特征尿蛋白对covid-19轻重级进行分型的非诊断方法及应用
文献发布时间:2023-06-19 11:55:48
技术领域
本发明涉及生物医药领域,特别涉及一种特征尿蛋白对covid-19轻重级进行分型的非诊断方法及应用。
背景技术
Covid-19的临床病症以发热、干咳、乏力等为主要表现,少数患者伴有鼻塞、流涕、腹泻等上呼吸道和消化道症状,Covid-19的肆虐威胁着世界上数亿人的健康,根据世卫组织的报告,截至2021年1月4日,全球有超过8300万人感染了SARS-CoV-2,死亡人数超过180万。在临床实践中,约80%的Covid-19 患者为非重症病例,症状轻微,预后良好,其余20%为重症,需要特殊护理,包括吸氧和人工通气等操作,然而重症Covid-19患者的疾病发展速度极为迅速, Covid-19的重症病例多在1周后出现呼吸困难,严重者会快速进展为急性呼吸窘迫综合征、脓毒症休克、难以纠正的代谢性酸中毒和出凝血功能障碍及多器官功能衰竭等情况,故及早发现重症Covid-19患者有着非常广泛的意义。
目前Covid-19的检测主要依赖于咽拭子核酸检测,该检测方法仅能检测病毒的有无,却无法指示患者病情的轻重,更无法预判患者是否可能出现组织损伤。也就是说,目前Covid-19的轻重型分型仅能通过患者的临床症状进行判断,极大可能会错过对临床症状最佳的人工干预。
发明内容
本发明的目的在于提供一种特征尿蛋白对covid-19轻重级进行分型的非诊断方法及应用,具体的,本文对受试者的尿液中的特征尿蛋白的相对表达量进行检测,相对表达量输入分型模型中得到covid-19分型结果的预测值,该预测值可用于对罹患covid-19的受试者进行轻重型分型以及肾脏组织损坏程度的监测,特征尿蛋白为:VPS36、CEL、FREM2、TNR、PTGFRN、MLEC、ADGRL1、OSTN、 ICOSLG、NPR3、MELTF、PRSS2、SERPINI1、MADCAM1、CDH22、CDH19、TRHDE、 SPOCK1、CD84和BTNL3。
本方案提供的特征尿蛋白组合使用,用于covid-19轻重型的分级:基于预测值分级covid-19的轻重型;用于对covid-19造成的肾脏组织损伤进行预防和治疗:若分级为重型covid-19,则预判患者存在验证的肾脏组织损伤;用于监测受试者的病症的恶化或改善:基于预测值的变化监测covid-19病症的变化状态;用于为制备治疗covid-19轻重型的靶向药物提供支持:基于预测值验证药物是否具有治疗效果,且本方案的特征尿蛋白在轻重型分型中的区别最大,可以用作未来药物靶点的研究重点。有利于临床诊治过程中进行更加针对性的治疗和用药,对于改善患者的预后具有重大意义。
另外,本方案是通过检测受试者的尿液中特征尿蛋白的相对表达量来预判covid-19分型结果,相比对血液采样或者咽拭子核酸检测的方式,尿液采样存在采样方便、病人依从性高的特点,且本方案仅需使用微量的尿液样本(500ul) 即可完成检测。
第一方面,本方案提供一种特征尿蛋白对covid-19轻重级进行分型的非诊断方法,包括以下内容:检测受试者尿液中特征尿蛋白的相对表达量,将尿蛋白的相对表达量输入分型模型中获取预测值,若预测值低于设定阈值,则分型受试者为重型,其中特征尿蛋白包括VPS36、CEL、FREM2、TNR、PTGFRN、MLEC、 ADGRL1、OSTN、ICOSLG、NPR3、MELTF、PRSS2、SERPINI1、MADCAM1、CDH22、 CDH19、TRHDE、SPOCK1、CD84和BTNL3。
在本方案中仅需取用不大于500μL受试者尿液即可,具体的,检测受试者尿液中特征尿蛋白的相对表达量的方法包括但不限于:利用tmt标记的尿蛋白组学分析方法进行检测,以及其他靶标或非靶标蛋白组学分析方法进行检测。
其中使用tmt标记的尿蛋白组学分析方法包括:
将尿液样本进行灭活和灭菌后加入丙酮沉淀蛋白过夜,重悬后加入尿素进行变性,再还原并烷基化处理蛋白裂解物,孵育设定时间后用TEAB进行稀释后用胰蛋白酶和混合TEA停止反应;经胰酶消化后的肽段使用除盐柱进行清洗除盐后,使用tmt标记多肽后溶解多肽,用LC-MS/MS进行分析后得到质谱数据,基于质谱数据获取多肽和蛋白的定量数据。
具体的,在本方案中,具体的手段如下:尿液样本在56℃下灭活和灭菌 30分钟,然后用冷丙酮沉淀过夜(尿:丙酮=1:4,v/v,-20℃),用100μL TEAB 重悬,加入100μL 10M尿素变性,再加入用10mm三(2-羧基乙基)膦(TCEP)和 40mm碘乙酰胺(IAA)还原并烷基化蛋白裂解物,30℃下避光孵育30分钟。用100 mM TEAB 200μL进一步稀释后,用5μg胰蛋白酶和1μg Lys-C的混合酶在32℃下消化12小时。加入30μL 10%三氟乙酸(TFA)停止反应。这些经胰酶消化后的肽段使用除盐柱进行清洗除盐后,使用TMTpro 16plex(Thermo Fisher)按照厂家说明书对多肽进行标记。重新使用2%的乙腈水溶液(V/V)对尿液多肽进行溶解,然后通过LC-MS/MS进行分析得到质谱数据。对得到的质谱数据,用商业化的Proteome Discoverer2.4.1.15软件进行鉴定和定量,输出多肽和蛋白的鉴定和定量结果。
分型模型以不同轻重型covid-19受试者的特征尿蛋白的相对表达量作为训练样本训练机器学习模型得到,分型模型的预测值表征受试者的covid-19轻重型,其中特征尿蛋白包括VPS36、CEL、FREM2、TNR、PTGFRN、MLEC、ADGRL1、 OSTN、ICOSLG、NPR3、MELTF、PRSS2、SERPINI1、MADCAM1、CDH22、CDH19、TRHDE、 SPOCK1、CD84和BTNL3。
具体的,在本方案中机器学习模型以随机森林算法(4.6.14版,R软件包) 构建得到,上述20个特征尿蛋白在39个轻型病人和11个重型患者中的相对表达量作为输入模型的原始数据,模型构建的主要参数设置为:ntree=1000, nodesize=1,其他使用默认参数。
为了提高分型模型的预测精度,训练样本至少选用:重症covid-19患者的尿蛋白相对表达量以及轻症covid-19患者的尿蛋白相对表达量,且分别标记样本类型是轻型还是重型;经过训练后的分型模型可基于输入的尿蛋白相对表达量输出预测值,预测值越高则表明对应的covid-19的分型越偏向于轻型,反之则更偏向于重型。
在本方案中,预测值的设定阈值为0.5,即,若预测值低于0.5则认定该受试者为covid-19重症。
第二方面,本发明提供一种特征尿蛋白作为检测靶标在制备分型受试者 covid-19轻重型的试剂盒中的应用,其中试剂盒含有检测特征尿蛋白的相对表达量的试剂;通过试剂盒检测受试者尿液中特征尿蛋白的相对表达量,特征尿蛋白的相对表达量与受试者covid-19分型结果相关联,其中特征尿蛋白为: VPS36、CEL、FREM2、TNR、PTGFRN、MLEC、ADGRL1、OSTN、ICOSLG、NPR3、MELTF、 PRSS2、SERPINI1、MADCAM1、CDH22、CDH19、TRHDE、SPOCK1、CD84和BTNL3。
其中特征尿蛋白的相对表达量与受试者covid-19分型结果相关联:将特征尿蛋白的相对表达量输入分型模型,若分型模型的预测值输出低于设定阈值,则预测受试者为covid-19为重型。
第三方面,本方案提供一种特征尿蛋白在制备分型受试者covid-19轻重型的试剂中的应用,检测受试者尿液中的特征尿蛋白的相对表达量,相对表达量输入分型模型预测受试者的covid-19分型结果,其中特征尿蛋白为:VPS36、 CEL、FREM2、TNR、PTGFRN、MLEC、ADGRL1、OSTN、ICOSLG、NPR3、MELTF、PRSS2、 SERPINI1、MADCAM1、CDH22、CDH19、TRHDE、SPOCK1、CD84和BTNL3。
第四方面,本方案提供一种分型受试者covid-19轻重型的分型模型,以不同轻重型covid-19受试者的尿液的特征尿蛋白的相对表达量作为训练样本训练机器学习模型得到,其中特征尿蛋白为:VPS36、CEL、FREM2、TNR、PTGFRN、 MLEC、ADGRL1、OSTN、ICOSLG、NPR3、MELTF、PRSS2、SERPINI1、MADCAM1、CDH22、 CDH19、TRHDE、SPOCK1、CD84和BTNL3,分型模型的预测值表征受试者的covid-19 轻重型。
相较现有技术,本方案的特点在于:通过蛋白组学数据的分析选定可用于指示Covid-19轻重型的20中特征尿蛋白,基于这20种特征尿蛋白的相对表达量输入分型模型中预测得到预测值,基于预测值可分型covid-19的轻重型,可以及早对病人分型进行预判,有利于临床诊治过程中进行更加针对性的治疗和用药,对于改善患者的预后具有重大意义,同时可以作为潜在的治疗靶点供后续研究。
附图说明
图1是重症、非重症covid-19患者、非COVID-19患者和健康供体的尿中多肽产率的示意图。
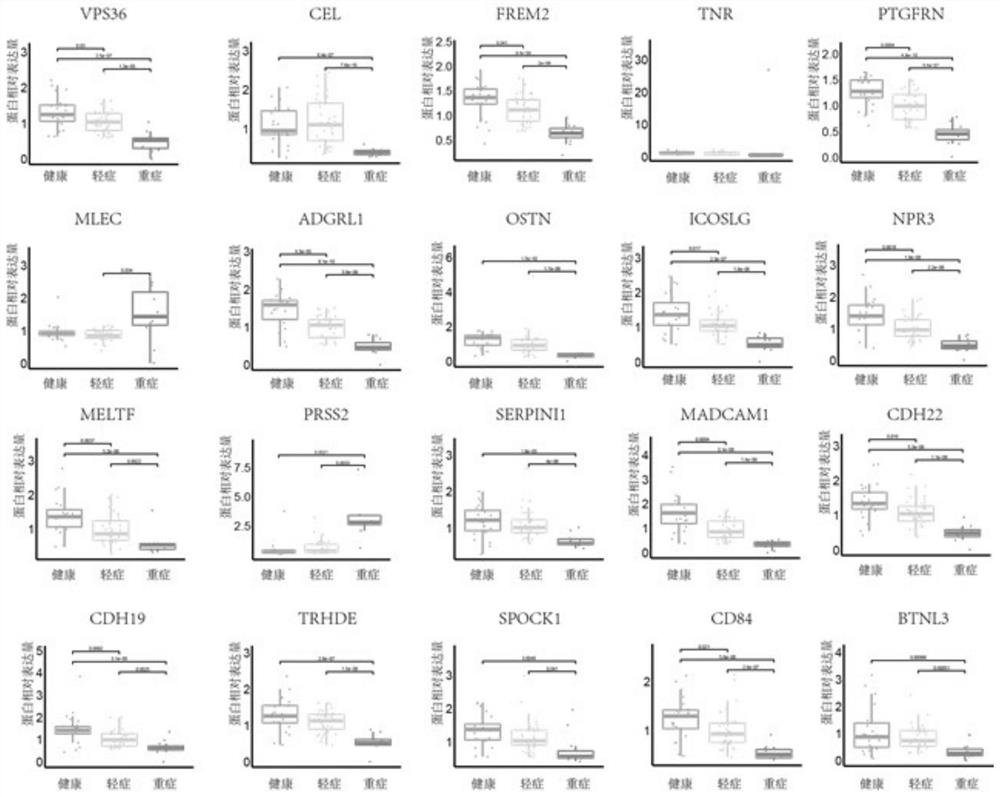
图2是筛选得到的20种特征尿蛋白数据图。
图3是分型实验1的尿蛋白的相对表达量输入分型模型后输出的数据结果图。
图4是分类实验1的13例covid-19患者的尿蛋白相对表达量情况。
图5是对照实验2所需求的20种特征尿蛋白的数据图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员所获得的所有其他实施例,都属于本发明保护的范围。
本发明人对covid-19尿液的蛋白质进行组学分析以说明选择这20种特征尿蛋白作为标记物的依据:
分析样本:50例covid-19患者(39例非重症和11例重症)、23例健康供体的尿液样本,样本取自浙江省台州医院。
分析过程:
样本准备:取患者等量的尿液,尿液样本在56℃下灭活和灭菌30分钟,随后用冷丙酮沉淀过夜(尿:丙酮=1:4,v/v,-20℃),再用100μL TEAB重悬后加入100μL 10M尿素变性,再加入用10mm三(2-羧基乙基)膦(TCEP)和40mm 碘乙酰胺(IAA)还原并烷基化蛋白裂解物,在30℃的黑暗中孵育30分钟。用 100mM TEAB 200μL进一步稀释后,再用2μg胰蛋白酶在32℃下消化4小时,继而再加入2μg胰蛋白酶在32℃下消化12小时。加入30μL 10%三氟乙酸(TFA)停止反应,取这些经胰酶消化后的肽段使用除盐柱进行清洗除盐后,使用TMTpro16plex按照厂家说明书对多肽进行标记。
纳升液相-高分辨率质谱分析:
重新使用2%的乙腈水溶液(V/V)溶解的尿液多肽通过LC-MS/MS进行分析,使用相同的LC系统,在数据依赖采集(DDA)模式中耦合Q-Exactive HF-X杂交四极轨道rap。本方案的实验进行了批次设计,以尽量减少批次效应对蛋白质组学数据的影响。本申请人将四组不同的样本随机分为6批次进行TMTpro 16plex 标记,每批样品数量相同,此处的四组不同的样本分别指代:COVID-19重症患者、COVID-19非重症患者、非COVID-19患者和健康供体的尿液样本;对于每个批次的TMT样品,采用nanflow DIONEX UltiMate 3000RSLCnano系统(Thermo Fisher Scientific,San Jose,USA)和XBridge Peptide BEH C18色谱柱(
在本方案中,酶被设置为胰蛋白酶,有两个缺失的切割耐受性。静态修饰为半胱氨酸氨基甲基化(+57.021464)、赖氨酸残基及肽段N端 TMTpro(+304.207145),可变修饰为蛋氨酸氧化(+15.994915)和肽段N端乙酰化 (+42.010565)。前体离子质量偏差设置为10ppm,碎裂离子质量偏差设置为0.02 Da。
结果分析:如图1所示可见重症和非重症covid-19患者的尿中肽含量明显高于健康志愿者,该结果表明covid-19患者尿液中蛋白量有所升高,具有潜在的蛋白尿行为特征。图1中,健康对照组指的是:健康供体;轻型患者指的是: 39例非重症;重型患者指的是的:11例重症。
且本申请人在尿液中鉴定了19,732个多肽和3854个蛋白,并得到了其各自对应的相对定量结果。蛋白质组数据的质量控制(QC)样本的中位数方差系数(CV) 为13%,表明本方案选用的样本的数据质量高。具体的,该数据表明本方案的数据是系统误差较小,不会因为系统误差的原因导致这20个尿蛋白的选择出现错误。样本在鉴定过程中专门插入并设置了QC的样本,使用QC样本的数据来证明本方案的分析方法的可靠性,从而证明本方案筛选到的20个蛋白,并非源自系统误差,而是样本的真实差异。
在证明了本方案选用的样本数据质量高的前提下,继续选用50例covid-19 患者的样本数据作为分析样本,在蛋白质组水平上使用机器学习的方法评估其对covid-19轻症和重症的区别,以最终定位20种特征尿蛋白。
数据挖掘的过程如下:
采用随机森林的R软件包(4.6.14版),在尿液数据中以尿液中鉴定得到的 3854个蛋白相对表达量作为变量输入,随机森林的参数设置为:ntree=5000, nodesize=1,其他参数按照默认设置,对筛选得到的蛋白按照伴随这些蛋白所输出的Mean Decrease(平均降低精度)进行排序。平均降低精度排名前20的尿蛋白,如图2所示,这些尿蛋白主要参与细胞粘附、细胞发育、分泌、消化和细胞外基质或结构组织相关的生物过程,这些尿蛋白为VPS36、CEL、FREM2、TNR、 PTGFRN、MLEC、ADGRL1、OSTN、ICOSLG、NPR3、MELTF、PRSS2、SERPINI1、MADCAM1、 CDH22、CDH19、TRHDE、SPOCK1、CD84和BTNL3。
以下就20中尿蛋白进行介绍:
VPS36蛋白,是内吞体分选转运复合体(ESCRT)II的构成部分,在病毒出牙过程中发挥重要作用。
CEL蛋白促进肠中大量乳糜微粒的产生,催化多种底物的水解,包括胆固醇酯,磷脂,溶血磷脂,二和三酰基甘油以及羟基脂肪酸(FAHFA)的脂肪酸酯。
FREM2编码的蛋白质定位于基底膜,可以自身形成三元复合物,该三元复合物在表皮-真皮相互作用中起作用。该蛋白对于皮肤和肾上皮的完整性很重要。
TNR编码细胞外基质糖蛋白腱生蛋白家族的成员。该蛋白质可能在神经突增生,神经细胞粘附和钠通道功能的调节中起作用。
PTGFRN(前列腺素F2受体抑制剂)通过减少受体数量而不是亲和常数,抑制前列腺素F2-alpha(PGF2-alpha)与其特异性FP受体的结合。与前列腺功能相关。
MLEC蛋白对Glc2Man9GlcNAc2(G2M9)N-聚糖具有亲和力,并参与调节内质网中的糖基化。该蛋白质还被证明与核糖蛋白I相互作用,并且可能参与指导错误折叠的蛋白质的降解。其相关途径包括先天免疫系统和蛋白质代谢。
ADGRL1是G蛋白偶联受体(GPCR)的latrophilin亚家族的成员,可能在细胞粘附和信号转导中起作用。
OSTN是一种激素,在大脑皮层的发育过程中作为树突状生长的调节剂。
ICOSLG是T细胞表面受体ICOS的配体。ICOSLG作为T细胞增殖和细胞因子分泌的共刺激信号,可诱导B细胞增殖。ICOSLG通过刺激记忆T细胞功能,在调节二次免疫应答中发挥重要作用。
NPR3三种利钠肽受体之一,可以调节血容量和压力,调节肺动脉高压和心脏功能以及某些代谢和生长过程。
MELTF是在黑色素瘤细胞上发现的细胞表面糖蛋白。该蛋白与运铁蛋白超家族成员具有序列相似性和铁结合特性。
PRSS2属于丝氨酸蛋白酶的胰蛋白酶家族,并编码阴离子胰蛋白酶原。它是位于T细胞受体β基因座内的胰蛋白酶原基因簇的一部分。该蛋白质在胰腺汁液中含量很高,其上调是胰腺炎的特征。
SERPINI1是丝氨酸蛋白酶抑制剂超家族的成员。该蛋白质主要由大脑中的轴突分泌,并且优先与组织型纤溶酶原激活剂反应并抑制组织型纤溶酶原激活。据认为在轴突生长的调节和突触可塑性的发展中起作用。
MADCAM1是一种内皮细胞粘附分子,与骨髓细胞上的白细胞beta7整合素 lpam1、l-选择素和VLA-4相互作用,可以引导白细胞进入粘膜和炎症组织。 COVID-19患者尿MADCAM1水平下降,可能提示白细胞外渗到炎症部位的过程受到影响。
CDH22是钙粘蛋白超家族的成员。在脑和神经内分泌器官的发育和维持过程中,可能在神经和非神经细胞的形态发生和组织形成中起重要作用。
CDH19蛋白是钙依赖性细胞-细胞粘附糖蛋白,钙黏着蛋白的丢失可能与癌症的形成有关,与CDH19相关的疾病包括电荷综合征和小眼病。
TRHDE(促甲状腺激素释放激素降解酶)是一种细胞外肽酶,可特异性裂解并使神经肽促甲状腺激素释放激素失活。与TRHDE相关的疾病包括Fraser综合征1。
SPOCK1可能在细胞-细胞和细胞-基质相互作用中起作用。可能有助于中枢神经系统的各种神经元机制。与SPOCK1相关的疾病包括耳聋,常染色体隐性遗传101和牙龈过度生长。
CD84是信号淋巴细胞活化分子(SLAM)家族的自配体受体,参与先天和适应性免疫应答的调节和相互联系。。可以介导依赖于SH2D1A和SH2D1B的自然杀伤(NK)细胞毒性(通过相似性),另外可以激活的T细胞的增殖反应。在巨噬细胞中,可增强LPS诱导的MAPK磷酸化和NF-κB活化,并调节LPS诱导的细胞因子分泌。与CD84相关的疾病包括淋巴增生综合征和选择性免疫球蛋白缺乏症。
BTNL3的重要旁源同系物是BTNL8,可能会刺激原发性免疫反应。通过作用于TCR/CD3复合物刺激的T细胞,进而刺激其增殖和细胞因子的产生。
在获取这20种特征尿蛋白后,本申请人基于这20种尿蛋白的相对表达量训练机器学习模型,并基于训练得到的模型进行covid-19轻重型的分类。
具体的,以不同轻重型covid-19受试者的尿液的尿蛋白的相对表达量作为训练样本训练机器学习模型得到,其中尿蛋白为:VPS36、CEL、FREM2、TNR、 PTGFRN、MLEC、ADGRL1、OSTN、ICOSLG、NPR3、MELTF、PRSS2、SERPINI1、MADCAM1、 CDH22、CDH19、TRHDE、SPOCK1、CD84和BTNL3,该预测值表征受试者的covid-19 轻重型程度。
机器学习模型使用的模型使用随机森林的R软件包(4.6.14版)进行构建。具体的,上述20个蛋白在39个轻型病人和11个重型患者中的相对表达量作为输入模型的原始数据,模型构建的主要参数设置为:ntree=1000,nodesize=1,其他使用默认参数。
训练样本为:39个轻型病人和11个重型患者的尿液蛋白相对定量数据,且标记对应标本的轻重型。
训练过程:将上述20个蛋白在39个轻型病人和11个重型患者中的相对表达量作为输入模型的原始数据输入该模型结构中进行训练。
本方案通过以下实验验证该分型模型在预测covid-19轻重型时表现良好。
分型实验1:
实验样本:使用常规采集手段采集13例covid-19患者的尿液样本,样本来源于浙江省台州医院。在本方案中,常规采集手段指的是:病人自主排尿后用尿液收集管进行收集。
使用tmt标记的尿蛋白组学分析方法对尿液样本进行测定,获取尿液样本的尿蛋白的相对表达量,其中尿蛋白为VPS36、CEL、FREM2、TNR、PTGFRN、MLEC、 ADGRL1、OSTN、ICOSLG、NPR3、MELTF、PRSS2、SERPINI1、MADCAM1、CDH22、 CDH19、TRHDE、SPOCK1、CD84和BTNL3。具体的,对尿液样本进行测定的方法参见其上关于样品准备以及纳升液相-高分辨率质谱分析步骤内容。
将尿蛋白的相对表达量输入分型模型中得到结果如图3所示,可见曲线下面积为(AUC)为0.89,预测值整体的准确率为0.69。曲线可用于评估本方案模型的有效性,我们首先使用50个训练队列样本进行筛选得到的模型,可以用这个曲线的相关参数(AUC)来对模型的稳定性和性能进行评估。然后建好的模型再应用于后续独立的队列(13个样本的队列)进行分型预测。分型结果的灵敏度和特异性,也可以用这个曲线的相关参数(AUC)来说明。如果训练队列建模和独立队列评估这两条曲线的相关参数较高,说明我们的模型有效性较好,是科学的。
结果分析:13例covid-19患者的尿蛋白相对表达量情况如图4所示,预测值及病症情况如表1所示。
表一:13例covid-19患者的预测值和病症情况
从结果可见,6例非重症患者(U9_7,U7_8,U9_11,U8_3,U10_10,U7_2)和3例重症患者(U10_11,U10_15,U8_9)被正确进行了分型。
在4例分类错误的样本中,重症病例U8-6为36岁女性,在诊断为重症患者后3天采集尿液(严重指标:氧合指数<300)。但在诊断为重症后2天,氧合指数上升到324,说明抽样是在病情好转阶段进行的。事实上,尿液取样后三天的CT检查也显示她双肺多发斑点状影呈现减少趋势。因此,在该患者尿样采集处于其病情好转阶段,故导致对该病例的错误分类,但其也从侧面反应了该分型模型起到一定的预测分型效果。第2例(U7-13)为非重症,被误诊为重症,实际2型糖尿病病史为2年,可能影响模型评估。另外两例U9-3和U8-15为男性重症,被误诊为非重症,原因不明。
另外,补充对照实验2:
选用同分类实验1相同的13例covid-19患者的尿液样本,依旧使用tmt 标记的尿蛋白组学分析方法对尿液样本进行测定,获取尿液样本的尿蛋白的相对表达量,唯一不同的是,随机选择了另外20种蛋白进行建模:GASK1B、LIPA、 PLAUR、RPL19、LSM2、GALM、FAM25A、RRAS、C1RL、FOLH1、NUCKS1、NPM1、S100A6、 FAT4、EPS8L2、C5orf15、SIAE、CRK、SEMG1、SMPDL3B。
机器学习模型为:选用与实验1相同的模型结构,参数设置为ntree=1000,nodesize=1。
训练样本为:39个轻型病人和11个重型患者的尿液蛋白相对定量数据,且标记对应标本的轻重型
训练过程:将上述20个蛋白在39个轻型病人和11个重型患者中的相对表达量作为输入模型的原始数据输入该模型结构中进行训练。
将尿蛋白的相对表达量输入此时的分型模型2中得到结果如图5所示,其中,可见曲线下面积为(AUC)为0.762,精度为0.62。
13例covid-19患者的预测值及病症情况见表2。
表2:对照实验2的13例covid-19患者的预测值及病症情况
从结果可见,几乎所有患者都被归纳为了轻型,不具有区分能力。
比对对照实验2和分类实验1可明显地感知,利用本方案选用的20种尿蛋白的相对表达量预测得到的预测结果更为准确。
本发明不局限于上述最佳实施方式,任何人在本发明的启示下都可得出其他各种形式的产品,但不论在其形状或结构上作任何变化,凡是具有与本申请相同或相近似的技术方案,均落在本发明的保护范围之内。