路径决定方法
文献发布时间:2023-06-19 12:10:19
技术领域
本发明涉及自主移动型的机器人的路径决定方法。
背景技术
以往,作为自主移动型的机器人的路径决定方法,已知有专利文献1及专利文献2中记载的路径决定方法。在该专利文献1的路径决定方法中,机器人基于行人等交通参与者的速度,计算被设想可能与交通参与者发生干扰的可能干扰时间,并且,计算设想交通参与者在规定时间后会移动到的虚拟障碍物区域。然后,基于可能干扰时间及虚拟障碍物区域,决定机器人的路径。由此,避免了机器人与交通参与者的干扰。
此外,在专利文献2的路径决定方法中,计算机器人的当前位置,基于外界传感器测定出的距离数据生成障碍物地图,并且,从存储部读入地图信息。接着,参照障碍物地图及地图信息,判定在存储于地图信息的路径上是否存在障碍物,在路径上存在障碍物的情况下,通过A*搜索算法来执行机器人的路径。具体而言,基于当前位置信息、障碍物地图及地图信息,计算包围网格地图上的机器人的多个网格中的障碍物的存在概率,将障碍物的存在概率最低的网格决定为路径。
现有技术文献
专利文献
专利文献1:日本特开2009-110495号公报
专利文献2:日本特开2010-191502号公报
发明内容
发明要解决的问题
根据上述专利文献1的路径决定方法,由于使用了交通参与者的可能干扰时间及虚拟障碍物区域的关系,当行人等实际的交通参与者以不能够预测的轨迹进行了移动时,机器人与交通参与者的干扰状态频繁发生。其结果是,存在机器人的停止状态频繁发生,商品性较低这样的问题。尤其是在存在人群拥挤的交通环境下,该问题变得显著。
此外,在专利文献2的路径决定方法的情况下,当行人等实际的交通参与者以不能够预测的轨迹进行了移动时,也会产生与专利文献1相同的问题。尤其是在存在人群拥挤的交通环境下,会成为发现不了障碍物的存在概率最低的网格的状态,由此,导致机器人的停止时间变长。
本发明是为了解决上述问题而完成的,其目的在于,提供一种能够决定机器人的路径的路径决定方法,使得即便在人群拥挤等的交通环境下,自主移动型的机器人也在避免与交通参与者的干扰的同时顺利地移动至目的地。
用于解决问题的手段
为了实现上述目的,本发明是一种路径决定方法,在包含行人在内的交通参与者存在于至目的地为止的交通环境的条件下,决定自主移动型的机器人向该目的地移动时的路径,其特征在于,取得在第1行人在避免与该第1行人以外的多个第2行人发生干扰的同时朝向目的地步行的情况下将该多个第2行人的步行模式设定为多种互不相同的步行模式时的第1行人的多个步行路径,生成将如下的图像数据与行动参数的关系相关联而得到的多个数据库,该图像数据是机器人沿着多个步行路径分别进行了移动的情况下包含表示该机器人的前方的视觉环境的环境图像的数据,该行动参数表示机器人沿着多个步行路径分别进行了移动的情况下的该机器人的行动,使用多个数据库,利用规定的学习方法来学习将图像数据作为输入且将行动参数作为输出的行动模型的模型参数,由此,生成学习后的该行动模型、即学习后模型,使用该学习后模型决定机器人的路径。
根据该路径决定方法,使用多个数据库而通过规定的学习方法来学习将图像数据作为输入且将行动参数作为输出的行动模型的模型参数,由此,生成学习后的行动模型、即学习后模型。然后,使用学习后模型决定机器人的路径。在该情况下,多个数据库作为将图像数据与行动参数的关系相关联的数据库而被生成,该图像数据是机器人沿着多个步行路径分别进行了移动的情况下包含表示机器人的前方的视觉环境的环境图像的数据,该行动参数表示机器人的行动。
此外,关于该多个步行路径,取得了在第1行人在避免与第1行人以外的多个第2行人发生的干扰的同时朝向目的地步行的情况下将多个第2行人的步行模式设定为多种互不相同的步行模式时的第1行人的步行路径。因此,多个数据库是将机器人沿着这样的步行路径进行了移动时的图像数据与表示机器人的行动的行动参数相关联而得到的,因此,能够在反映出第1行人的实际的步行路径的同时高精度地学习行动模型的模型参数。其结果是,能够将机器人的路径决定为,即便在人群拥挤等的交通环境下,自主移动型的机器人也会在避免与交通参与者的干扰的同时顺利地移动至目的地。
在本发明中优选的是,图像数据除了包含环境图像之外,还包含表示机器人的速度的大小的程度的速度程度图像、以及表示目的地的方向的方向图像。
根据该路径决定方法,图像数据除了包含环境图像之外,还包含表示机器人的速度的大小的程度的速度程度图像以及表示目的地的方向的方向图像,因此,能够简化行动模型的构造,能够减少机器人的路径决定时的计算量。其结果是,能够迅速且高精度地决定机器人的路径。
在本发明中优选的是,多个数据库是将如下的图像数据与行动参数的关系相关联而得到的,该图像数据与行动参数是虚拟的机器人在虚拟空间内沿着多个步行路径分别进行了移动的情况下的数据与参数。
根据该路径决定方法,通过使虚拟的机器人在虚拟空间中沿着多个步行路径分别移动,能够生成多个数据库。由此,无需实际准备机器人等,相应地能够容易地生成数据库。
附图说明
图1是示出应用了本发明的一实施方式的路径决定装置的机器人的外观的图。
图2是示出机器人的引导系统的结构的图。
图3是示出机器人的电结构的框图。
图4是示出学习装置的结构的框图。
图5是取得第1行人的步行路径时的立体图。
图6是示出图5的步行路径的取得结果的一例的图。
图7是示出开始取得步行路径时的第2行人的配置的第1模式的图。
图8是示出第2行人的配置的第2模式的图。
图9是示出第2行人的配置的第3模式的图。
图10是示出第2行人的配置的第4模式的图。
图11是示出第2行人的配置的第5模式的图。
图12是示出第2行人的配置的第6模式的图。
图13是示出第2行人的配置的第7模式的图。
图14是示出模拟环境下的虚拟机器人视点中的图像的图。
图15是示出根据图14的图像生成的掩模图像的图。
图16是示出路径决定装置等的功能的框图。
图17是示出移动控制处理的流程图。
具体实施方式
以下,参照附图对本发明的一实施方式的路径决定装置进行说明。如图1所示,本实施方式的路径决定装置1应用于倒立摆式的机器人2,通过后述的方法,在交通参与者的存在概率高的条件下决定机器人2的路径。
该机器人2是自主移动型的机器人,在图2所示的引导系统3中使用。该引导系统3是在购物中心或机场等由机器人2给利用者带路并将利用者引导至其目的地(例如店铺或登机口)的形式。
如图2所示,引导系统3具备在规定的区域内进行自主移动的多个机器人2、与多个机器人2分体设置且被输入利用者的目的地的输入装置4、以及能够与机器人2及输入装置4相互进行无线通信的服务器5。
该输入装置4是计算机类型,在通过利用者(或操作者)的鼠标及键盘的操作输入了利用者的目的地时,将表示该目的地的无线信号向服务器5发送。服务器5在接收到来自输入装置4的无线信号时,基于内部的地图数据,将利用者的目的地本身或者直至目的地为止的中继地点设定为目的地Pobj,将表示该目的地Pobj的目的地信号向机器人2发送。
如后所述,机器人2内的控制装置10在经由无线通信装置14接收到来自服务器5的目的地信号时,读入该目的地信号所包含的目的地Pobj,决定直至该目的地Pobj为止的路径。
接着,对机器人2的机械结构进行说明。如图1所示,机器人2具备主体20和设置于主体20的下部的移动机构21等,构成为通过该移动机构21能够在路面上向全方位移动。
具体而言,该移动机构21例如与日本特开2017-56763号的移动机构同样地构成,因此,这里省略其详细说明,但具备圆环状的芯体22、多个滚轮23、第1致动器24(参照图3)及第2致动器25(参照图3)等。
多个滚轮23以按照等角度间隔在芯体22的圆周方向(绕轴心的方向)上排列的方式外插于芯体22,多个滚轮23分别能够绕芯体22的轴心与芯体22一体地旋转。此外,各滚轮23能够绕各滚轮23的配置位置处的芯体22的横截面的中心轴(以芯体22的轴心为中心的圆周的切线方向的轴)进行旋转。
此外,第1致动器24由电动机构成,当从控制装置10被输入了后述的控制输入信号时,经由未图示的驱动机构,驱动芯体22绕其轴心进行旋转。
另一方面,第2致动器25也与第1致动器24同样地由电动机构成,当从控制装置10被输入了控制输入信号时,经由未图示的驱动机构,驱动滚轮23绕其轴心进行旋转。由此,通过第1致动器24及第2致动器25对主体20进行驱动,使得主体20在路面上向全方位移动。根据以上的结构,机器人2能够在路面上向全方位移动。
接着,对机器人2的电结构进行说明。如图3所示,机器人2还具备控制装置10、照相机11、LIDAR(雷达)12、加速度传感器13及无线通信装置14。
该控制装置10由包括CPU、RAM、ROM、E2PROM、I/O接口及各种电气电路(均未图示)等的微型计算机构成。在该E2PROM内存储有机器人2所引导的场所的地图数据及CNN(Convolutional Neural Network:卷积神经网络)。在该情况下,作为CNN,存储有通过后述的学习装置30充分地学习了CNN的模型参数即连接层的权重及偏置项而得到的CNN。
照相机11拍摄机器人2的周边环境,将表示该周边环境的图像信号向控制装置10输出。此外,LIDAR12使用激光计测距周边环境内的对象物的距离等,将表示该距离的计测信号向控制装置10输出。此外,加速度传感器13检测机器人2的加速度,将表示该加速度的检测信号向控制装置10输出。
控制装置10使用以上的照相机11的图像信号及LIDAR12的计测信号,通过amlc(adaptive Monte Carlo localization:自适应蒙特卡洛定位)方法来估计机器人2的自身位置。此外,控制装置10基于LIDAR12的计测信号及加速度传感器13的检测信号,计算机器人2的后述的x轴速度v_x及y轴速度v_y。
此外,无线通信装置14与控制装置10电连接,控制装置10经由该无线通信装置14与服务器5执行无线通信。
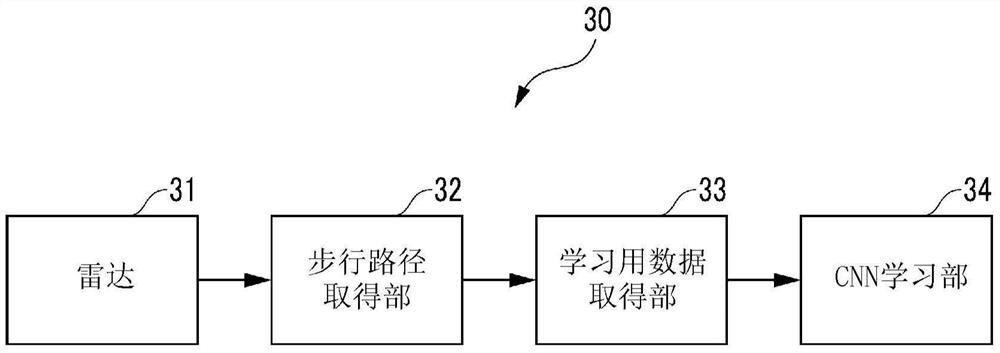
接着,对本实施方式的路径决定装置1的结构及路径决定方法的原理进行说明。首先,对图4所示的学习装置30进行说明。该学习装置30用于学习后述的CNN的模型参数(连接层的权重及偏置项),具备LIDAR31、步行路径取得部32、学习用数据取得部33及CNN学习部34。具体而言,这些要素32~34由未图示的控制器等构成。
首先,为了学习通常的行人的步行路径,如图5所示,将第1行人M1设定为作为基准的行人,在该第1行人M1从步行开始地点Ps(参照图6)步行至目的地地点Po(参照图6)的情况下,在步行开始时,设定了在其行进方向上以不规则的配置存在多个第2行人M2的人群拥挤的交通环境。
接着,使用LIDAR31计测第1行人M1从步行开始地点Ps实际上步行到目的地地点Po时的位置的变化与多个第2行人M2的位置的变化,将该计测结果向步行路径取得部32输出。
然后,在步行路径取得部32中,基于LIDAR31的计测结果,例如如图6所示那样逐次取得第1行人M1的从步行开始地点Ps步行到目的地地点Po的步行路径Rw并进行存储。如该图所示,取得将沿第1行人M1的行进方向延伸的轴规定为x轴且将与第1行人M1的行进方向正交的轴规定为y轴时的二维的x-y坐标值来作为第1行人M1的步行路径Rw。另外,以下的说明中的x轴及y轴的定义与图6相同。
该x轴的原点被设定为第1行人M1的步行开始地点Ps,y轴的原点被设定为第1行人M1的行进方向的右侧的规定位置。此外,从第1行人M1的步行开始地点Ps达到目的地地点Po为止的第2行人M2的位置在与第1行人M1的步行路径Rw相关联的状态下被步行路径取得部32取得。
除此之外,在步行路径取得部32中,在将第2行人M2的步行模式切换为图7~13分别所示的第1模式~第7模式的同时取得第1行人M1的步行路径Rw。在该情况下,如图7所示,第1模式是10个第2行人M2在其一部分与第1行人M1擦身而过的同时与x轴平行地朝向第1行人M1侧步行的模式,如图8所示,第2模式是5个第2行人M2在其一部分与第1行人M1擦身而过的同时与x轴平行地朝向第1行人M1侧步行的模式。
此外,如图9所示,第3模式是10个第2行人M2在其一部分与第1行人M1交叉的同时从第1行人M1的右侧朝向左侧步行的模式,如图10所示,第4模式是5个第2行人M2在其一部分与第1行人M1交叉的同时从第1行人M1的右侧朝向左侧步行的模式。另外,如图11所示,第5模式与第3模式相反,是10个第2行人M2在其一部分与第1行人M1交叉的同时从第1行人M1的左侧朝向右侧步行的模式,如图12所示,第6模式与第4模式相反,是5个第2行人M2在其一部分与第1行人M1交叉的同时从第1行人M1的左侧朝向右侧步行的模式。
除此之外,如图13所示,第7模式是10个第2行人M2中的5个第2行人M2从第1行人M1的右侧朝向左侧步行、剩余5个第2行人M2从第1行人M1的左侧朝向右侧步行、并且它们中的一部分在与第1行人M1交叉的同时步行的模式。
如以上那样,在步行路径取得部32中,第1行人M1的步行路径Rw在与第2行人M2的位置相关联的状态下被取得,它们的取得结果被输出到学习用数据取得部33。
在学习用数据取得部33中,在从步行路径取得部32被输入了步行路径Rw等的取得结果时,基于该取得结果,通过以下所述的方法,取得/生成学习用数据。首先,在gazebo模拟器等的模拟环境下,生成与上述的第2行人M2相当的虚拟第2行人M2’(参照图14)以及与机器人2相当的虚拟机器人(未图示)。
接着,使虚拟机器人以追随于上述的第1行人M1的步行路径Rw的方式移动,并且,使虚拟第2行人M2’追随于由步行路径取得部32取得的第2行人M2的位置而移动。
在该移动中,以规定周期对虚拟机器人的前方的视觉环境的图像进行取样,基于该取样结果,通过SSD(Single Shot MultiBox Detector:单发多框检测器)方法,逐次生成掩模图像。例如,如图14所示,在模拟环境下3个虚拟第2行人M2’位于虚拟机器人的前方的情况下,通过SSD方法取得3个虚拟第2行人M2’的位置,由此生成图15所示的掩模图像。
如该图所示,在该掩模图像中,3个虚拟第2行人M2’的位置被显示为3个矩形的框B。在该图中,3个框B的虚线所示的区域实际上显示为红色,除此以外的以点绘制出的区域实际上显示为黑色。
与此同时,在掩模图像的上端部,取样时的目的地地点Po被显示为矩形的白色框。该目的地地点Po将以虚拟机器人的当前时间点的自身位置为基准时的前方的中央位置作为0deg(度),被设定为-90deg~90deg的范围内的值。
此外,在该掩模图像的下端,取样时的虚拟机器人的虚拟x轴速度v_x’及虚拟y轴速度v_y’被显示为2个矩形的白色框。这些虚拟x轴速度v_x’及虚拟y轴速度v_y’分别是虚拟机器人的x轴方向及y轴方向的速度分量,被设定为虚拟机器人的最小移动速度v_min(例如值0)与最大移动速度v_max的范围内的值。该情况下的虚拟机器人的x轴方向及y轴方向与上述的图7等同样地被定义。
除此之外,在学习用数据取得部33中,取样时的虚拟机器人的移动方向指令被设定为以“左方向”、“中央方向”及“右方向”这3个方向为要素的向量值。在该移动方向指令的情况下,例如,在虚拟机器人直行时,“中央方向”被设定为值1,除此以外的“左方向”及“右方向”被设定为值0。
此外,在虚拟机器人朝右方向移动时,“右方向”被设定为值1,除此以外的方向被设定为值0。在该情况下,在虚拟机器人相对于直行方向以规定角度θ以上朝右移动时,“右方向”被设定为值1。另外,在虚拟机器人朝左方向移动时,“左方向”被设定为值1,除此以外的方向被设定为值0。在该情况下,在虚拟机器人相对于直进方向以规定角度θ以上朝左移动时,“左方向”被设定为值1。
接着,在学习用数据取得部33中,按照上述的规定周期逐次生成将上述的掩模图像(参照图15)与移动方向指令作为1组数据相关联起来而得到的数据来作为学习用数据。然后,最终在生成了多组(几千组以上)的学习用数据的时刻,将这些学习用数据向CNN学习部34输出。在该情况下,在学习用数据取得部33中也可以构成为,在每次按照规定周期生成学习用数据时将该学习用数据向CNN学习部34输出。另外,在本实施方式中,学习用数据相当于多个数据库。
在CNN学习部34中,在从学习用数据取得部33被输入了多组的学习用数据时,使用这些学习用数据执行CNN的模型参数的学习。具体而言,向CNN输入1组学习用数据中的掩模图像,针对此时的CNN的输出,使用移动方向指令作为教师数据。
在该情况下,CNN的输出层由3个单元构成,从CNN输出将来自这3个单元的3个softmax值作为要素的指令(以下称为“CNN输出指令”)。该CNN输出指令由将与移动方向指令相同的3个方向(“左方向”、“中央方向”及“右方向”)作为要素的指令构成。
接着,使用移动方向指令和CNN输出指令的损失函数(例如均方误差),通过梯度法来运算CNN的连接层的权重及偏置项。即,执行CNN的模型参数的学习运算。然后,通过将以上的学习运算执行与学习用数据的组数对应的量(即几千次的量)的次数,从而CNN学习部34中的CNN的模型参数的学习运算结束。在该学习装置30中,如以上那样执行CNN的模型参数的学习。
接着,参照图16,对本实施方式的路径决定装置1等的结构进行说明。路径决定装置1通过以下所述的方法,决定(计算)作为机器人2的路径的移动速度指令v,该移动速度指令v将作为机器人2的x轴速度v_x及y轴速度v_y的目标的目标x轴速度v_x_cmd及目标y轴速度v_y_cmd作为要素。
如该图所示,路径决定装置1具备掩模图像生成部50、移动方向决定部51、暂定移动速度决定部52及移动速度决定部53,具体而言,这些要素50~53由控制装置10构成。另外,按照规定的控制周期ΔT执行以下所述的各种控制处理。
首先,对掩模图像生成部50进行说明。在该掩模图像生成部50中,当被输入来自照相机11的图像信号及来自LIDAR12的计测信号时,通过上述的SSD方法生成掩模图像。
在该掩模图像内,以与上述的图15的掩模图像的框B同样的方式显示前方的交通参与者的框(未图示),代替虚拟x轴速度v_x’、虚拟y轴速度v_y’及目的地地点Po而显示机器人2的x轴速度v_x、y轴速度v_y及目的地Pobj(均未图示)。
在该情况下,基于照相机11的图像信号及LIDAR12的计测信号来确定交通参与者的位置及尺寸。此外,基于LIDAR12的计测信号及加速度传感器13的检测信号来确定机器人2的x轴速度v_x及y轴速度v_y。另外,通过来自服务器5的目的地信号来确定目的地Pobj。如以上那样生成的掩模图像从掩模图像生成部50被输出到移动方向决定部51。
移动方向决定部51具备由上述的CNN学习部34学习了模型参数而得到的CNN(未图示),使用该CNN,如以下那样决定机器人2的移动方向。
首先,当在移动方向决定部51中向CNN输入了来自掩模图像生成部50的掩模图像时,从CNN输出上述的CNN输出指令。接着,将CNN输出指令的3个要素(“左方向”、“中央方向”及“右方向”)中的最大值的要素的方向决定为机器人2的移动方向。然后,将如以上那样决定的机器人2的移动方向从移动方向决定部51向暂定移动速度决定部52输出。
在该暂定移动速度决定部52中,基于来自移动方向决定部51的机器人2的移动方向和机器人2的x轴速度v_x及y轴速度v_y,计算暂定移动速度指令v_cnn。该暂定移动速度指令v_cnn将机器人2的x轴速度的暂定值v_x_cnn及y轴速度的暂定值v_y_cnn作为要素。接着,将如以上那样决定的机器人2的暂定移动速度指令v_cnn从暂定移动速度决定部52向移动速度决定部53输出。
在该移动速度决定部53中,基于暂定移动速度指令v_cnn,通过应用了DWA(Dynamic Window Approach:动态窗口法)的算法来决定移动速度指令v。该移动速度指令v将目标x轴速度v_x_cmd及目标y轴速度v_y_cmd作为要素,这2个速度v_x_cmd、v_y_cmd在后述的移动控制处理中被用作机器人2的x轴速度及y轴速度的目标值。
具体而言,如下式(1)所示,定义目的函数G(v),以使该目的函数G(v)成为最大值的方式决定移动速度指令v。
G(v)=α·cnn(v)+β·dist(v)……(1)
上式(1)的α、β是规定的权重参数,基于机器人2的动态特性来决定。此外,上式(1)的cnn(v)是如下的函数值:将以Dynamic Window内的x轴速度和y轴速度为要素的速度指令与暂定移动速度指令v_cnn之间的偏差作为独立变量,该独立变量越小,则该cnn(v)越示出更大的值。
此外,上式(1)的dist(v)是设想机器人2以x轴速度的暂定值v_x_cnn及y轴速度的暂定值v_y_cnn移动时表示机器人2与最接近机器人2的交通参与者之间的距离的值,基于LIDAR12的计测信号来决定。
在本实施方式的路径决定装置1中,如以上那样决定以目标x轴速度v_x_cmd及目标y轴速度v_y_cmd为要素的移动速度指令v。另外,在本实施方式中,决定移动速度指令v相当于决定机器人的路径。
接着,参照图17对移动控制处理进行说明。该移动控制处理用于控制移动机构21的2个致动器24、25以使得机器人2以上述的2个目标速度v_x_cmd、v_y_cmd移动,通过控制装置10按照规定的控制周期ΔT执行该移动控制处理。
如该图所示,首先,读入各种数据(图17/步骤1)。该各种数据是从上述的照相机11、LIDAR12、加速度传感器13及无线通信装置14输入到控制装置10的信号的数据。
接着,判定是否已读入上述的目的地信号所包含的目的地Pobj(图17/步骤2)。当该判定为否定时(图17/步骤2…否),即当未从服务器5接收到目的地信号时,直接结束本处理。
另一方面,当该判定为肯定时(图17/步骤2…是),通过上述的图16的方法,计算目标x轴速度v_x_cmd及目标y轴速度v_y_cmdx(图17/步骤3)。
接着,根据目标x轴速度v_x_cmd及目标y轴速度v_y_cmdx,通过规定的控制算法来计算x轴控制输入Ux及y轴控制输入Uy(图17/步骤4)。在该情况下,作为规定的控制算法,使用地图检索等前馈控制算法、反馈控制算法即可。
接着,将与x轴控制输入Ux对应的控制输入信号向第1致动器24输出,并且,将与y轴控制输入Uy对应的控制输入信号向第2致动器25输出(图17/步骤5)。之后,结束本处理。由此,机器人2的实际的x轴速度v_x及y轴速度v_y被控制为目标x轴速度v_x_cmd及目标y轴速度v_y_cmd。其结果是,机器人2沿着由这些目标速度v_x_cmd、v_y_cmd决定的路径,在避开前方的交通参与者的同时朝向目的地Pobj移动。
如以上那样,根据本实施方式的路径决定装置1,使用学习用数据并通过梯度法来学习以掩模图像为输入且以移动方向指令为输出的CNN的模型参数(权重及偏置项),由此生成学习后CNN。然后,使用学习后CNN,决定机器人2的移动速度指令v。在该情况下,学习用数据作为将掩模图像与移动方向指令的关系相关联的数据而生成,该掩模图像是虚拟机器人在虚拟空间内沿着多个步行路径Rw分别进行了移动时包含表示虚拟机器人的前方的视觉环境的环境图像在内的图像,该移动方向指令表示该情况下虚拟机器人的移动方向。
此外,关于该多个步行路径Rw,取得了在第1行人M1在避免与多个第2行人发生干扰的同时朝向目的地点Po步行的情况下、将多个第2行人M2的步行模式设定为第1步行模式~第7步行模式时的第1行人M1的步行路径。因此,学习用数据是将虚拟的机器人沿着这样的步行路径Rw进行了移动时的掩模图像与表示机器人的移动方向的移动方向指令相关联后得到的数据,因此,能够在反映出第1行人M1的实际的步行路径的同时高精度地学习CNN的模型参数。其结果是,能够将机器人2的路径决定为,即便在人群拥挤等的交通环境下,自主移动型的机器人2也会在避免与交通参与者的干扰的同时顺利地移动至目的地。
此外,在掩模图像中,除了显示机器人2的前方的环境图像之外,还显示表示x轴速度v_x及y轴速度v_y的2个矩形的白色框和表示目的地点Po的矩形的白色框,因此,能够简化CNN的构造,能够减少决定机器人2的路径时的计算量。由此,能够迅速且高精度地决定机器人的路径。此外,由于学习用数据是通过使虚拟机器人在虚拟空间内沿着多个步行路径Rw分别移动而生成的,因此,无需实际准备机器人、交通参与者等,相应地能够容易地生成学习用数据。
另外,实施方式是作为自主移动型的机器人而使用了机器人2的例子,但本发明的机器人不限于此,只要是自主移动型的机器人即可。例如,也可以使用车辆型的机器人或双脚步行型的机器人。
此外,实施方式是将CNN用作行动模型的例子,但本发明的行动模型不限于此,只要将图像数据作为输入且将行动参数作为输出即可。例如,也可以将RNN(RecurrentNeural Network:递归神经网络)及DQN(deep Q-network:深度Q网络)等用作行动模型。
此外,实施方式是将梯度法用作规定的学习法的例子,但本发明的规定的学习法不限于此,只要是学习行动模型的模型参数的方法即可。
另一方面,实施方式是作为移动机构而使用了具备芯体22及多个滚轮23的移动机构21的例子,但移动机构不限于此,只要能够使机器人向全方位移动即可。例如,作为移动机构,也可以采用如下结构:组合球体与多个滚轮,通过这些滚轮,驱动球体进行旋转,由此,使机器人向全方位移动。
此外,实施方式是将CNN存储于机器人2的控制装置10的E2PROM内的例子,但也可以构成为,将CNN存储于服务器5侧,在服务器5侧实施路径决定的运算,并将运算结果发送到机器人2。
并且,实施方式是在移动速度决定部53中通过DWA方法计算出以x轴速度v_x及y轴速度v_y为要素的移动速度指令v来作为机器人2的移动速度的例子,但也可以取而代之,在移动速度决定部53中,通过DWA方法计算出x轴速度v_x及角速度ω来作为机器人2的移动速度。
另一方面,实施方式是在步行路径取得部32中作为第2行人M2的步行模式而使用了第1模式~第7模式的例子,但可以使用将第2行人M2的移动方向及数量变更为与此不同的移动方向及数量而得到的步行模式,以取得第1行人M1的步行路径Rw。例如,也可以使用多个第2行人M2与多个第2行人M2以相互斜交叉的方式步行的步行模式、多个第2行人M2沿着x轴线步行且多个第2行人M2沿着y轴线步行从而相互交叉的步行模式等。
标号说明
1:路径决定装置;
2:机器人;
32:步行路径取得部;
33:学习用数据取得部;
34::CNN学习部;
Pobj:目的地;
M1:第1行人;
Po:目的地地点;
M2:第2行人;
Rw:第1行人的步行路径;
v:移动速度指令(机器人的路径)。
- 流体供给系统、路径决定装置、路径决定程序及路径决定方法
- 路径决定装置、机器人及路径决定方法