一种图像检测方法、装置及存储介质
文献发布时间:2023-06-19 11:35:49
技术领域
本申请实施例涉及终端应用技术领域,尤其涉及一种图像检测方法、装置及存储介质。
背景技术
目前,用户大多通过终端的应用程序(Application,APP)的用户界面(UserInterface,UI),在网络上进行信息检索、与其他用户互动等操作,用户的生活越来越智能化,用户界面是系统和用户之间进行交互和信息交换的媒介,是介于用户与硬件而设计彼此之间交互沟通相关软件,目的是使用户能够方便有效率地去操作硬件以达成双向交互,完成希望借助硬件需要完成的工作。由于不同终端的硬件或软件存在差异,例如市场机型种类繁多、屏幕大小、分辨率各不相同,因此,在开发APP时难以全面兼顾各种终端的硬件或软件,容易出现因为APP与终端的硬件或软件不兼容而导致UI异常的问题,例如出现文字重叠。
在对现有技术的研究和实践过程中,本申请实施例的发明人发现,虽然现有技术只能依靠人工测试时观察应用的页面是否在不同的屏幕大小、分辨率的终端上发生文字重叠、错位等现象。一方面,依靠人工肉眼判断,费时耗力,所能手工覆盖的机型类型有限;另一方面,人工仅能检测到在UI中明显可见的重叠文字,当APP的界面背景繁杂时,容易漏检。因此,现有技术检测界面中的重叠文字的准确率不高且检测效率低。
发明内容
本申请实施例提供了一种图像检测方法、装置及存储介质,能够提高重叠文字的检测效率、准确率、以及提高测试的全面覆盖率。
第一方面中,本申请实施例提供一种图像检测方法,
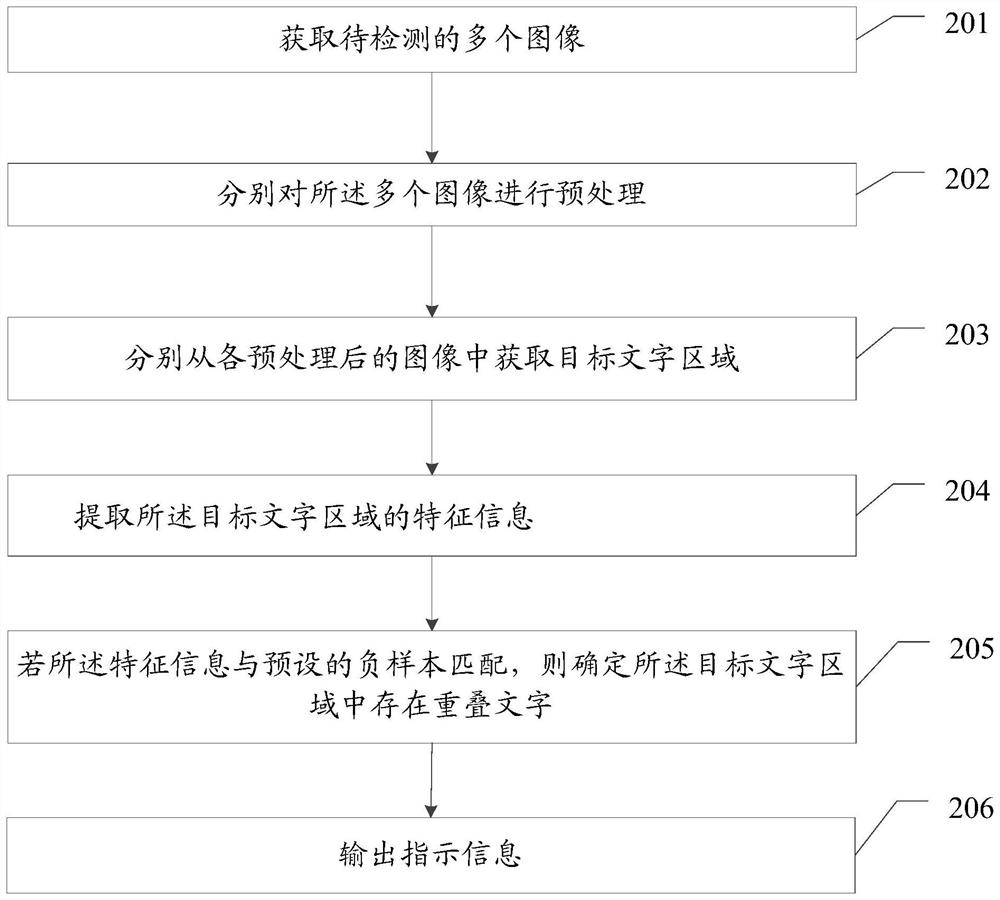
获取待检测的多个图像,所述图像为待检测应用的不同界面的截图;
分别对所述多个图像进行预处理;
分别从各预处理后的图像中获取目标文字区域;
提取所述目标文字区域的特征信息;
若所述特征信息与预设的负样本匹配,则确定所述目标文字区域中存在重叠文字;
输出指示信息,所述指示信息用于指示存在重叠文字的目标图像。
一种可能的设计中,所述确定所述目标文字区域中存在重叠文字之后,所述方法还包括:
确定所述目标图像中重叠文字的重叠位置;
在所述目标图像上的所述重叠位置设置标志,所述标志用于指示所述目标图像中包括重叠文字。
一种可能的设计中,所述确定所述目标文字区域中存在重叠文字之后,所述方法还包括:
分别计算存在重叠文字的异常图像的置信度;
将置信度高于预设置信度的异常图像作为所述目标图像。
一种可能的设计中,所述方法由神经网络模型实现,所述方法还包括:
获取多张样本图像;
基于所述多张样本图像生成训练样本,所述训练样本包括正样本和负样本;
将所述正样本和所述负样本分别输入文本检测模型,以训练所述文本检测模型。
一种可能的设计中,所述获取多张样本图像,包括:
确定待训练的样本类型,所述样本类型指示训练样本为正样本或负样本;
根据样本类型设置文本的文字类型,所述文字类型包括字号、字体、颜色、大小和文字风格中的至少一种;
根据文本的文字类型和至少两行文本,生成与所述样本类型对应的样本图像。
一种可能的设计中,所述至少两行文本包括第一行文本和第二行文本,所述基于所述多张样本图像生成训练样本,包括:
创建第一空白画布;
根据所述第一行文本的起始位置、文字大小、文字数量和所述空白画布的边长,在所述空白画布上设置第一行文本,所述第一行文本为第一方向;
根据所述第一行文本的起始位置和文字大小、以及第一预设条件,在所述第一空包画布上设置所述第二行文本,得到所述负样本;所述第二行文本为所述第一方向。
一种可能的设计中,所述第一行文本的起始位置满足:
0 所述第二行文本的起始位置满足: y0+fsize 其中,x0为所述第一行文本在第二方向上的起始位置,y0为所述第一行文本在所述第一方向上的起始位置,y1为所述第二行文本在所述第一方向上的起始位置,所述fsize为所述第一行文本的文字大小,S为所述第一空白画布的边长,所述第二方向与所述第一方向之间的夹角大于0。 一种可能的设计中,所述基于所述多张样本图像生成训练样本,包括: 创建第二空白画布; 在所述空白画布上设置第一行文本,所述第一行文本为第一方向; 根据所述第一行文本的起始位置和文字大小、以及第一预设条件,在所述空包画布上设置第二行文本,得到正样本;所述第二行文本为所述第一方向; 将所述正样本输入文本检测模型,以训练所述文本检测模块。 一种可能的设计中,所述第二行文本的起始位置满足: x0 其中,x0为所述第一行文本在第二方向上的起始位置,x1为所述第二行文本在所述第二方向上的起始位置,y0为所述第一行文本在所述第一方向上的起始位置,y1为所述第二行文本在所述第一方向上的起始位置,所述fsize为所述第一行文本的文字大小,S为所述第二空白画布的边长,所述第二方向与所述第一方向之间的夹角大于0,β1和β2根据所述文字大小得到。 一种可能的设计中,所述指示信息和所述负样本均保存在区块链节点上。 第二方面中,本申请实施例提供一种图像检测装置,具有实现对应于上述第一方面提供的图像检测方法的功能。所述功能可以通过硬件实现,也可以通过硬件执行相应的软件实现。硬件或软件包括一个或多个与上述功能相对应的模块,所述模块可以是软件和/或硬件。 一种可能的设计中,所述图像检测装置包括: 输入输出模块,获取待检测的多个图像,所述图像为待检测应用的不同界面的截图; 处理模块,用于分别对所述多个图像进行预处理;分别从各预处理后的图像中获取目标文字区域;提取所述目标文字区域的特征信息;若所述特征信息与预设的负样本匹配,则确定所述目标文字区域中存在重叠文字; 通过所述输入输出模块输出指示信息,所述指示信息用于指示存在重叠文字的目标图像。 一种可能的设计中,所述处理模块确定所述目标文字区域中存在重叠文字之后,还用于: 确定所述目标图像中重叠文字的重叠位置; 在所述目标图像上的所述重叠位置设置标志,所述标志用于指示所述目标图像中包括重叠文字。 一种可能的设计中,所述处理模块确定所述目标文字区域中存在重叠文字之后,还用于: 分别计算存在重叠文字的异常图像的置信度; 将置信度高于预设置信度的异常图像作为所述目标图像。 一种可能的设计中,所述方法由神经网络模型实现,所述处理模块还用于: 通过所述输入输出模块获取多张样本图像; 基于所述多张样本图像生成训练样本,所述训练样本包括正样本和负样本; 通过所述输入输出模块将所述正样本和所述负样本分别输入文本检测模型,以训练所述文本检测模型。 一种可能的设计中,所述处理模块具体用于: 确定待训练的样本类型,所述样本类型指示训练样本为正样本或负样本; 根据样本类型设置文本的文字类型,所述文字类型包括字号、字体、颜色、大小和文字风格中的至少一种; 根据文本的文字类型和至少两行文本,生成与所述样本类型对应的样本图像。 一种可能的设计中,所述至少两行文本包括第一行文本和第二行文本,所述处理模块具体用于: 创建第一空白画布; 根据所述第一行文本的起始位置、文字大小、文字数量和所述空白画布的边长,在所述空白画布上设置第一行文本,所述第一行文本为第一方向; 根据所述第一行文本的起始位置和文字大小、以及第一预设条件,在所述第一空包画布上设置所述第二行文本,得到所述负样本;所述第二行文本为所述第一方向。 一种可能的设计中,所述第一行文本的起始位置满足: 0 所述第二行文本的起始位置满足: y0+fsize 其中,x0为所述第一行文本在第二方向上的起始位置,y0为所述第一行文本在所述第一方向上的起始位置,y1为所述第二行文本在所述第一方向上的起始位置,所述fsize为所述第一行文本的文字大小,S为所述第一空白画布的边长,所述第二方向与所述第一方向之间的夹角大于0。 一种可能的设计中,所述处理模块具体用于: 创建第二空白画布; 在所述空白画布上设置第一行文本,所述第一行文本为第一方向; 根据所述第一行文本的起始位置和文字大小、以及第一预设条件,在所述空包画布上设置第二行文本,得到正样本;所述第二行文本为所述第一方向; 将所述正样本输入文本检测模型,以训练所述文本检测模块。 一种可能的设计中,所述第二行文本的起始位置满足: x0 其中,x0为所述第一行文本在第二方向上的起始位置,x1为所述第二行文本在所述第二方向上的起始位置,y0为所述第一行文本在所述第一方向上的起始位置,y1为所述第二行文本在所述第一方向上的起始位置,所述fsize为所述第一行文本的文字大小,S为所述第二空白画布的边长,所述第二方向与所述第一方向之间的夹角大于0,β1和β2根据所述文字大小得到。 一种可能的设计中,所述指示信息和所述负样本均保存在区块链节点上。 本申请实施例又一方面提供了一种图像检测装置,其包括至少一个连接的处理器、存储器和输入输出单元,其中,所述存储器用于存储计算机程序,所述处理器用于调用所述存储器中的计算机程序来执行上述第一方面所述的方法。 本申请实施例又一方面提供了一种计算机可读存储介质,其包括指令,当其在计算机上运行时,使得计算机执行上述第一方面所述的方法。 本申请实施例提供的方案中,由于正样本为预先设置,获取的图像为待检测应用的不同界面的截图,所以在将图像的特征信息与预设的负样本匹配时,能够准确的确定所述目标文字区域中存在重叠文字。相较于现有技术,本方案能够提高重叠文字的检测效率、准确率、以及提高测试的全面覆盖率。 附图说明 图1a为本申请实施例中的一种应用场景示意图; 图1b为本申请实施例中的一种应用场景示意图; 图2为本申请实施例中图像检测方法的一种流程示意图; 图3为本申请实施例中图像检测方法的一种流程示意图; 图4a为本申请实施例中的正样本的一种示意图; 图4b为本申请实施例中的正样本的一种示意图; 图4c为本申请实施例中的正样本的一种示意图; 图4d为本申请实施例中的正样本的一种示意图; 图5a为本申请实施例中的负样本的一种示意图; 图5b为本申请实施例中的负样本的一种示意图; 图5c为本申请实施例中的负样本的一种示意图; 图5d为本申请实施例中的负样本的一种示意图; 图6a为本申请实施例中的文本检测模型的一种分支结构示意图; 图6b为本申请实施例中的文本检测模型的一种分支结构示意图; 图6c为本申请实施例中的文本检测模型的一种分支结构示意图; 图7为本申请实施例中的区块链系统的一种结构示意图; 图8为本申请实施例中图像检测装置的一种结构示意图; 图9为本申请实施例中图像检测装置的一种结构示意图;。 具体实施方式 本申请实施例的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的实施例能够以除了在这里图示或描述的内容以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或模块的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或模块,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或模块,本申请实施例中所出现的模块的划分,仅仅是一种逻辑上的划分,实际应用中实现时可以有另外的划分方式,例如多个模块可以结合成或集成在另一个系统中,或一些特征可以忽略,或不执行,另外,所显示的或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,模块之间的间接耦合或通信连接可以是电性或其他类似的形式,本申请实施例中均不作限定。并且,作为分离部件说明的模块或子模块可以是也可以不是物理上的分离,可以是也可以不是物理模块,或者可以分布到多个电路模块中,可以根据实际的需要选择其中的部分或全部模块来实现本申请实施例方案的目的。 本申请实施例供了一种图像检测方法、装置及存储介质,该方案可用于服务器侧或者终端设备侧,服务器侧可应用到各类产品开发完成后的UI兼容性测试中,或者应用到对非APP客户端载体的其他媒介(例如H5页面、PC端、Mac端等)的截图进行检测。服务器侧可检测UI界面中的文字重叠、显示异常等操作。本申请实施例仅以服务器为例,服务器侧部署了图像检测装置,本申请实施例中图像检测装置可以是区块链系统中的节点。 图1a为本申请实施例的一种应用场景,测试人员对安装了同一APP的手机进行功能测试,截取手机APP的不同界面的图像并作为待检测图像,然后将这些待检测图像上传到图像检测装置,图像检测装置对这些待检测图像进行文字重叠识别,最后输出检测结果。其中,图像检测装置中部署了文本检测模型,该文本检测模型由多个场景的文字图片训练得到。具体来说,本申请实施例主要提供以下技术方案: 通过生成多个场景(如随机文字、不同字体、颜色、大小、艺术形态)的文字图片,用多个场景的文字图片对文本检测模型进行训练,使得文本检测模型能够判别图片中是否存在文字重叠现象。例如图1b所示,通过运行UI自动化脚本以遍历APP的各个页面,并获取对应的UI截图,将UI截图输入场景文本识别模型,通过场景文本识别模型检测出UI截图中的文字区域,再判断UI截图中是否存在文字区域,且是否存在非文字异常。若存在文字的区域,则截取存在文字的区域,并采样为预设像素大小(例如64*64)的待测样本。将待测样本输入文本检测模型,通过文本检测模型对待测样本中的文字进行分类鉴别(即判断文字区域中的文字是否存在重叠),例如若检测出页面文字无异常,则将待测样本分为正样本;若检测出页面文字存在重叠,则将待测样本分为负样本,并报错。整个检测过程都是自动进行,且由于文本检测模型是基于多个场景的文字图片训练得到,所以能够更全面的覆盖文字重叠的多种异常场景,进而提高检测效果。 参照图2,以下介绍本申请实施例所提供的一种图像检测方法,可以应用到UI客户端的随机测试工具,还可以应用到开发、测试过程中的任意涉及页面展示的环节,本申请实施例不对应用场景作限定。本申请实施例包括: 201、获取待检测的多个图像。 其中,所述图像为待检测应用的不同界面的截图。本申请实施例中的待检测的图像可以是静态图,也可以是动态图。本申请实施例中待检测的多个图像可为APP的不同页面的截图;待检测的多个图像也可以是非APP载体的其他媒介的不同页面的截图,例如待检测的多个图像为H5页面、PC端、Mac端等的截图。本申请实施例不对待检测的多个图像的来源作限定。 例如,终端通过接收图像检测请求,根据图像检测请求获取待检测的UI截图(即待检测的图像)。终端可以从网络数据库中获取其他终端采集的待检测的图像、或者服务器获取待检测的图像。终端也可以从自身的存储器中获取(需要预先截取图像或者从其他渠道获取图像,并存储在终端的存储器中)待检测的图像。或者终端对用户针对待检测应用响应时对应的界面进行截图,例如终端采用内置的截图软件对不同响应的界面进行动画录制,将动画中的每张图片作为上述待检测的多个图像。本申请实施例不对获取待检测的图像的获取方式、获取时间、获取渠道和存储方式作限定。 可选的,在本申请实施例中,待检测的用户界面截图可以为各个APP在运行过程中,任意用户界面对应的界面截图等。该用户界面截图可以包括针对该应用程序在终端运行过程中,用户界面的视频图像截图、用户界面的聊天图像截图、用户界面的游戏图像截图等,上述应用程序可以为任意终端上安装的任意应用程序。在本申请实施例中,对此不作具体限定。 202、分别对所述多个图像进行预处理。 其中,预处理可包括:图像畸变处理、锐化、去噪等处理。通过对图像进行预处理,能够更好的获取目标文字区域,以及识别目标文字区域中是否存在文字重叠现象。 203、分别从各预处理后的图像中获取目标文字区域。 一些实施方式中,可调用场景文本识别(Detecting Text in Natural Imagewith Connectionist Text Proposal Network,CTPN)模型对待检测的图像检测,将各预处理后的图像输入到CTPN模型中,通过调用CTPN模型检测各预处理后的图像是否存在疑似文字、以及文字所在的位置信息。若待检测的图像不存在文字区域,则丢弃该图像;若预处理后的图像存在文字区域,则采用标注框框选图像中的文字区域,并对该文字区域进行裁剪采样,以得到预设像素大小(例如64×64像素)的目标文字区域的图像,并继续对该图像进入步骤204处理。 204、提取所述目标文字区域的特征信息。 其中,所述目标文字区域的特征信息是指字体、在图像中的位置信息、文字的轮廓信息等。 一些实施方式中,可通过文本检测模型提取目标文字区域的特征信息。可选的,文本检测模型可基于残差网络(Residual Networks,ResNet)训练得到。 205、若所述特征信息与预设的负样本匹配,则确定所述目标文字区域中存在重叠文字。 其中,负样本是指存在重叠文字的图像。负样本可包括多张图像,每张图像均存在重叠文字,各图像中的文字重叠方式、重叠程度、重叠文字的文字类型、重叠文字的倾斜角度等均不作限定。 一些实施方式中,负样本可通过随机文字、不同字体、颜色、大小、艺术形态训练文件检测模型得到。这样得到的负样本就可以全面的检测不同场景下的文字重叠现象。一方面,提高检测的范围,另一方面,提高检测的准确率,代替人工判断。 例如,将预处理后的待检测图像文字区域图像输入文本检测模型中,文本检测模型中的卷积层(Convolutional Layers)将对待检测文字区域图像进行特征提取,将输出的特征向量输入到训练好的分类器全连接层(Fully Connected Layers,FC)中,并确定提取的待检测图像的特征图与哪一分类(有文字重叠图像类别、无文字重叠类别)最为吻合,得到不同分类的正确概率,输出分类结果,最终获得图像检测结果。 例如,将预处理后的待检测文字区域图像输入训练后的文本检测模型中,CNN将对待检测文字区域图像进行特征提取,将提取的特征向量与训练后的CNN中的权重矩阵W融合,得到第一概率值,文本检测模型根据第一概率值预测提取的待检测图像的特征图与有文字重叠图像类别最为吻合,则输出分类结果:待检测文字区域图像含文字重叠异常,待检测图像具有文字重叠异常。 例如,将预处理后的待检测文字区域图像输入文本检测模型中,CNN将对待检测文字区域图像进行特征提取,将提取的特征向量与训练后的CNN中的权重矩阵W融合,得到第二概率值,文本检测模型根据第二概率值预测提取的待检测图像的特征图与无文字重叠图像类别最为吻合,则输出分类结果:待检测文字区域图像无文字重叠异常,待检测图像为无文字重叠异常。 综上可述,本实施例在获取了图像后,对该图像进行边缘检测和分词处理,得到该图像的特征向量,对该特征向量进行编码,得到用于图像检测的特征向量,通过文本检测模型预测待检测图像的图像类别即可得到对应的检测结果,本申请实施例能够提高检测准确率和检测效率。 一些实施方式中,还可以根据目标文字区域的特征信息确定文字类型,根据文字类型从预设的多个预设的训练样本(包括正样本和负样本中的至少一个)中确定一个与文字类型对应的训练样本,然后调用该文字类型的训练样本,与该训练样本进行比较。可见,根据文字类型确定用于检测重叠文字的训练样本,能够提高检测的准确率和检测效率。可以同时将该文字类型的正样本、负样本分别与上述特征信息进行匹配,哪个样本能与该特征信息匹配,则可确定该特征信息对应的文字区域的检测结果,例如,正样本与该特征信息匹配,则可确定该特征信息对应的文字区域不存在重叠文字;该特征信息匹配,则可确定该特征信息对应的文字区域存在重叠文字。 206、输出指示信息。 其中,所述指示信息用于指示存在重叠文字的目标图像。便于定位存在重叠文字的图像,以及便于快速的了解APP出现文字重叠的严重程度。 一些实施方式中,所述确定所述目标文字区域中存在重叠文字之后,所述方法还包括: 确定所述目标图像中重叠文字的重叠位置; 在所述目标图像上的所述重叠位置设置标志,所述标志用于指示所述目标图像中包括重叠文字。通过该标志,能够快速的定位重叠文字在目标图像中的位置。 一些实施方式中,所述确定所述目标文字区域中存在重叠文字之后,所述方法还包括: 分别计算存在重叠文字的异常图像的置信度; 将置信度高于预设置信度的异常图像作为所述目标图像。 通过设置置信度,能够减少误报率,或者减少重叠问题较轻的上报数量,便于着重于分析重叠严重的界面。 一些实施方式中,还可以针对一个APP的多个特定页面进行更高精度的检测。或者,根据经验值来选择要重点识别的界面图像,例如借鉴其他APP通常出现文字重叠的界面,本申请实施例重点检测相同或相似界面是否出现文字重叠,这样,能够有针对性的识别,并且提高识别效率。 与现有机制相比,本申请实施例中,由于正样本为预先设置,获取的图像为待检测应用的不同界面的截图,所以在将图像的特征信息与预设的负样本匹配时,能够准确的确定所述目标文字区域中存在重叠文字。相较于现有技术,本方案能够提高重叠文字的检测效率、准确率、以及提高测试的全面覆盖率。一方面中,能够有效地降低人工检查、肉眼测试的工作量,更高效地对不同分辨率、不同屏幕大小的机型进行同步检测,提高兼容性测试覆盖率。另一方面中,即使UI异常出现的部位非常细微,采用本申请实施例中的图像检测方法也能够全方位地遍历每一个页面的每一处文字展示,有效避免人工检查导致的漏检。 可选的,在一些实施方式中,所述方法由神经网络模型实现,获取训练样本(包括正样本和负样本),其中,正样本是指文字正常显示且没有发生文字重叠的图像,负样本是指发生文字重叠的图像。如图3所示,训练文本检测模型的流程包括: 301、获取多张样本图像。 其中,所述多张样本图像包括字号、字体、颜色、大小和文字风格中的至少一种类型组合的文字图片。样本图像可从素材库中获取。素材库可通过随机选用常用文字1000个、各类中文英文字体集、场景不同的背景图片形成。其中,样本图像中文字的字体、文字的颜色、背景图像等要素随机生成,根据所述样本图像获取规则获取训练样本。 一些实施方式中,所述获取多张样本图像,包括: 确定待训练的样本类型,所述样本类型指示训练样本为正样本或负样本; 根据样本类型设置文本的文字类型,所述文字类型包括字号、字体、颜色、大小、文字风格、语言类型中的至少一种;其中语言类型可包括中文、英文、日文、韩文等不同语种的语言文字,文字类型还可包括数字,本申请实施例不对此作限定。 根据文本的文字类型和至少两行文本,生成与所述样本类型对应的样本图像。 本申请实施例中的第一行文本和第二行文本可以时随机生成,也可以时按照预设规则生成,本申请实施例不对第一行文本和第二行文本中的文字类型、第一行文本和第二行文本的生成方式作限定。 一些实施方式中,所述样本图像获取规则为:首先,在随机位置生成第一行文字;然后根据重叠规则,相对第一行文字生成第二行文字。根据所述样本图像获取规则获取样本图像并对样本图像进行标注,得到样本图像的标签信息:如果样本图像中没有文字重叠,则得到正样本;如果样本图像含文字重叠,则得到负样本。将获得的正样本与负样本添加至训练样本中。 302、对训练样本进行预处理。 具体的,本申请实施例对预设样本获取模型获取的正样本与负样本图像进行预处理。由于当前文字图像的场景中,模型的任务目标是判别待检测图像中文字是否重叠,不适宜改变图像使待检测图像中的文字变形或者不可读,因此,在本步骤中对预设样本获取模型获取的正样本与负样本图像的预处理方式,主要为对图像进行裁剪、增强、旋转、移位、调整色调、对比度和饱和度等图片增强手段即可。 具体的,对训练集生成模型生成的正样本与负样本图像进行预处理后,在输入残差网络前,正样本与负样本均裁切为64×64像素图像。 综上所述,本申请实施例对训练样本集中的正样本与负样本图像进行图像预处理的操作能够丰富样本场景,提高模型鲁棒性。 303、基于所述多张样本图像生成训练样本。 其中,训练样本包括多张样本图像。所述训练样本包括正样本和负样本。 可选的,本申请实施例可采用python获取正样本与负样本构成训练样本。具体的,在python的绘画模块任意创建一个正方形的空白画布,该空白画布的边长为S,S为正整数。下面分别介绍正样本和负样本的生成过程: (1)构建正样本: 首先,创建第一空白画布,根据所述第一行文本的起始位置、文字大小、文字数量和所述空白画布的边长,在所述空白画布上设置第一行文本,所述第一行文本为第一方向。 然后,根据所述第一行文本的起始位置和文字大小、以及第一预设条件,在所述第一空包画布上设置第二行文本,得到所述负样本;所述第二行文本为所述第一方向。 最后,将所述负样本输入文本检测模型,以训练所述文本检测模块。 一些实施方式中,重叠规则包括对所述第一行文本的起始位置和所述第二行文本的起始位置的控制,具体来说,所述第一行文本的起始位置满足: 0 所述第二行文本的起始位置满足: y0+fsize 其中,x0为所述第一行文本在第二方向上的起始位置,y0为所述第一行文本在所述第一方向上的起始位置,y1为所述第二行文本在所述第一方向上的起始位置,所述fsize为所述第一行文本的文字大小,S为所述第一空白画布的边长,所述第二方向与所述第一方向之间的夹角大于0。 例如,在第一空白画布中央横向生成N个文字即第一行文本,N1为正整数;设定文字大小为fsize1,并控制文字起止点均不超出第一空白画布,例如:在第一空白画布中设置二维坐标系,设置第一行文本中文字的起始点坐标为s0(x0,y0),并控制x0>0,S>y0且S>x0+fsize1×N1且S>y0+fsize。然后,在生成第一行文字的基础上横向生成N2个文字即第二行文字,N2为正整数;设定文字大小为fsize,并控制文字起止点均不超出画布,例如:在空白画布中设定笛卡尔二维坐标系,规定文字的起始点坐标为s0(x0,y0),并控制x0>0,S>y0且S>x0+fsize1×N2且S>y0+fsize2。 由于文字可能存在多种场景,例如,常规字体、艺术字体、背景繁杂等,故最终得到的正样本也不同。图4a和图4b均为简单标准文字下的正样本,图4c为艺术文字下的正样本,图4d为背景复杂的正样本。 (2)构建负样本: 首先,创建第二空白画布,在所述空白画布上设置第一行文本,所述第一行文本为第一方向。 然后,根据所述第一行文本的起始位置和文字大小、以及第一预设条件,在所述空包画布上设置第二行文本,得到正样本;所述第二行文本为所述第一方向。 最后,将所述正样本输入文本检测模型,以训练所述文本检测模块。 一些实施方式中,重叠规则包括对所述第一行文本的起始位置和所述第二行文本的起始位置的控制,具体来说,所述第一行文本的起始位置满足: 0 所述第二行文本的起始位置满足: x0 其中,x0为所述第一行文本在第二方向上的起始位置,x1为所述第二行文本在所述第二方向上的起始位置,y0为所述第一行文本在所述第一方向上的起始位置,y1为所述第二行文本在所述第一方向上的起始位置,所述fsize为所述第一行文本的文字大小,S为所述第二空白画布的边长,所述第二方向与所述第一方向之间的夹角大于0,β1和β2根据所述文字大小得到。例如β1和β2的值可以设定为fsize/5,以防止第二行文字的起始点正好靠近第一行文字的末尾,产生了互不重叠的样本,例如:第二行文字的起始点与第一行有任意交叉。更多负样本的生成能够以此类推,在此不做赘述。 由于文字可能存在多种场景,例如,常规字体、艺术字体、背景繁杂等,故最终得到的负样本也不同。图5a和图5b均为简单标准文字下的负样本,图5c为艺术文字下的负样本,图5d为背景复杂的负样本。 304、将所述正样本和所述负样本分别输入文本检测模型,以训练所述文本检测模型。 具体的,本申请实施例将经过预处理后的训练样本中的正样本与负样本图像输入文本检测模型中,提取正样本与负样本的图像特征,将正样本与负样本的图像特征输入所述文本检测模型中,根据模型的收敛情况,不断调整文本检测模型的各种超参数,以得到最终分类准确率相对最高的、收敛速度相对最快的文本检测模型。对文本检测模型通过验证集反馈调整CNN中的权重矩阵W,使得目标损失函数的值降低,本申请实施例中采用训练样本训练17次时已经能在测试集中达到100%的分类准确率。 一些实施方式中,由于文本中的文字为连续,且图像中的文字存在空间特征,所以,可在文本检测模型中引入CNN和长短期记忆网络((Long Short-Term Memory,LSTM)。所述文本检测模型可包括双向LSTM,CNN可获取图像中文字的空间信息,LSTM可获得图像中文字的序列特征,便于检测各种朝向的文字,例如不仅能检测横向分布的文字,在LSTM中加入水平Anchor后还能检测竖直分布的文字。 可见,能够通过更换文字、更换字体、更换不同样式的背景素材、更换相对文字大小、更换文字排列方式将上述获取样本图像的过程重复无数次,以便得到场景更丰富的训练样本。本申请实施例通过预设样本获取模型获取的正样本与负样本图像,能够自定义预设规则以获取样式不一的训练样本,能够得到场景更丰富的训练样本。 其中,文本检测模型可以根据实际应用的需求进行设定,以该结构为CNN为例,CNN包括输入层、多个卷积层、多个池化层、多个全连接层以及输出层,网络的层数至少为15层;其中,输入层是整个文本检测模型的输入部分,输入层的图像可以为彩色图像或灰度图像。 一些实施方式中,如图6a、图6b和图6c分别为文本检测模型的分支结构示意图,图6a、图6b和图6c按照标号先后顺序依次连接。本申请实施例中的文本检测模型的主干网络结构可为18层的残差网络(Residual Network-18,ResNet-18)。对含有重叠文字异常区域的图片以及正常的图片进行训练,包括以下步骤: (1)对前一步骤生成的图片进行预处理。针对当前文字的场景,任务目标是判别正常文字的重叠,所以不适宜改变图片使得文字变形或者不可读;只需尝试随机旋转(RandomRotation)、移位(Translation)的图片增强手段即可,丰富样本场景,提高模型鲁棒性。输入网络前均裁切(Resize)至64*64像素。 (2)预处理后的图片送入Resnet-18进行卷积。Resnet沿用了VGG网络(VisualGeometry Group,VGG-Net)全3×3卷积层的设计。首先经过1个3x3的卷积,接着经过8个残差模块(Residual block),残差块里首先有2个有相同输出通道数的3×3卷积层。每个卷积层后接一个批量归一化层和激活函数。然后将输入跳过这两个卷积运算后直接加在最后的激活函数前。 (3)再经过1个的平均池化层(Average Pooling),保留主要的特征同时降低数据的维度。 (4)最后将得到的数据输入一个全连接层,映射到异常、正常的二分类结果上。 上述训练样本在网络中多次迭代后,得到在这个异常检测场景下拟合效果较好的前向网络模型。 可选的,为了提高文本检测模型的表达能力,还可以通过加入激活函数来加入非线性因素,在本申请实施例中,该激活函数可为线性整流函数(Rectified Linear Unit,ReLU),而填充(padding,指属性定义元素边框与元素内容之间的空间)方式均为“same”,“same”填充方式可以简单理解为以0填充边缘,左边(上边)补0的个数和右边(下边)补0的个数一样或少一个;卷积层对输入层输入的图像进行卷积操作,提取卷积特征,提取的卷积特征经过激活函数的非线性映射,在一定程度上给网络带来了稀疏性,减少了参数之间的相互依存关系,缓解了过拟合问题。 综上所述,本申请实施例中的文本检测模型采用Resnet-18,残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。 本申请实施例中,上述训练样本、指示信息均可保存在区块链中。其中,区块链是分布式数据存储、点对点传输、共识机制、加密算法等计算机技术的新型应用模式。区块链(Blockchain),本质上是一个去中心化的数据库,是一串使用密码学方法相关联产生的数据块,每一个数据块中包含了一批次网络交易的信息,用于验证其信息的有效性(防伪)和生成下一个区块。区块链可以包括区块链底层平台、平台产品服务层以及应用服务层。 区块链底层平台可以包括用户管理、基础服务、智能合约以及运营监控等处理模块。其中,用户管理模块负责所有区块链参与者的身份信息管理,包括维护公私钥生成(账户管理)、密钥管理以及用户真实身份和区块链地址对应关系维护(权限管理)等,并且在授权的情况下,监管和审计某些真实身份的交易情况,提供风险控制的规则配置(风控审计);基础服务模块部署在所有区块链节点设备上,用来验证业务请求的有效性,并对有效请求完成共识后记录到存储上,对于一个新的业务请求,基础服务先对接口适配解析和鉴权处理(接口适配),然后通过共识算法将业务信息加密(共识管理),在加密之后完整一致的传输至共享账本上(网络通信),并进行记录存储;智能合约模块负责合约的注册发行以及合约触发和合约执行,开发人员可以通过某种编程语言定义合约逻辑,发布到区块链上(合约注册),根据合约条款的逻辑,调用密钥或者其它的事件触发执行,完成合约逻辑,同时还提供对合约升级注销的功能;运营监控模块主要负责产品发布过程中的部署、配置的修改、合约设置、云适配以及产品运行中的实时状态的可视化输出,例如:告警、监控网络情况、监控节点设备健康状态等。 本申请实施例中执行图像检测方法的装置(也可称作服务器或终端)可以是区块链系统中的节点。本申请实施例中的图像检测装置可以是如图8所示的一种区块链系统中的节点。 图1a至图7中任一项所对应的实施例中所提及的任一技术特征也同样适用于本申请实施例中的图8和图9所对应的实施例,后续类似之处不再赘述。 以上对本申请实施例中一种图像检测方法进行说明,以下对执行上述图像检测方法的装置进行介绍。 上面对本申请实施例中的一种图像检测方法进行了描述,下面对本申请实施例中的图像检测装置进行描述。 参阅图8,如图8所示的一种图像检测装置的结构示意图,其可应用于检测重叠文字。本申请实施例中的图像检测装置能够实现对应于上述图1a至图7中任一项所对应的实施例中所执行的图像检测方法的步骤。图像检测装置实现的功能可以通过硬件实现,也可以通过硬件执行相应的软件实现。硬件或软件包括一个或多个与上述功能相对应的模块,所述模块可以是软件和/或硬件。所述图像检测装置可包括处理模块和输入输出模块,所述处理模块、所述输入输出模块的功能实现可参考图1a至图7中任一项所对应的实施例中所执行的操作,此处不作赘述。例如,所述处理模块可用于控制所述输入输出模块的输入输出操作。 一些实施方式中,所述输入输出模块可用于获取待检测的多个图像,所述图像为待检测应用的不同界面的截图; 所述处理模块可用于分别对所述多个图像进行预处理;分别从各预处理后的图像中获取目标文字区域;提取所述目标文字区域的特征信息;若所述特征信息与预设的负样本匹配,则确定所述目标文字区域中存在重叠文字; 通过所述输入输出模块输出指示信息,所述指示信息用于指示存在重叠文字的目标图像。 本申请实施例中,由于正样本为预先设置,所述输入输出模块获取的图像为待检测应用的不同界面的截图,所以在所示处理模块将图像的特征信息与预设的负样本匹配时,能够准确的确定所述目标文字区域中存在重叠文字。相较于现有技术,本方案能够提高重叠文字的检测效率、准确率、以及提高测试的全面覆盖率。 一些实施方式中,所述处理模块确定所述目标文字区域中存在重叠文字之后,还用于: 确定所述目标图像中重叠文字的重叠位置; 在所述目标图像上的所述重叠位置设置标志,所述标志用于指示所述目标图像中包括重叠文字。 一些实施方式中,所述处理模块确定所述目标文字区域中存在重叠文字之后,还用于: 分别计算存在重叠文字的异常图像的置信度; 将置信度高于预设置信度的异常图像作为所述目标图像。 一些实施方式中,所述方法由神经网络模型实现,所述处理模块还用于: 通过所述输入输出模块获取多张样本图像; 基于所述多张样本图像生成训练样本,所述训练样本包括正样本和负样本; 通过所述输入输出模块将所述正样本和所述负样本分别输入文本检测模型,以训练所述文本检测模型。 一些实施方式中,所述处理模块具体用于: 确定待训练的样本类型,所述样本类型指示训练样本为正样本或负样本; 根据样本类型设置文本的文字类型,所述文字类型包括字号、字体、颜色、大小和文字风格中的至少一种; 根据文本的文字类型和至少两行文本,生成与所述样本类型对应的样本图像。 一些实施方式中,所述至少两行文本包括第一行文本和第二行文本,所述处理模块具体用于: 创建第一空白画布; 根据所述第一行文本的起始位置、文字大小、文字数量和所述空白画布的边长,在所述空白画布上设置第一行文本,所述第一行文本为第一方向; 根据所述第一行文本的起始位置和文字大小、以及第一预设条件,在所述第一空包画布上设置所述第二行文本,得到所述负样本;所述第二行文本为所述第一方向。 一些实施方式中,所述处理模块具体用于: 创建第二空白画布; 在所述空白画布上设置第一行文本,所述第一行文本为第一方向; 根据所述第一行文本的起始位置和文字大小、以及第一预设条件,在所述空包画布上设置第二行文本,得到正样本;所述第二行文本为所述第一方向; 将所述正样本输入文本检测模型,以训练所述文本检测模块。 上面从模块化功能实体的角度对本申请实施例中的图像检测装置进行了描述,下面从硬件处理的角度分别对本申请实施例中的图像检测装置进行描述。图8所示的装置可以具有如图9所示的结构,当图8所示的装置具有如图9所示的结构时,图9中的处理器和输入输出单元能够实现前述对应该装置的装置实施例提供的处理模块和收发模块相同或相似的功能,图9中的中央存储器存储处理器执行上述图像检测方法时需要调用的计算机程序。在本申请实施例图8所示的实施例中的输入输出模块所对应的实体设备可以为输入输出接口,处理模块对应的实体设备可以为处理器。 在上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。 所属领域的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统,装置和模块的具体工作过程,可以参考前述方法实施例中的对应过程,在此不再赘述。 在本申请实施例所提供的几个实施例中,应该理解到,所揭露的系统,装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述模块的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个模块或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或模块的间接耦合或通信连接,可以是电性,机械或其它的形式。 所述作为分离部件说明的模块可以是或者也可以不是物理上分开的,作为模块显示的部件可以是或者也可以不是物理模块,即可以位于一个地方,或者也可以分布到多个网络模块上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。 另外,在本申请实施例各个实施例中的各功能模块可以集成在一个处理模块中,也可以是各个模块单独物理存在,也可以两个或两个以上模块集成在一个模块中。上述集成的模块既可以采用硬件的形式实现,也可以采用软件功能模块的形式实现。所述集成的模块如果以软件功能模块的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。 在上述实施例中,可以全部或部分地通过软件、硬件、固件或者其任意组合来实现。当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。 所述计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行所述计算机计算机程序时,全部或部分地产生按照本申请实施例所述的流程或功能。所述计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。所述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一计算机可读存储介质传输,例如,所述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(DSL))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。所述计算机可读存储介质可以是计算机能够存储的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。所述可用介质可以是磁性介质,(例如,软盘、硬盘、磁带)、光介质(例如,DVD)、或者半导体介质(例如固态硬盘Solid State Disk(SSD))等。 以上对本申请实施例所提供的技术方案进行了详细介绍,本申请实施例中应用了具体个例对本申请实施例的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本申请实施例的方法及其核心思想;同时,对于本领域的一般技术人员,依据本申请实施例的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本申请实施例的限制。
- 一种图像检测方法、图像检测装置、设备及存储介质
- 图像质量检测方法、装置、存储介质及产品检测方法