最相关的源领域中的非支点词替换。
进一步地,步骤(4)中,若预测结果替换时长度不一致,则应对造成的偏移进行处理。
本发明的有益效果:利用领域间共同的支点特征词得到领域间不同的非支点特征之间的对应关系,从而达到领域间特征词映射的目的,具有大量标注的源领域上训练的模型,可直接在没有标注的目标领域上使用。
附图说明
图1为本发明方法流程图。
具体实施方式
以下结合附图对本发明具体实施方式作进一步详细说明。
如图1所示,本发明提供的一种基于领域适应的少样本实体识别方法。本发明假设具备相近领域的相对充足的带标签语料和无标签语料,源领域具有带标签语料和无标签语料,目标领域只含有无标签语料。具体过程为:
(1)选取支点特征
统计n-gram(n一般取值为2)在源领域和目标领域的语料中出现的频次,选取在两个领域同时出现,且频次超过阈值(如100)词组作为支点特征词,阈值根据需求的识别的准确率选择,通过支点特征词将模板“支点特征词w在右面”、“支点特征词w在左面”、“支点特征词w在中间”实例化,每个实例代表一个维度的支点特征,形成支点特征集,w表示文本句子中的支点特征词。
(2)建立训练数据集,训练支点特征分类器
将步骤(1)中的支点特征集作为训练数据集,训练一组预测样本句子中是否存在支点特征词的支点特征分类器,如判断句子中是否包含“支点特征词w在字的右面”,具体为:对每一维支点特征i训练一个逻辑回归模型作为支点特征分类器,对样本句子中的词判断是否存在支点特征,训练后得到逻辑回归模型的系数w
支点特征分类器的样本输入:计算两个领域全部句子的n-gram形成n-gram列表,每个句子的特征为n-gram列表中的词是否存在于句子中的支点特征词和非支点特征词的二值向量,然后去掉句子中全部支点特征词对应的维度,得到句子的特征向量。
支点特征分类器的样本输出:输出维度为1,由于计算了句子的n-gram特征,如果句子中的某个非支点特征词的左面或右面是支点特征词,那么句子必然至少包含了该支点特征词的2-gram,此时这条句子样本的标签为1,否则标签为0,通过该2-gram大量出现的事实反映两个词的相关性,同时在该支点特征词的w
针对中文语料,对两个领域语料分词,取所有可能的分词结果形成lattice,之后对全部lattice词建立n-gram,再用步骤(1)过程建立样本,此时每个句子包含了句子中全部分词结果对应的n-gram。
(3)在源领域上训练实体识别模型
在源领域语料上训练实体识别模型,如lstm,模型的输入为一个句子,输出为与句子长度相同的标签序列,标记了句子中每个字的类别。针对中文语料,用lattice分词作为输入。
(4)在目标领域上进行实体识别
用步骤(3)中训练好的模型在目标领域上进行预测,利用w矩阵中的相关性信息,对目标领域中每个非支点特征词word_dst,寻找源领域中对应的非支点特征词word_src,具体地,筛选出与word_dst最相关并且同时满足相关性大于一定阈值如0.7的支点特征词集合word_pivots,再从源领域中找到与word_pivots中的词相关性分值之和最高的词,如果该相关性分值的平均值大于阈值如0.7,则用源领域中的非支点特征词word_src替换word_dst,否则不替换。例如源领域为糖尿病患者病历,目标领域为癌症患者病历,则可能将目标领域中的非支点特征词“肺癌”替换为源领域中的“糖尿病”。针对中文语料,将每个lattice分词对应的最相关的源领域中的非支点词替换。若预测结果替换时长度不一致,则应对造成的偏移进行处理。
上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
- 一种基于领域适应的少样本实体识别方法
- 一种基于领域适应的少样本文本分类方法