基于视觉目标检测和重识别的多源两阶段菜品识别方法
文献发布时间:2023-06-19 11:35:49
技术领域
本发涉及信息技术领域中的计算机视觉和模式识别技术,具体是一种基于视觉目标检测和重识别的多源两阶段菜品识别方法。
背景技术
餐厅和食堂是生活中大众用餐的地方,但是传统的餐厅和食堂收银结账流程是个既费时又费力的过程,而且由于收银员的精力有限,不能一直保持高效工作且不出错,另外,当客流量激增的时候,收银结账的速度成为了食堂运转效率的一大瓶颈,除此之外,大量的不断更新的菜品也为收银员准确结算增加了难度,所以单单凭人工结账收银已经远远满足不了应用需求的快速增长,餐厅、食堂收银结账迫切需要通过智能化手段来大幅提高结账收银效率,降低收银成本。餐厅、食堂中菜品识别算法是智能结算技术的核心组成部件,如果能够自动地在收银场景中对菜品进行长时间持续地识别,就能够极大的提高收银效率,大幅降低收银成本,将结账收银带入一个全新的智能化时代。尽管经过全世界各国专家和学者多年的不懈研究,目标识别算法取得了长足的进步。但是,在实际的应用场景中一些具有挑战的因素,诸如类别不确定、部分遮挡、类间和类内相似性干扰、姿态变化,光照变化等因素,仍使得菜品识别算法的大规模应用和达到工业标准应用面临重重困难。
发明内容
本发明的目的是针对现有技术的不足,而提供一种基于视觉目标检测和重识别的多源两阶段菜品识别方法。这种方法通过结合目标检测和重识别技术来定位和识别菜品,能提高实际菜品识别的鲁棒性和精度。
实现本发明目的的技术方案是:
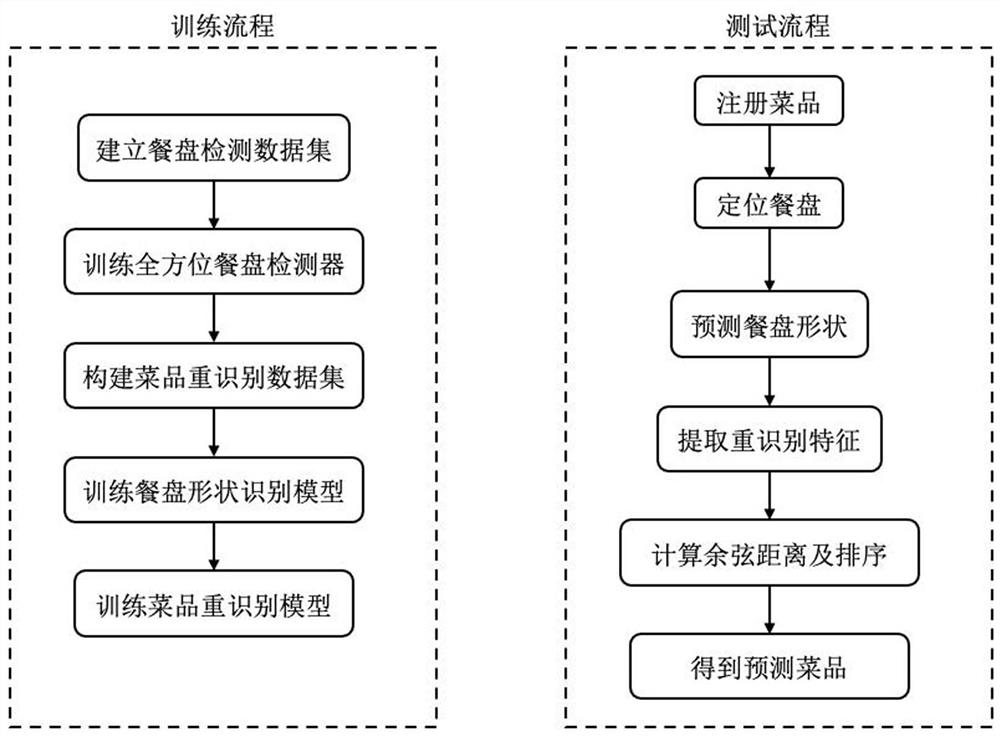
一种基于视觉目标检测和重识别的多源两阶段菜品识别方法,包括训练流程和测试流程,其中训练流程包括如下步骤:
1-1)建立餐盘检测数据集:在真实的不同餐厅和食堂环境中采集餐盘检测数据集,餐盘检测数据集中每张图片中的托盘上的餐盘中都有盛着不同菜品、或菜品以外的其它物品或空餐盘,餐盘的图片采用垂直向下视角进行图像采集,对采集的图像进行标注,标注包括采集的图像矩形边框的旋转角度、餐盘的颜色、餐盘的形状和菜品的名称,将餐盘检测数据集分为训练集和测试集,测试集中餐盘中的菜品种类不包含在训练集中餐盘中的菜品种类中;
1-2)训练全方位餐盘检测器:首先定义全方位餐盘检测器,全方位餐盘检测器采用旋转的边界框来定位餐盘,全方位餐盘检测器为单阶段检测器即能够一次性预测出目标的位置和类别、并且参数量小于10M,全方位餐盘检测器采用图片的长边为计算角度的参考轴、设为h,图片的短边表示为w,以水平线为参考,设逆时针方向为正方向、角度的定义域为[0°,180°],将角度预测作为一个包含180个类别的分类任务,其中180个类别对应180度的分类任务,全方位餐盘检测器的训练过程为:全方位餐盘检测器的检测模型以Yolo v5为基准模型进行训练,训练全方位检测器的训练样本从步骤1)得到的训练集中选取,训练样本类别总数为3类,包括餐盘类、空盘类、饮料类,然后再加上旋转边界框的中心点位置、宽、高、旋转角度这些在训练过程中使模型要去拟合的对象,每次输入一个批次的图片,一个批次含有16张图片,然后对这些图片进行尺度处理即将这些图片的长边缩放到480像素,再对短边不足480像素的部分用黑色填充,就得到了尺寸为480*480像素的一批次图片,接着将这些处理好的图片输入到模型中,输出得到网络的预测值,包括目标类别、边界框的中心点、宽、高、旋转角度,然后,将这些预测值与真实值进行损失计算即采用如公式(1)所示损失函数对目标类别预测、旋转角度预测进行优化:
其中,L代表损失函数,y表示角度的真实值,
其中,L
1-3)构建菜品重识别数据集:将餐盘检测数据集中的所有图片里盛有餐品的餐盘按照所标注的边界框裁剪保存,并且记录下所裁剪图片中对应的菜品的名称构成菜品重识别数据集,菜品重识别数据集共包含 18870张菜品图片,然后将所有的图片分成训练集和测试集两部分;
1-4)训练餐盘形状识别模型:对每一个餐盘的图像进行了有规则的数据增强即将分类模型的输入设置为224*224,在调整大小之前先对图像进行填充:将每一个餐盘的图像的长边缩放到224像素,并且用黑色像素填充短边不足224 像素的部分,得到224*224像素的图片,然后将处理好的图片作为分类模型的输入数据,分类模型包括多尺度的特征提取网络和分类头网络,首先定义如下:
卷积块1的输入为通道数为C的特征向量,包括顺序连接的特征输出通道数为6C的卷积核尺寸为1*1的卷积层、批归一化层、Swish激活函数、卷积核尺寸为k*k的深度可分离卷积层,其中,k的值在使用时候确定、作通道相乘操作的批归一化层、Swish激活函数、池化层、全连接层-作用为降维、Swish激活函数、全连接层-作用为升维、Sigmoid激活函数、特征输出通道数为C的卷积核尺寸为1*1的卷积层、批归一化层、随机丢弃层,其中,最后一个随机丢弃层的输出特征与卷积块1最开始的输入特征作累加操作;
卷积块2的输入为通道数为C的特征向量,包括顺序连接的特征输出通道数为C的卷积核尺寸为3*3的深度可分离卷积层、批归一化层、Swish激活函数、作通道相乘操作的池化层、全连接层-作用为降维、Swish激活函数、全连接层- 作用为升维、Sigmoid激活函数、卷积核尺寸为1*1的卷积层、批归一化层;
卷积块3的输入为通道数为C的特征向量,包括顺序连接的特征输出通道数为6C的卷积核尺寸为1*1的卷积层、批归一化层、Swish激活函数、作通道相乘操作的卷积核尺寸为k*k的深度可分离卷积层,其中k在不同地方取不同的值、批归一化层、Swish激活函数、池化层、全连接层-作用为降维、Swish激活函数、全连接层-作用为升维、Sigmoid激活函数、特征输出通道数为C的卷积核尺寸为1*1的卷积层、批归一化层,
所述多尺度的特征提取网络为顺序连接的输出为尺寸为112*112*16卷积块2、卷积核尺寸为3*3的卷积层、批归一化层、输出为尺寸为56*56*24激活函数、卷积块3-其中参数k为3、输出为尺寸为28*28*40卷积块1-其中卷积块 3中的参数k为3、卷积块3-其中卷积块3中的参数k为5、输出为尺寸为 14*14*80卷积块1-其中卷积块3中的参数k为5、卷积块3-其中卷积块3中的参数k为3、卷积块1-其中卷积块3中的参数k为3、卷积块3-其中卷积块3中的参数k为3、输出为尺寸为14*14*112卷积块1-其中卷积块3中的参数k为 3、卷积块3-其中卷积块3中的参数k为5、卷积块1-其中卷积块3中的参数k为5、卷积块3-其中卷积块3中的参数k为5、卷积块1-其中卷积块3中的参数k为5、卷积块3-其中卷积块3中的参数k为5、卷积块1-其中卷积块 3中的参数k为5、卷积块3-其中卷积块3中的参数k为5、卷积块1-其中卷积块3中的参数k为5、卷积块3-其中卷积块3中的参数k为5、输出为尺寸为7*7*192卷积块1-其中卷积块3中的参数k为5、输出尺寸为7*7*320卷积块 3-其中卷积块3中的参数k为3、卷积核尺寸为3*3的卷积层、批归一化层、 7*7*1280Swish激活函数,多尺度特征提取网络的输入是尺寸为224*224*3的图片;
所述分类头网络包括顺序连接的全局池化层、随机失活层、全连接层 1024*n,其中,1024表示输入全连接层的特征通道数,n表示全连接层输出的特征通道数,n的值取决于分类类别数目,此处n的值为餐盘形状的种类数,分类头网络的输入是尺寸为7*7*1280特征向量,在餐盘检测数据集中预定义6种形状进行分类,即圆形、正方形、三角形、椭圆形、菱形和桶形形状分类,分类模型的输出是一个尺寸为1*n的向量,n表示为类别数量-这里是6,这个向量表示的含义是对应每个类别分类模型给出的预测分数值,预测分数最高的那个类别为分类模型预测的分类结果,将分类模型的输出和真实形状值进行比较,并采用交叉熵损失函数来进行优化预测,直到交叉熵损失函数收敛;
1-5)训练菜品重识别模型:菜品重识别模型结构包括主干网络和与主干网络连接的特征映射头网络及属性预测头网络,其中,主干网络为MobileNetV2特征映射头网络包括顺序连接的自适应平均池化层、批归一化层(1024)、全连接层 (1024*n),属性预测头网络包括顺序连接的全局平均池化层、批归一化层(1024)、全连接层(1024*m),其中,批归一化层的1024表示输入和输出该层的特征通道数,全连接层的1024表示输入该层的特征通道数,n表示输出该层的特征通道数,n的值取决于分类类别数目,此处n的值为菜品的种类数,m也表示为输出该层的特征通道数,m的值取决于分类类别数目,此处m的值为餐盘的形状类别总数加上颜色类别总数,菜品重识别模型训练时,给定餐盘图像,先将图像缩放到224*224像素输入到主干网络中得到主干网络的输出即图片的特征,将此输出分别再输入到特征映射头网络和属性预测头网络,将特征映射头网络的输出和真实菜品种类进行计算损失,将属性预测头网络得到的输出,和真实餐盘形状和颜色进行计算损失,这两个损失都采用交叉熵损失函数进行优化,重复此训练过程一直到交叉熵损失函数收敛,对标签作平滑的操作,如公式(3)所示:
其中P是平滑操作后的标签,ε是人为设定的超参数,K表示多分类的类别总数,i表示当前所选的类别值,y表示此标签的真实类别值;
所述测试流程是将步骤1-1)得到的餐盘检测数据集中的测试集作为测试样本包括如下步骤:
2-1)注册菜品:将所有种类的菜品进行一次注册,首先采用全方位餐盘检测器检测出餐盘的位置,然后将按照检测出的餐盘区域边界框范围把餐盘区域裁剪出来分别输入到餐盘形状识别模型和菜品重识别模型中,从餐盘形状识别模型输出得到餐盘形状,从菜品重识别模型输出得到菜品图片特征,从而得到餐盘形状信息以及菜品图片的特征,将菜品的特征、餐盘的形状信息保存在数据库即注册库中;
2-2)定位餐盘:采用分辨率为1920*1080的固定相机,采用垂直向下视角进行对餐盘的图像采集,然后得到图片,再将图片输入到全方位餐盘检测模型中,输出得到餐盘、空盘、饮料的边界框位置,然后裁剪下餐盘的图片并将裁剪下餐盘的图片保存以待后续流程使用;
2-3)预测餐盘形状:将裁剪得到的餐盘图片输入到餐盘形状识别模型中,预测得到餐盘的形状类别;
2-4)提取重识别特征:将裁剪得到的餐盘图片输入到菜品重识别模型中,输出得到菜品图片的特征并保存;
2-5)计算余弦距离及排序:对注册库中的菜品以步骤2-3)得到的餐盘形状类别为约束粗筛选一次即选出注册库中满足此餐盘形状的菜品,然后再计算步骤2-4)得到的特征与筛选后的注册库中菜品特征之间的的余弦距离,最后将这些计算得到的余弦距离按照值从小到大进行排序;
2-6)得到预测菜盘:最终,将步骤2-5)排好序的余弦距离取最小的距离的那个菜品中类则作为最终识别结果。
菜品识别常常被看作是一个两阶段的任务,通常是在第一阶段对图像进行检测得到餐盘的位置,然后在第二阶段对具体菜品进行识别,然而,在第一阶段,通常使用的检测器只能用水平的标注框来定位餐盘,而餐盘摆放的方向又是随机不规则的,这就会使得标注框内引入多余的背景干扰信息从而影响后续识别的精度,另外,更重要的是,在第二阶段,如果出现之前没出现过的新菜品,那么传统的只能识别的固定类别数目的分类模型就不能正确识别菜品,为了解决上述问题,使在菜品识别中既能精确定位各式摆放的餐盘又能鲁棒识别新旧菜品,本技术方案利用任意方向的目标检测和重识别的两阶段的算法来进行菜品识别。
本技术方案首先使用建立的菜品识别数据集来训练支持任意方向定位的目标检测器,再利用这个数据集裁剪出每个菜品的图片构成一个新的数据集,然后利用它来训练重识别模型和形状分类模型;在餐厅和食堂实际使用的时候,只需对每个菜注册一次,训练好的检测模型首先会对摄像头采集的图片实时进行餐盘检测;检测到餐盘后,形状分类模型对餐盘形状进行分类,随后重识别模型对其提取特征,并结合餐盘形状信息在已注册的菜品库里找到特征度量距离最近的菜品来完成识别。
本技术方案与现有基于传统分类模型的菜品识别方法相比具有诸多优点和有益效果:传统的分类模型需要提前定义好需要分类的类别,它能够处理的范围被限制在固定的类别里,这种方式在遇到识别新的类别时候就会无法处理,从而导致算法崩溃,而本技术方案将菜品识别视为重识别的过程,只需在用餐前对新的菜品进行简单注册,即能支持对新类别的识别;与传统的分类模型不同,本技术方案加入了三个重要模块来增强模型的判别力和精度:(1)引入全方向的餐盘检测模块,它能用任意方向的边界框来标注餐盘以最大程度的贴合餐盘边缘,这能够解决传统水平边界框标注方式引入的冗余背景噪音;(2)在重识别模型中增加了属性分支,利用局部信息(餐盘的形状和颜色)来使得模型学习到更加鲁棒的特征映射;(3)加入了形状分类模块来作为辅助的约束条件来进行后处理,既能减少干扰物的影响又能加快菜品的检索速度。
这种方法通过结合目标检测和重识别技术来定位和识别菜品,解决菜品类别数目不确定的挑战来适应在实际场景中不同餐厅不同时间段菜品不固定的情况;通过提取餐盘的形状和颜色信息作为辅助来提高模型在复杂场景下的判别力,最终能提高实际菜品识别的鲁棒性和精度。
附图说明
图1为本例方法与现有菜品识别方法的流程对比图示意图;
图2为全方位边界框餐盘检测器的样例图,其中左侧为本例方法支持全方位边界框的餐盘检测结果,右侧为现有菜品识别产品的餐盘检测的结果;
图3为本例建立的数据集的标注样例图;
图4为本例中全方位检测器中关于旋转角度的定义示意图;
图5为本例方法的流程示意图;
图6本例中的分类模型结构图;
图7为本例中的重识别网络模型结构图。
具体实施方式
下面结合附图和实施例对本发明的内容足进一步的阐述,但不是对本发明的限定。
实施例:
参照图5,一种基于视觉目标检测和重识别的多源两阶段菜品识别方法,包括训练流程和测试流程,其中训练流程包括如下步骤:
1-1)建立餐盘检测数据集:如图3所示,在真实的不同餐厅和食堂环境中采集餐盘检测数据集,餐盘检测数据集中每张图片中的托盘上的餐盘中都有盛着不同菜品、或菜品以外的其它物品或空餐盘,餐盘的图片采用垂直向下视角进行图像采集,对采集的图像进行标注,标注包括采集的图像矩形边框的旋转角度、餐盘的颜色、餐盘的形状和菜品的名称,将餐盘检测数据集分为训练集和测试集,测试集中餐盘中的菜品种类不包含在训练集中餐盘中的菜品种类中;
1-2)训练全方位餐盘检测器:首先定义全方位餐盘检测器,全方位餐盘检测器采用旋转的边界框来定位餐盘,全方位餐盘检测器为单阶段检测器即能够一次性预测出目标的位置和类别、并且参数量小于10M,如图4所示,全方位餐盘检测器采用图片的长边为计算角度的参考轴、设为h,图片的短边表示为w,以水平线为参考,设逆时针方向为正方向、角度的定义域为[0°,180°],将角度预测作为一个包含180个类别的分类任务,其中180个类别对应180度的分类任务,全方位餐盘检测器的训练过程为:全方位餐盘检测器的检测模型以Yolo v5为基准模型进行训练,训练全方位检测器的训练样本从步骤1)得到的训练集中选取,训练样本类别总数为3类,包括餐盘类、空盘类、饮料类,然后再加上旋转边界框的中心点位置、宽、高、旋转角度这些在训练过程中使模型要去拟合的对象,每次输入一个批次的图片,一个批次含有16张图片,然后对这些图片进行尺度处理即将这些图片的长边缩放到480像素,再对短边不足480像素的部分用黑色填充,就得到了尺寸为480*480像素的一批次图片,接着将这些处理好的图片输入到模型中,输出得到网络的预测值,包括目标类别、边界框的中心点、宽、高、旋转角度,然后,将这些预测值与真实值进行损失计算即采用如公式(1)所示损失函数对目标类别预测、旋转角度预测进行优化:
其中,L代表损失函数,y表示角度的真实值,
其中,L
1-3)构建菜品重识别数据集:将餐盘检测数据集中的所有图片里盛有餐品的餐盘按照所标注的边界框裁剪保存,并且记录下所裁剪图片中对应的菜品的名称构成菜品重识别数据集,菜品重识别数据集共包含 18870张菜品图片,然后将所有的图片分成训练集和测试集两部分;
1-4)训练餐盘形状识别模型:对每一个餐盘的图像进行了有规则的数据增强即将分类模型的输入设置为224*224,在调整大小之前先对图像进行填充:将每一个餐盘的图像的长边缩放到224像素,并且用黑色像素填充短边不足224 像素的部分,得到224*224像素的图片,然后将处理好的图片作为分类模型的输入数据,分类模型包括多尺度的特征提取网络和分类头网络,如图6所示,首先定义如下:
卷积块1的输入为通道数为C的特征向量,包括顺序连接的特征输出通道数为6C的卷积核尺寸为1*1的卷积层、批归一化层、Swish激活函数、卷积核尺寸为k*k的深度可分离卷积层,其中,k的值在使用时候确定、作通道相乘操作的批归一化层、Swish激活函数、池化层、全连接层-作用为降维、Swish激活函数、全连接层-作用为升维、Sigmoid激活函数、特征输出通道数为C的卷积核尺寸为1*1的卷积层、批归一化层、随机丢弃层,其中,最后一个随机丢弃层的输出特征与卷积块1最开始的输入特征作累加操作;
卷积块2的输入为通道数为C的特征向量,包括顺序连接的特征输出通道数为C的卷积核尺寸为3*3的深度可分离卷积层、批归一化层、Swish激活函数、作通道相乘操作的池化层、全连接层-作用为降维、Swish激活函数、全连接层- 作用为升维、Sigmoid激活函数、卷积核尺寸为1*1的卷积层、批归一化层;
卷积块3的输入为通道数为C的特征向量,包括顺序连接的特征输出通道数为6C的卷积核尺寸为1*1的卷积层、批归一化层、Swish激活函数、作通道相乘操作的卷积核尺寸为k*k的深度可分离卷积层,其中k在不同地方取不同的值、批归一化层、Swish激活函数、池化层、全连接层-作用为降维、Swish激活函数、全连接层-作用为升维、Sigmoid激活函数、特征输出通道数为C的卷积核尺寸为1*1的卷积层、批归一化层,
所述多尺度的特征提取网络为顺序连接的输出为尺寸为112*112*16卷积块2、卷积核尺寸为3*3的卷积层、批归一化层、输出为尺寸为56*56*24激活函数、卷积块3-其中参数k为3、输出为尺寸为28*28*40卷积块1-其中卷积块 3中的参数k为3、卷积块3-其中卷积块3中的参数k为5、输出为尺寸为 14*14*80卷积块1-其中卷积块3中的参数k为5、卷积块3-其中卷积块3中的参数k为3、卷积块1-其中卷积块3中的参数k为3、卷积块3-其中卷积块3中的参数k为3、输出为尺寸为14*14*112卷积块1-其中卷积块3中的参数k为 3、卷积块3-其中卷积块3中的参数k为5、卷积块1-其中卷积块3中的参数k为5、卷积块3-其中卷积块3中的参数k为5、卷积块1-其中卷积块3中的参数k为5、卷积块3-其中卷积块3中的参数k为5、卷积块1-其中卷积块 3中的参数k为5、卷积块3-其中卷积块3中的参数k为5、卷积块1-其中卷积块3中的参数k为5、卷积块3-其中卷积块3中的参数k为5、输出为尺寸为7*7*192卷积块1-其中卷积块3中的参数k为5、输出尺寸为7*7*320卷积块 3-其中卷积块3中的参数k为3、卷积核尺寸为3*3的卷积层、批归一化层、 7*7*1280Swish激活函数,多尺度特征提取网络的输入是尺寸为224*224*3的图片;
所述分类头网络包括顺序连接的全局池化层、随机失活层、全连接层 1024*n,其中,1024表示输入全连接层的特征通道数,n表示全连接层输出的特征通道数,n的值取决于分类类别数目,此处n的值为餐盘形状的种类数,分类头网络的输入是尺寸为7*7*1280特征向量,在餐盘检测数据集中预定义6种形状进行分类,即圆形、正方形、三角形、椭圆形、菱形和桶形形状分类,分类模型的输出是一个尺寸为1*n的向量,n表示为类别数量-这里是6,这个向量表示的含义是对应每个类别分类模型给出的预测分数值,预测分数最高的那个类别为分类模型预测的分类结果,将分类模型的输出和真实形状值进行比较,并采用交叉熵损失函数来进行优化预测,直到交叉熵损失函数收敛;
1-5)训练菜品重识别模型:如图7所示,菜品重识别模型结构包括主干网络和与主干网络连接的特征映射头网络及属性预测头网络,其中,主干网络为 MobileNetV2特征映射头网络包括顺序连接的自适应平均池化层、批归一化层 (1024)、全连接层(1024*n),属性预测头网络包括顺序连接的全局平均池化层、批归一化层(1024)、全连接层(1024*m),其中,批归一化层的1024表示输入和输出该层的特征通道数,全连接层的1024表示输入该层的特征通道数,n表示输出该层的特征通道数,n的值取决于分类类别数目,此处n的值为菜品的种类数,m也表示为输出该层的特征通道数,m的值取决于分类类别数目,此处m的值为餐盘的形状类别总数加上颜色类别总数,菜品重识别模型训练时,给定餐盘图像,先将图像缩放到224*224像素输入到主干网络中得到主干网络的输出即图片的特征,将此输出分别再输入到特征映射头网络和属性预测头网络,将特征映射头网络的输出和真实菜品种类进行计算损失,将属性预测头网络得到的输出,和真实餐盘形状和颜色进行计算损失,这两个损失都采用交叉熵损失函数进行优化,重复此训练过程一直到交叉熵损失函数收敛,对标签作平滑的操作,如公式(3)所示:
其中P是平滑操作后的标签,ε是人为设定的超参数,K表示多分类的类别总数,i表示当前所选的类别值,y表示此标签的真实类别值;
所述测试流程是将步骤1-1)得到的餐盘检测数据集中的测试集作为测试样本包括如下步骤:
2-1)注册菜品:将所有种类的菜品进行一次注册,首先采用全方位餐盘检测器检测出餐盘的位置,然后将按照检测出的餐盘区域边界框范围把餐盘区域裁剪出来分别输入到餐盘形状识别模型和菜品重识别模型中,从餐盘形状识别模型输出得到餐盘形状,从菜品重识别模型输出得到菜品图片特征,从而得到餐盘形状信息以及菜品图片的特征,将菜品的特征、餐盘的形状信息保存在数据库即注册库中;
2-2)定位餐盘:采用分辨率为1920*1080的固定相机,采用垂直向下视角进行对餐盘的图像采集,然后得到图片,再将图片输入到全方位餐盘检测模型中,输出得到餐盘、空盘、饮料的边界框位置,然后裁剪下餐盘的图片并将裁剪下餐盘的图片保存以待后续流程使用;
2-3)预测餐盘形状:将裁剪得到的餐盘图片输入到餐盘形状识别模型中,预测得到餐盘的形状类别;
2-4)提取重识别特征:将裁剪得到的餐盘图片输入到菜品重识别模型中,输出得到菜品图片的特征并保存;
2-5)计算余弦距离及排序:对注册库中的菜品以步骤2-3)得到的餐盘形状类别为约束粗筛选一次即选出注册库中满足此餐盘形状的菜品,然后再计算步骤2-4)得到的特征与筛选后的注册库中菜品特征之间的的余弦距离,最后将这些计算得到的余弦距离按照值从小到大进行排序;
2-6)得到预测菜盘:最终,将步骤2-5)排好序的余弦距离取最小的距离的那个菜品中类则作为最终识别结果。
菜品识别常常被看作是一个两阶段的任务,通常是在第一阶段对图像进行检测得到餐盘的位置,然后在第二阶段对具体菜品进行识别,然而,在第一阶段,通常使用的检测器只能用水平的标注框来定位餐盘,而餐盘摆放的方向又是随机不规则的,这就会使得标注框内引入多余的背景干扰信息从而影响后续识别的精度,另外,更重要的是,在第二阶段,如果出现之前没出现过的新菜品,那么传统的只能识别的固定类别数目的分类模型就不能正确识别菜品,如图1所示,为了解决上述问题,使在菜品识别中既能精确定位各式摆放的餐盘又能鲁棒识别新旧菜品,本例可应用于食堂自助结账领域,能够支持任意的对菜品信息进行增加、删除、修改,并且在训练的过程中还利用了餐盘的颜色和形状信息作为辅助来提高模型的判别力。
- 基于视觉目标检测和重识别的多源两阶段菜品识别方法
- 基于深度学习目标检测和度量学习的开放性菜品识别方法