一种异常业务指标分析方法及装置
文献发布时间:2023-06-19 12:07:15
技术领域
本公开涉及数据分析技术领域,尤其涉及一种异常业务指标分析方法及装置。
背景技术
随着大数据时代的到来,企业获得数据的数量呈爆炸式增长,企业按照不同的度量衡标准(后续简称为指标)获取相应的多维度数据集合,其中每条数据包含多个维度,所述维度指的是人们观察数据的角度,例如,可以将“上海用户A搜索冰皮月饼的做法”的数据,划分为地域、用户、食品、做法四个维度;进一步地,还可以将一个维度划分为多个维度因子,所述维度因子指的是人们观察数据的某个维度的细节程度,又例如,可以将“地域”维度进一步划分为北京、上海、天津。
当指标发生异常波动时,企业通过对多维度数据集合进行交叉分析,可有效排查和确定引起指标发生异常波动的根本原因。在现有技术中,通常是采用蒙特卡洛搜索树与层级剪枝相结合的方法,确定引起指标发生异常波动的维度因子组合。
具体地,先将各个原始维度确定为第一层相应的根节点,再对各个原始维度进行排列组合,并将各个维度组合确定为第二层相应的节点,以此类推,直至生成最后一层相应的叶子节点;
其次,各个根节点下包含相应的维度因子组合集,依次遍历各个根节点的维度因子组合集,计算各个根节点的各个维度因子组合的异常概率值,剔除低于设定阈值的异常概率值对应的维度因子组合,将异常概率最大值对应的维度因子组合,确定为第一层的候选维度因子组合,以此类推,直至得到其他各层的候选维度因子组合;
最后,将异常概率最大值对应的候选维度因子组合,确定为该指标的目标维度因子组合。
但是采用这种方法会引起以下问题:首先,蒙特卡洛搜索树具有一定随机性,针对同一指标的多维度数据集合,可能在实际应用中会输出不同的运行结果,容易引起歧义;其次,即便在层级遍历中使用了层级剪枝算法剔除冗余维度因子组合,但后续层中节点待遍历的维度因子组合数量依然很大,增加运算量。
有鉴于此,需要设计一种新的异常业务指标分析方法及装置,以克服上述缺陷。
发明内容
本公开提供一种异常业务指标分析方法及装置,用于实现提高准确率,减小运算量。本公开的技术方案如下:
根据本公开实施例的第一方面,提供一种异常业务指标分析方法,包括:
在执行业务任务的过程中,对产生的多维度数据集合进行实时监控,其中,一个维度表征一种业务属性,所述多维度数据表征包含多种业务属性的数据;
基于获得的所述多维度数据集合,判定存在异常业务指标时,确定与所述异常业务指标对应的多个维度,并基于所述多个维度,生成相应的节点树,其中,所述异常业务指标表征影响业务数据波动的因素,所述节点树内的每一层至少包含一个节点,所述一个节点对应一个维度或者多个维度;
循环遍历所述节点树中的各层,其中,在一次循环过程中,执行以下操作:
每遍历一层,基于设置的最大元素数目以及对应所述一层中各个节点分别设置的待选维度因子集合,生成所述一层中各个节点对应的维度因子组合集,所述维度因子组合集表征导致产生所述异常业务指标的业务属性值集合,并对各个待选维度因子集合进行更新,基于获得的各个维度因子组合集中,确定在上一层中存在一个维度因子组合符合预设的遍历停止规则时,停止遍历,并对所述最大元素数目进行更新,以及在进一步确定所述一个维度因子组合符合预设的异常筛选规则时,停止循环,并将所述一个维度因子组合作为所述异常业务指标分析结果输出。
可选的,确定所述多个维度之后,基于所述多个维度,生成相应的节点树之前,进一步包括:
基于所述多维度数据集合,确定所述多个维度各自对应的初始维度因子集合;
分别针对各个初始维度因子集合执行以下操作:
计算一个初始维度因子集合中各类初始维度因子的占比值,其中,一类初始维度因子的占比值,表征取值相同的一类初始维度因子在所述一个初始维度因子集合中所占百分比;
在所述一个初始维度因子集合中,删除占比值未达到预设门限值的一类初始维度因子;
将经过处理的各个初始维度因子集合,设置为相应维度对应的待选维度因子集合的初始值。
可选的,基于所述多个维度,生成相应的节点树,包括:
基于所述多个维度生成第一层的各个节点,所述第一层中的一个节点对应一个维度;
从第二层开始,循环执行以下操作,直到确定无法生成新的排列组合结果为止:对上一层的各个节点对应的维度进行排列组合,基于排列组合结果生成当前层的各个节点,其中,当前层的一个节点对应一个排列组合结果;
基于各层的生成顺序,以及各层输出的节点,形成相应的节点树。
可选的,每遍历一层,基于设置的最大元素数目以及对应所述一层中各个节点分别设置的待选维度因子集合,生成所述一层中各个节点对应的维度因子组合集,并对各个待选维度因子集合进行更新,包括:
基于所述最大元素数目,确定一个维度因子组合包含的维度因子数目最大值;
分别针对所述一层中各个节点对应的待选维度因子集合执行以下操作:
对一个待选维度因子集合进行排列组合,基于排列组合结果生成一个节点对应的维度因子组合集;
计算各个维度因子组合对应的异常概率值,将各个异常概率值按照从大到小的顺序进行排列,在所述维度因子组合集中,删除所述异常概率值未达到设定排列次序的维度因子组合;
将经过处理的所述维度因子组合集,确定为所述一个节点对应的新的维度因子组合集;
基于所述新的维度因子组合集,对所述一个节点对应的待选维度因子集合进行更新。
可选的,计算各个维度因子组合中的一个维度因子组合的异常概率值时,包括:
在所述多维度数据集合中,筛选出包含所述一个维度因子组合的多维度数据;
将所述多维度数据的总数目,与所述多维度数据集合中各条多维度数据的总数目之间的比值,确定为所述一个维度因子组合的异常概率值。
可选的,基于获得的各个维度因子组合集中,确定在上一层中存在一个维度因子组合符合预设的遍历停止规则时,包括:
基于所述一层对应的所述各个维度因子组合集,确定所述一层对应的异常概率最大值;
确定所述一层对应的异常概率最大值,小于上一层对应的异常概率最大值时,判定所述是一层中的异常概率最大值对应的维度因子组合,符合所述遍历停止规则。
可选的,在进一步确定所述一个维度因子组合符合预设的异常筛选规则时,停止循环,并将所述的一个维度因子组合作为所述节点树的目标维度因子组合输出,包括:
将上一次循环过程中输出的异常概率最大值,与当前循环过程中输出的异常概率最大值之间的差值,确定为所述一个维度因子组合的异常概率增长速度;
确定所述一个维度因子组合的异常概率值增长速度,小于上一次循环过程中输出的一个维度因子组合的异常概率值增长速度时,判定所述一个维度因子组合符合所述异常筛选规则;
停止循环,并将所述的一个维度因子组合作为所述异常业务指标分析结果输出。
根据本公开实施例的第二方面,提供一种异常业务指标分析装置,包括:
生成单元,被配置为在执行业务任务的过程中,对产生的多维度数据集合进行实时监控,其中,一个维度表征一种业务属性,所述多维度数据表征包含多种业务属性的数据;
基于获得的所述多维度数据集合,判定存在异常业务指标时,确定与所述异常业务指标对应的多个维度,并基于所述多个维度,生成相应的节点树,其中,所述异常业务指标表征影响业务数据波动的因素,所述节点树内的每一层至少包含一个节点,所述一个节点对应一个维度或者多个维度;
分析单元,被配置为循环遍历所述节点树中的各层,其中,在一次循环过程中,执行以下操作:
每遍历一层,基于设置的最大元素数目以及对应所述一层中各个节点分别设置的待选维度因子集合,生成所述一层中各个节点对应的维度因子组合集,所述维度因子组合集表征导致产生所述异常业务指标的业务属性值集合,并对各个待选维度因子集合进行更新,基于获得的各个维度因子组合集中,确定在上一层中存在一个维度因子组合符合预设的遍历停止规则时,停止遍历,并对所述最大元素数目进行更新,以及在进一步确定所述一个维度因子组合符合预设的异常筛选规则时,停止循环,并将所述的一个维度因子组合作为所述异常业务指标分析结果输出。
可选的,确定所述多个维度之后,基于所述多个维度,生成相应的节点树之前,所述生成单元进一步配置为:
基于所述多维度数据集合,确定所述多个维度各自对应的初始维度因子集合;
分别针对各个初始维度因子集合执行以下操作:
计算一个初始维度因子集合中各类初始维度因子的占比值,其中,一类初始维度因子的占比值,表征取值相同的一类初始维度因子在所述一个初始维度因子集合中所占百分比;
在所述一个初始维度因子集合中,删除占比值未达到预设门限值的一类初始维度因子;
将经过处理的各个初始维度因子集合,设置为相应维度对应的待选维度因子集合的初始值。
可选的,基于所述多个维度,生成相应的节点树,所述生成单元被配置为:
基于所述多个维度生成第一层的各个节点,所述第一层中的一个节点对应一个维度;
从第二层开始,循环执行以下操作,直到确定无法生成新的排列组合结果为止:对上一层的各个节点对应的维度进行排列组合,基于排列组合结果生成当前层的各个节点,其中,当前层的一个节点对应一个排列组合结果;
基于各层的生成顺序,以及各层输出的节点,形成相应的节点树。
可选的,每遍历一层,基于设置的最大元素数目以及对应所述一层中各个节点分别设置的待选维度因子集合,生成所述一层中各个节点对应的维度因子组合集,并对各个待选维度因子集合进行更新,所述分析单元被配置为:
基于所述最大元素数目,确定一个维度因子组合包含的维度因子数目最大值;
分别针对所述一层中各个节点对应的待选维度因子集合执行以下操作:
对一个待选维度因子集合进行排列组合,基于排列组合结果生一个节点对应的维度因子组合集;
计算各个维度因子组合对应的异常概率值,将各个异常概率值按照从大到小的顺序进行排列,在所述维度因子组合集中,删除所述异常概率值未达到设定排列次序的维度因子组合;
将经过处理的所述维度因子组合集,确定为所述一个节点对应的新的维度因子组合集;
基于所述新的维度因子组合集,对所述一个节点对应的待选维度因子集合进行更新。
可选的,计算各个维度因子组合中的一个维度因子组合的异常概率值时,所述分析单元被配置为:
在所述多维度数据集合中,筛选出包含所述一个维度因子组合的多维度数据;
将所述多维度数据的总数目,与所述多维度数据集合中各条多维度数据的总数目之间的比值,确定为所述一个维度因子组合的异常概率值。
可选的,基于获得的各个维度因子组合集中,确定在上一层中存在一个维度因子组合符合预设的遍历停止规则时,所述分析单元被配置为:
基于所述一层对应的所述各个维度因子组合集,确定所述一层对应的异常概率最大值;
确定所述一层对应的异常概率最大值,小于上一层对应的异常概率最大值时,判定所述上一层中的异常概率最大值对应的维度因子组合,符合所述遍历停止规则。
可选的,在进一步确定所述一个维度因子组合符合预设的异常筛选规则时,停止循环,并将所述的一个维度因子组合作为所述节点树的目标维度因子组合输出,所述分析单元被配置为:
将上一次循环过程中输出的异常概率最大值,与所述当前循环过程中输出的异常概率最大值之间的差值,确定为所述一个维度因子组合的异常概率增长速度;
确定所述一个维度因子组合的异常概率值增长速度,小于上一次循环过程中输出的一个维度因子组合的异常概率值增长速度时,判定所述一个维度因子组合符合所述异常筛选规则;
停止循环,并将所述的一个维度因子组合作为所述异常业务指标分析结果输出。
根据本公开实施例的第三方面,提供一种电子设备,包括:
存储器,用于存储可执行指令;
处理器,用于读取并执行所述存储器中存储的可执行指令,以实现上述任一项方法。
根据本公开实施例的第四方面,提供一种存储介质,当所述存储介质中的指令由处理器执行时,使得能够执行上述任一项方法的步骤。
本公开的实施例提供的技术方案至少带来以下有益效果:
在本公开实施例中,在执行业务任务的过程中,对产生的多维度数据集合进行实时监控,基于获得的多维度数据集合,判定存在异常业务指标时,确定与异常业务指标对应的多个维度,并基于多个维度,产生相应的节点树;通过循环遍历节点树中的各层,其中在一次循环中,每遍历一层,基于最大元素数目以及对应所述一层中各个节点的待选维度因子集合,生成所述一层中各个节点对应的维度因子组合集,并对各个待选维度因子集合进行更新,基于获得的各个维度因子组合集中,确定在上一层中存在一个维度因子组合符合遍历停止规则时,停止遍历,并对最大元素数目更新,以及在进一步确定所述一个维度因子组合符合异常筛选规则时,停止循环,并将所述一个维度因子组合作为异常业务指标分析结果输出。在一次循环中,只要在某一层中存在符合遍历停止条件的一个维度因子组合,就可以停止遍历,无需遍历节点树内的所有层,减小运算量;进一步地,只要所述一个维度因子组合符合异常筛选条件时,就将所述一个维度因子组合作为异常业务指标分析结果输出,针对同一指标的多维度数据集合进行分析,最终输出的异常业务指标分析结果一致,不会产生歧义,提高准确率。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理,并不构成对本公开的不当限定。
图1是根据一示例性实施例示出的异常业务指标分析的流程示意图。
图2是根据一示例性实施例示出了节点树的示意图。
图3是根据一示例性实施例示出的一种异常业务指标分析装置的框图。
图4是根据一示例性实施例示出的一种电子设备的结构示意图。
具体实施方式
为了使本领域普通人员更好地理解本公开的技术方案,下面将结合附图,对本公开实施例中的技术方案进行清楚、完整地描述。
需要说明的是,本公开的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本公开的实施例能够以除了在这里图示或描述的那些以外的顺序实施。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。
为了实现降低应用成本,提高准确率和减小运算量,在本公开实施例中提供了一种解决方案,该方案为:在执行业务任务的过程中,对产生的多维度数据集合进行实时监控,基于获得的多维度数据集合,判定存在异常业务指标时,确定与异常业务指标对应的多个维度,并基于多个维度,产生相应的节点树;通过循环遍历节点树中的各层,其中在一次循环中,每遍历一层,基于最大元素数目以及对应所述一层中各个节点的待选维度因子集合,生成所述一层中各个节点对应的维度因子组合集,并对各个待选维度因子集合进行更新,在确定获得的各个维度因子组合集中,存在一个维度因子组合符合遍历停止规则时,停止遍历,并对最大元素数目更新,以及在进一步确定所述一个维度因子组合符合异常筛选规则时,停止循环,并将所述一个维度因子组合作为异常业务指标分析结果输出。
下面结合附图对本公开优选实施方式进行详细说明。
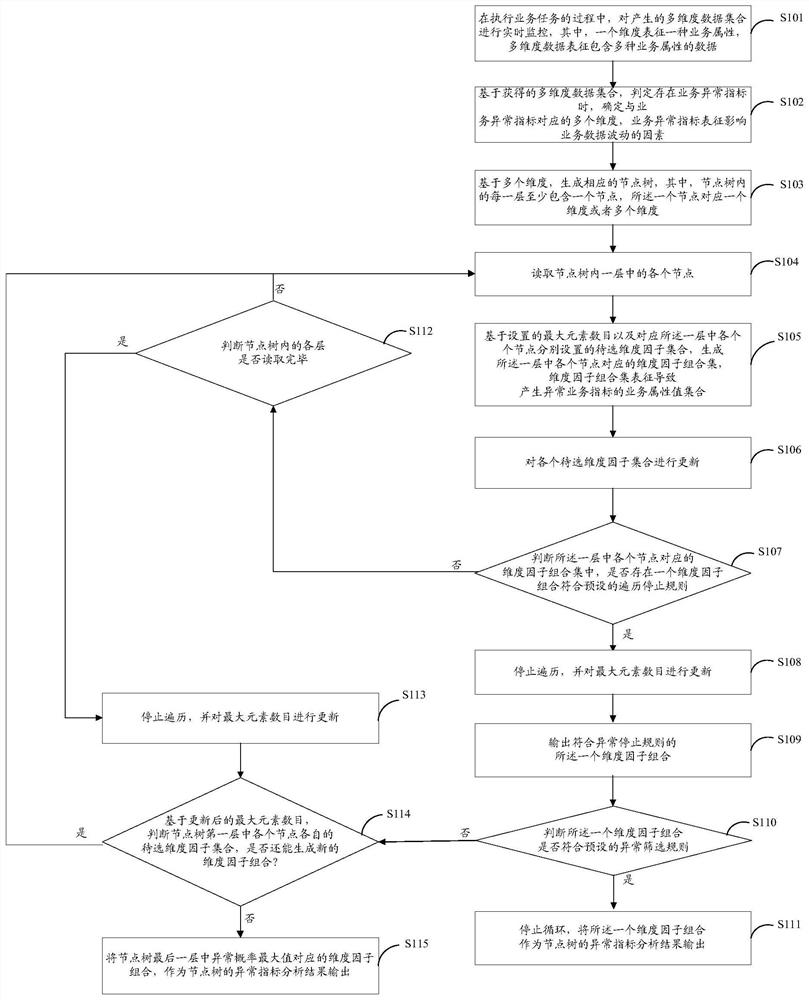
参阅图1所示,本公开实施例中对异常业务指标分析的详细过程如下:
S101:在执行业务任务的过程中,对产生的多维度数据集合进行实时监控,其中,一个维度表征一种业务属性,多维度数据表征包含多种业务属性的数据。
例如,多维度数据“上海用户A搜索冰皮月饼的做法”,可以被划分为地域、用户、食品、做法四个维度。
S102:基于获得的多维度数据集合,判定存在异常业务指标时,确定与异常业务指标对应的多个维度,异常业务指标表征影响业务数据波动的因素。
在执行业务任务的过程中,对产生的多维度数据集合进行实时监控,基于获得的多维度数据集合,对预设的各个业务指标的数值进行实时更新,当业务指标的数值未位于预设阈值区间时,判定该业务指标为异常业务指标;再获取异常业务指标发生时间段内产生的多维度数据集合,确定所述多维度数据集合对应的多个维度,并将所述多个维度,作为异常业务指标对应的多个维度输出。
例如,获取视频平台当天的多维度播放数据集合,确定该视频平台的当天视频播放总次数为3600次,高于阈值区间[2000,3000],判定视频播放总次数这一指标为异常业务指标,并基于当天的多维度播放数据集合,确定视频播放总次数对应的多个维度分别为,用户、性别、用户年龄段、地域、视频类型、观看视频时间段。
可选的,在确定多个维度之后,在基于多个维度生成相应的节点树之前,进一步地,可基于多维度数据集合,确定多个维度各自对应的初始维度因子集合,一个维度因子表征一个业务属性值。
在实际应用场景下,由于维度划分不均匀,而造成维度的初始维度因子集合中包含大量的初始维度因子,而在所述初始维度因子集合中,占比值过低的某类初始维度因子(后续简称长尾因子)通常是不具备分析价值的,若各个初始维度因子集合未将各自集合中的长尾因子删除,还可能影响最终异常分析结果的准确性。因此,为了减小分析运算量和提高异常分析结果准确性,分别针对各个初始维度因子集合执行预处理操作,具体过程如下:
A1、计算一个初始维度因子集合中各类初始维度因子的占比值,其中,一类初始维度因子的占比值,表征取值相同的一类初始维度因子在所述一个初始维度因子集合中所占百分比;
A2、在所述一个初始维度因子集合中,删除占比值未达到预设门限值的一类初始维度因子;
A3、判断各个初始维度因子集合是否均处理完毕,若是,执行步骤A4;否则,返回步骤A1;
A4、将经过处理的各个初始维度因子集合,设置为相应维度对应的待选维度因子集合的初始值。
为了便于理解上述内容,举一具体实施例进行描述。
例如,当后台在周六监控到“视频播放次数”指标发生骤减时,将判定所述指标发生异常,在终端执行视频播放任务时,并自动获取各终端在周六执行视频播放任务时产生的多维度数据集合,所述多维度数据集合如表1所示。
表1
其中,基于表1中的多维度数据集合,可确定出“地域”、“用户性别”“日期”三个维度;而在“地域”维度下包括“北京市”、“天津市”和“上海市”三类初始维度因子,在“用户性别”维度下包括“男”、“女”两类初始维度因子,在“日期”维度下包括“周六”一类初始维度因子。
通过计算“地域”维度下各类初始维度因子的占比值可知,“上海市”初始维度因子的占比值是25%,“天津市”初始维度因子的占比值是25%,“北京市”初始维度因子的占比值是50%,由于各类初始维度因子的占比值均大于预设门限值,无需对“地域”维度的初始维度因子集合执行删除操作。
S103:基于多个维度,生成相应的节点树,其中,节点树内的每一层至少包含一个节点,所述一个节点对应一个维度或者多个维度。
可选的,基于多个维度生成相应的节点树的过程如下:
B1、基于多个维度生成第一层的各个节点,其中第一层的一个节点对应的一个维度;
循环执行步骤B2~B4,生成第二层直至最后一层中的各个节点;
B2、对上一层的各个节点对应的维度进行排列组合;
B3、基于排列组合结果生成当前层的各个节点,其中,当前层的一个节点对应一个排列组合结果;
B4、判断是否仍能生成新的排列组合结果,若是,返回步骤B2;否则,执行步骤B5;
B5、基于各层的生成顺序,以及各层输出的节点,形成相应的节点树。
为了便于理解,举一具体实施例进行描述。
例如,异常指标包含A、B、C三个维度,那么基于A、B、C三个维度生成的节点树如图2所示,具体生成过程如下:
首先,将A、B、C三个维度作为第一层的节点;
然后,将A、B、C三个维度进行排列组合,得到AB、AC和BC三个排列组合结果,并将AB、AC和BC作为第二层的节点;
最后,将AB、AC和BC再次排列组合,得到ABC一个排列组合结果,并将ABC作为第三层的节点输出。由于第三层的ABC节点无法生成新的排列组合结果,继而无法生成第四层中的各个节点,因此,ABC可以看做是第三层的节点,也可以看做是最后一层的叶子节点。
S104:读取节点树内一层中的各个节点。
S105:基于设置的最大元素数目以及对应所述一层中各个节点分别设置的待选维度因子集合,生成所述一层中各个节点对应的维度因子组合集,维度因子组合集表征业务指标异常的业务属性值集合。
可选的,以所述一层中的一个节点为例,生成所述一个节点的维度因子组合集的过程如下:
C1、基于最大元素数目,确定一个维度因子组合包含的维度因子数目最大值。
C2、选取所述一个节点对应的待选维度因子集合。
C3、对一个待选维度因子集合进行排列组合,基于排列组合结果生成所述一个节点对应的维度因子组合集。
例如,最大元素数目是2,地域维度的待选维度因子集合为(天津,北京,上海),那么,地域维度的维度因子组合集,如表2所示。
表2
S106:对各个待选维度因子集合进行更新。
可选的,以一个待选维度因子集合为例,其更新过程如下:
D1、计算所述一层中各个维度因子组合对应的异常概率值。
其中,计算一个维度因子组合的异常概率值的过程如下:
首先,在多维度数据集合中,筛选出包含一个维度因子组合的多维度数据;
其次,将多维度数据的总数目,与多维度数据集合中各条多维度数据的总数目之间的比值,确定为所述一个维度因子组合的异常概率值。
所述异常概率值表征,所述一个维度因子组合造成指标发生异常的可能性。若维度因子组合的异常概率值低,表征所述维度因子组合造成指标发生异常的可能性低;若维度因子组合的异常概率值高,表征所述维度因子组合造成指标发生异常的可能性高。
例如,假设多维度数据集合如表3所示,需要计算维度因子组合(“北京”&“女”&“18-23”)的异常概率值。
表3
在上述多维度数据集合中,有2条多维度数据同时包含(“北京”&“女”&“18-23”)这一维度因子组合,因此,(“北京”&“女”&“18-23”)的异常概率值为2/6=1/3。
D2、将各个异常概率值按照从大到小的顺序进行排列,在维度因子组合集中,删除异常概率值未达到设定排列次序的维度因子组合。
若维度因子组合的异常概率值低,表征所述维度因子组合造成指标发生异常的可能性低,说明构成所述维度因子组合的各个维度因子,并不是造成指标发生异常的根本原因。通常来说,对所述各个维度因子进行排列组合,基于排列组合结果确定下一层中对应的维度因子组合,所述对应的维度因子组合的异常概率值也不高。
因此,为了进一步减小运算量,先将异常概率值按照从大到小的顺序进行排列;然后在维度因子组合集中,删除异常概率值未达到设定排列次序的维度因子组合。这样,可以将异常概率值较大的维度因子组合保留下来,以确保最终输出的异常指标分析结果的准确率。
D3、将经过处理的维度因子组合集,确定为所述一个节点对应的新的维度因子组合集。
D4、基于所述新的维度因子组合集,对所述一个节点对应的待选维度因子集合进行更新。
例如,维度A的待选维度因子集合为(a1,a2,a3,a4),而维度A的新的维度因子组合集是{(a1,a3),(a1,a2)},由于维度因子a4与(a1,a3)、(a1,a2)均不存在交集,故将a4删除。
又例如,维度A包含3类维度因子(a1,a2,a3,a4),而维度A对应的维度因子组合集是{(a1,a2,a3),(a2,a4)},由于所有维度因子与(a1,a2,a3)、(a2,a4)均存在交集,故保留所有的维度因子。
为了便于举例,上述各个例子中的维度数目,以及各维度对应的待选维度因子数目都比较少,但是在实际应用场景中,需要对10个维度以上的数据进行异常分析,而且每一维度下包含成百上千个待选维度因子,因此,执行步骤D4,将大大减小运算量,而且及时剔除冗余数据,也会提高异常分析结果的准确率。
S107:基于所述一层中各个节点对应的维度因子组合集中,判断在上一层中是否存在一个维度因子组合符合预设的遍历停止规则,若是,执行步骤108;否则,执行步骤112。
可选的,具体判断过程如下:
首先,基于所述一层对应的各个维度因子组合集,确定所述一层对应的异常概率最大值。
其次,确定所述一层对应的异常概率最大值,小于上一层对应的异常概率最大值时,判定所述上一层中的异常概率最大值对应的维度因子组合,符合遍历停止规则。
若维度因子组合的异常概率值低,表征所述维度因子组合造成指标发生异常的可能性低;若维度因子组合的异常概率值高,表征所述维度因子组合造成指标发生异常的可能性高。因此,通过设置的遍历停止规则,可以确定出在当前循环过程中的异常概率最大值的维度因子组合。
S108:停止遍历,并对最大元素数目进行更新。
可以根据实际应用场景设置最大元素数目的取值,在此并不多作限定。但是,若最大元素数目设置的过小,可能在遍历过程中,遗漏掉能影响指标状态(即正常状态或者异常状态)的维度因子;若最大元素数目设置的过大,在遍历过程中会获取到很多冗余或者无效的维度因子,增大运算量。因此,可以将最大元素数目的初始值设为2,每次更新加1,逐步确定最合理的最大元素数目。
S109:输出符合遍历停止规则的所述一个维度因子组合。
S110:判断所述一个维度因子组合是否符合预设的异常筛选规则,若是,执行步骤111;否则,执行步骤113。
可选的,判断所述一个维度因子组合是否符合异常筛选规则的过程如下:
首先,将上一次循环过程中输出的异常概率最大值,与当前循环过程中输出的异常概率最大值之间的差值,确定为所述一个维度因子组合的异常概率增长速度;
其次,确定所述一个维度因子组合的异常概率值增长速度,小于上一次循环过程中输出的一个维度因子组合的异常概率值增长速度时,判定所述一个维度因子组合符合所述异常筛选规则。
S111:停止循环,将所述一个维度因子组合作为异常业务指标分析结果输出。
所述一个维度因子组合的异常概率值最大,表征所述一个维度因子组合是导致指标发生异常的可能性最大;而且随着最大元素数目的增大,自节点树第一层开始,每一层中各个节点对应的待选维度因子集合的排列组合结果变多,也就是说,每一层中各个节点对应的维度因子组合的个数变多,通常当前层的异常概率最大值的增长速度,比上一层的异常概率最大值的增长速度要快,而当增长速度变慢时,就可以确认后面层中的异常概率最大值的增长速度会持续变慢,因此,直接将增长速度由快转慢这一转折点,所对应的所述一个维度因子组合确定为引起指标发生异常的根本原因。
S112:判断节点树内的各层是否读取完毕,若是,执行步骤112;否则,返回步骤103。
S113:停止遍历,并对最大元素数目进行更新。
S114:基于更新后的最大元素数目,判断节点树第一层中各个节点各自的待选维度因子集合,是否还能生成新的维度因子组合,若是,返回步骤104;否则,执行步骤115。
例如,地域维度的待选维度因子集合为(天津,北京,上海),用户维度的待选维度因子集合为(李先生,张女士,王女士),当最大元素数目设为4时,(天津,北京,上海)排列组合后无法生成新的维度因子组合,同理,(李先生,张女士,王女士)排列组合后也无法生成新的维度因子组合。
S115:将节点树最后一层中异常概率最大值对应的维度因子组合,作为业务异常指标分析结果输出。
例如,节点树最后一层中异常概率最大值对应的维度因子组合为(天津,女性,20~29岁,古装爱情剧,20:00~24:00),表征导致当天的视频播放总次数高于阈值区间的根本原因是,天津市处于20~29岁的女性观众,喜欢在晚上20:00~24:00登陆视频平台观看古装爱情类型的电视剧。
基于上述实施例,参阅图3所示,本公开实施例中,提供一种异常业务指标分析装置300,至少包括生成单元301和分析单元302,其中,
生成单元301,被配置为在执行业务任务的过程中,对产生的多维度数据集合进行实时监控,其中,一个维度表征一种业务属性,所述多维度数据表征包含多种业务属性的数据;
基于获得的所述多维度数据集合,判定存在异常业务指标时,确定与所述异常业务指标对应的多个维度,并基于所述多个维度,生成相应的节点树,其中,所述异常业务指标表征影响业务数据波动的因素,一个维度表征一种属性,所述节点树内的每一层至少包含一个节点,所述一个节点对应一个维度或者多个维度;
分析单元302,被配置为循环遍历所述节点树中的各层,其中,在一次循环过程中,执行以下操作:
每遍历一层,基于设置的最大元素数目以及对应所述一层中各个节点分别设置的待选维度因子集合,生成所述一层中各个节点对应的维度因子组合集,所述维度因子组合集表征导致产生异常业务指标的业务属性值集合,并对各个待选维度因子集合进行更新,基于获得的各个维度因子组合集中,确定在上一层中存在一个维度因子组合符合预设的遍历停止规则时,停止遍历,并对所述最大元素数目进行更新,以及在进一步确定所述一个维度因子组合符合预设的异常筛选规则时,停止循环,并将所述的一个维度因子组合作为所述异常业务指标分析结果输出。
可选的,确定所述多个维度之后,基于所述多个维度,生成相应的节点树之前,所述生成单元301进一步配置为:
基于所述多维度数据集合,确定所述多个维度各自对应的初始维度因子集合;
分别针对各个初始维度因子集合执行以下操作:
计算一个初始维度因子集合中各类初始维度因子的占比值,其中,一类初始维度因子的占比值,表征取值相同的一类初始维度因子在所述一个初始维度因子集合中所占百分比;
在所述一个初始维度因子集合中,删除占比值未达到预设门限值的一类初始维度因子;
将经过处理的各个初始维度因子集合,设置为相应维度对应的待选维度因子集合的初始值。
可选的,基于所述多个维度,生成相应的节点树,所述生成单元301被配置为:
基于所述多个维度生成第一层的各个节点,所述第一层中的一个节点对应一个维度;
从第二层开始,循环执行以下操作,直到确定无法生成新的排列组合结果为止:对上一层的各个节点对应的维度进行排列组合,基于排列组合结果生成当前层的各个节点,其中,当前层的一个节点对应一个排列组合结果;
基于各层的生成顺序,以及各层输出的节点,形成相应的节点树。
可选的,每遍历一层,基于设置的最大元素数目以及对应所述一层中各个节点分别设置的待选维度因子集合,生成所述一层中各个节点对应的维度因子组合集,并对各个待选维度因子集合进行更新,所述分析单元302被配置为:
基于所述最大元素数目,确定一个维度因子组合包含的维度因子数目最大值;
分别针对所述一层中各个节点对应的待选维度因子集合执行以下操作:
对一个待选维度因子集合进行排列组合,基于排列组合结果生一个节点对应的维度因子组合集;
计算各个维度因子组合对应的异常概率值,将各个异常概率值按照从大到小的顺序进行排列,在所述维度因子组合集中,删除所述异常概率值未达到设定排列次序的维度因子组合;
将经过处理的所述维度因子组合集,确定为所述一个节点对应的新的维度因子组合集;
基于所述新的维度因子组合集,对所述一个节点对应的待选维度因子集合进行更新。
可选的,计算各个维度因子组合中的一个维度因子组合的异常概率值时,所述分析单元302被配置为:
在所述多维度数据集合中,筛选出包含所述一个维度因子组合的多维度数据;
将所述多维度数据的总数目,与所述多维度数据集合中各条多维度数据的总数目之间的比值,确定为所述一个维度因子组合的异常概率值。
可选的,基于获得的各个维度因子组合集中,确定在上一层中存在一个维度因子组合符合预设的遍历停止规则时,所述分析单元302被配置为:
基于所述一层对应的所述各个维度因子组合集,确定所述一层对应的异常概率最大值;
确定所述一层对应的异常概率最大值,小于上一层对应的异常概率最大值时,判定所述一层中的异常概率最大值对应的维度因子组合,符合所述遍历停止规则。
可选的,在进一步确定所述一个维度因子组合符合预设的异常筛选规则时,停止循环,并将所述的一个维度因子组合作为所述节点树的目标维度因子组合输出,所述分析单元302被配置为:
将上一次循环过程中输出的异常概率最大值,与所述当前循环过程中输出的异常概率最大值之间的差值,确定为所述一个维度因子组合的异常概率增长速度;
确定所述一个维度因子组合的异常概率值增长速度,小于上一次循环过程中输出的一个维度因子组合的异常概率值增长速度时,判定所述一个维度因子组合符合所述异常筛选规则;
停止循环,并将所述的一个维度因子组合作为所述异常业务指标分析结果输出。
基于上述实施例,参阅图4所示,本公开实施例中,提供一种计算设备,至少包括存储器401和处理器402,其中,
存储器401,用于存可执行指令;
处理器402,用于读取并执行所述存储器中存储的可执行指令,以实现上述任一项方法。
基于上述实施例,提供一种存储介质,至少包括:当所述存储介质中的指令由的处理器执行时,使得能够执行上述任一项方法的步骤。
综上所述,在本公开实施例中,在执行业务任务的过程中,对产生的多维度数据集合进行实时监控,基于获得的多维度数据集合,判定存在异常业务指标时,确定异常业务指标对应的多个维度,并基于多个维度,产生相应的节点树;通过循环遍历节点树中的各层,其中在一次循环中,每遍历一层,基于最大元素数目以及所述一层中各个节点的待选维度因子集合,生成所述一层中各个节点对应的维度因子组合集,并对各个待选维度因子集合进行更新,在确定获得的各个维度因子组合集中,存在一个维度因子组合符合遍历停止规则时,停止遍历,并对最大元素数目更新,以及在进一步确定所述一个维度因子组合符合异常筛选规则时,停止循环,并将所述一个维度因子组合作为异常业务指标分析结果输出。
在一次循环中,只要在某一层中存在符合遍历停止条件的一个维度因子组合,就可以停止遍历,无需遍历节点树内的所有层,不仅减小了运算量,还可以花费最少的分析时间确定出,本次循环中可能符合异常筛选条件的一个维度因子组合;进一步地,只要确定所述一个维度因子组合符合异常筛选条件时,就将所述一个维度因子组合作为异常业务指标分析结果输出,由于每次循环所设置的最大元素数目逐渐增大,自节点树第一层开始,基于每一层中各个节点的待选维度因子集合,生成每一层中各个节点对应的维度因子组合的个数也逐渐增多,这样,在扩大维度因子组合的个数的前提下,确定出符合异常筛选条件的维度因子组合和最合理的最大元素数目,进一步提高异常指标分析结果的准确率;而且,相比于现有技术中采用蒙特卡洛搜索树算法分析指标发生异常的原因,因蒙特卡洛搜索树算法具有一定随机性,针对同一指标的多维度数据集合,会输出不同的运行结果,容易引起歧义,本公开实施例基于同一最大元素数目,对同一指标的多维度数据集合进行多次分析时,最终输出的异常业务指标分析结果均一致,不会产生歧义,因此,采用本公开实施例的方法分析异常指标,可以提高异常业务指标分析结果的准确率。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本公开的其它实施方案。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求指出。
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。
- 一种异常业务指标分析方法及装置
- 一种指标异常根源分析方法、装置及计算机可读存储介质