用于参数化双耳输出系统和方法的头部跟踪
文献发布时间:2023-06-19 11:35:49
本申请是申请号为201680075037.8、申请日为2016年11月17日、发明名称为“用于参数化双耳输出系统和方法的头部跟踪”的发明专利申请的分案申请。
技术领域
本发明提供可选地利用头部跟踪时的改进形式的参数化双耳输出的系统和方法。
参考文献
Gundry,K.,“一种用于环绕声的新型矩阵解码器(A New Matrix Decoder forSurround Sound),”AES 19th International Conf.,Schloss Elmau,德国,2001年。
Vinton,M.、McGrath,D.、Robinson,C.、Brown,P.,“新一代环绕解码和用于消费和专业应用的上混(Next generation surround decoding and up-mixing for consumerand professional applications)”,AES 57th International Conf,Hollywood,CA,USA,2015年。
Wightman,F.L.和Kistler,D.J.(1989年).“自由场收听的耳机模拟(Headphonesimulation of free-field listening).I.Stimulus synthesis,”J.Acoust.Soc.Am.85,858–867。
ISO/IEC 14496-3:2009–信息技术--视听对象的编码—第3部分:音频(Information technology--Coding of audio-visual objects--Part3:Audio),2009年。
Mania,Katerina等人."在不同程度的场景复杂度下的虚拟环境中的头部跟踪延迟的感知灵敏度(Perceptual sensitivity to head tracking latency in virtualenvironments with varying degrees of scene complexity)."Proceedings of the1st Symposium on Applied perception in graphics and visualization.ACM,2004年。
Allison,R.S.、Harris,L.R.、Jenkin,M.、Jasiobedzka,U.和Zacher,J.E.(2001,March).虚拟环境中时间延迟的容忍度(Tolerance of temporal delay in virtualenvironments).In Virtual Reality,2001年.Proceedings.IEEE(pp.247-254).IEEE。
Van de Par,Steven和Armin Kohlrausch."对听觉-视觉不同步的灵敏度和听觉-视觉定时的抖动(Sensitivity to auditory-visual asynchrony and to jitter inauditory-visual timing)."Electronic Imaging.International Society for Opticsand Photonics,2000年。
背景技术
整个说明书中背景技术的任何讨论绝不应被认为是承认这样的技术是广泛已知的或者形成本领域中的公知常识的一部分。
音频内容的内容创建、编码、分发和再现传统上是基于声道的。也就是说,一个特定的目标回放系统是针对整个内容生态系统的内容设想的。这样的目标回放系统的例子是单声道、立体声、5.1、7.1、7.1.4等。
如果内容要在不同于预期回放系统的回放系统上再现,则可以应用下混或上混。例如,5.1内容可以通过采用特定的已知的下混方程来在立体声回放系统上再现。另一个例子是立体声内容在7.1扬声器设置上的回放,7.1扬声器设置可以包括所谓的上混处理,该上混处理可以由存在于立体声信号(比如由所谓的矩阵编码器(比如Dolby Pro Logic)使用的立体声信号)中的信息指引(guide),或者可以不由该信息指引。为了指引上混处理,可以通过将特定的相位关系包括在下混方程中、或者换句话说、通过应用复值下混方程来暗含地标示(signal)关于下混之前的信号的原始位置的信息。用放置在两个维度上的扬声器对内容使用复值下混系数的这样的下混方法的众所周知的例子是LtRt(Vinton等人,2015年)。
所得的(立体声)下混信号可以在立体声扩音器系统上再现,或者可以被上混到具有环绕扬声器和/或高度扬声器的扩音器设置。信号的预期定位可以由上混器从声道间相位关系导出。例如,在LtRt立体声表示中,异相的(例如,具有接近于-1的声道间波形规范化互相关系数的)信号理想上应由一个或多个环绕扬声器再现,而正相关系数(接近于+1)指示该信号应由收听者前面的扬声器再现。
已经开发了各种上混算法和策略,这些上混算法和策略的不同之处在于它们从立体声下混重新创建多声道信号的策略。在相对简单的上混器中,立体声波形信号的规范化互相关系数是根据时间而跟踪的,而(一个或多个)信号根据规范化互相关系数的值被引导(steer)到前置扬声器或后置扬声器。该方法对于相对简单的内容效果很好,在相对简单的内容中,只有一个听觉对象同时存在。较高级的上混器是基于从特定频率区域导出的统计信息来控制从立体声输入到多声道输出的信号流(Gundry 2001年、Vinton等人2015年)。具体地说,在各个时间/频率片(tile)中可以采用基于引导分量或主导分量和立体声(扩散)残留信号的信号模型。除了估计主导分量和残留信号之外,还估计方向(以方位角,可能补充有仰角(elevation))角度,随后将主导分量信号引导到一个或多个扩音器以在回放期间重构(估计的)位置。
矩阵编码器和解码器/上混器的使用不限于基于声道的内容。音频行业中的最近发展基于音频对象,而不是声道,在音频对象中,一个或多个对象包含音频信号和相关联的元数据,该元数据除了其他方面之外,指示该音频信号的随着时间而变化的预期位置。对于这样的基于对象的音频内容,如Vinton等人2015年的文献中所概述的,也可以使用矩阵编码器。在这样的系统中,对象信号被下混为具有依赖于对象位置元数据的下混系数的立体声信号表示。
矩阵编码的内容的上混和再现不一定限于扩音器上的回放。包含主导分量信号和(预期)位置的引导分量或主导分量的表示使得可以借助于与头部相关脉冲响应(HRIR)的卷积在耳机上再现(Wightman等人,1989年)。图1中示出了实现该方法的系统的简单示意图。矩阵编码的格式的输入信号2首先被分析3以确定主导分量方向和幅值。主导分量信号借助于基于主导分量方向从查找表6导出的一对HRIR被卷积4、5,以计算用于耳机回放7的输出信号,以使得回放信号被感知为来自由主导分量分析级3确定的方向。该方案可以应用于宽带信号上以及各个子带上,并且可以补充有残留(或扩散)信号的各种方式的专用处理。
矩阵编码器的使用非常适合于到AV接收器的分发和AV接收器上的再现,但是对于要求低传输数据速率和低功耗的移动应用,可能是有问题的。
不论是使用基于声道的内容、还是使用基于对象的内容,矩阵编码器和解码器都依赖于从矩阵编码器分发给解码器的信号的相当准确的声道间相位关系。换句话说,分发格式应当很大程度上是波形保持的。对于波形保持的这样的依赖性在位速率受约束的条件下可能是有问题的,在位速率受约束的条件下,音频编解码器采用参数化方法、而不是波形编码工具来获得较好的音频质量。如MPEG-4音频编解码器(ISO/IEC 14496-3:2009)中实现的,一般知道的波形不保持的这样的参数化工具的例子通常被称为频带复制、参数化立体声、空间音频编码等。
如前一节中所概述的,上混器包含信号的分析和引导(或HRIR卷积)。对于通电设备,比如AV接收器,这一般不引起问题,但是对于电池操作的设备,比如移动电话和平板,与这些处理相关联的计算复杂度和对应的存储器要求通常是不期望的,因为它们对电池寿命的影响是负面的。
前述分析通常还引入了额外的音频延时。这样的音频延时是不期望的,因为(1)它需要视频延迟来维持音频-视频边缘(lip)同步,这需要大量的存储器和处理能力,并且(2)在头部跟踪的情况下,可能引起头部移动和音频渲染之间的异步/延时。
由于可能存在很强的异相信号分量,矩阵编码的下混在立体声扩音器或耳机上可能也不是声音最佳的。
发明内容
本发明的一个目的是提供改进形式的参数化双耳输出。
根据本发明的第一方面,提供了一种对基于声道或基于对象的输入音频进行编码以用于回放的方法,该方法包括以下步骤:(a)首先将基于声道或基于对象的输入音频渲染为初始输出表示(例如,初始输出表示);(b)从基于声道或基于对象的输入音频确定主导音频分量的估计,并且确定用于将初始输出表示映射到主导音频分量的一系列主导音频分量加权因子;(c)确定主导音频分量方向或位置的估计;并且(d)将初始输出表示、主导音频分量加权因子、主导音频分量方向或位置编码为用于回放的编码信号。提供用于将初始输出表示映射到主导音频分量的一系列主导音频分量加权因子可以使得能够利用主导音频分量加权因子和初始输出表示来确定主导分量的估计。
在一些实施例中,该方法进一步包括确定残留混音的估计,残留混音是初始输出表示减去主导音频分量或其估计的渲染。该方法还可以包括:生成基于声道或基于对象的输入音频的消声双耳混音,并且确定残留混音的估计,其中,残留混音的估计可以是消声双耳混音减去主导音频分量或其估计的渲染。此外,该方法可以包括确定用于将初始输出表示映射到残留混音的估计的一系列残留矩阵系数。
初始输出表示可以包括耳机或扩音器表示。基于声道或基于对象的输入音频可以按时间和频率分片,并且可以对一系列时间步和一系列频带重复编码步骤。初始输出表示可以包括立体声扬声器混音。
根据本发明的另外的方面,提供了一种对编码的音频信号进行解码的方法,编码的音频信号包括:第一(例如,初始)输出表示(例如,第一/初始输出表示)、主导音频分量方向和主导音频分量加权因子;该方法包括以下步骤:(a)利用主导音频分量加权因子和初始输出表示来确定估计的主导分量;(b)通过根据主导音频分量方向在相对于预期收听者的空间地点处进行双耳化来渲染估计的主导分量以形成渲染的双耳化的估计的主导分量;(c)从第一(例如,初始)输出表示重构残留分量估计;并且(d)组合渲染的双耳化的估计的主导分量和残留分量估计以形成输出的空间化的音频编码信号。
编码的音频信号进一步可以包括表示残留音频信号的一系列残留矩阵系数,并且步骤(c)进一步可以包括:(c1)将残留矩阵系数应用于第一(例如,初始)输出表示以重构残留分量估计。
在一些实施例中,可以通过从第一(例如,初始)输出表示减去渲染的双耳化的估计的主导分量来重构残留分量估计。步骤(b)可以包括根据指示预期收听者的头部方位的输入头部跟踪信号来进行估计的主导分量的初始旋转。
根据本发明的进一步的方面,提供了一种用于针对使用耳机的收听者解码和再现音频流的方法,该方法包括:(a)接收包含第一音频表示和附加音频变换数据的数据流;(b)接收表示收听者的方位的头部方位数据;(c)基于第一音频表示和接收的变换数据来创建一个或多个辅助信号;(d)创建第二音频表示,第二音频表示包含第一音频表示和(一个或多个)辅助信号的组合,在第二音频表示中,(一个或多个)辅助信号中的一个或多个已经响应于头部方位数据而被修改;并且(e)将第二音频表示作为输出音频流输出。
在一些实施例中,可以进一步包括辅助信号的修改包含从声源位置到收听者的耳朵的声学路径的模拟。变换数据可以包含矩阵化系数和以下中的至少一个:声源位置或声源方向。变换处理可以根据时间或频率而应用。辅助信号可以表示至少一个主导分量。声源位置或方向可以作为变换数据的一部分被接收,并且可以响应于头部方位数据而被旋转。在一些实施例中,最大旋转量限于在方位角或仰角上小于360度的值。可以通过在变换域或滤波器组域中进行矩阵化来从第一表示获得第二表示。变换数据进一步可以包括附加矩阵化系数,并且步骤(d)进一步可以包括在组合第一音频表示和(一个或多个)辅助音频信号之前响应于附加矩阵化系数对第一音频表示进行修改。
附图说明
现在将仅以举例的方式来参照附图描述本发明的实施例,在附图中:
图1示意性地示出用于矩阵编码的内容的耳机解码器;
图2示意性地示出根据实施例的编码器;
图3是解码器的示意性框图;
图4是编码器的详细可视化;以及
图5更详细地示出解码器的一种形式。
具体实施方式
实施例提供了一种表示基于对象的或基于声道的音频内容的系统和方法,该系统和方法(1)与立体声回放兼容,(2)使得可以进行包括头部跟踪的双耳回放,(3)具有低解码器复杂度,并且(4)不依赖于矩阵编码,但仍与矩阵编码兼容。
这通过组合一个或多个主导分量(或主导对象或它们的组合)的编码器端分析来实现,一个或多个主导分量(或主导对象或它们的组合)包括与附加参数组合的、从下混预测这些主导分量的权重,权重最小化仅基于引导分量或主导分量的双耳渲染和整个内容的期望的双耳表示之间的误差。
在实施例中,主导分量(或多个主导分量)的分析是在编码器中、而不是在解码器/渲染器中提供的。音频流然后补充有指示主导分量的方向的元数据和关于可以如何从相关联的下混信号获得(一个或多个)主导分量的信息。
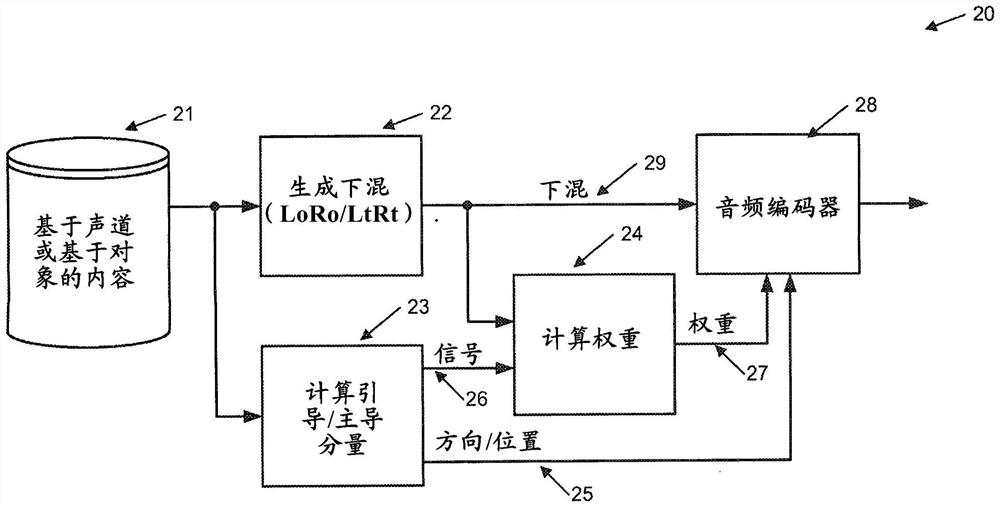
图2示出优选实施例的编码器20的一种形式。基于对象的或基于声道的内容21被进行分析23以确定(一个或多个)主导分量。该分析可以根据时间和频率而发生(假定音频内容被分解为时间片和频率子片)。该处理的结果是一个主导分量信号26(或多个主导分量信号)以及相关联的(一个或多个)位置或(一个或多个)方向信息25。随后,权重被估计24并且被输出27以使得可以从发送的下混重构(一个或多个)主导分量信号。该下混生成器22不一定必须遵守LtRt下混规则,而可以是使用非负实值下混系数的标准ITU(LoRo)下混。最后,输出的下混信号29、权重27和位置数据25被音频编码器28打包,并且准备好分发。
现在转到图3,示出了优选实施例的对应的解码器30。音频解码器重构下混信号。该信号被输入31,并且被音频解码器32拆包(unpack)为下混信号、主导分量的方向和权重。随后,使用主导分量估计权重来重构(34)(一个或多个)引导分量,这些引导分量通过使用发送的位置或方向数据被渲染36。位置数据可以根据头部旋转或平移信息38被可选地修改33。另外,可以从下混减去(35)(一个或多个)重构的主导分量。可选地,在下混路径内存在(一个或多个)主导分量的减法,但是可替代地,如下所述,该减法也可以在编码器处发生。
为了改进减法器35中的重构的主导分量的移除或取消,可以在减法之前首先使用发送的位置或方向数据来渲染主导分量输出。图3中示出了这个可选的渲染级39。
现在返回到一开始更详细地描述编码器,图4示出了用于对基于对象的(例如,Dolby Atmos)音频内容进行处理的编码器40的一种形式。音频对象最初是作为Atmos对象41存储的,并且首先通过使用混合复值正交镜像滤波器(HCQMF)组42被划分为时间片和频率片。当我们省略对应的时间索引和频率索引时,输入对象信号可以用x
使用复值标量H
可替代地,可以通过使用头部相关脉冲响应(HRIR)来创建双耳混音Y(y
可以通过以下方式来估计主导分量
其中,
其中,(.)
主导/引导信号d[n](示例性地实现主导音频分量)随后用以下方程给出:
其中,
其中,
计算46权重或预测系数w
其中,权重w
其中,R
我们随后可以从消声双耳混音y
最后,估计51另一组预测系数或权重w
其中,R
立体声混音z
估计主导分量的系数w
主导分量的位置或方向
以及可选地,残留权重w
尽管以上描述涉及基于单个主导分量的渲染,但是在一些实施例中,编码器可以适于检测多个主导分量、对所述多个主导分量中的每个确定权重和方向、渲染所述多个主导分量中的每个并且从消声双耳混音Y减去所述多个主导分量中的每个、然后确定所述多个主导分量中的每个已经被从消声双耳混音Y减去之后的残留权重。
图5更详细地示出解码器/渲染器60的一种形式。解码器/渲染器60应用旨在从未拆包的输入信息z
首先,使用合适的滤波器组或变换61(比如HCQMF分析组61)来将立体声下混划分为时间/频率片。其他变换(比如离散傅立叶变换、(修正的)余弦或正弦变换、时域滤波器组或小波变换)也可以等同地被应用。随后,使用预测系数权重w
估计的主导分量信号
该主导分量信号随后被渲染65并且基于发送的位置/方向数据
总消声双耳输出是第二音频表示的例子。因此,该步骤可以被说成是对应于创建第二音频表示,第二音频表示包含所述第一音频表示和所述(一个或多个)辅助信号的组合,在第二音频表示中,所述(一个或多个)辅助信号中的一个或多个已经被响应于所述头部方位数据而被修改。
应进一步注意到,如果关于多于一个的主导信号的信息被接收到,则可以渲染每个主导信号并且将该主导信号添加到重构的残留信号。
只要头部旋转或平移没有被应用,输出信号
正如从以上方程公式化可以观察到的,从立体声表示构造消声双耳表示的有效操作包含2x2矩阵70,在该矩阵中,矩阵系数依赖于发送的信息w
如果不估计主导分量(例如,w
在期望从头部旋转/头部跟踪排除某些对象的情况下,这些对象可以从(1)主导分量方向分析和(2)主导分量信号预测排除。结果,这些对象将通过系数w
在类似的思路中,对象可以被设置为“通过”模式,该模式意味着在双耳表示中,将对它们进行振幅平移,而不是HRIR卷积。这可以通过简单地对系数
实施例不限于立体声下混的使用,因为其他声道计数也可以被采用。
参照图5描述的解码器60具有输出信号,该输出信号包含渲染的主导分量方向、加上用矩阵系数w
1.可以在编码器中借助于信号
2.可以将系数w
信号
所描述的方法也可以应用于发送的信号Z是双耳信号的系统中。在这种特定情况下,图5的解码器60保持原样,而图4中被标记为“生成立体声(LoRo)混音”的方框44应该被与产生信号对Y的方框相同的“生成消声双耳混音”43(图4)取代。另外,可以根据要求生成其他形式的混音。
该方法可以扩展到从发送的包含特定的对象或声道子集的立体声混音重构一个或多个FDN输入信号的方法。
该方法可以扩展到从发送的立体声混音预测多个主导分量并且在解码器端渲染这些主导分量。基本上不限制对于每个时间/频率片仅预测一个主导分量。具体地说,主导分量的数量在每个时间/频率片中可以是不同的。
解释
整个说明书中所称“一个实施例”、“一些实施例”或“实施例”意味着与实施例结合描述的特定的特征、结构或特性被包括在本发明的至少一个实施例中。因此,短语“在一个实施例中”、“在一些实施例中”或“在实施例中”在整个说明书中各个地方的出现不一定全都指的是同一个实施例,但是可以指同一个实施例。此外,在一个或多个实施例中,特定的特征、结构或特性可以以本领域的普通技术人员从本公开将清楚的任何合适的方式组合。
如本文所使用的,除非另有指定,否则序数形容词“第一”、“第二”、“第三”等描述共同对象的使用仅指示相似对象的不同实例正被提到,而非意图暗示如此描述的对象必须按时间上、空间上、排名上的给定顺序或任何其他方式的给定顺序。
在所附权利要求书和本文的描述中,术语“包括”、“其包括”或“它包括”中的任何一个是意指至少包括后面的元件/特征、但不排除其他元件/特征的开放性术语。因此,术语“包括”在被用于权利要求中时不应被解释为是限制其后列出的手段或元件或步骤。例如,表达“包括A和B的设备”的范围不应限于仅由元件A和B组成的设备。如本文所使用的术语“包含”或“其包含”或“它包含”中的任何一个也是也意指至少包括该术语后面的元件/特征、但不排除其他元件/特征的开放性术语。因此,包括与包含是同义的,并且意指包含。
如本文所使用的,术语“示例性”是以提供例子的意义使用的,与指示质量相反。也就是说,“示例性实施例”是作为例子提供的实施例,与一定是示例性质量的实施例相反。
应该意识到,在上面对本发明的示例性实施例的描述中,为了使本公开精简并且帮助理解各种发明方面中的一个或多个的目的,本发明的各种特征在单个实施例、附图或其描述中有时被分组在一起。然而,本公开的方法不应被解释为反映要求保护的发明需要比每个权利要求中明确记载的特征多的特征的意图。相反,如所附权利要求所反映的,发明方面在于比单个前述公开实施例的所有特征少的特征。因此,具体实施方式所附的权利要求特此被明确地并入到该具体实施方式中,每个权利要求独自作为本发明的单独的实施例。
此外,虽然本文所描述的一些实施例包括一些、但不是其他的包括在其他实施例中的特征,但是不同实施例的特征的组合意在于本发明的范围内,并且形成如本领域技术人员将理解的不同实施例。例如,在所附权利要求中,要求保护的实施例中的任何一个可以被按任何组合使用。
此外,实施例中的一些在本文中被描述为可以由计算机系统的处理器、或由实施功能的其他手段实现的方法或方法的元素组合。因此,具有用于实施这样的方法或方法的元素所需要的指令的处理器形成用于实施该方法或该方法的元素的手段。此外,装置实施例的本文所描述的元素是用于实施由用于实施本发明的目的的元素执行的功能的手段的例子。
在本文提供的描述中,阐述了许多特定细节。然而,理解的是,可以在没有这些特定细节的情况下实施本发明的实施例。在其他情况下,为了不模糊该描述的理解,没有对众所周知的方法、结构和技术进行详细展示。
类似地,要注意的是,术语“耦合的”在被用在权利要求中时不应被解释为仅限于直接连接。术语“耦合的”和“连接的”、连同它们的派生词可以被使用。应理解,这些术语并非意图是彼此的同义词。因此,表达“耦合到设备B的设备A”的范围不应限于其中设备A的输出直接连接到设备B的输入的设备或系统。它意味着,在A的输出和B的输入之间存在路径,该路径可以是包括其他设备或手段的路径。“耦合的”可以意味着两个或更多个元件为直接的物理或电接触,或者两个或更多个元件不彼此直接接触,但是仍彼此合作或交互。
因此,虽然已经描述了本发明的实施例,但是本领域技术人员将认识到,在不脱离本发明的精神的情况下,可以对本发明做出其他的和进一步的修改,并且意图要求保护落在本发明的范围内的所有这样的改变和修改。例如,上面给出的任何公式仅表示可以使用的过程。可以添加功能性,或者从框图删除功能性,并且可以在功能块之间交换操作。对于在本发明的范围内描述的方法,可以添加或删除步骤。
本发明的各方面可以从以下枚举的示例实施例(EEES)领会:
EEE 1.一种对基于声道或基于对象的输入音频进行编码以用于回放的方法,该方法包括以下步骤:
(a)首先将基于声道或基于对象的输入音频渲染为初始输出表示;
(b)从基于声道或基于对象的输入音频确定主导音频分量的估计,并且确定用于将初始输出表示映射到主导音频分量的一系列主导音频分量加权因子;
(c)确定主导音频分量方向或位置的估计;并且
(d)将初始输出表示、主导音频分量加权因子、主导音频分量方向或位置编码为用于回放的编码信号。
EEE 2.根据EEE 1所述的方法,进一步包括确定残留混音的估计,残留混音是初始输出表示减去主导音频分量或该主导音频分量的估计的渲染。
EEE 3.根据EEE 1所述的方法,进一步包括:生成基于声道或基于对象的输入音频的消声双耳混音,并且确定残留混音的估计,其中,残留混音的估计是消声双耳混音减去主导音频分量或该主导音频分量的估计的渲染。
EEE 4.根据EEE 2或3所述的方法,进一步包括确定用于将初始输出表示映射到残留混音的估计的一系列残留矩阵系数。
EEE 5.根据前述任一个EEE所述的方法,其中,初始输出表示包括耳机或扩音器表示。
EEE 6.根据前述任一个EEE所述的方法,其中,基于声道或基于对象的输入音频按时间和频率分片,并且对一系列时间步和一系列频带重复所述编码步骤。
EEE 7.根据前述任一个EEE所述的方法,其中,初始输出表示包括立体声扬声器混音。
EEE 8.一种对编码的音频信号进行解码的方法,编码的音频信号包括:
-第一输出表示;
-主导音频分量方向和主导音频分量加权因子;
该方法包括以下步骤:
(a)利用主导音频分量加权因子和初始输出表示来确定估计的主导分量;
(b)通过根据主导音频分量方向在相对于预期收听者的空间地点处进行双耳化来渲染估计的主导分量以形成渲染的双耳化的估计的主导分量;
(c)从第一输出表示重构残留分量估计;并且
(d)组合渲染的双耳化的估计的主导分量和残留分量估计以形成输出的空间化的音频编码信号。
EEE 9.根据EEE 8所述的方法,其中,编码的音频信号进一步包括表示残留音频信号的一系列残留矩阵系数,并且所述步骤(c)进一步包括:
(c1)将残留矩阵系数应用于第一输出表示以重构残留分量估计。
EEE 10.根据EEE 8所述的方法,其中,通过从第一输出表示减去渲染的双耳化的估计的主导分量来重构残留分量估计。
EEE 11.根据EEE 8所述的方法,其中,所述步骤(b)包括根据指示预期收听者的头部方位的输入头部跟踪信号来进行估计的主导分量的初始旋转。
EEE 12.一种用于针对使用耳机的收听者解码和再现音频流的方法,该方法包括:
(a)接收包含第一音频表示和附加音频变换数据的数据流;
(b)接收表示收听者的方位的头部方位数据;
(c)基于所述第一音频表示和接收的变换数据来创建一个或多个辅助信号;
(d)创建第二音频表示,第二音频表示包含所述第一音频表示和(一个或多个)辅助信号的组合,在第二音频表示中,(一个或多个)辅助信号中的一个或多个已经响应于所述头部方位数据而被修改;并且
(e)将第二音频表示作为输出音频流输出。
EEE 13.根据EEE 12所述的方法,其中,辅助信号的修改包含从声源位置到收听者的耳朵的声学路径的模拟。
EEE 14.根据EEE 12或13所述的方法,其中,所述变换数据包含矩阵化系数和以下中的至少一个:声源位置或声源方向。
EEE 15.根据EEE 12至14中任一个所述的方法,其中,变换处理是根据时间或频率应用的。
EEE 16.根据EEE 12至15中任一个所述的方法,其中,辅助信号表示至少一个主导分量。
EEE 17.根据EEE 12至16中任一个所述的方法,其中,响应于头部方位数据使作为变换数据的一部分接收的声源位置或方向旋转。
EEE 18.根据EEE 17所述的方法,其中,最大旋转量限于在方位角或仰角上小于360度的值。
EEE 19.根据EEE 12至18中任一个所述的方法,其中,通过在变换域或滤波器组域中进行矩阵化来从第一表示获得第二表示。
EEE 20.根据EEE 12至19中任一个所述的方法,其中,变换数据进一步包括附加矩阵化系数,并且步骤(d)进一步包括在组合第一音频表示和(一个或多个)辅助音频信号之前响应于附加矩阵化系数对第一音频表示进行修改。
EEE 21.一种装置,该装置包括被配置为执行根据EEE 1至20中任一个所述的方法的一个或多个设备。
EEE 22.一种包括指令程序的计算机可读存储介质,该指令程序当被一个或多个处理器执行时使一个或多个设备执行根据EEE 1至20中任一个所述的方法。
- 用于参数化双耳输出系统和方法的头部跟踪
- 用于参数化双耳输出系统和方法的头部跟踪