基于二部图的后期融合多视图聚类机器学习方法及系统
文献发布时间:2023-06-19 11:29:13
技术领域
本发明涉及计算机视觉和模式识别技术领域,尤其涉及基于二部图的后期融合多视图聚类机器学习方法及系统。
背景技术
聚类是一种非常重要的无监督学习方法,其目的是将没有标签的数据划分成k个类。k均值聚类是一种应用最为广泛的方法,它迭代执行以下两个步骤直至收敛:(1)根据样本点所属的类,更新k个聚类中心;(2)根据聚类中心,更新样本所属的类。其中核k均值聚类因其可以学习到样本非线性信息而被广泛研究。
从不同角度观察一个事物,能得到对该事物更为深刻的认识。随着信息采集技术的发展,对于同一个数据样本,我们可以轻易得到它不同视图的信息。我们称拥有多个视图信息的数据为多视图数据。为了对多视图数据进行聚类,学术界衍生了多视图聚类算法。
按照视图融合的时机不同,现有的多视图聚类算法可以大致分为以下两类:(1)基于前期融合的多视图聚类算法。前期融合,是指在进行聚类之前,将多个视图的表征融合起来,得到一个统一的表示。接着,再对其运行聚类算法,得到最终的聚类结果。以上可称之为“两步法”。或者可以将最终的聚类目标式和视图融合的目标式组合成一个目标式进行优化,可以称之为“一步法”。这其中比较经典的算法有多核聚类算法(Liu X,Dou Y,Yin J,etal.“Multiple Kernel k-Means Clustering with Matrix-Induced Regularization”,inAAAI 2016,pp.1888–1894)、多视图谱聚类算法(Son J-W,Jeon J,Lee A,et al.“Spectralclustering with brainstorming process for multi-view data”,in AAAI 2017,pp.2548–2554)以及多视图子空间聚类算法(Kang Z,Zhou W,Zhao Z,et al.“Large-scalemulti-view subspace clustering in linear time”in AAAI 2020,pp.4412-4419)等。前期融合多视图聚类算法根据各自的信息融合机制大大地提高了聚类表现。(2)基于后期融合的多视图聚类算法。与前期融合不同,后期融合多视图聚类首先从每个单视图中获得基础划分,然后再利用这些基础划分中获得一个最优的聚类结果。所有的集成聚类算法均可以视作一种后期融合方法。对于基础划分的使用,不同的方法也导致了不同的聚类效果和计算复杂度。文献“From Ensemble Clustering to Multi-View Clustering”(Tao Z,LiuH,Li S,et al.,in IJCAI,2017,pp.2843–2849)利用基础划分先构造各个视图的关联矩阵,即判断样本两两之间是否归为同一类的n×n维的0-1矩阵,通过低秩和稀疏矩阵分解的方式从中学习到一个统一的表示,用以实现较好的聚类效果。文献“Self-PacedClustering Ensemble”(Zhou P,Du L,Liu X,et al.,in TNNLS,2020,pp.1–15)则是构造各视图关联矩阵后,给定一个样本学习难度的测量准则,利用自步学习按照从简到难的顺序对样本进行聚类。文献“Multi-view Clustering via Late Fusion AlignmentMaximization”(Wang S,Liu X,Zhu E,et al.,in IJCAI,2019,pp.3778–3784)则是最大化一致划分和基础划分之间的线性组合之间的内积。文献“Efficient and EffectiveRegularized Incomplete Multi-view Clustering”(Liu X,Li M,Tang C,et al.,inTPAMI,2020,preprint)则利用后期融合的方法处理缺失多视图聚类问题,取得了非常好的效果。
虽然上述算法取得了较好的效果,然而:(1)绝大部分的前期融合多视图聚类算法在空间和时间上的消耗非常大,例如多核k均值聚类和多视图谱聚类,它们的空间复杂均为O(n^2),时间复杂度均为O(n^3)。这导致这类算法无法在大规模数据集上得到应用。(2)现有后期融合多视图聚类基于的假设是最大化最优聚类指示矩阵与基础聚类指示矩阵线性组合的内积,用以求取最优聚类指示矩阵。这种做法过分简化了最优聚类指示矩阵的搜索空间。
发明内容
本发明的目的是针对现有技术的缺陷,提供了基于二部图的后期融合多视图聚类机器学习方法及系统。
为了实现以上目的,本发明采用以下技术方案:
基于二部图的后期融合多视图聚类机器学习方法,包括:
S1.获取聚类任务和目标数据样本;
S2.通过对获取的聚类任务和目标数据样本相对应的各个视图运行核k均值聚类,得到基础划分,并计算各视图多样化正则项;
S3.利用随机初始化选定各个视图的代表点,建立基于二部图的后期融合多视图聚类目标函数;
S4.采用循环方式求解建立的基于二部图的后期融合多视图聚类目标函数,得到视图融合后的二部图;
S5.对得到的二部图进行谱聚类,得到聚类结果。
进一步的,所述步骤S2中运行核k均值聚类,具体为:
核k均值聚类的目标为最小化基于划分矩阵B∈{0,1}
其中,
公式(1)化为:
其中,K表示核矩阵,K的元素为K
令
其中,I
进一步的,所述步骤S3中基于二部图的后期融合多视图聚类目标函数,表示为:
s.t.Z1
其中,
进一步的,所述步骤S4中采用循环方式求解建立的基于二部图的后期融合多视图聚类目标函数具体为:
利用三步交替法求解公式(3),具体为:
A1.固定γ和
设Z的第i行为z
其中,
A2.固定γ和Z,优化
A3.固定
其中,
进一步的,所述步骤S4中利用三步交替法求解公式(3),其中三步交替法终止条件表示为:
(obj
其中,obj
进一步的,还提供基于二部图的后期融合多视图聚类机器学习系统,包括:
获取模块,用于获取聚类任务和目标数据样本;
运行模块,用于通过对获取的聚类任务和目标数据样本相对应的各个视图运行核k均值聚类,得到基础划分,并计算各视图多样化正则项;
建立模块,用于利用随机初始化选定各个视图的代表点,建立基于二部图的后期融合多视图聚类目标函数;
求解模块,用于采用循环方式求解建立的基于二部图的后期融合多视图聚类目标函数,得到视图融合后的二部图;
聚类模块,用于对得到的二部图进行谱聚类,得到聚类结果。
进一步的,所述运行模块中运行核k均值聚类,具体为:
核k均值聚类的目标为最小化基于划分矩阵B∈{0,1}
其中,
其中,K表示核矩阵,K的元素为K
令
其中,I
进一步的,所述建立模块中基于二部图的后期融合多视图聚类目标函数,表示为:
s.t.Z1
其中,
进一步的,所述求解模块中采用循环方式求解建立的基于二部图的后期融合多视图聚类目标函数具体为:
利用三步交替法求解公式(3),具包括:
第一固定模块,用于固定γ和
设Z的第i行为z
其中,
第二固定模块,用于固定γ和Z,优化
第三固定模块,用于固定
其中,
进一步的,所述求解模块中利用三步交替法求解公式(3),其中三步交替法终止条件表示为:
(obj
其中,obj
与现有技术相比,本发明提出了一种新颖的基于二部图的后期融合多视图聚类机器学习方法,该方法包括获取基础聚类划分和计算图多样化正则项、优化目标函数获取二部图和利用二部图进行聚类等模块。通过对代表点进行优化,本发明使得经过优化后的代表点不但可以代表单个视图的信息,也能更好地服务于视图融合,进而使学习得到的二部图能更好地融合各个视图的信息,达到聚类效果提升的目的。在六个公共数据集上的实验结果证明了本发明的性能优于现有方法。
附图说明
图1是实施例一提供的基于二部图的后期融合多视图聚类机器学习方法流程图;
图2是实施例二提供的参数λ敏感性图示意图;
图3是实施例二提供的不同代表点数s对聚类效果的影响示意图;
图4是实施例二提供的随迭代次数增加,聚类性能和目标函数值的变化示意图;
图5是实施例三提供的基于二部图的后期融合多视图聚类机器学习系统结构图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
本发明针对现有缺陷,提供了基于二部图的后期融合多视图聚类机器学习方法及系统。
实施例一
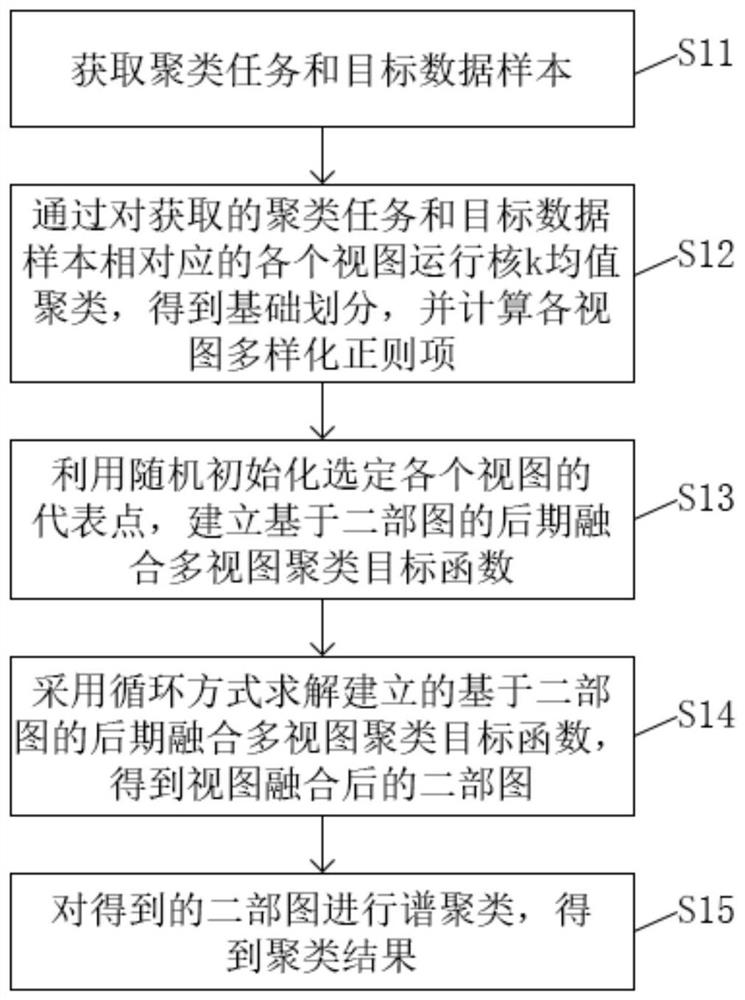
本实施例提供的基于二部图的后期融合多视图聚类机器学习方法,如图1所示,包括:
S11.获取聚类任务和目标数据样本;
S12.通过对获取的聚类任务和目标数据样本相对应的各个视图运行核k均值聚类,得到基础划分,并计算各视图多样化正则项;
S13.利用随机初始化选定各个视图的代表点,建立基于二部图的后期融合多视图聚类目标函数;
S14.采用循环方式求解建立的基于二部图的后期融合多视图聚类目标函数,得到视图融合后的二部图;
S15.对得到的二部图进行谱聚类,得到聚类结果。
本实施例提出的一种通过后期融合学习多视图信息进行聚类的新方法,用于表示视图代表点法,相比于在优化过程中不进行更新的锚点,代表点能够更好地服务于多视图聚类;且在后期融合算法中利用二部图进行图学习的方法,降低了计算和存储复杂度。
在步骤S12中,通过对获取的聚类任务和目标数据样本相对应的各个视图运行核k均值聚类,得到基础划分,并计算各视图多样化正则项。具体为:
核k均值聚类的目标为最小化基于划分矩阵B∈{0,1}
其中,
公式(1)可以化为:
其中,K表示核矩阵,K的元素为K
由于上式中的变量B是离散的,优化较为困难。令
其中,I
其闭式解为核矩阵K前k最大特征值对应的特征向量,可通过对K进行特征分解获得。
在步骤S13中,利用随机初始化选定各个视图的代表点,建立基于二部图的后期融合多视图聚类目标函数。
其中基于二部图的后期融合多视图聚类目标函数,表示为:
s.t.Z1
其中,
在步骤S14中,采用循环方式求解建立的基于二部图的后期融合多视图聚类目标函数,得到视图融合后的二部图,具体为:
利用三步交替法求解公式(3),具体为:
A1.固定γ和
设Z的第i行为z
其中,
A2.固定γ和Z,优化
A3.固定
其中,
上述三步交替法终止条件表示为:
(obj
其中,obj
在步骤S15中,对得到的二部图进行谱聚类,得到聚类结果。
对二部图Z进行谱聚类的过程具体为:
令
与现有技术相比,本实施例提出了一种新颖的基于二部图的后期融合多视图聚类机器学习方法,该方法包括获取基础聚类划分和计算图多样化正则项、优化目标函数获取二部图和利用二部图进行聚类等模块。通过对代表点进行优化,本实施例使得经过优化后的代表点不但可以代表单个视图的信息,也能更好地服务于视图融合,进而使学习得到的二部图能更好地融合各个视图的信息,达到聚类效果提升的目的。
实施例二
本实施例提供基于二部图的后期融合多视图聚类机器学习方法与实施例一的不同之处在于:
本实施例在6个MKL标准数据集上测试了本发明方法的聚类性能,包括OxfordFlower17、Oxford Flower102、Protein fold prediction、UCI-Digital、ColumbiaConsumer Video(CCV)和Caltech102。数据集的相关信息参见表1。
表1
对于ProteinFold,本实施例产生了12个基准核矩阵,其中前10特征集使用了二阶多项式核,最后两个使用了cosine内积核。对于CCV,通过应用一个高斯核在SIFT、STIP和MFCC特征上,生成三个基核,三个高斯核的宽度设置成每对样本距离的均值。其他数据集的核矩阵可从互联网下载。
本实验采用平均多核聚类算法(A-MKKM)、最优单视图核k均值聚类算法(SB-MKKM)、多核k均值聚类(MKKM)、鲁棒的多核聚类(RMKKM)、带矩阵诱导正则化项的多核k均值聚类(MKKM-MR)、最优邻居多核聚类(ONKC)、基于后期融合的最大化对齐多视图聚类(MVC-LFA)。在所有实验中,所有基准核首先被中心化和正则化。对于所有数据集,假设类别数量已知且被设置为聚类类别数量。另外,本实验使用了网格搜索RMKKM、MKKM-MR、ONKC和MVC-LFA的参数。本实施例方法的正则化参数也通过网格搜索[2
本实验使用了常见的聚类准确度(ACC)、归一化互信息(NMI)和纯度(Purity)来显示每种方法的聚类性能。所有方法随机初始化并重复50次并显示最佳结果以减少k-means造成的随机性。
表2
表2展示了上述方法以及对比算法在所有数据集上的聚类效果。根据该表可以观察到:1.所提出的算法在三种评价标准下,均优于所有对比算法。2.ONKC在多核算法中是一种重要的基准算法,而所提出的算法在六个数据集ACC上的表现要分别优于ONKC达7.14%,10.22%,3.17%,3.45%,6.07%和10.2%。3.MVC-LFA是一种后期融合算法,通常表现要比其他绝大部分多视图算法要好,而所提出的算法在三个聚类指标下,分别平均超出其7.58%,7.07%和7.34%。
此外,我们还对比了在优化过程中不进行更新的锚点的表现,即分别用k均值聚类和随机采样选定锚点,代入目标式,在算法运行过程中不进行更新。为了避免算法随机性的影响,我们重复了该实验50次,取所有结果的平均值。结果如表3所示。
表3
从表3可以看出,无论是通过k均值选定或者是随机选定的代表点的效果,都比我们提出的代表点法要差很多。因此,我们代表点在算法优化过程中的更新是有效的。
本实施例引入了正则化参数λ以平衡二部图学习和多样化正则项的比重。如图2所示,绘出了当λ在[2
本实施例还有一个重要的参数,即代表点的个数s。我们在[2k,4k,...,14k]范围内选取代表点个数,其中k为聚类簇数,并进行实验,结果如图3所示。可以看出随着s的增大,聚类效果呈总体上升的趋势。但是较大的s必将带来较高的计算开销,为了兼顾聚类效果和复杂度,可以经验地选择代表点数s=8k。
本实施例也给出了每次迭代时的目标函数值和聚类表现的变化,如图4所示。可以看出目标函数值单调减少且通常在25次迭代之内即可收敛。可以看出,随着目标函数的减少,聚类效果会有所波动,但整体呈现上升趋势,本实例说明算法在训练过程中,能够不断提高聚类性能。
实施例三
本实施例提供基于二部图的后期融合多视图聚类机器学习系统,如图5所示,包括:
获取模块11,用于获取聚类任务和目标数据样本;
运行模块12,用于通过对获取的聚类任务和目标数据样本相对应的各个视图运行核k均值聚类,得到基础划分,并计算各视图多样化正则项;
建立模块13,用于利用随机初始化选定各个视图的代表点,建立基于二部图的后期融合多视图聚类目标函数;
求解模块14,用于采用循环方式求解建立的基于二部图的后期融合多视图聚类目标函数,得到视图融合后的二部图;
聚类模块15,用于对得到的二部图进行谱聚类,得到聚类结果。
进一步的,所述运行模块中运行核k均值聚类,具体为:
核k均值聚类的目标为最小化基于划分矩阵B∈{0,1}
其中,
其中,K表示核矩阵,K的元素为K
令
其中,I
进一步的,所述建立模块中基于二部图的后期融合多视图聚类目标函数,表示为:
s.t.Z1
其中,
进一步的,所述求解模块中采用循环方式求解建立的基于二部图的后期融合多视图聚类目标函数具体为:
利用三步交替法求解公式(3),具包括:
第一固定模块,用于固定γ和
设Z的第i行为z
其中,
第二固定模块,用于固定γ和Z,优化
第三固定模块,用于固定
其中,
进一步的,所述求解模块中利用三步交替法求解公式(3),其中三步交替法终止条件表示为:
(obj
其中,obj
需要说明的是,本实施例提供的基于二部图的后期融合多视图聚类机器学习系统与实施例一类似,在此不多做赘述。
与现有技术相比,本实施例包括获取基础聚类划分和计算图多样化正则项、优化目标函数获取二部图和利用二部图进行聚类等模块。通过对代表点进行优化,本实施例使得经过优化后的代表点不但可以代表单个视图的信息,也能更好地服务于视图融合,进而使学习得到的二部图能更好地融合各个视图的信息,达到聚类效果提升的目的。
注意,上述仅为本发明的较佳实施例及所运用技术原理。本领域技术人员会理解,本发明不限于这里所述的特定实施例,对本领域技术人员来说能够进行各种明显的变化、重新调整和替代而不会脱离本发明的保护范围。因此,虽然通过以上实施例对本发明进行了较为详细的说明,但是本发明不仅仅限于以上实施例,在不脱离本发明构思的情况下,还可以包括更多其他等效实施例,而本发明的范围由所附的权利要求范围决定。
- 基于二部图的后期融合多视图聚类机器学习方法及系统
- 基于代理图改善的后期融合多核聚类机器学习方法及系统