一种数据统计方法、装置及终端设备
文献发布时间:2023-06-19 11:39:06
技术领域
本发明涉及计算机技术领域,尤其涉及一种数据统计方法、装置及终端设备。
背景技术
在大数据时代,数据也越来越被政府或企业所使用,单节点的数据库已经很难满足大数据背景下的存储和计算要求,多节点的分布式数据库的应用越来越广泛。
如果对单节点数据库中存储的数据进行如方差、标准差的数据统计,可以使用数据库原生的统计函数直接进行统计得到结果。其中,数据库原生的统计函数只应用于全表统计的数据环境,因此需要待统计数据存储在同一个数据节点。
而在分布式数据库中,同一个表的数据分布存储在不同的数据节点,无法使用数据库原生的统计函数进行计算和数据统计。对此,目前常见的技术方案是,将全表数据迁移到一个节点上再使用数据库原生的统计函数,但这种技术方案降低了数据统计效率。
发明内容
本发明的主要目的在于提出一种数据统计方法、装置及终端设备,以解决现有技术中在多节点的分布式数据库的基础上,进行样本方差、样本标准差、总体方差、总体标准差的计算时,会降低数据统计效率的问题。
为实现上述目的,本发明实施例第一方面提供一种数据统计方法,应用于存储有待统计目标表的分布式数据库,待统计目标表的表数据存储在分布式数据库的N个数据节点中,所述数据统计方法包括:
获取到数据统计指令时,在所述N个数据节点中提取满足第一检索条件的表数据作为目标数据;所述表数据包括行数标签、字段信息和属性标签;
按照预设计算规则对所述目标数据进行处理,获得通用数据;
根据所述通用数据和所述数据统计指令生成数据统计SQL语句,在任一个所述数据节点执行所述数据统计SQL语句,完成所述数据统计指令;
其中,N为正整数。
结合本发明实施例第一方面,本发明实施例第一实施方式中,获取到数据统计指令时,在所述N个数据节点中提取满足第一检索条件的表数据作为目标数据,包括:
遍历所述分布式数据库的N个数据节点;
遍历第n个所述数据节点时,若第n个所述数据节点的表数据的属性标签满足所述第一检索条件,则所述表数据为满足第一检索条件的表数据;
其中,n为小于或者等于N的正整数。
结合本发明实施例第一方面,本发明实施例第二实施方式中,按照预设计算规则对所述目标数据进行处理,获得通用数据,包括:
获取第n个所述数据节点的目标数据时,根据预设计算规则选择预设类型字段信息,并根据所述行数标签和预设类型字段信息计算基于第n个所述数据节点的目标数据的行数总和、预设类型字段信息总和;
根据基于N个数据节点的目标数据的行数总和、预设类型字段信息总和计算基于N个数据节点的目标数据的字段均值;
根据所述基于N个数据节点的目标数据的行数总和、预设类型字段信息总和及所述字段均值,对基于N个数据节点的目标数据的每个预设类型字段信息进行中间值计算,获得行数据中间值,并将所述行数据中间值进行总和;
将总和后的行数据中间值作为所述通用数据。
结合本发明实施例第一方面第二实施方式,本发明实施例第三实施方式中,根据所述通用数据和所述数据统计指令生成数据统计SQL语句,包括:
分析所述数据统计指令,所述数据统计指令为计算总体方差时,使用所述通用数据和所述数据统计指令生成计算总体方差的数据统计SQL语句,公式为:
A=sum_var/count_score;
其中,sum_var为所述通用数据,count_score为N个所述数据节点的行数总和。
结合本发明实施例第一方面第二实施方式,本发明实施例第四实施方式中,根据所述通用数据执行所述数据统计指令,包括:
分析所述数据统计指令,所述数据统计指令为计算样本方差时,使用所述通用数据和所述数据统计指令生成计算样本方差的数据统计SQL语句,公式为:
B=sum_var/(count_score-1);
其中,sum_var为所述通用数据,count_score为N个所述数据节点的行数总和。
结合本发明实施例第一方面第二实施方式,本发明实施例第五实施方式中,根据所述通用数据执行所述数据统计指令,包括:
分析所述数据统计指令,所述数据统计指令为计算总体标准差时,使用所述通用数据和所述数据统计指令生成计算总体标准差的数据统计SQL语句,公式为:
C=pow(sum_var/count_score,1/2);
其中,sum_var为所述通用数据,count_score为N个所述数据节点的行数总和。
结合本发明实施例第一方面第二实施方式,本发明实施例第六实施方式中,根据所述通用数据执行所述数据统计指令,包括:
分析所述数据统计指令,所述数据统计指令为计算样本偏差时,使用所述通用数据和所述数据统计指令生成计算样本偏差的数据统计SQL语句,公式为:
D=pow(sum_var/(count_score-1),1/2);
其中,sum_var为所述通用数据,count_score为N个所述数据节点的行数总和。
本发明实施例第二方面提供一种数据统计装置,应用于存储有待统计目标表的分布式数据库,待统计目标表的表数据存储在分布式数据库的N个数据节点中,所述数据统计装置包括:
目标数据提取模块,用于获取到数据统计指令时,在所述N个数据节点中提取满足第一检索条件的表数据作为目标数据;所述表数据分为K组,每组所述表数据包括行数标签、字段信息和属性标签;
目标数据处理模块,包括按照预设计算规则对所述目标数据进行处理,获得通用数据;
数据统计指令执行模块,用于根据所述通用数据和所述数据统计指令生成数据统计SQL语句,在任一个所述数据节点执行所述数据统计SQL语句,完成所述数据统计指令;
其中,N为正整数。
本发明实施例的第三方面提供了一种终端设备,包括存储器、处理器以及存储在上述存储器中并可在上述处理器上运行的计算机程序,上述处理器执行上述计算机程序时实现如上第一方面所提供的方法的步骤。
本发明实施例的第四方面提供了一种计算机可读存储介质,上述计算机可读存储介质存储有计算机程序,上述计算机程序被处理器执行时实现如上第一方面所提供的方法的步骤。
本发明实施例提出一种数据统计方法,在获取到数据统计指令时,在分布式数据的N个数据节点中提取满足第一检索条件的表数据,并在执行数据统计指令之前,对表数据进行处理,获得通用数据,然后根据通用数据和数据统计指令生成数据统计SQL语句,从而可以在任意一个数据节点执行数据统计SQL语句,完成数据统计指令,不受限于分布式数据库数据分布在不同的节点,无法使用数据库原生的统计函数进行计算和数据统计的情况,从而避免了数据迁移所造成的统计效率降低的问题。
附图说明
图1为本发明实施例提供的数据统计方法的实现流程示意图;
图2为本发明实施例提供的数据统计装置的组成结构示意图。
本发明目的的实现、功能特点及优点将结合实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。
在本文中,使用用于表示元件的诸如“模块”、“部件”或“单元”的后缀仅为了有利于本发明的说明,其本身并没有特定的意义。因此,"模块"与"部件"可以混合地使用。
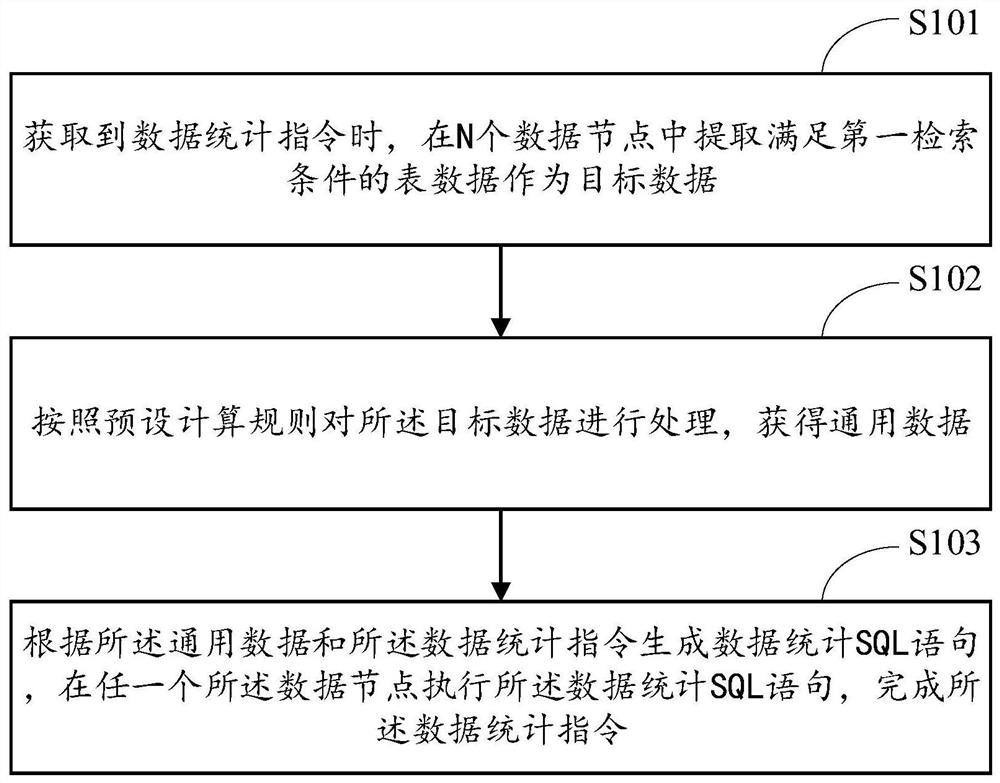
如图1所示,本发明实施例提供一种数据统计方法,应用于存储有待统计目标表的分布式数据库,待统计目标表的表数据存储在分布式数据库的N个数据节点中,所述数据统计方法包括但不限于如下步骤:
S101、获取到数据统计指令时,在所述N个数据节点中提取满足第一检索条件的表数据。
在具体应用中,分布式数据库包括分立的N个数据节点,每个数据节点存储一部分的待统计目标表的表数据,其中,表数据包括行数标签、字段信息和属性标签。因此,通过上述步骤S101,在N个数据节点中提取的表数据可以来自多个不同的数据节点。
其中,N为正整数。
在本发明实施例中,第一检索条件与表数据的属性标签关联,上述步骤S101的一种实现方式可以为:
遍历所述分布式数据库的N个数据节点;
遍历第n个所述数据节点时,若第n个所述数据节点的表数据的属性标签满足所述第一检索条件,则所述表数据为满足第一检索条件的表数据。
其中,n为小于或者等于N的正整数。
本发明实施例还示例性地示出分布式数据库的表数据提取过程;
如下所示,表1和表2为同一个待统计目标表在分布式数据库的两个数据节点中存储的表数据,将表1作为第1个数据节点存储的待统计目标表的表数据,表2作为第2个数据节点存储的待统计目标表的表数据,示例性地,本实施例中,表1表2所示的表数据包括行数标签id、属性标签name、属性标签class和字段信息score,具体地,行数标签id位于第一列,属性标签name位于第二列,属性标签class位于第三列,字段信息score位于第四列。
表1
表2
假设第一检索条件为属性标签class=1,根据上述步骤S101,在上述的分布式数据库中提取的满足第一检索条件的表数据,也即目标数据,为表1中的第一行数据和第二行数据,以及表2中的第一行数据和第三行数据,表示为:
表1中的
{id=1,name=aaa,class=1,score=90};
{id=2,name=bbb,class=1,score=98};
表2中的
{id=1,name=ddd,class=1,score=87};
{id=1,name=fff,class=1,score=96}。
S102、按照预设计算规则对所述表数据进行处理,获得通用数据。
上述步骤S102中,预设计算规则可以为针对任一类型的字段信息,所进行的样本方差、样本标准差、总体方差、总体标准差计算的统计函数。
需要说明的是,数据统计指令包括预设计算规则的指定,且其可以指定上述预设计算规则中的一种或多种。
在本发明实施例中,使用数据统计方法进行基于分布式数据库的方差统计及标准差统计,因此,示例性的,上述步骤S102的实现方式为:
获取第n个所述数据节点的目标数据时,根据预设计算规则选择预设类型字段信息,并根据所述行数标签和预设类型字段信息计算第n个所述数据节点的目标数据的行数总和、预设类型字段信息总和;
根据N个所述数据节点的目标数据的行数总和、预设类型字段信息总和计算N个所述数据节点的目标数据的字段均值;
根据N个所述数据节点的目标数据的行数总和、预设类型字段信息总和及所述字段均值,对N个所述数据节点的目标数据的每个预设类型字段信息进行中间值计算,获得行数据中间值,并将所述行数据中间值进行总和;
将总和后的行数据中间值作为所述通用数据。
根据上文示出的分布式数据库,即将待统计目标表的表数据分别存储在两个数据节点(表1和表2)中的分布式数据库,本实施例中,在使用数据统计方法进行基于分布式数据库的方差统计及标准差统计时,预设计算规则即基于表1和表2的class=1的表数据,进行字段信息score的方差、标准差计算,目标数据仍为表1中的第一行数据和第二行数据,以及表2中的第一行数据和第三行数据。
且示例性地,基于第1个数据节点获取目标数据时,即表1中的第一行数据和第二行数据时,将基于第1个数据节点的目标数据的行数总和记为count1,count1=1+1=2,将基于第1个数据节点的目标数据的预设类型字段信息总和记为sum1,sum1=90+98=188;基于第2个数据节点获取目标数据时,即表2中的第一行数据和第三行数据时,将基于第2个数据节点的目标数据的行数总和记为count2,count2=1+1=2,将基于第2个所述数据节点的目标数据的预设类型字段信息总和记为sum2,sum1=87+96=183;
根据基于此2个数据节点的目标数据的行数总和、预设类型字段信息总和,可以得出基于此2个数据节点的目标数据的字段均值,记为avg_score,avg_score=sum_score/count_score=92.75,其中,sum_score=sum1+sum2,count_score=count1+count2。
结合方差统计及标准差统计的计算原理,本实施例中,在根据基于此2个数据节点的目标数据的行数总和、预设类型字段信息总和及字段均值,对基于此2个数据节点的目标数据的每个预设类型字段信息进行中间值计算,获得的行数据中间值实际上为方差统计及标准差统计计算过程中均使用的中间式,即(score-avg_score)平方,其中,score为基于此2个数据节点的目标数据的每个预设类型字段信息,即上表1和表2中的score=90、score=98、score=87、score=96。则通用数据,即总和后的行数据中间值示例性地用sum_var表示,
S103、根据所述通用数据和所述数据统计指令生成数据统计SQL语句,在任一个所述数据节点执行所述数据统计SQL语句,完成所述数据统计指令。
在上述步骤S103中,数据统计SQL(Structured Query Language,结构化查询语言)语句为基于分布式数据库的查询和程序设计语言。
在本发明实施例中,使用数据统计方法进行基于分布式数据库的方差统计及标准差统计,因此,本实施例中,数据统计指令包括方差统计规则、标准差统计规则以及统计的字段信息的类型。
本发明实施例示出上述步骤S103的四种实现方式,在一个实施例中,根据所述通用数据和所述数据统计指令生成数据统计SQL语句,包括:
分析所述数据统计指令,所述数据统计指令为计算总体方差时,使用所述通用数据和所述数据统计指令生成计算总体方差的数据统计SQL语句,公式为:
A=sum_var/count_score;
其中,sum_var为所述通用数据,count_score为N个所述数据节点的行数总和。
在另一实施例中,根据所述通用数据执行所述数据统计指令,包括:
分析所述数据统计指令,所述数据统计指令为计算样本方差时,使用所述通用数据和所述数据统计指令生成计算样本方差的数据统计SQL语句,公式为:
B=sum_var/(count_score-1);
其中,sum_var为所述通用数据,count_score为N个所述数据节点的行数总和。
在又一实施例中,根据所述通用数据执行所述数据统计指令,包括:
分析所述数据统计指令,所述数据统计指令为计算样本偏差时,使用所述通用数据和所述数据统计指令生成计算样本偏差的数据统计SQL语句,公式为:
D=pow(sum_var/(count_score-1),1/2);
其中,sum_var为所述通用数据,count_score为N个所述数据节点的行数总和。
在又一实施例中,根据所述通用数据执行所述数据统计指令,包括:
分析所述数据统计指令,所述数据统计指令为计算总体标准差时,使用所述通用数据和所述数据统计指令生成计算总体标准差的数据统计SQL语句,公式为:
C=pow(sum_var/count_score,1/2);
其中,sum_var为所述通用数据,count_score为N个所述数据节点的行数总和。
在具体应用中,根据所述通用数据和所述数据统计指令生成的数据统计SQL语句,以及在任一个所述数据节点执行所述数据统计SQL语句,示例性的可以为:
从DN1...DNn任选一个数据节点执行
select
pow(sum_var/count_score,1/2)as stddev_pop,
pow(sum_var/(count_score-1),1/2)as stddev_samp,
sum_var/count_score as var_pop,
sum_var/(count_score-1)as var_samp from T limit 1得到结果;
如图2所示,本发明实施例提供一种数据统计装置20,应用于存储有待统计目标表的分布式数据库,待统计目标表的表数据存储在分布式数据库的N个数据节点中,所述数据统计装置20包括:
目标数据提取模块21,用于获取到数据统计指令时,在所述N个数据节点中提取满足第一检索条件的表数据作为目标数据;所述表数据分为K组,每组所述表数据包括行数标签、字段信息和属性标签;
目标数据处理模块22,包括按照预设计算规则对所述目标数据进行处理,获得通用数据;
数据统计指令执行模块23,用于根据所述通用数据和所述数据统计指令生成数据统计SQL语句,在任一个所述数据节点执行所述数据统计SQL语句,完成所述数据统计指令
其中,N为正整数。
本发明实施例提供的数据统计装置,在获取到数据统计指令时,提取满足第一检索条件的表数据,并在执行数据统计指令之前,对表数据进行处理,获得通用数据,然后根据通用数据和数据统计指令生成数据统计SQL语句,从而可以在任意一个数据节点执行数据统计SQL语句,完成数据统计指令,不受限于分布式数据库数据分布在不同的节点,无法使用数据库原生的统计函数进行计算和数据统计的情况,从而避免了数据迁移所造成的统计效率降低的问题。
本发明实施例还提供一种终端设备包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现如上述实施例中所述的数据统计方法中的各个步骤。
本发明实施例还提供一种存储介质,所述存储介质为计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现如上述实施例中所述的数据统计方法中的各个步骤。
以上所述实施例仅用以说明本发明的技术方案,而非对其限制;尽管前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围,均应包含在本发明的保护范围之内。
- 一种数据统计方法、装置及终端设备
- 一种使用数据统计方法、装置、终端设备及存储介质