高通量测序数据的变异路径图表示方法及其生成方法
文献发布时间:2023-06-19 11:27:38
技术领域
本发明涉及高通量测序数据的分析与应用领域,具体地说,是一种高通量测序数据的变异路径图表示方法及其生成方法。
背景技术
高通量测序是现代生物医学研究和应用领域的常用技术。高通量测序的结果是大量的短片段序列信息,称为“读段”。目前常见的读段形式为一对字符串,长度为100-150。其中一个字符串由A、T、C、G组成,代表所测得的序列;另一个字符串由序列的每个位置对应的测序质量数值转化而成的字符组成。高通量测序数据的分析流程,一般需要首先将这些读段的序列,比对到参考基因组的相应位置。然后,依据参考基因组上特定的位置被多少读段覆盖(即覆盖深度)、参考基因组与测得序列在对应位置上的差异,计算一系列生物医学指标,例如:基因表达量、转录因子结合位置、表观遗传修饰位置、基因变异、蛋白变异、可能的新抗原(肽段变异)等。
目前这一主流的分析流程存在一定缺陷,主要是:1)由于测序对象的基因组存在个体差异,一部分测序对象特有的基因组序列在参考基因组上不存在,因此这部分测序数据无法比对到参考基因组上。于是,与测序对象特有基因组序列相关的序列特征,无法进入后续分析流程的视野,成为生物医学研究与应用的盲区。这一缺陷在与肿瘤相关的研究与应用中非常重要。肿瘤的成因有很大可能是由于患者的个体特异的基因组区域发生了变异,而这些变异无法利用基于参考基因组的分析流程发现。2)目前,将测序读段比对到参考基因组上的软件工具普遍存在一定的设计局限:通过比对参考基因组的方法,很难有效地发现染色体结构变异(例如,测序对象的基因组相对于参考基因组发生了大片段的序列重排等)。染色体结构变异对基因功能往往造成较大的影响。基于参考基因组的方法在染色体结构变异发现中的效率不足,也是目前肿瘤和其它疾病机制研究的瓶颈之一。
另一方面,通过高通量测序数据可以拼接得到测序对象的基因组。这一方法可以得到测序对象的特有基因组序列。但是,由于基因组的结构复杂,现有的序列拼接工具通常仅给出一组最可能的基因序列。这些序列依据经验可能性选出,并不能完整地表示真实测序数据中包含的全部序列变异信息。因此,利用目前的拼接工具得到的测序对象的个体化基因组序列,仍具有信息损失。此外,利用拼接得到的个体化基因组作为参考基因组进行后续的分析,仍然受制于上述基于参考基因组的分析流程的第二个局限。
目前,常用基因组拼接工具的基本算法是德布鲁因图(de Bruijn Graph)。在德布鲁因图中,每一个读段的序列字符串被切分成长度为K的小片段,称为K串。具有相同序列的K串被认为是基因组上的同一座位(因此,本发明中也称K为分辨率参数)。以每一个K串为一个节点,如两个K串具有重叠的(K-1)个字符,那么它们之间存在一条边。通过这种方法,每个读段均可被映射成德布鲁因图中的一条路径。于是,序列拼接问题转化为在德布鲁因图中寻找一组包含所有读段的路径的问题。虽然利用德布鲁因图可以完整地表示高通量测序数据,但是一个分辨率足够高(K足够大)的德布鲁因图的节点数过多(几乎等于整个基因组的位点数),遍历该图非常困难;同时,图中每个节点记录的序列均与其相邻节点记录的序列有K-1个长度的字符重复,导致储存空间的低效使用。由于这两个问题的存在,直接基于德布鲁因图进行不依赖参考基因组的测序数据分析非常低效,计算成本过高,很难实际使用。
高通量测序数据的标准格式是FASTQ。FASTQ文件的一个单元表示一个读段。每个单元占用4行空间。第一行为读段的名称,第二行为读段的序列信息,第三行为一个“+”符号,第四行为读段的质量信息。第二行与第四行具有相同的长度。第二行特定位置的字符的测序质量对应于第四行相同位置的字符。对于双端测序的样本,一个样本有两个FASTQ文件,其中的读段分别对应检测到的核酸分子的首部和尾部的序列及其测序质量。
发明内容
为克服上述现有高通量测序数据分析方法的不足,本发明设计了一种高通量测序数据的变异路径图表示方法及其生成方法,利用变异路径图可以表示来自多个样本的全部高通量测序数据的读段之间的位置对应关系(而不仅仅是那些能够匹配到参考基因组上的读段之间的位置对应关系)。变异路径图记录图中的每个“路径片段”的序列由哪些样本的哪些读段的哪些片段覆盖。这些信息可以简便、直观地与现有测序数据分析工具对接,用于后续的生物学特征分析。整体来说,变异路径图是原始测序数据的另一种表示形式,信息在从原始测序数据到变异路径图的转化过程中无损失。将原始测序数据转化为变异路径图,可以方便地对接后续的生物学特征分析,包括基因表达量、转录因子结合位置、表观遗传修饰位置、基因变异、蛋白变异、可能的新抗原(肽段变异)等分析。
本发明通过以下技术方案来实现的:
本发明公开了一种测序数据的变异路径图的具体表示方法,变异路径图包括路径片段和切点,路径片段由一组路径单元从左至右顺序连接组成,路径片段代表一个长度大于等于1的任意序列,路径片段与路径单元的首尾均由切点标记。
作为进一步地改进,本发明所述的路径片段带有一组附加信息:该路径片段的序列的哪个片段,被原始测序数据中的哪个读段覆盖,以及该路径片段的序列的片段与覆盖它的读段的序列的片段之间的对应关系;
路径单元代表一个长度大于等于1的任意序列,是用于组装路径片段的基础数据结构,仅在计算的中间过程中使用,在最终的变异路径图中不呈现;
切点是一个编号,代表路径单元之间的连接,一个路径单元的尾部切点与另一个路径单元的首部切点编号相同,则这两个路径单元从左至右连接;
变异路径图具有分辨率参数K,即变异路径图中,任意连续的(K-1)个字符(可以跨越路径片段)组成的序列不一致;若原始测序数据中,两个读段有(K-1)个连续字符相同,则这两个读段中的这两个(K-1)长度的片段覆盖变异路径图中的同一个长度为(K-1)个字符的路径,该路径可能跨越多个相互连接的路径片段。
作为进一步地改进,当路径片段(或路径单元)的首或尾可连接至少两个路径片段(或路径单元)或不能连接任何路径片段(或路径单元)时,该路径片段(或路径单元)的首或尾切点称为一个路径的分叉点。
本发明还公开了一种测序数据的变异路径图的具体生成方法,利用对切点的识别和追踪,建立“变异路径图中路径片段(或路径单元)的分叉点”、“变异路径图中路径片段序列内部对应于原始测序读段的起点或终点的位置(即路径单元的起点或终点)”与“原始测序读段内序列的位置坐标”之间的关联,利用这一关联实现高效的分布式拼接。
作为进一步地改进,步骤为:首先扫描所有原始测序数据的读段序列,生成所有可能的长度为(K-1)的子序列,并记录该子序列左、右侧的字符,然后将这些长度为(K-1)的子序列聚类,依据每一类长度为(K-1)的子序列的左侧或右侧字符的可能性,识别切点在原始读段序列中的位置,将原始读段序列拆分成由切点标记首尾位置的小片段,再将这些小片段按首尾切点和序列归集,生成路径单元,然后将不分叉的路径单元首尾连接,形成路径片段,得到变异路径图。
作为进一步地改进,本发明的具体包含以下步骤:
1)对每个原始测序读段,从左到右依次扫描其序列中存在的长度为(K-1)的字符串,生成(K-1)串对象;
2)将步骤1)生成的所有(K-1)串对象,按照其(K-1)长度的字符串聚簇,对每一簇的(K-1)串对象,分配一个独一无二的簇ID(正整数),然后分析每一簇的(K-1)串对象,获得切点-读段位置对象;
3)将步骤2)生成的全部切点-读段位置对象,按其来源读段编号聚簇;然后分析每一簇的切点-读段位置对象,生成路径单元-读段位置对象;
4)将步骤3)生成的全部路径单元-读段位置对象,按起始切点ID,结束切点ID,路径单元序列的三元组聚簇;然后将每一簇路径单元-读段位置对象,映射为一个路径单元对象;
5)对上一步骤生成的全部路径单元对象,执行归并等价切点ID的操作;
6)执行左切点对齐操作,执行右切点对齐操作;
7)重复步骤6),直到在步骤6)的执行过程中,每个聚簇仅包含一个路径单元对象;
8)依据步骤7)生成的路径单元对象,生成路径片段内部切点集,路径片段内部切点指向前、向后均只连接一个路径单元(即不分叉)的切点;
9)将步骤7)生成的路径单元对象映射为未连接的路径片段对象;
10)、将步骤9)生成的未连接的路径片段对象进行连接;
11)、经上述步骤生成的,完全连接后的路径片段对象集,构成一个对原始测序数据的变异路径图表示;路径片段对象包含其左侧和右侧的切点ID信息,以及该路径片段序列的哪个部分被原始测序数据读段序列的哪个片段覆盖的信息。
本发明还公开了另一种测序数据的变异路径图的具体生成方法,当测序数据集非常大时,将海量的原始测序数据拆分为不同的部分,对每个部分的原始测序数据分别构建变异路径图,再将所得的变异路径图合并,得到全部测序数据或特定测序数据的变异路径图。
作为进一步地改进,本发明所述的合并两个变异路径图的具体步骤如下:
1)对两个变异路径图中的路径片段的每个位置给予唯一的位置编号;
2)将两个变异路径图分别视为一个读段,扫描得到两个读段中所有的长度为(K-1)的字符串,生成(K-1)串对象,字符串可能从任意一个路径片段中的任意位置开始,以任意路径跨越路径片段的边界;(K-1)串对象不再记录其来源读段的全序列信息,但记录该(K-1)串在读段上的结束位置;
3)将步骤2)生成的(K-1)串对象,按照其(K-1)长度字符串聚簇,对每一簇的(K-1)串对象,分配一个独一无二的簇ID(正整数),然后分别分析每一簇的(K-1)串对象,直接使用(K-1)串对象记录的该(K-1)串在来源读段上的结束位置信息,而不是基于其起始位置计算结束位置,获得切点-读段位置对象;同时,切点-读段位置对象需记录切点两侧的字符,但不记录来源读段全序列,切点两侧的字符可依据(K-1)串对象记录的信息获得;
4)将步骤3)生成的全部切点-读段位置对象,按其来源读段编号聚簇;然后分别分析每一簇的切点-读段位置对象,执行操作以生成路径单元-读段位置对象;在生成路径单元-读段位置对象时,不记录路径单元序列,但记录路径单元的第一个和最后一个字符;
5)将步骤4)生成的全部路径单元-读段位置对象,按起始切点ID,结束切点ID,路径单元的首、尾字符的四元组聚簇;然后将每一簇路径单元-读段位置对象,映射为一个路径单元对象;在生成路径单元对象时,不记录路径单元序列,但记录路径单元的第一个和最后一个字符;
6)对上一步骤生成的全部路径单元对象,执行归并等价切点ID的操作;
7)依据步骤6)生成的路径单元对象,生成路径片段内部切点集,路径片段内部切点指向前、向后均只连接一个路径单元(即不分叉)的切点;
8)将步骤6)生成的路径单元对象映射为未连接的路径片段对象,这时,路径单元的路径单元序列的长度可依据其来源读段位置表中任意一条记录的来源读段起始位置与来源读段结束位置的距离进行计算;
9)、将步骤8)生成的未连接的路径片段对象进行连接;
10)、经上述步骤生成的,完全连接后的路径片段对象集,其路径片段的起始与结束位置必与原变异路径图中的某个路径片段的起始位置或结束位置对应,即合成的变异路径图的路径片段必是原变异路径图中路径片段的拆分,依据这种对应关系,可将原变异路径图中路径片段的来源读段映射表转换为合成的变异路径图中路径片段的来源读段映射表;
11)、经上述步骤生成的路径片段对象集,是合并两个变异路径图的结果,构成一个对合并后的原始测序数据的变异路径图表示;路径片段对象包含其左侧和右侧的切点ID信息,以及该路径片段序列的哪个部分被合并后的原始测序数据读段序列的哪个片段覆盖的信息。
本发明具有以下创新点:
1)定义了变异路径图的数据结构,包括路径片段、路径单元、切点;以及变异路径图表示原始测序数据读段的方法。
2)提出了识别切点的方法,以及建立切点在“变异路径图上的位置”与在“原始测序数据读段上的位置”之间的对应关系的方法。
3)提出了通过切点的追踪,将读段拆分成覆盖不同路径单元的小片段,再归集成为路径单元、连接成为路径片段,最后得到变异路径图的拼接方法。
本发明的有益效果如下:
1)由于从原始测序数据转化到变异路径图的过程无需匹配参考基因组,因此无法匹配到参考基因组的那部分原始测序数据的信息不会损失。基于变异路径图的后续数据分析不但能够观察到可以定位于参考基因组上的序列特征,还能够观察到不能定位于参考基因组上的(样本个体或分组特异的)序列特征。
2)变异路径图可表示来自多个组别,多个样本的测序数据的读段间对应关系。依据每个“路径片段”的序列由哪些样本的哪些读段的哪些片段覆盖,可以不依赖参考基因组提供的坐标体系,比较并报告不同样本或分组间的序列特征差异,包括序列突变、转录本(或肽段)表达差异、表观修饰位置差异、转录因子结合位点差异等。
3)与FASTQ格式或德布鲁因图格式的测序数据相比,变异路径图几乎没有数据冗余,且可以直接计算:a)特定序列被哪些样本的多少读段覆盖,b)这些读段的这些区域的测序质量特征,c)特定序列的前后是否存在分叉,d)这些分叉分别被来自哪些样本的多少读段支持。上述四个特征是几乎所有现有测序数据生物学特征分析工具的分析依据。变异路径图以紧致、直观的方式提供后续分析的充分依据,可以方便地对接现有分析工具,完成后续的生物学特征分析。
4)变异路径图的生成方法可以设计为符合Map-Reduce模式的算法(详见具体实施方式部分),因此可以利用现有的大数据分析工具(如Spark等),以简洁的方式实现。这一实现方式计算效能高,能够处理传统实现方式无法处理的海量测序数据,并可使用较大的分辨率参数K进行计算。随着底层大数据分析框架的迭代优化,本发明设计的算法的执行效率也会随之不断提高。
附图说明
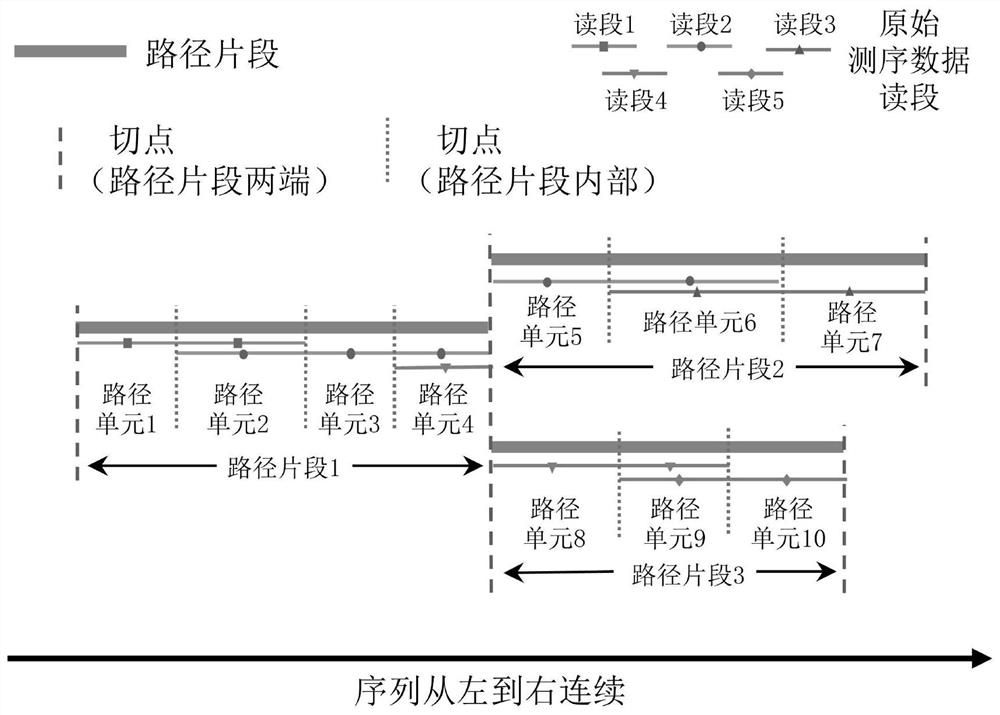
图1是本发明所述的变异路径图与原始高通量测序数据读段之间的关系图。
具体实施方式
本发明公开了一种高通量测序数据的变异路径图表示方法及其生成方法,图1是本发明所述的变异路径图与原始高通量测序数据读段之间的关系图,变异路径图包括路径片段和切点,路径片段包括路径单元,路径片段与路径单元的首尾均由切点标记,一个路径片段的尾切点与另一个路径片段的首切点相同,则它们从左向右连接。一个路径片段的首尾可连接多个路径片段或不连接路径片段,称为“路径分叉”,路径片段由“路径单元”连接而成,路径单元的首尾同样由切点标记,一个路径单元的尾切点与另一个路径单元的首切点相同,则它们从左向右连接;路径片段内部的路径单元按顺序一对一连接,不分叉。路径片段的第一个和最后一个路径单元可能不连接其它路径单元,或连接分别属于其它路径片段的多个路径单元,原始测序数据中的一个读段覆盖变异路径图中唯一的一条路径,每个读段的起点和终点位置必对应一个切点,如果在两个读段中,存在一个长度为(K-1)的相同子序列,但临接该相同子序列的左(或右)侧字符不同,则这两个读段的相同子序列的左(或右)侧位置对应变异路径图中相同的一个切点(即路径分叉处的切点,如图1中路径片段1、2、3之间的切点)。若两个读段中,存在一个长度为(K-1)的相同子序列,则该相同子序列覆盖变异路径图中相同且唯一的一段路径。
根据上述定义,可以通过如下方法识别切点:首先扫描所有原始测序数据的读段序列,生成所有可能的长度为(K-1)的子序列,并记录该子序列左、右侧的字符,然后将这些长度为(K-1)的子序列聚类,如果某个子序列左侧不存在任何字符,或者存在2个以上不同的字符,或者某个读段的起始是这个子序列,则该子序列的左侧存在一个切点,每个包含该子序列的读段中,该子序列的左侧存在一个相同的切点。类似的,如果某个子序列右侧不存在任何字符,或者存在2个以上不同的字符,或者某个读段的结束是这个子序列,则该子序列的右侧存在一个切点,每个包含该子序列的读段中,该子序列的右侧存在一个相同的切点。
由于读段序列的首部和尾部所对应的变异路径图位置必是切点位置,因此,变异路径图中任意一对相邻切点中间的部分(一个路径单元)必然能被某读段完整覆盖;且任意一个读段的序列必然可由首尾相连的一组路径单元拼接而成,这组路径单元可能分属于不同的路径片段,如图1中的读段2,读段4。基于上述特性,首尾切点相同且中间序列相同的原始读段中的序列片段,必覆盖变异路径图中相同的路径单元。因此,可以依据上一步得到的切点在原始读段序列中的位置,将原始读段序列拆分成由切点标记首尾的小片段;再将这些小片段按首尾切点和序列归集,生成路径单元,每个路径单元包含该路径单元被哪些原始读段的哪些片段覆盖的信息;然后将不分叉的路径单元首尾连接,形成路径片段(同时生成该路径片段的哪些部分被哪些原始读段的哪些片段覆盖的信息),得到变异路径图。
下面通过具体实施案例对本发明的技术方案作进一步地说明:
本发明公开了一种测序数据的变异路径图的具体表示方法,变异路径图包括路径片段和切点:
1)路径片段代表一个长度大于等于1的任意序列,每个路径片段带有一组附加信息:该路径片段的序列的哪个片段,被原始测序数据中的哪个读段覆盖,以及该路径片段的序列的片段与覆盖它的读段的序列的片段之间的对应关系;
2)切点是一个编号,代表路径片段之间的连接方式,每个路径片段的序列的起始处和结束处各有一个切点,当一个路径片段(A)的结束切点编号与另一个路径片段(B)的起始切点编号相同,则表示变异路径图中,A路径片段以从左到右的方式连接B路径片段。一个路径片段在其起始处和结束处均可以连接多个其它的路径片段(即路径分叉)。一个路径片段的起始和结束处也可以不连接任何其它路径片段(即变异路径图的起点和终点,也称为路径分叉)。
3)每个路径片段由一组“路径单元”从左至右顺序连接组成。路径单元类似于路径片段,每个路径单元代表一个长度大于等于1的任意序列,其左侧和右侧各有一个切点。如果一个路径单元(X)的结束切点编号与另一个路径单元(Y)的起始切点编号相同,则表示变异路径图中,X路径单元以从左到右的方式连接Y路径单元。一个路径片段的起始切点即组成该路径片段的最左侧的路径单元的起始切点;一个路径片段的结束切点即组成该路径片段的最右侧的路径单元的结束切点。每个路径单元仅能唯一地从属于一个路径片段;在一个路径片段内,所有路径单元仅从左到右顺序连接,不存在分叉。路径单元是用于组装路径片段的基础数据结构,仅在计算的中间过程中使用,在最终的变异路径图中不呈现。
4)变异路径图具有分辨率参数K(K为自然数),即变异路径图中,任意连续的(K-1)个字符(可以跨越路径片段)组成的序列不一致;若原始测序数据中,两个读段有(K-1)个连续字符相同,则这两个读段中的这两个(K-1)长度的片段覆盖变异路径图中的同一个长度为(K-1)个字符的路径。该路径可能跨越多个相互连接的路径片段。因此,一个分辨率参数为K的变异路径图所表示的原始测序数据的拼接方式,等价于原始测序数据的一个基于“K串”的德布鲁因图拼接。
本发明还公开了一种测序数据的变异路径图的具体生成方法,利用对“切点”的追踪,建立“变异路径图中路径片段(或路径单元)的分叉点”、“变异路径图中路径片段序列内部对应于原始测序读段的起点或终点的位置(即路径单元的起点或终点)”与“原始测序读段内序列的位置坐标”之间的关联,利用这一关联实现高效的分布式拼接,包含以下步骤:
1)对每个原始测序读段,从左到右依次扫描其序列中存在的长度为(K-1)的字符串,生成(K-1)串对象,每个(K-1)串对象包含如下信息:
a.扫描得到的长度为(K-1)的序列字符串;
b.该字符串左侧的字符(如该字符串为其来源读段的第一个(K-1)串,则其左侧字符记为‘|’);
c.该字符串右侧的字符(如该字符串为其来源读段的最后一个(K-1)串,则其右侧字符记为‘|’);
d.该(K-1)串的来源读段编号;
e.该(K-1)串在来源读段上的起始位置坐标;
f.当该(K-1)串是其来源读段的第一个(K-1)串,则记录其来源读段的全部序列信息,否则不记录。
2)将步骤1)生成的所有(K-1)串对象,按照其(K-1)长度字符串聚簇,对每一簇的(K-1)串对象,分配一个独一无二的簇ID(正整数);然后分别对每一簇的(K-1)串对象,执行以下操作以获得“切点-读段位置”对象:
a.若该簇(K-1)串对象的左侧字符包含两种或以上的非‘|’字符,或者包含‘|’字符,则该簇(K-1)串对象的序列的左侧存在一个切点(包含两种或以上非‘|’字符或仅包含‘|’字符时,该切点对应于变异路径图中的分叉点;同时包含‘|’字符和一种非‘|’字符时,该切点对应于变异路径图中路径片段序列内部对应于原始测序读段的起始的位置,也是一个路径单元的起点位置)。
b.若该簇(K-1)串对象的序列的左侧存在一个切点,则将该簇内每个(K-1)串对象映射成为一个切点-读段位置对象。每个切点-读段位置对象包含如下信息:
切点ID(等于簇ID的负值)(负值表示左侧切点);
来源读段编号(等于(K-1)串对象的来源读段编号);
来源读段位置(等于(K-1)串对象在来源读段上的起始位置);
来源读段全序列(当(K-1)串对象记录了来源读段的全序列时记录,否则不记录)。
c.若该簇(K-1)串对象的右侧字符包含两个或以上的非‘|’字符,或者包含‘|’字符,则该簇(K-1)串对象的序列的右侧存在一个切点(包含两种或以上非‘|’字符或仅包含‘|’字符时,该切点对应于变异路径图中的分叉点;同时包含‘|’字符和一种非‘|’字符时,该切点对应于变异路径图中路径片段序列内部对应于原始测序读段的结束的位置,也是一个路径单元的结束位置)。
d.若该簇(K-1)串对象的序列的右侧存在一个切点,则将该簇内每个(K-1)串对象映射成为一个切点-读段位置对象。每个切点-读段位置对象包含如下信息:
切点ID(等于簇ID)(正值表示右侧切点)。
来源读段编号(等于(K-1)串对象的来源读段编号)。
来源读段位置(等于(K-1)串对象在来源读段上的结束位置,可通过(K-1)串对象在来源读段上的起始位置计算得到)。
来源读段全序列(当(K-1)串对象记录了来源读段全序列时记录,否则不记录)。
e.若该簇(K-1)串对象的序列的左侧和右侧均不存在切点,则该簇(K-1)串对象不生成任何“切点-读段位置”对象。
3)将步骤2)生成的全部切点-读段位置对象,按其来源读段编号聚簇;然后分别对每一簇的切点-读段位置对象,执行以下操作以生成“路径单元-读段位置”对象:
a.将该簇切点-读段位置对象按它们的来源读段位置排序;
b.由步骤1)-2)可得,由某个读段生成的第一个(K-1)串对象,必带有该读段的全序列信息;该(K-1)串对象的左侧必是一个切点;因此,由该(K-1)串对象生成的切点-读段位置对象必带有该读段的全序列信息且其来源读段位置最小(排序最靠前),因此,排序后的切点-读段位置对象集的第一个对象,必含有该读段的全序列信息,记该读段的全序列为S。
c.在排序后的切点-读段位置对象集中从前到后依次扫描,每次取相邻的一对切点-读段位置对象,记位置靠前的对象为A,位置靠后的对象为B,将它们映射为一个路径单元-读段位置对象,该路径单元-读段位置对象包含如下信息:
起始切点ID(等于A的切点ID);
结束切点ID(等于B的切点ID);
来源读段编号(等于聚簇对象共同的来源读段编号);
来源读段起始位置(等于A的来源读段位置);
来源读段结束位置(等于B的来源读段位置);
路径单元序列(等于一个以A、B的“来源读段位置”作为起始、结束位置,从S中提取的子字符串)。
4)将步骤3)生成的全部路径单元-读段位置对象,按其(起始切点ID,结束切点ID,路径单元序列)的三元组聚簇;然后将每一簇路径单元-读段位置对象,映射为一个“路径单元”对象,该路径单元对象包含以下信息:
a.起始切点ID(等于聚簇对象共同的起始切点ID);
b.结束切点ID(等于聚簇对象共同的结束切点ID);
c.路径单元序列(等于聚簇对象共同的路径单元序列);
d.来源读段位置表,每个聚簇中的路径单元-读段位置对象映射为该表中的一条记录,每条记录包含如下信息:
来源读段编号(等于路径单元-读段位置对象的来源读段编号);
来源读段起始位置(等于路径单元-读段位置对象的来源读段起始位置);
来源读段结束位置(等于路径单元-读段位置对象的来源读段结束位置);
5)对上一步骤生成的全部路径单元对象,执行归并等价切点ID的操作,步骤如下:
a.对全部路径单元对象,按其路径单元序列的长度,拆分为一个长度非0的对象集(记为非空路径单元集)和一个长度为0的对象集(记为空路径单元集),若空路径单元集为空集,则无需归并,直接返回全部路径单元对象为归并后的路径单元对象;
b.空路径单元集中的路径单元,其起始切点ID与结束切点ID等价,若两个切点ID同时与第三个切点ID等价,则这三个切点ID相互等价,按照这一等价规则,可计算出一组“等价切点ID的集合”,并生成切点ID的替换规则:将每个“等价切点ID的集合”中的切点ID替换为该集合中数值最小的切点ID;不在等价切点ID的集合中的切点ID不变;
c.对非空路径单元集中的路径单元对象,应用上述切点ID的替换规则,替换其起始切点ID和结束切点ID;
d.对替换后的非空路径单元对象,按(起始切点ID,结束切点ID,路径单元序列)的三元组聚簇;然后将每一簇路径单元对象,映射为一个路径单元对象。映射的方法是:以簇内任何一个路径单元对象为映射结果的模版,变更其来源读段位置表为聚簇中所有路径单元的来源读段位置表的记录的并集,其余信息不变;
e.上述步骤所得的路径单元对象为归并后的路径单元对象。
6)对上一步骤生成的全部路径单元对象,执行左切点对齐操作,由步骤1)-2)可得,最终变异路径图中的路径分叉点必对应一个切点,因此,一个切点的右侧第一个字符决定了变异路径图中相邻的两个切点间的唯一路径,依据这一原理,可进行路径单元的左对齐,路径单元的左对齐可以切分融合的路径单元,融合的路径单元的存在,是因为读段的左右侧的截断效应,导致读段左侧和右侧(K-1)长度内的部分切点无法被步骤1)-2)标记,至使步骤3)-4)得到的路径单元并非最小的路径单元,而是越过了未被标记的切点的若干路径单元的融合,路径单元的左对齐操作步骤如下:
a.对全部路径单元对象,按其(起始切点ID,路径单元序列的第一个字符)的二元组聚簇;
b.将每一簇路径单元对象映射为一簇新的路径单元对象,方法如下:
1、将簇内的路径单元对象按路径单元序列的长度排序,记长度最小的路径单元对象为A,其长度为L。
2、将A映射为一个新的路径单元对象。该新对象的信息与A一致,仅变更新对象的来源读段位置表。该新对象的来源读段位置表包含:
i)全部A的来源读段位置表中的记录;
ii)该簇中其它路径单元的来源读段位置表中的记录映射而来的记录,映射的规则是:来源读段编号不变,来源读段起始位置不变,来源读段结束位置设置为与来源读段起始位置相距为L(向后)的位置。
3、将该簇中非A的路径单元对象映射为一个新的路径单元对象,该新对象的起始切点ID设置为A的结束切点ID,该新对象的结束切点ID不变,该新对象的路径单元序列,设置为原对象的路径单元序列从左侧删除A的路径单元序列后剩下的序列(该序列可能为空),该新对象的来源读段位置表的记录由原对象的来源读段位置表的记录映射而来,映射的规则是:来源读段编号不变,来源读段起始位置设置为与原来源读段起始位置相距为(L+1)(向后)的位置,来源读段结束位置不变。
c.上述聚簇后映射生成的路径单元对象中,可能包含路径单元序列为空的路径单元对象,因此需要对所得对象执行步骤5)归并等价切点ID的操作,归并等价切点ID后所得的路径单元对象为步骤6)最终生成的左切点对齐后的路径单元对象。
7)对上一步骤生成的全部路径单元对象,执行右切点对齐操作。由步骤1)-2)可得,最终变异路径图中的路径分叉点必对应一个切点。因此,一个切点的左侧第一个字符决定了变异路径图中相邻的两个切点间的唯一路径。依据这一原理,可进行路径单元的右对齐。路径单元的右对齐可以切分融合的路径单元,融合的路径单元的存在,是因为读段的左右侧的截断效应,导致读段左侧和右侧(K-1)长度内的部分切点无法被步骤1)-2)标记,至使步骤3)-4)得到的路径单元并非最小的路径单元,而是越过了未被标记的切点的若干路径单元的融合。路径单元的右对齐操作步骤如下:
a.对全部路径单元对象,按其(结束切点ID,路径单元序列的最后一个字符)的二元组聚簇;
b.将每一簇路径单元对象映射为一簇新的路径单元对象,方法如下:
1、将簇内的路径单元对象按路径单元序列的长度排序,记长度最小的路径单元对象为A,其长度为L。
2、将A映射为一个新的路径单元对象。该新对象的信息与A一致,仅变更新对象的来源读段位置表。该新对象的来源读段位置表包含:
i)全部A的来源读段位置表中的记录;
ii)该簇中其它路径单元的来源读段位置表中的记录映射而来的记录,映射的规则是:来源读段编号不变,来源读段起始位置设置为与来源读段结束位置相距为L(向前)的位置,来源读段结束位置不变。
3、将该簇中非A的路径单元对象映射为一个新的路径单元对象。该新对象的起始切点ID不变。该新对象的结束切点ID设置为A的起始切点ID。该新对象的路径单元序列,设置为原对象的路径单元序列从右侧删除A的路径单元序列后剩下的序列(该序列可能为空)。该新对象的来源读段位置表的记录由原对象的来源读段位置表的记录映射而来,映射的规则是:来源读段编号不变,来源读段起始位置不变,来源读段结束位置设置为与原来源读段结束位置相距为(L+1)(向前)的位置。
c.上述聚簇后映射生成的路径单元对象中,可能包含路径单元序列为空的路径单元对象,因此需要对所得对象执行步骤5)归并等价切点ID的操作。归并等价切点ID后所得的路径单元对象为步骤7)最终生成的右切点对齐后的路径单元对象。
8)重复步骤6)-7),直到在步骤6)和7)的执行过程中,每个聚簇仅包含一个路径单元对象。
9)依据步骤8)生成的路径单元对象,生成“路径片段内部切点集”,路径片段内部切点指向前、向后均只连接一个路径单元(即不分叉)的切点,生成路径片段内部切点集的步骤如下:
a.将所有路径单元对象按照起始切点ID聚簇,记录仅包含一个路径单元对象的簇的起始切点ID,记为集合A。
b.将所有路径单元对象按照结束切点ID聚簇,记录仅包含一个路径单元对象的簇的结束切点ID,记为集合B。
c.取集合A与B的交集,得到路径片段内部切点集。
10)将步骤8)生成的路径单元对象映射为未连接的“路径片段”对象。每个路径片段对象包含如下信息:
a.起始切点ID(等于路径单元对象的起始切点ID);
b.起始切点是否为路径片段内部切点(若起始切点ID在步骤9)生成的路径片段内部切点集中,则为是,否则为否);
c.结束切点ID(等于路径单元对象的结束切点ID);
d.结束切点是否为路径片段内部切点(若结束切点ID在步骤9)生成的路径片段内部切点集中,则为是,否则为否);
e.路径片段长度(设置为路径单元序列的长度);
f.来源读段映射表。每个路径单元来源读段位置表的一条记录映射为路径片段来源读段映射表的一条记录,该记录包含如下信息:
路径片段起始位置(设置为1);
路径片段结束位置(设置为路径单元序列的长度);
读段ID(等于路径单元来源读段位置表记录的来源读段ID);
读段起始位置(等于路径单元来源读段位置表记录的来源读段起始位置);
读段结束位置(等于路径单元来源读段位置表记录的来源读段结束位置)。
11)将步骤10)生成的未连接的路径片段对象进行连接,步骤如下:
a.找到一对可连接的路径片段对象,记为A、B,满足条件:A的结束切点ID等于B的起始切点ID。
b.将A、B合成一个新的路径片段对象C。合成后A、B不再存在。C在满足条件的情况下可继续与其它的路径片段对象连接。合成规则如下:
C的起始切点ID设置为A的起始切点ID;
C的“起始切点是否为路径片段内部切点”设置为A的“起始切点是否为路径片
段内部切点”;
C的结束切点ID设置为B的结束切点ID;
C的“结束切点是否为路径片段内部切点”设置为B的“结束切点是否为路径片
段内部切点”;
C的路径片段长度设置为A的路径片段长度与B的路径片段长度之和;
C的来源读段映射表由A和B的来源读段映射表合并生成,步骤如下:
i)由于B路径片段连接在A路径片段之后,首先将B路径片段的来源读段映射表中的每一条记录的“读段起始位置”和“读段结束位置”均增加A路径片段的“路径片段长度”;
ii)取A、B两个路径片段的来源读段映射表,得到其记录的并集。在该集合中,如果两条记录(记为U、V)满足条件“U来自A的来源读段映射表;V来自B的来源读段映射表;U、V的读段ID相同;U的读段结束位置等于V的读段起始位置减1”,则将这两条记录合成一条新的记录(记为R),使“R的路径片段起始位置等于U的路径片段起始位置;R的路径片段结束位置等于V的路径片段结束位置;R的读段ID等于U、V共同的读段ID;R的读段起始位置等于U的读段起始位置;R的读段结束位置等于V的读段结束位置”;
iii)经上述步骤生成的记录集构成C的来源读段映射表。
c.重复上述步骤,直到无法找到可连接的路径片段对象。所得的路径片段对象集即为完全连接后的路径片段对象集。
12)经上述步骤生成的,完全连接后的路径片段对象集(每个路径片段对象包含其左侧和右侧的切点ID信息,以及该路径片段序列的哪个部分被原始测序数据读段序列的哪个片段覆盖的信息),构成一个对原始测序数据的变异路径图表示。
针对海量的原始数据,本发明提供了另一种测序数据的变异路径图的具体生成方法。这一方法将海量的原始测序数据拆分为不同的部分,对每个部分的原始测序数据分别构建变异路径图,再将所得的变异路径图合并,得到全部测序数据或特定测序数据的变异路径图,包含以下步骤:
1)将海量的原始测序数据,按样本或分组,拆分为不同的部分,对每个部分的原始测序数据,按前述第2点权利要求所述的方法,生成该部分原始测序数据的变异路径图;
2)将所得的变异路径图两两合并,得到全部原始测序数据的变异路径图;或将特定样本或分组的变异路径图合并,得到一部分特定测序数据的变异路径图,用于比较特定样本或特定分组之间的差异,合并两个变异路径图的步骤如下:
a.对两个变异路径图(记为G、H)中的路径片段的每个位置给予唯一的位置编号,使得:
同一变异路径图中,所有路径片段的所有位置具有不同的编号。
同一变异路径图中,同一路径片段的最左侧到最右侧位置的编号连续递增。
同一变异路径图中,分属两个不同路径片段的任意两个位置的编号不相邻(差值不等于1)。
b.将变异路径图G、H分别视为一个读段。G具有读段ID“1”,H具有读段ID“2”。扫描得到G、H中所有的长度为(K-1)的字符串,生成(K-1)串对象。这些字符串可能从任意一个路径片段中的任意位置开始,以任意路径跨越路径片段的边界。每个(K-1)串对象包含如下信息:
扫描得到的长度为(K-1)的序列字符串。
该字符串左侧的字符(如该字符串来源于一个左侧没有连接其它路径片段的路径片段的最左侧,则其左侧的字符记为‘|’;如该字符串来源于一个左侧可能连接多个其它路径片段的路径片段的最左侧,则生成多个(K-1)串对象,每个(K-1)串对象记录一种可能性)。
该字符串右侧的字符(如该字符串来源于一个右侧没有连接其它路径片段的路径片段的最右侧,则其右侧的字符记为‘|’;如该字符串来源于一个右侧可能连接多个其它路径片段的路径片段的最右侧,则生成多个(K-1)串对象,每个(K-1)串对象记录一种可能性)。
该(K-1)串的来源读段编号(“1”或者“2”)。
该(K-1)串在来源读段上的起始位置编号。
该(K-1)串在来源读段上的结束位置编号。
c.按类似于前述第2点权利要求方法,基于上述(K-1)串对象,可生成合成的变异路径图,方法的主要改变在于:
(K-1)串对象不再记录其来源读段的全序列信息,但记录该(K-1)串在读段上的结束位置,这一改变是因为(K-1)串可能跨越路径片段的边界,而不同的路径片段内的位置编号不连续,因此不能依据K-1串的起始位置计算其结束位置。
在生成“切点-读段位置”对象时,直接使用(K-1)串对象记录的该(K-1)串在来源读段上的结束位置信息,而不是基于其起始位置计算结束位置,同时,切点-读段位置对象需记录切点两侧的字符(可依据(K-1)串对象记录的信息获得),但不记录来源读段全序列。
在生成“路径单元-读段位置”对象时,不记录路径单元序列,但记录路径单元的第一个和最后一个字符。
同样,在生成“路径单元”对象时,不记录路径单元序列,但记录路径单元的第一个和最后一个字符。
因只有两个读段,不会出现“融合的路径单元”,所以跳过所有与“左切点对齐”和“右切点对齐”相关的步骤。
按上述方法生成的路径单元必然对应于原变异路径图G、H中路径单元的某种拆分,因此,在生成未连接的“路径片段”时,路径单元的“路径单元序列”的长度可以依据其来源读段位置表中任意一条记录的“来源读段起始位置”与“来源读段结束位置”的距离进行计算(此时这两个位置必位于G或H的同一个路径片段内,因此位置编号的差值与序列长度相等)。
按上述方法生成的合成变异路径图(一组经完全连接后的路径片段对象),其路径片段的起始与结束位置必与原变异路径图G或H中的某个路径片段的起始位置或结束位置对应,即合成的变异路径图的路径片段必是G、H中路径片段的拆分。依据这种对应关系,可将G、H中路径片段的来源读段映射表转换为合成的变异路径图中路径片段的来源读段映射表。转换的方法为直观的片段拆分方法,此处不再赘述。
d.按上述方法可合并两个变异路径图G、H为一个合成的变异路径图。
以上并非是对本专利具体实施方式的限制。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明实质范围的前提下,还可以做出若干变化、改型、添加或替换,这些改进和润饰也应视为本发明的保护范围。
- 高通量测序数据的变异路径图表示方法及其生成方法
- 基于高通量测序和高斯混合模型的拷贝数变异检测方法