一种轻量级GPU云烘培Web3D实时全局光照渲染管线
文献发布时间:2023-06-19 11:26:00
技术领域
本发明涉及云计算、协作式渲染领域,特别是涉及实时全局光照协作式渲染管线。
背景技术
真实感渲染需要牵涉到大量的基于物理的计算。随着GPU硬件的不断发展,目前高端PC平台已经可以流畅的渲染次世代、强真实感3D场景。然而对于较低配置的平台(如移动设备、头戴式显示器),或者由于起步较晚尚无法利用最新GPU技术的Web平台,没有足够的能力进行此类复杂计算。如目前WebGL进度仍无法赶超OpenGL或DirectX,一些新的GPU特性,如通用计算GPGPU、几何着色器以及曲面细分等无法在Web3D应用中利用,极大的阻碍了Web3D场景渲染往更真实、更高效的阶段迈进。对于该问题,首先想到的是将所有渲染和交互计算放置云端的云计算、云游戏方案,有关该方法的理论和产品也大量涌现。
然而,大部分3D应用、电子游戏都是软实时系统。这意味着,此类系统对延时非常敏感。网络波动会非常明显地体现在应用画面上,或延迟数秒才反馈用户交互或降低画面分辨率,影响用户地体验。而且,云游戏方案大部分都是基于视频流式传输画面,客户端设备仅进行视频解码、服务器网络通讯等简单操作中,没有完全利用客户端地运算性能。
发明内容
面对以上问题,本发明公开一种轻量级GPU云烘培Web3D实时全局光照渲染管线,前端充分利用有限的运算性能完成轻量级的场景直接光照计算,以及用户交互逻辑相应,复杂的全局光照数据由云端计算、流式传输而得,保证用户的流畅体验的同时增强了画面表现力。
为实现上述目的,本发明提供了如下方案:
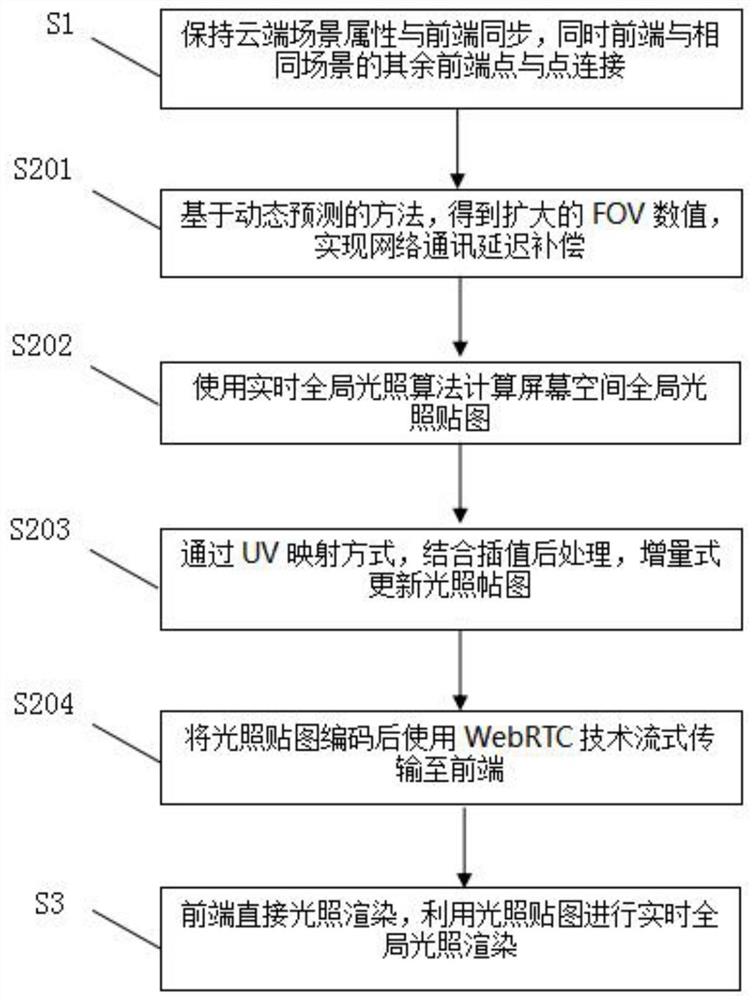
一种轻量级GPU云烘培Web3D实时全局光照渲染管线,应用于全局光照协作式渲染系统,所述渲染系统由负责全局光照的云端和负责直接光照的前端构成,所述云端与前端之间通过WebSocket与WebRTC通信连接,所述渲染管线的实现方法包括以下步骤:
S1,保持云端场景属性与前端同步,同时前端与相同场景的其余前端点对点连接;
S2,云端基于GPU加速Lightmap烘培,对全局光照进行处理,具体包括:
S201,基于动态预测的方法,得到扩大的FOV数值,实现网络通讯延迟补偿;
S202,使用实时全局光照算法计算屏幕空间全局光照贴图;
S203,通过UV映射方式,结合插值后处理,增量式更新光照帖图;
S204,将光照贴图编码后使用WebRTC技术流式传输至前端;
S3,前端直接光照渲染,利用光照贴图进行实时全局光照渲染。
进一步的,所述的步骤S1中,保持云端场景属性与前端同步,同时前端与相同场景的其余前端点对点连接,具体包括:
统一云端与前端的场景模型,包括命名统一、层级关系统一、单位统一、格式统一、方向统一、模型UV通道数量及数据统一;
云端与前端之间,建立WebSocket、WebRTC连接,云端将已建立连接的相同场景的其他前端列表传输至指定的前端;
指定的前端与相同场景的其他前端之间通过WebRTC建立点对点连接;
云端与相同场景的其他前端并行传输改动前的轻量化原始场景;
指定的前端将改动的场景数据,包括模型方向、位置、材质信息、光源方向、位置、光强、颜色信息和当前时间信息,通过WebSocket传递至云端,云端根据传递数据修改场景。
进一步的,所述的步骤S201,基于动态预测的方法,得到扩大的FOV数值,实现网络通讯延迟补偿,具体包括:
基于场景帧画面数据、Lightmap全局光照辐照度数据、场景模型网络数据,使用关注度算法计算出当前帧、上一帧、上上帧关注点位置;
输入当前帧、上一帧、上上帧关注点位置,使用Dead Reckoning算法计算出下一帧关注点位置,以此为中心建立相机平截头体,计算出相机方向D′
输入当前帧、上一帧、上上帧相机方向、位置信息,使用Dead Reckoning算法计算出下一帧相机方向D″
D
F
其中,a、b为权重系数,取值为a,b∈[0.0,1.0]且a+b=1.0,权重比例根据相应的Dead Reckoning以及关注度算法手动调节;
以相机当前帧、下一帧方向与位置数据建立平截头体,计算当前帧、下一帧相机远平面右上角的点P
根据以下公式计算得到扩大的FOV数值:
其中,α为初始FOV大小,默认值为60°,v
进一步的,所述的步骤S202,使用实时全局光照算法计算屏幕空间全局光照贴图,具体包括:
基于当前帧相机方向、位置信息以及扩大后的FOV进行实时全局光照的计算;
使用基于GPU加速的实时全局光照算法烘培屏幕空间全局光照贴图;
实时全局光照最终输出的屏幕空间全局光照贴图格式包含三个或四个通道,其中三个通道存放全局光照漫反射辐照度数据,第四个通道存放全局光照镜面反射辐照度亮度数据;
对得到的屏幕空间全局光照贴图数据进行线性化处理。
进一步的,所述的步骤S203,通过UV映射方式,结合插值后处理,增量式更新光照帖图,具体包括:
场景所有模型需预先UV参数化,将所有UV坐标数据合并成图集,并缩放、拉伸至u≥0,v≤1范围内,存储于模型第二套UV通道中;
计算第二套UV的屏幕空间贴图,其分辨率需与实时全局光照计算的屏幕空间全局光照贴图长宽比例一致;
对每一个像素,采样第二套UV屏幕空间贴图得到UV数据,采样屏幕空间全局光照贴图得到辐照度数据,将辐照度数据存入上一帧光照贴图中以UV数据为索引的像素中;
第二套UV的屏幕空间贴图、屏幕空间全局光照贴图、光照贴图存储内容均为线性数据;
定义1:RGBA值为(0,0,0,0)的像素为非法像素;
定义2:除非法像素以外的像素为合法像素;
对光照贴图使用Pull-Push方法插值,为仅插值光照贴图中的非法像素;
在Pull阶段建立一个自下而上的图像金字塔,上一层的图像尺寸为下一层的一半,每一个合法像素的颜色值为上一层周围四个合法像素的平均值;
在Push阶段从上往下逐层对每个非法像素进行填充,每个非法像素的颜色值是当前层级的Pull图像和上一层级Push图像中该非法像素周围的颜色值进行加权平均;
对光照贴图使用高斯模糊后处理,减轻闪烁问题。
进一步的,所述的步骤S204,将光照贴图编码后使用WebRTC技术流式传输至前端,具体包括:
云端将当前帧光照贴图编码至H.264视频流;
云端将H.264视频流通过WebRTC传输至前端;
前端解码H.264视频流,获取当前帧光照贴图。
进一步的,所述的步骤S3,前端直接光照渲染,利用光照贴图进行实时全局光照渲染,具体包括:
前端片段着色阶段使用模型第二套UV采样光照贴图,得到间接光照辐照度值,计算直接光照漫反射、镜面反射数值,根据基于物理的渲染公式计算最终颜色值,具体公式如下:
f
其中,E
本发明提供的轻量级GPU云烘培Web3D实时全局光照渲染管线,公开了以下技术效果:
1)本发明使用视点无关的Lightmap作为渲染管线的存储和传输数据结构,Lightmap满足流式传输需要的相关性特征,与主流的视频传输格式(如H.264,H.265)相结合,同时Lightmap也具有视点无关的特性,这意味着场景中所有物体的表面光照信息都存放于Lightmap中,相机视角发生改变时Lightmap的存储结构不会发生改变,也不需要重新全部计算,当前端渲染管线接受到Lightmap时,仅需要采样Lightmap,即可获取需要的光照参数,以完成全局光照的照明,最后,由于Lightmap在渲染管线的着色器中进行光照还原,所以不会像使用视点相关技术的方法那样产生重影的伪像;
2)本发明对于分布式渲染管线通讯造成的网络延迟问题,使用视点预测的方法预测Web端当前视点位置,依据此数据扩大FOV,从而渲染更多的物体,当用户在场景中漫游时,对于全局光照部分,无需向传统的全局光照烘培器那样一次烘培出一张完整的Lightmap,仅需要烘培相机可见部分即可,为此,使用延迟处理后的相机渲染一张低分辨率的屏幕空间光图作为增量,通过UV映射到Lightmap中,完成增量更新,以达到降低全局光照计算量,较少服务器负载,同时效果也不会有过多的失真,另外,该方法可以有效解决Lightmap生成时的接缝问题,无需进行额外的后处理步骤。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例轻量级GPU云烘培Web3D实时全局光照渲染管线的流程示意图;
图2为本发明实施例实时全局光照协作式渲染系统的系统架构图;
图3为本发明实施例云端基于GPU加速Lightmap烘培对全局光照进行处理的流程图;
图4为本发明实施例网络延迟与最终效果影响图;
图5为本发明实施例低分率下的屏幕空间全局光照图对最终输出的光照贴图效果影响图;
图6为本发明实施例实时全局光照协作式渲染系统客户端帧率。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种轻量级GPU云烘培Web3D实时全局光照渲染管线,能够拆分渲染任务,将复杂的全局光照计算任务分配至云端执行,渲染数据传输到前端,与前端轻量级渲染数据结合,从而增强低运算性能设备的渲染能力。使Web3D场景的光照水平不局限于单次反弹的直接光照,更有光线在场景中数次反弹,物体与物体互相照明的光照,让Web3D的渲染效果达到次时代水准。同时,将用户交互逻辑放至前端执行,同时在前端执行部分轻量级的渲染任务(如直接光照),保证系统及时响应用户反馈,在网络情况不理想的情况下也能提供足够的渲染信息,提升用户体验。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
如图1和图2所示所示,本发明提供的轻量级GPU云烘培Web3D实时全局光照渲染管线,应用于全局光照协作式渲染系统,所述渲染系统由负责全局光照的云端和负责直接光照的前端构成,所述云端与前端之间通过WebSocket与WebRTC通信连接,所述渲染管线的实现方法包括以下步骤:
S1,保持云端场景属性与前端同步,同时前端与相同场景的其余前端点对点连接;
S2,云端基于GPU加速Lightmap烘培,对全局光照进行处理,具体包括:
S201,基于动态预测的方法,得到扩大的FOV数值,实现网络通讯延迟补偿;
S202,使用实时全局光照算法计算屏幕空间全局光照贴图;
S203,通过UV映射方式,结合插值后处理,增量式更新光照帖图;
S204,将光照贴图编码后使用WebRTC技术流式传输至前端;
S3,前端直接光照渲染,利用光照贴图进行实时全局光照渲染。
其中,所述的步骤S1中,保持云端场景属性与前端同步,同时前端与相同场景的其余前端点对点连接,具体包括:
统一云端与前端的场景模型,包括命名统一、层级关系统一、单位统一、格式统一、方向统一、模型UV通道数量及数据统一;
云端与前端之间,建立WebSocket、WebRTC连接,云端将已建立连接的相同场景的其他前端列表传输至指定的前端;其中,前端云端建立WebSocket连接,之后前端云端建立WebRTC连接,若前端网络环境无法有效的P2P穿透则重新连接,直至前端远端连接成功;
指定的前端与相同场景的其他前端之间通过WebRTC建立点对点连接;
云端与相同场景的其他前端并行传输改动前的轻量化原始场景;
指定的前端将改动的场景数据,包括模型方向、位置、材质信息、光源方向、位置、光强、颜色信息和当前时间信息,通过WebSocket传递至云端,云端根据传递数据修改场景。
所述的步骤S201,基于动态预测的方法,得到扩大的FOV数值,实现网络通讯延迟补偿,具体包括:
基于场景帧画面数据、Lightmap全局光照辐照度数据、场景模型网络数据,使用关注度算法计算出当前帧、上一帧、上上帧关注点位置;
输入当前帧、上一帧、上上帧关注点位置,使用Dead Reckoning算法计算出下一帧关注点位置,以此为中心建立相机平截头体,计算出相机方向D′
输入当前帧、上一帧、上上帧相机方向、位置信息,使用Dead Reckoning算法计算出下一帧相机方向D″
D
F
其中,其中,a、b为权重系数,取值为a,b∈[0.0,1.0]且a+b=1.0,权重比例根据相应的Dead Reckoning以及关注度算法手动调节;
以相机当前帧、下一帧方向与位置数据建立平截头体,计算当前帧、下一帧相机远平面右上角的点P
根据以下公式计算得到扩大的FOV数值:
其中,α为初始FOV大小,默认值为60°,v
设置当前相机FOV值为步骤S201最后计算得到的FOV值;使用基于体素化的实时全局光照算法烘培出一张分辨率为1920*1080的屏幕空间全局光照贴图。
所述的步骤S202,使用实时全局光照算法计算屏幕空间全局光照贴图,具体包括:
基于当前帧相机方向、位置信息以及扩大后的FOV进行实时全局光照的计算;
使用基于GPU加速的实时全局光照算法烘培屏幕空间全局光照贴图;
实时全局光照最终输出的屏幕空间全局光照贴图格式包含三个或四个通道,其中三个通道存放全局光照漫反射辐照度数据,第四个通道存放全局光照镜面反射辐照度亮度数据;
对得到的屏幕空间全局光照贴图数据进行线性化处理。
如图3所示,在具体实施例中,所述的步骤S203,通过UV映射方式,结合插值后处理,增量式更新光照帖图,具体包括:
(1)基于当前相机视角渲染场景,输出一张分辨率为1920*1080的贴图,其格式为RGFloat,R通道内容为屏幕像素对应的模型第二套UV的U坐标值,R通道内容为屏幕像素对应的模型第二套UV的V坐标值;
(2)对每一个像素,采样(1)中输出的贴图得到UV数据,采样步骤S3输出的贴图得到辐照度数据,将辐照度数据存入上一帧光照贴图中以UV数据为索引的像素中,光照贴图的分辨率为1024*1024;
(3)定义1:RGBA值为(0,0,0,0)的像素为非法像素;
定义2:除非法像素以外的像素为合法像素;
对光照贴图使用Pull-Push方法插值,为仅插值光照贴图中的非法像素;
(4)在Pull阶段建立一个3层、自下而上的图像金字塔,上一层的图像尺寸为下一层的一半,每一个合法像素的颜色值为上一层周围四个合法像素的平均值;
(5)在Push阶段从上往下逐层对每个非法像素进行填充。每个非法像素的颜色值是当前层级的Pull图像和上一层级Push图像中该非法像素周围的颜色值进行加权平均。
(6)对光照贴图使用高斯模糊后处理,模糊半径为5。
所述的步骤S204,将光照贴图编码后使用WebRTC技术流式传输至前端,具体包括:
(1)云端将使用Nvidia Video Code将当前帧光照贴图GPU硬件编码至H.264视频流;
(2)云端将H.264视频流通过WebRTC传输至前端;
(3)前端使用HTML5
所述的步骤S3,前端直接光照渲染,利用光照贴图进行实时全局光照渲染,具体包括:
前端进行PBR真实感渲染时,首先计算在片段着色阶段直接光照漫反射、镜面反射数值,然后使用模型第二套UV采样光照贴图,得到间接光照辐照度值,根据基于物理的渲染公式计算最终颜色值,具体公式如下:
f
其中,E
如图4评估了Sponza场景下,步骤S201所提出的相机延迟处理方法提升最终渲染效果,效果评估指标为结构相似性指标(Structural Similarity Index,SSIM),参考图为0ms延迟下的最终画面。
如图5评估了不同分辨率下屏幕空间全局光照贴图进行步骤S203后对最终画面的效果影响,指标同样为结构相似性指标,场景为Sponza,Conference,Sibenik。参考图为不采用步骤S203,完整烘培的光照贴图。
图6记录了实施例实时全局光照协作式渲染系统客户端运行时帧率变化。使用Sponza、Conference、Sibenik作为测试场景,截取了Web客户端加载场景,并于服务器建立连接以后的20秒帧率变化。图6中可以看出,前端帧率始终维持在30帧以上,在30-45帧之间浮动。FPS浮动的主要原因在于视频解码阶段比较消耗GPU性能,对于GPU性能不那么理想的移动平台来说,会占用较大的GPU资源。
本发明提供的轻量级GPU云烘培Web3D实时全局光照渲染管线,由负责全局光照的云端渲染系统和负责直接光照的前端系统构成,同时前端与相同场景的其余前端点对点连接;云端借助强大的GPU性能,负责计算量较大的全局光照计算任务,云端首先通过基于预测的方法动态扩大FOV,降低延时造成的问题,接着创新性地使用实时全局光照计算得到的低分辨率下的屏幕空间全局光照贴图,通过UV映射方式,结合插值方法,完成增量式的光照贴图更新,最终将该光照贴图编码后使用WebRTC技术流式传输至前端;前端系统仅负责交互逻辑处理与直接光照计算,间接光照数据通过解码光照贴图得到。本发明能够拆分渲染任务,将复杂的全局光照计算任务分配至云端执行,渲染数据传输到前端,与前端轻量级渲染数据结合,从而增强低运算性能设备的渲染能力。本发明使Web3D场景的光照水平不局限于单次反弹的直接光照,更有光线在场景中数次反弹,物体与物体互相照明的光照,让Web3D的渲染效果达到次时代水准。同时,将用户交互逻辑放至前端执行,同时在前端执行部分轻量级的渲染任务(如直接光照),保证系统及时响应用户反馈,在网络情况不理想的情况下也能提供足够的渲染信息,提升用户体验。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本申请中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 一种轻量级GPU云烘培Web3D实时全局光照渲染管线
- 一种面向Web3D的人造模型网页轻量级可视化方法