数据处理方法和装置
文献发布时间:2023-06-19 11:57:35
技术领域
本发明属于敏感信息保护领域,具体涉及个人定向数据推送的混淆和避免定向推送。
背景技术
目前,针对客户的偏好的收集已经成为商业网站推送信息的一个依据和常见的手段,客户在页面的每个操作都可能被记录并被分析,在后台被形成访问记录,并基于访问记录对用户进行分析,从而形成用户画像,并依据用户的画像进行信息的推送。在大数据时代,相关用户画像在形成后可用于对用户的信息筛选。
然而这种信息的推送方式尽管是受到商家欢迎的,但因侵犯隐私并不受到用户的欢迎,且用户处于不对等的地位。因信息的推送往往构建于多种因素,这导致即使在未登录的情况下或者处于特定会话、持有特定令牌、Cookies的情况下,仍然基于部分信息可以推测出用户的大致画像,从而使得推送特定的信息成为可能,从而使得用户的倾向性或者隐私被暴漏,这对于用户时明显不利的,而部分服务提供方不提供或者提供了过于繁琐的指引步骤用于防止用户取消跟踪,且不遵循Do Not Track不要跟踪(DNT)的约定,或者主动通过刺探用户信息的方式超范围获取信息(如访问用户存储的浏览记录),因此需要提供技术手段防止此类泄露风险。
发明内容
针对现有技术中用户信息存在泄露的风险,本发明提供了一种数据处理方法,通过提供偏离画像的信息,从而避免或者延迟真实用户信息的泄露。
本发明提供的数据处理方法包括:
1)获得第一目标页面,其中包括至少一个用于展示推荐信息的推荐组件的信息,获得推荐组件中推荐数值的离散度或分布;
2)如果推荐数值中第一标记属性的比例高于期待值R,至少载入一个不含第一标记属性的第二页面;
3)在第三目标页面重新计算推荐数值的离散度,如果第一类标记属性的比例高于期待值R,执行步骤2),否则退出;
所述第一目标页面和第三目标页面含有个性化的推荐信息,且推荐信息被映射至包含第一标记属性的标签集中,其中第一标记属性属于期待减少的比例;
所述推荐数值的离散度为获得推荐组件的可视部分的内容,并对其进行解析,得到文本标签的信息,并对文本标签进行统计,确定文本标签的离散度。
在本发明的一个实施例内,所述文本标签的信息包括文本标签的内容和位置,所述文本标签的位置为在页面内相对位置或者绝对位置。
在本发明的一个另外一个实施例内,依据规则确定文本标签的标记属性,根据标记属性计算页面中推荐数值的离散度。
所述文本标签映射至至少两类标记属性,且至少存在第一标记属性和第二标记属性,其中第一标记属性属于用户期待在信息推荐中减少出现,第二标记属性属于用户期待在信息推荐中出现的优先级高于第一标记属性。
在本发明的一个实施例内,所述第一页面为通过第一配置文件获得、枚器窗口或者为选定的活跃的窗口获得;
在使用第一配置文件加载页面时,所述第一配置文件至少包括浏览器类型、进程模块名称、地址中的一种或多种;
在第一配置文件包括浏览器类型时,程序可以通过查找进程的方式获得当前浏览器的进程ID,并进一步获得浏览器的句柄,根据浏览器的句柄获得窗口的信息;
也可以通过查找进程模块的方式获得当前浏览器的进程ID,并进一步获得浏览器的句柄,根据浏览器的句柄获得窗口的信息;
也可以通过查找进程模块地址的方式获得当前浏览器的进程ID,并进一步获得浏览器的句柄,根据浏览器的句柄获得窗口的信息。
在通过枚举窗口获得信息时,至少通过获得窗口信息、进程信息的方式将其与信息组件匹配,以桌面浏览器为例,可以设置一个常见浏览器的集合,通过枚举窗口信息的并和浏览器模块匹配的方式获得运行的窗口进程。
在本发明的一个实施例中,在使用选定的活跃的窗口获得目标页面时,通过设置一个悬浮球或者提供一个当前窗口列表的形式,或通过手工选择的方式获得目标页面。
本发明中可视化内容获得为通过远程控制获得、截图功能获得或者通过页面解析获得;
在通过远程控制获得时,则至少可以使用类似selenium、scrapy等框架获得,常见或者主流浏览器提供了远程调试的支持,然而部分浏览器尽管提供了远程调试支持,但是不具备渲染的特性。
以非浏览器的其他部分截屏,例如移动设备的截屏,可以参考现有技术的方式进行,例如使用ScreenShotActivity或者其他开源项目。桌面客户端的截屏可以使用非浏览器的形式实现,例如多个浏览器或者社区提供了java、c#等版本的套件,甚至可以嵌入传统浏览器的方式来实现。
如选用页面解析,则可以选择前述的多种客户端或者框架实现,例如使用常规的页面访问获得网页源代码,或者通过调试框架获得页面的源代码,或者通过自定义的浏览器获得源代码,而对于非浏览器的移动端应用,受限于隐私以及安全考虑的技术实现,通过页面解析获得其他浏览器或者app的源代码是不现实的,因而建议采用截图的方式进行而并非是直接进行解析,但是在自定义的信息展示装置内,直接获得页面的源代码实际上是和桌面一致的。
页面推荐内容的获得为通过预定义规则或者关键字实现的。
以预定义的规则进行的推荐内容获得为预设网站与推荐规则的匹配节点,并对相应的节点进行截图。以某网站的信息推荐页面为例,其推荐内容对应的XPath为“/html/body/div[1]/div/main/div/div[2]/div[2]/div/div/div[3]/div[2]”,对于稳定的商业网站而言,该位置在一个版本周期内一般为固定的,而对于布局经常改版的信息平台而言,此XPath对应的规则需要更新后方可以使用;在XPath失效的情况下,可以进一步设置关键字规则,如查找对应的div的class属性或者div节点对应的文本值textcontent,来确定相应的节点;部分页面使用了字体混淆技术,在此情况下,仅可以通过字体映射还原或者光学字符识别的方式获得实际的文本。
在推荐内容可以采取前两种方式(XPath以及关键字)的方式获得时,可以通过读取WebElement相应属性来获得最小图像获取区域或者文本节点的内容,否则应当进行全文解析获得所有关键字或者通过截屏确定相应节点的分布。
对于通过DOM树或者源代码解析的内容,可以通过选择相应节点,并提取文本的方式获得所有的标签,对于标签可以采取字典的方式确定相应的标签归属,特别的,部分网站使用不同的样式表对于期待关注的主题进行区分,在进行文本提取时可以通过补入适当的空格,然后对字符串进行拆分,这样更有助于定位标签归属;对于长的字符串,可以选择贪婪模式,选择2、3、4或5的滑动窗口对其进行分词,此种分类方式在部分商业网站,例如购物性网站往往具备更高的效率,因部分错误的字词往往会造成按照字典或者分词工具无法确认的缺陷(如志强CPU中志强为至强的错字),而按照此方式在部分字词错误的情况下,依据正确的字词仍然可以具有一定的命中率;长的字符串也可以选择自然语言处理的方式进行分词,如HanLP、jieba等工具,或者通过各服务平台提供的自然语言处理api的方式进行。
对于通过OCR获得的信息,通过前述的方式进行主题的区分,并得到页面对应的节点所对应的标记。例如,OCR获得信息中,“推荐内容”其对应的偏移(x,y)为800,200时,其他OCR得到的信息中,x值小于800部分的文字内容不应当被考虑。相关区域的下限按照停用字或者临界推测的规则确定,例如按照停用字规则时,如“推荐内容”其对应的偏移(x,y)为800,200时,在对应的偏移(x,y)为860,3200时处解析到了“更多内容”,则应当选择其作为此推荐区域的终点;按照临界推测的方式确定推荐区域的方法为根据推荐区域的起点,确定可信区域内所有的文本位置,并统计所有文本区域出现的间隔,选择具备规律性的节点作为推荐信息节点,
另外一种方式为基于DOM的信息获取节点的范围,例如获得标记偏移(x,y)为800,200时,遍历DOM树,并可以构建辅助的映射,以java为例,构建图HashMap
标签离散度的计算较为简单的方式为计算相应领域的权重值非零部分的方差,或为计算相应领域的权重值非零部分的方差,或为计算特定领域的权重值非零部分的方差。
对应于标签离散度的计算,以购物网站为例,可以设置一个本地的词典,按照类别设置一级、二级和三级分类,对应于第二级或者第三级的分类,设置一个或者多个关键字,例如对于路由器,可以设置包括品牌(华为、普联、新华三)、使用的环境(大户型、中户型、小户型)、特性(Wifi6、Wi-Fi6、ax),等关键字,当识别到的文本至少包含一个关键字时,相应的标签的权重增加1或者特定值,对于一个文本,可以设置仅增加第一个匹配的标签或者所有匹配的标签。
通过截图获得的节点位置确定,对于无法通过解析方式或者元素节点位置的情况,可以通过预设规则或者手工确定的方式进行,例如通过选择特定的区域,从而使得具体区域和节点关联;对于预设规则方式确定节点位置的,则可以通过获得分辨率信息和页面的缩放比,进而获得页面中对应部件的位置。
所述的第一页面和第三页面可以为同一地址的页面,在第二页面包括推荐信息时,第二页面可以为第三页面。
在步骤2)执行多次后,预期第一页面或者第三页面中推荐内容的分布会产生变化,为了避免此过程中因缓存原因造成的数据延迟,可以在请求头中进行近似的设定即可。
通过上述的方式可以实现使用浏览记录进行信息预测从而实现推送的信息的偏离,进而使得用户的隐私得到了保护。
附图说明
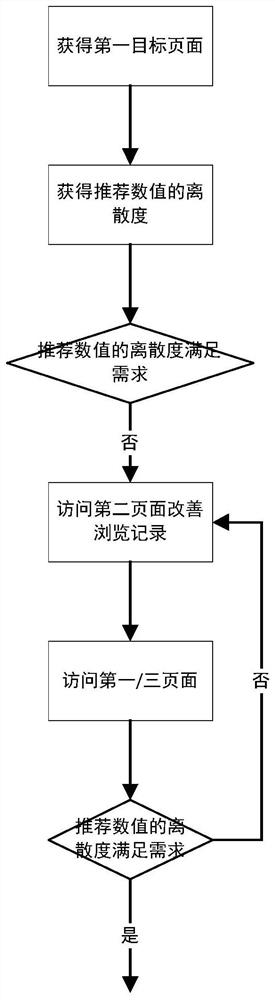
图1、本发明数据处理方法的流程图;
图2、本发明的一个实施例中选择性访问页面的流程图,通过该方式访问不具备第一属性的页面。
具体实施方式
如下为本发明的具体实施例,其仅用作对本发明的解释而并非限制。
以网站1为例,以虚拟机Hyper-V安装系统后,使用代理访问网站1,在未登录账户的情况下,其推荐页面显示的内容为“家具、女装、首饰、手机”,而当取消代理,配置HyperV的虚拟交换机模式为外部网络类型,则网站1依据来源推送了“母婴、家居服、内存条、硬盘”的广告,具备和外部物理计算机一致的推送内容。多次还原镜像后使用代理访问网站1,其推荐页面显示的内容包括“蓝牙、女装、运动鞋、手机、皮包、西裤、睡袋、冰箱、图书、收纳盒、洗衣液、零食”等内容,但是在取消代理并且更换计算机使用的IP地址访问网站1,得到的推送结果含有“母婴、婴儿床、床护”以及计算机硬件,特别是为了测试数据可靠起见,在进行测试前,所处网络搜索特定CPU型号,如ROME,而在取消代理后,虚拟机内的网站推送内容至少出现了“志强铂金、志强黄金”等关联搜索结果,这表明网站1具备关联性推荐的后台方法;对于某知识问答网站、新闻网站、自媒体网站的测试也表明相应的网站具备跟踪浏览历史的实际行为。基于此进行用户信息的处理,从而避免信息的明显泄露。
则可以构建两类不同标记属性的标签,其中第一类为敏感信息类,为包含母婴以及计算机相关词汇,第二类标签为除此之外的词汇,第一标记属性标签集属于用户期待在信息推荐中减少出现,第二标记属性标签集属于用户期待在信息推荐中出现优先级高于第一类标签;此外,还可以在第二类标记属性中细分出第三类,从而提高定向推荐的几率。
在构建第一类或者第二次的关键词词汇时,可以设置一类关键字,并且照此关键词设置更多的子关键字作为后续使用的查询关键字或者停用词。
参见图1-2,本发明提供的数据处理方法包括:
1)获得含有第一目标页面,获得至少一个用于展示推荐信息的推荐组件的信息,并获得推荐组件中推荐数值的离散度或分布;
2)如果推荐数值的比例或离散度中第一类标记属性占比R
3)在第三目标页面重新计算推荐数值的离散度,如果其高于期待值R,执行步骤2),否则退出;
所述第一目标页面和第三目标页面含有个性化的推荐信息;
所述推荐数值的离散度为获得推荐组件的可视部分的内容,并对其进行解析,得到文本标签的信息,并对文本标签进行统计,确定文本标签的离散度;
所述第一目标页面、第二目标页面和第三目标页面的推荐信息被映射至至少包含第一标记属性的标签集中,其中第一标记属性为期待减少的标记属性。
所述的映射过程为通过分词或者提取关键字后和字典进行匹配,获得对应的标记属性。
在本发明的一个实施例内,所述第一页面为通过第一配置文件获得、枚器窗口或者为选定的活跃的窗口获得;
在使用第一配置文件加载页面时,所述第一配置文件至少包括浏览器类型、进程模块名称、地址中的一种或多种;
在第一配置文件包括浏览器类型时,程序可以通过查找进程的方式获得当前浏览器的进程ID,并进一步获得浏览器的句柄,根据浏览器的句柄获得窗口的信息;
也可以通过查找进程模块的方式获得当前浏览器的进程ID,并进一步获得浏览器的句柄,根据浏览器的句柄获得窗口的信息;
也可以通过查找进程模块地址的方式获得当前浏览器的进程ID,并进一步获得浏览器的句柄,根据浏览器的句柄获得窗口的信息。
在通过枚举窗口获得信息时,至少通过获得窗口信息、进程信息的方式将其与信息组件匹配,以桌面浏览器为例,可以设置一个常见浏览器的集合,通过枚举窗口信息并匹配浏览器进程名称(如Firefox.exe,msedge.exe)的方式获得运行的窗口进程。
对应于此,可以设置配置文件config.ini至少包括:
该配置文件中浏览器的配置可以通过扫描的方式获得或者通过用户手工指定;该配置文件中还包括了目标网站以及页面内对应的信息推荐区域的XPath,该文件可以设置为自动更新的内容,或者通过手工确认信息区域的XPath。
在通过手工确认,在使用选定的活跃的窗口获得目标页面的XPath时,通过设置一个悬浮球或者提供一个当前窗口列表的形式,或通过手工选择的方式获得目标页面,并在此技术上进一步获得信息推荐区域的位置。
在本发明的一个实施例内,所述文本标签的信息包括文本标签的内容和位置,所述文本标签的位置为在页面内相对位置或者绝对位置。
在本发明的一个另外一个实施例内,依据规则确定文本标签的标记属性,根据标记属性计算页面中推荐数值的离散度。
本发明中可视化内容获得为通过远程控制获得、截图功能获得或者通过页面解析获得;
在通过远程控制获得时,则至少可以使用类似selenium、scrapy等框架获得,常见或者主流浏览器提供了远程调试的支持,然而部分浏览器,特别是缺乏可靠渲染性能的无头浏览器,并不支持渲染页面并截图的特性,因而无法获得相应的渲染信息。而部分页面为了防止采集或者处于流量控制的考虑,渲染过程事实上是通过多次渲染来实现的,部分渲染过程需要特定的事件触发,仅基于DOM树的结构进行信息的处理可能会遗漏信息;且针对于部分渲染结果,如果不考虑可视化的因素,极有可能获得包含蜜罐的信息。对应于支持插件性能,特别是内容过滤性能的插件,其可能在页面载入过程中以及页面载入后对DOM树进行增减,因而应当在此过程中禁用相应的插件。
以selenium套件为例,在使用具备推荐信息的页面时,可以通过设置分辨率信息来获得具备解析价值的图像信息,在页面载入完毕后,如使用java语言进行实施,通过调用已实现TakesScreenshot接口可以实现屏幕信息的获取;对于普通页面信息,往往不可能通过单次截屏的方式来进行,因而可以通过多次滚动页面截屏的方式来实现整体的信息获取,在进行截屏信息获取时,可以通过设置不载入图像信息,此设置可以在浏览器的配置文件中设置完成,从而避免了因部分图像信息的像素变化而造成图像拼接的困难,而对于需要载入图像的清醒,也可以选择最大匹配度的方式进行截图的获取,例如截取一个1200*800的图片后,通过selenium向下滚动的方式来实现其他内容的载入,此过程中,可以保存上一次图像最末2行的rgb值,例如选择Cx,y=(R+G+B)/3,x为图像的横向偏移,y为纵向偏移,并将C大于128的标记为0,小于128的标记为1,并将新图像的最顶端的1像素或者25个纵向偏移所对应的行按照类似方式处理,将图像进行处理后,选择最大匹配值进行拼接。
以非浏览器的其他部分截屏,例如移动设备的截屏,可以参考现有技术的方式进行,例如使用ScreenShotActivity或者其他开源项目。桌面客户端的截屏可以使用非浏览器的形式实现,例如多个浏览器或者社区提供了java、c#等版本的套件,甚至可以嵌入传统浏览器的方式来实现,这些套件多数实现了webkit的内核,并可以支持脚本语言的执行,更为方便的,可以提供更为方便的接口以进行相应的处理,例如在引用WebKitBrowser.dll后,可以实现嵌入基于.net的页面嵌入,且更为方便的跟踪DOM载入事件,而对于截图过程而言,可以通过将相应部件的绘制方法将部件绘制至缓冲区域即可。在不使用前述实例的情形中,可以选择系统或者编程语言提供的api来获得特定区域的图像获取。
如选用页面解析,则可以选择前述的多种客户端或者框架实现,例如使用常规的页面访问获得网页源代码,或者通过调试框架获得页面的源代码,或者通过自定义的浏览器获得源代码,而对于非浏览器的移动端应用,受限于隐私以及安全考虑的技术实现,通过页面解析获得其他浏览器或者app的源代码是不现实的,因而建议采用截图的方式进行而并非是直接进行解析。
页面推荐内容的获得为通过预定义规则或者关键字实现的。
以预定义的规则进行的推荐内容获得为预设网站与推荐规则的匹配节点,并对相应的节点进行截图。以某网站的信息推荐页面为例,其推荐内容对应的XPath为“/html/body/div[1]/div/main/div/div[2]/div[2]/div/div/div[3]/div[2]”,对于稳定的商业网站而言,该位置一般为固定的,而对于网页的改版而言,此XPath对应的规则需要更新后方可以使用;在XPath失效的情况下,可以进一步设置关键字规则,如查找对应的div的class属性或者div节点对应的文本值textcontent,来确定相应的节点;部分页面使用了字体混淆技术,在此情况下,仅可以通过字体映射还原或者光学字符识别的方式获得实际的文本。
在推荐内容可以采取前两种方式(XPath以及关键字)的方式获得时,可以通过读取WebElement相应属性来获得最小图像获取区域或者文本节点的内容,否则应当进行全文解析获得所有关键字或者通过截屏确定相应节点的分布。
对于通过DOM树或者源代码解析的内容,可以通过选择相应节点,并提取文本的方式获得所有的标签,对于标签可以采取字典的方式确定相应的标签归属,特别的,部分网站使用不同的样式表对于期待关注的主题进行区分,在进行文本提取时可以通过补入适当的空格,减少匹配的工作量,然后对字符串进行拆分,这样更有助于定位标签归属;对于长的字符串,可以选择贪婪模式,选择2、3、4或5的滑动窗口对其进行分词,此种分类方式在部分商业网站,例如购物性网站往往具备更高的效率,因部分错误的字词往往会造成按照字典或者分词工具无法确认的缺陷(如志强CPU中志强为至强的错字),而按照此方式在部分字词错误的情况下,依据正确的字词仍然可以具有一定的命中率;长的字符串也可以选择自然语言处理的方式进行分词,如HanLP、jieba等工具,或者通过各服务平台提供的自然语言处理api的方式进行。
对于通过OCR获得的信息,通过前述的方式进行主题的区分,并得到页面对应的节点所对应的标记。例如,OCR获得信息中,“推荐内容”其对应的偏移(x,y)为800,200时,其他OCR得到的信息中,x值小于800部分的文字内容不应当被考虑。相关区域的下限按照停用字或者临界推测的规则确定,例如按照停用字规则时,如“推荐内容”其对应的偏移(x,y)为800,200时,在对应的偏移(x,y)为860,3200时处解析到了“更多内容”,则应当选择其作为此推荐区域的终点;按照临界推测的方式确定推荐区域的方法为根据推荐区域的起点,确定可信区域内所有的文本位置,并统计所有文本区域出现的间隔,选择具备规律性的节点作为推荐信息节点,例如,在(810,220),(815,282),(850,320),(820,360),(830,420),(830,480),(1024,520),(810,560),(850,720),(810,840),(890,840)分别识别到了"30","2999.0","媲美i7","1799","E5王","透明","秒i7八核主机","1488.00","2021","30","199.00",则应当确定相应的文本分布以280为间隔,具体计算方式可以为从最大纵向偏移值的文本倒序计算,例选择y=840,假设有效信息节点为I为总节点数,分别尝试1至I的数i,判断y/i相隔5个像素点内是否有可识别的文字,并记为1,对于匹配失败的则记为-1,并统计实际匹配总数,按照此方式确定最大匹配的节点总数,从而确定实际的渲染单元;并基于此选择可点击查询的单元。
另外一种方式为基于DOM的信息获取节点的范围,例如获得标记偏移(x,y)为800,200时,遍历DOM树,并可以构建辅助的映射,以java为例,构建图HashMap
标签离散度的计算较为简单的方式为计算相应领域的权重值非零部分的方差,或为计算相应领域的权重值非零部分的方差,并计算预计减少的第一类标签的占比R
在本发明的一个实施例内,计算出现所有出现的标签对应属性的占比,获得了n个标签及其占比,以及m个属于第一类标签的标签及其占比,计算i个标签所对应占比的平方和,以及所有属于第一类标签的平方和作为R
在本发明的一个实施例中,标签离散度的计算方式为标签所属领域的对应权重值的方差。
对应于标签离散度的计算,以购物网站为例,可以设置一个本地的词典,按照类别包括"女装/内衣/家居、女鞋/男鞋/箱包、母婴/童装/玩具、男装/运动户外、美妆/彩妆/个护、手机/数码/企业、大家电/生活电器、零食/生鲜/茶酒、厨具/收纳/清洁、家纺/家饰/鲜花、图书音像/文具、医药保健/进口、汽车/二手车/用品、房产/装修家具/建材、手表/眼镜/珠宝饰品",对应于"女装/内衣/家居"等一级分类,其可以进一步包括"流行趋势、毛衣、外套、小黑裙、阔腿神裤、宝藏羊毛、西装大衣、芭比裤、无钢圈文胸、美背文胸、上装、卫衣、毛衣、衬衫、T恤、马甲、雪纺衫、女裙、连衣裙、半身裙、旗袍、外套、羽绒、服棉衣、棉服、短外套、毛呢大衣、皮草、风衣、西装、皮衣、女裤、休闲裤牛仔裤打底裤棉裤羽绒裤、特色女装、大码女装、中老年女装、套装、时尚套装、运动套装、服饰服务、洗衣服务、袜子、丝袜、连裤袜、船袜、家居、家居服套装、保暖内衣、睡衣、袜子、睡裙背心、吊带、睡袍、睡裤、内裤、女士内裤、男士内裤、文胸、文胸、文胸套装、抹胸、配件、乳贴、胸垫搭扣、塑身、连体衣、分体塑身、塑身腰封"等二级和三级分类,对应于第二级或者第三级的分类,设置一个或者多个关键字,例如对于路由器,可以设置包括品牌(华为、普联、新华三)、使用的环境(大户型、中户型、小户型)、特性(Wifi6、Wi-Fi6、ax),等关键字,当识别到的文本至少包含一个关键字时,相应的标签的权重增加1或者特定值,对于一个文本,可以设置仅增加第一个匹配的标签或者所有匹配的标签,并按前述的方法计算权重值。
参见图2,在获得可点击或者访问的点击查询区域后,可以构建一个集合,并设置了一个时间间隔,以java实现时,如(5000+new Date().getTime()%12000)ms,在该时间间隔后测试集合内的下一个可点击区域是否属于目标页面。
在本发明的另外一个实施例中,设置单个页面来源的点击查询区域查询次数,即基于单个页面来源的可点击区域不超过此次数,以避免被拦截。
在本发明的另外一个实施例中,设置单个页面来源的点击查询区域查询次数为1,即永远基于新的单个页面来源来实现下一个页面的获取。
然而,通过上述方式确定的可点击或者访问的单元可能不属于目标页面(即含有第一标记属性),因而在判断后发现不存在可点击区域时,可以通过获得配置文件内queryField对应的单元,通过调用ajax进行赋值、或者更改dom进行赋值或者获得该查询位置后,通过自动点击工具获得输入焦点后输入。
上述实施方案中,通过截图获得的节点位置确定各个元素或者节点的位置,对于无法通过解析方式或者元素节点位置的情况,可以通过预设规则或者手工确定的方式进行,例如通过选择特定的区域,从而使得具体区域和节点关联;对于预设规则方式确定节点位置的,则可以通过获得分辨率信息和页面的缩放比,进而获得页面中对应部件的位置。
如图2,在进行完成一个循环后,如至少进行60个页面的访问后,访问第一页面,或者在第二页面内含有推荐内容时,或者指定第三页面作为测试页面,并按照前述的方式重新计算推荐的离散度,发现目标关键词所属词组的出现率明显降低,如“母婴”、“计算机硬件”相关的推荐已经消失。且使用虚拟机环境测试时,相应的推荐中并不存在“母婴”、“计算机硬件”相关的推荐,这表明相应的操作在一定程度上改变了网站对于用户的画像。
在一个实例中,上述的操作在登陆账号后进行,在更换网络环境和所使用的客户端类型后(PC端→安卓手机端),推送区域的内容发生了近似的变化。
相近似的操作适用于使用了智能推荐的知识问答平台和自媒体平台,均实现了个人爱好信息的保护。
在部分情况下,由于网络原因,本地获取的信息可能为缓存,从而影响了离散度的计算,在此情况下,可以通过设置http头包含no-cache设置来避免此缺陷。
在部分情况下,部分网站并不适用于此方式进行敏感信息的保护,在此情况下,可以通过设置一个阈值,如设置步骤2)最多被执行3次,以及每次执行步骤2)中的第二页面数目不超过100,从而避免被服务平台误判为非正常访问。
通过上述的方式可以实现使用浏览记录进行信息预测从而实现推送的信息的偏离,进而使得用户的隐私得到了保护。
- 图像数据处理方法、用于图像数据处理方法的程序、记录有用于图像数据处理方法的程序的记录介质和图像数据处理装置
- 药箱的数据处理方法、装置、数据处理方法和装置