一种基于遗传算法的自动标注方法
文献发布时间:2023-06-19 11:29:13
技术领域
本发明涉及数据处理领域,尤其涉及一种基于遗传算法的自动标注方法。
背景技术
用户评论是体验过应用程序的用户的直接反馈。从用户评论中检测到的新出现的问题,如现有的bug(如崩溃)和不利的应用功能(如广告太多),可以为应用开发者维护其应用和安排应用更新提供信息证据。用户评论提供了一种有效和高效的方法来识别应用程序的新问题,这将对开发人员有很大的帮助。
应用程序评论的一个明显特征是数量可观,这可能超过人类浏览所有评论的能力,而动态分析过程中的自动化过程可以及时提醒应用程序开发人员用户关心的问题或功能,还可以帮助他们加快错误修复过程。
以前的一些研究是关于主题描述过程的自动化,主题通常由主题建模方法生成,如潜在狄利克雷分配、分层狄利克雷过程和聚类算法等。为了自动翻译主题,前人有在主题中重新排列关键词以细化其主题定义,也有提供了交互式方法来获得有意义的聚类结果,例如维护具有一致意义的聚类和移除包含异常值的聚类。
发明内容
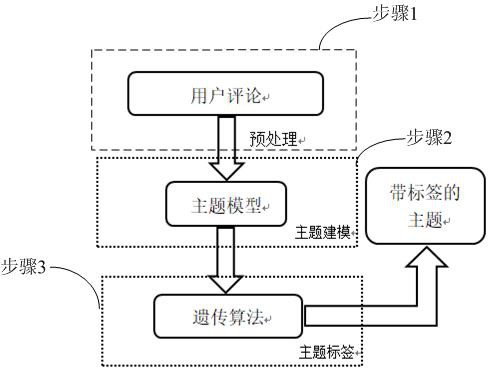
本发明提供了一种基于遗传算法的自动标注方法,包括依次执行以下步骤:
步骤1,预处理:获取评论,从评论中删除长度小于两个单词的评论和所有非字母数字字符,然后取小写字母,在标记化后剔除存在于NLTK语料库中的终止词,接下来,将单词简化为词根形式。
步骤2:主题建模;采用LDA主题建模方法,给定一个评论列表R = {r
步骤3,基于遗传算法的主题标注:设计适合该主题标注场景的染色体结构、适应度参数以及遗传算子,从而完成对主题的标注。
作为本发明的进一步改进,在所述步骤3中,还包括执行以下步骤:
步骤30:染色体结构;用两个单词标注主题,对于每个主题,收集前k个单词作为整个数据集,每个个体都由所选两个单词的索引来表示。
步骤31:适应度参数;基于单词一致性、单词概率、用户评级、一个主题中的单词相似度以及与其他主题中的单词差异度来估计适应度参数。
步骤32:遗传算子;遗传算子包括交叉和变异;用单词索引作为基因表示,通过索引号的改变表达交叉和变异。
作为本发明的进一步改进,在所述步骤31中,单词一致性具体包括:
将单词一致性得分的值限制在0到1之间,计算基于一个主题中包含前k个单词的评论,单词x和y的一致性得分为:
其中f
作为本发明的进一步改进,在所述步骤31中,单词概率表示一个单词属于每个主题的概率,所以在一个特定的题目β
其中f
作为本发明的进一步改进,在所述步骤31中,用户评级具体包括:
在项目中,为了获得对开发人员更有用的标签,对评分较高的评论进行惩罚,并通过以下方式对评分较低的评论进行优先排序:
其中f
作为本发明的进一步改进,在所述步骤31中,一个主题中的单词相似度具体包括:
对于具有前k个单词的主题β
其中f
作为本发明的进一步改进,在所述步骤31中,其他主题中的单词差异度也是基于海林格距离的,海林格距离的目的是使不同主题的标签距离最大化,它可以定义为:
其中f
每个染色体c的适应度值通过下式计算:
其中,w
作为本发明的进一步改进,在所述步骤32中,采用单点交叉,即采用2个单词索引表示染色体,故直接将父染色体的第二个索引修改为母染色体的第二个索引,母染色体的第二个索引修改为父染色体的第二个索引,产生两个后代。
作为本发明的进一步改进,在所述步骤32中,采用单词索引号表示基因序列,突变操作即将某一个索引号以小概率反转为另一个也在词汇表上的单词索引号。
作为本发明的进一步改进,在所述步骤1中,还包括评论嘈杂词的过滤,即删除标记的非信息性评论中经常出现的嘈杂的单词。
本发明的有益效果是:在本发明中,我们的目标是自动解释由主题建模方法生成的主题,提出的主题标注方法采用遗传算法,试图获得一个最优的主题标注。本发明可以用于了解用户对应用的评论,有利于开发者进一步开发或改进应用;本发明也可以被手机市场利用,及时呈现应用的特点,方便用户选择应用。
附图说明
图1是本发明遗传算法的自动标注方法流程图;
图2是本发明遗传算法的原理图。
具体实施方式
本发明公开了一种基于遗传算法的自动标注方法,如图1、图2所示,创新性地将遗传算法应用在主题标注领域,设计适合该场景的染色体结构、遗传算子以及适应度参数,以达到显著性的结果。
遗传算法是受自然选择和自然遗传学进化思想启发的自适应启发式搜索方法。基本概念是模拟自然系统中对进化至关重要的过程。对每个个体的评价涉及5个要素: 单词一致性、单词概率、用户评分、一个主题中的单词相似性以及与其他主题中的单词不相似性(单词不相似性也叫单词差异度)。这里的词概率是通过主题建模方法生成的(我们在项目中使用LDA)。单词一致性旨在使标签更容易被人理解,更像一个短语。
本发明公开的一种基于遗传算法的自动标注方法,包括依次执行以下步骤:
步骤1:预处理;
我们在一篇评论中删除长度小于两个单词的评论和所有非字母数字字符,然后我们取小写字母,在标记化后剔除存在于NLTK语料库中的终止词,接下来,我们将单词简化为词根形式。
无意义和有用的评论通常是混合在一起的,这可能会影响主题提取和后续为了解决这个问题,我们只需删除标记的非信息性评论中经常出现的45个嘈杂的单词。
用于过滤评论的嘈杂词包括:app, apps, good, excellent, awesome, please,they, i, facebook, instagram, templerun, very, too, like,love, nice, ok,yeah, amazing, lovely, perfect, much, bad, best, yup, suck, much, super, hi,thank, thanks, great, really, omg, gud, loved, liked, thats, yes, cool, fine,hello, god, alright, poor。
步骤2:主题建模;
主题建模是提取集合中潜在“主题”以及去除噪声的典型方式,其中每个评论被视为由一组潜在主题组成。主题建模中的每一个主题都以单词的分类分布为特征,在用户评论中捕捉一个主题。因此,主题很好地揭示了用户想要谈论的内容。我们采用LDA——一种规范的主题建模方法,给定一个评论列表R = {r
表1: 评论-主题矩阵
步骤3:基于遗传算法的主题标注;
设计适合该主题标注场景的染色体结构、适应度参数以及遗传算子,从而完成对主题的标注。
我们设计了一种遗传算法来自动标注每个主题。可能的标签可以是单词、短语或句子的形式;然而,句子太长,不能作为一个分支的标签,单个单词携带的语义信息不足,人们无法完全理解主题。所以我们在项目中使用两个单词作为主题标签,直观地将两个单词的结果视为一个短语。一个好的主题标签应该涵盖该主题中的单词信息,并与其他主题的标签区分开来。
在所述步骤3中,还包括执行以下步骤:
步骤30:染色体结构;
主题标记过程是逐主题执行的。如上所述,两个单词的术语被认为是候选标签。对于每个主题,我们收集前k个单词作为整个数据集,每个个体都由所选两个单词的索引来表示,与一般遗传算法采用二进制编码表示基因不同,我们选择单词索引作为基因表示。例如,2,56表示索引为2和56的单词包含一个个体或染色体。
步骤31:适应度参数;
适应度参数是基于四个要素来估计的:单词概率、单词一致性、用户评级、一个主题中的单词相似性以及与其他主题中的单词不相似性。
(1)单词一致性
我们假设如果两个词最经常出现在一篇评论中,那么这两个词具有更高的一致性。受PMI(逐点互信息)的启发,我们设计了自己的一致性评估方法,将单词一致性得分的值限制在0到1之间,PMI是信息论和统计学中使用的一种关联度量。计算基于一个主题中包含前k个单词的评论。单词x和y的一致性得分为
其中f
(2)单词概率
单词概率表示一个单词属于每个主题的概率。所以在一个特定的题目β
其中f
(3)用户评级
一般来说,应用程序开发人员更关心评分较低的用户评论,因为这些评论往往会提供一些关于软件bug或有趣功能的信息。因此,在项目中,为了获得对开发人员更有用的标签,我们对评分较高的评论进行惩罚,并通过以下方式对评分较低的评论进行优先排序
其中f
(4)单词相似度
好的标签应该覆盖题目中概率较高的词所代表的一般信息。对于具有前k个单词的主题β
其中f
(5)单词差异度
与单词相似度的计算类似,单词相异度也是基于海林格距离的,海林格距离的目的是使不同主题的标签距离最大化。它可以定义为
其中f
每个染色体c的适应度值通过下式计算:
其中,w
步骤32:遗传算子;
遗传算子包括交叉和变异;以往都用二进制编码表示基因,通过改变里面部分比特位实现交叉和变异。在这里,我们用单词索引作为基因表示,通过索引号的改变表达交叉和变异。
交叉是通过重组染色体为下一代创造新的个体。在这里,我们采用单点交叉。以往的遗传算法单点交叉是选择父母二进制编码中的相同位置切断,并且在每个父母的染色体上交叉点之后的部分被交换以产生两个新的后代。本发明采用2个单词索引表示染色体,故直接将父染色体的第二个索引修改为母染色体的第二个索引,母染色体的第二个索引修改为父染色体的第二个索引,产生两个后代。
关于突变,以往的遗传算法是通过将二进制编码中一个比特位从1变为0或者从0变为1,从而改变整个基因序列的表达。本发明采用单词索引号表示基因序列,故突变操作即将某一个索引号以小概率反转为另一个也在词汇表上的单词索引号。
本发明公开的一种基于遗传算法的自动标注方法,还包括评估。我们对谷歌游戏的两个应用程序(脸书和脸书桌面窗口聊天客户端)的用户评论进行了评估。脸书的数据包含6636条评论,平均长度为42个单词,脸书桌面窗口聊天客户端收集涉及5855条评论,平均长度为44个单词。
表2的5列对应了脸书的5个话题,每个话题的前10个单词在表3的4-13行列出,本发明的模型的标签在表2的第二行中描述。因为在预处理步骤中,本发明将单词变成词根,所以结果短语由词根化的词组成。为了证明本发明的方法的有效性,本发明与现有方法进行了比较,现有方法的结果在第三行描述。通过比较发现如话题1,本发明的方法捕获到了主题,即“消息很少”这一问题,而现有方法“运作良好”表意不明,本发明的结果更加精确。后面4个话题中本发明的方法结果也更有信息量。
表2 脸书上使用w
表2 脸书中使用适应度函数的前5个主题模型的短语
本发明的有益效果:在本发明中,我们的目标是自动解释由主题建模方法生成的主题,提出的主题标注方法采用遗传算法,试图获得一个最优的主题标注。它可以用于了解用户对应用的评论,有利于开发者进一步开发或改进应用,它也可以被手机市场利用,及时呈现应用的特点,方便用户选择应用。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 一种基于遗传算法的自动标注方法
- 一种基于运动匹配的视频自动标注方法及自动标注系统