一种服务的计算资源配置方法、系统及装置
文献发布时间:2023-06-19 12:13:22
技术领域
本发明涉及资源配置领域,特别是涉及一种服务的计算资源配置方法、系统及装置。
背景技术
Kubernetes简称“k8s”或者“kube”,是一个可移植的、可扩展的开源平台,用于管理容器化服务。k8s平台对服务提供了弹性扩容能力,能根据一定的弹性策略动态增加或减少服务的容器节点,从而动态地调整服务处理能力。
目前,对于新上线的平台各服务,k8s平台会按照预设计算资源标准配额为新上线的平台各服务配置计算资源初始值,但是,新上线的平台各服务的服务类型并不相同,其实际所需的计算资源量也有所差异,导致上述资源固定配置方式易存在计算资源配置不足或计算资源配置过多的问题,使得服务计算资源配置不够合理;而且,预设计算资源标准配额通常存储于系统内存中,在系统“冷启动”下内存所存储的内容会全部丢失,从而无法实现服务“冷启动”状态下的计算资源初始化配置。
因此,如何提供一种解决上述技术问题的方案是本领域的技术人员目前需要解决的问题。
发明内容
本发明的目的是提供一种服务的计算资源配置方法、系统及装置,请可根据在线学习算法为平台新上线服务推荐适配其服务类型的计算资源配额,使得服务计算资源配置更加合理化;而且,此计算资源配置方法不依赖于系统内存所存储的计算资源标准配额,能够实现服务“冷启动”状态下的资源初始化配置。
为解决上述技术问题,本发明提供了一种服务的计算资源配置方法,包括:
预先设置用于为平台各服务推荐与其服务类型相适配的计算资源配额的在线学习算法;
在平台上线新服务时,根据所述在线学习算法推荐出与所述新服务的服务类型相适配的目标计算资源配额;
按照所述目标计算资源配额进行所述新服务的计算资源初始化配置。
优选地,所述服务的计算资源配置方法还包括:
预先设置用于根据各服务对应的计算资源使用率、计算效率、计算请求量及计算请求延迟相应计算各服务的最优计算资源配额的配额最优算法;
在所述新服务投入工作后,利用所述配额最优算法,根据所述新服务实际对应的计算资源使用率、计算效率、计算请求量及计算请求延迟计算所述新服务的最优计算资源配额;
求取计算的最优计算资源配额与推荐的目标计算资源配额之间的配额误差,根据所述配额误差修改所述在线学习算法的推荐参数,以减少所述配额误差。
优选地,求取计算的最优计算资源配额与推荐的目标计算资源配额之间的配额误差,根据所述配额误差修改所述在线学习算法的推荐参数,以减少所述配额误差的过程,包括:
根据所述在线学习算法和所述配额最优算法得到用于求取所述新服务对应的配额误差的损失函数;
利用FTRL算法确定在得到的所有损失函数之和最小的条件下所述在线学习算法的目标推荐参数,并按照所述目标推荐参数修改所述在线学习算法的推荐参数。
优选地,所述配额最优算法为模糊逻辑算法或神经网络算法。
优选地,预先设置用于为平台各服务推荐与其服务类型相适配的计算资源配额的在线学习算法的过程,包括:
预先设置用于为平台各服务推荐与其服务类型相适配的计算资源配额的LinearUCB算法;
根据所述Linear UCB算法的运算速度要求调整所述Linear UCB算法中的计算精确度约束,以使所述Linear UCB算法的实际运算速度达到所述运算速度要求。
优选地,预先设置用于为平台各服务推荐与其服务类型相适配的计算资源配额的在线学习算法的过程,还包括:
按照
优选地,各服务的计算资源由CPU和GPU共同提供;
所述服务的计算资源配置方法还包括:
预先设置用于根据各服务对应的计算请求量、CPU剩余使用量、GPU剩余使用量相应确定各服务的服务副本数量的副本扩缩容算法;
在所述新服务投入工作后,利用所述副本扩缩容算法,根据所述新服务实际对应的计算请求量、CPU剩余使用量、GPU剩余使用量确定所述新服务的目标服务副本数量;
根据所述目标服务副本数量对所述新服务的服务副本进行扩缩容处理。
为解决上述技术问题,本发明还提供了一种服务的计算资源配置系统,包括:
预设模块,用于预先设置用于为平台各服务推荐与其服务类型相适配的计算资源配额的在线学习算法;
推荐模块,用于在平台上线新服务时,根据所述在线学习算法推荐出与所述新服务的服务类型相适配的目标计算资源配额;
配置模块,用于按照所述目标计算资源配额进行所述新服务的计算资源初始化配置。
优选地,所述预设模块具体用于:
预先设置用于为平台各服务推荐与其服务类型相适配的计算资源配额的LinearUCB算法;
根据所述Linear UCB算法的运算速度要求调整所述Linear UCB算法中的计算精确度约束,以使所述Linear UCB算法的实际运算速度达到所述运算速度要求;
所述预设模块还用于:
按照
为解决上述技术问题,本发明还提供了一种服务的计算资源配置装置,包括:
存储器,用于存储计算机程序;
处理器,用于在执行所述计算机程序时实现上述任一种服务的计算资源配置方法的步骤。
本发明提供了一种服务的计算资源配置方法,预先设置用于为平台各服务推荐与其服务类型相适配的计算资源配额的在线学习算法;在平台上线新服务时,根据在线学习算法推荐出与新服务的服务类型相适配的目标计算资源配额;按照目标计算资源配额进行新服务的计算资源初始化配置。可见,本申请可根据在线学习算法为平台新上线服务推荐适配其服务类型的计算资源配额,使得服务计算资源配置更加合理化;而且,此计算资源配置方法不依赖于系统内存所存储的计算资源标准配额,能够实现服务“冷启动”状态下的资源初始化配置。
本发明还提供了一种服务的计算资源配置系统及装置,与上述配置方法具有相同的有益效果。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对现有技术和实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
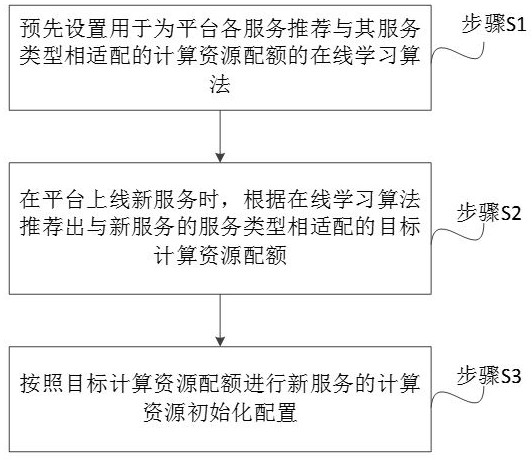
图1为本发明实施例提供的一种服务的计算资源配置方法的流程图;
图2为本发明实施例提供的一种服务的计算资源配置系统的结构示意图。
具体实施方式
本发明的核心是提供一种服务的计算资源配置方法、系统及装置,请可根据在线学习算法为平台新上线服务推荐适配其服务类型的计算资源配额,使得服务计算资源配置更加合理化;而且,此计算资源配置方法不依赖于系统内存所存储的计算资源标准配额,能够实现服务“冷启动”状态下的资源初始化配置。
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参照图1,图1为本发明实施例提供的一种服务的计算资源配置方法的流程图。
该服务的计算资源配置方法包括:
步骤S1:预先设置用于为平台各服务推荐与其服务类型相适配的计算资源配额的在线学习算法。
具体地,本申请提前为平台各服务设置一个在线学习算法,此在线学习算法用于为平台各服务推荐与其服务类型相适配的计算资源配额,即在线学习算法的输入为:平台服务,在线学习算法的输出为:与输入的平台服务的服务类型相适配的计算资源配额。
需要说明的是,在线学习算法在应用之前,需通过一些样本(平台各历史服务及与各历史服务相适配的计算资源配额组成样本)对在线学习算法中的推荐参数进行训练,以使在线学习算法能够为平台各服务推荐与其服务类型较为适配的计算资源配额。
更具体地,对在线学习算法中的推荐参数进行训练的过程具体为:将平台历史服务作为在线学习算法的输入,得到在线学习算法的输出:与输入的平台历史服务的服务类型相适配的计算资源推荐配额;求取在线学习算法输出的计算资源推荐配额和样本中给出的与输入的平台历史服务的服务类型相适配的计算资源配额之间的配额误差;根据配额误差修改在线学习算法的推荐参数,以减少配额误差,使在线学习算法推荐的计算资源配额更加准确。
步骤S2:在平台上线新服务时,根据在线学习算法推荐出与新服务的服务类型相适配的目标计算资源配额。
具体地,在平台上线新服务时,本申请可根据在线学习算法推荐出与新服务的服务类型相适配的计算资源配额(称为目标计算资源配额),以为新服务的计算资源初始化配置提供依据。
步骤S3:按照目标计算资源配额进行新服务的计算资源初始化配置。
具体地,本申请在根据在线学习算法推荐出与新服务的服务类型相适配的目标计算资源配额之后,按照推荐的目标计算资源配额进行新服务的计算资源初始化配置即可,使得服务计算资源配置更加合理化。
本发明提供了一种服务的计算资源配置方法,预先设置用于为平台各服务推荐与其服务类型相适配的计算资源配额的在线学习算法;在平台上线新服务时,根据在线学习算法推荐出与新服务的服务类型相适配的目标计算资源配额;按照目标计算资源配额进行新服务的计算资源初始化配置。可见,本申请可根据在线学习算法为平台新上线服务推荐适配其服务类型的计算资源配额,使得服务计算资源配置更加合理化;而且,此计算资源配置方法不依赖于系统内存所存储的计算资源标准配额,能够实现服务“冷启动”状态下的资源初始化配置。
在上述实施例的基础上:
作为一种可选的实施例,服务的计算资源配置方法还包括:
预先设置用于根据各服务对应的计算资源使用率、计算效率、计算请求量及计算请求延迟相应计算各服务的最优计算资源配额的配额最优算法;
在新服务投入工作后,利用配额最优算法,根据新服务实际对应的计算资源使用率、计算效率、计算请求量及计算请求延迟计算新服务的最优计算资源配额;
求取计算的最优计算资源配额与推荐的目标计算资源配额之间的配额误差,根据配额误差修改在线学习算法的推荐参数,以减少配额误差。
进一步地,本申请不仅在在线学习算法应用之前,通过一些样本对在线学习算法中的推荐参数进行训练,还在在线学习算法应用于平台服务计算资源配额推荐之后,对在线学习算法中的推荐参数进行在线训练:
本申请提前设置一个计算各服务的最优计算资源配额的配额最优算法,考虑到任一服务对应的计算资源配额与此服务对应的计算资源使用率、计算效率、计算请求量及计算请求延迟有一定关系,所以本申请设置的配额最优算法具体用于根据各服务对应的计算资源使用率、计算效率、计算请求量及计算请求延迟相应计算各服务的最优计算资源配额。
在平台上线的新服务投入工作后,本申请利用提前设置的配额最优算法,根据新服务实际对应的计算资源使用率、计算效率、计算请求量及计算请求延迟,计算新服务的最优计算资源配额。可以理解的是,在线学习算法的推荐优化目标是:在线学习算法为新服务推荐的目标计算资源配额尽可能接近配额最优算法计算的新服务的最优计算资源配额。
基于此,本申请求取配额最优算法计算的新服务的最优计算资源配额与在线学习算法为新服务推荐的目标计算资源配额之间的配额误差,然后根据配额误差修改在线学习算法的推荐参数,以减少配额误差,使在线学习算法推荐的计算资源配额更加准确。
作为一种可选的实施例,求取计算的最优计算资源配额与推荐的目标计算资源配额之间的配额误差,根据配额误差修改在线学习算法的推荐参数,以减少配额误差的过程,包括:
根据在线学习算法和配额最优算法得到用于求取新服务对应的配额误差的损失函数;
利用FTRL算法确定在得到的所有损失函数之和最小的条件下在线学习算法的目标推荐参数,并按照目标推荐参数修改在线学习算法的推荐参数。
具体地,在线学习算法用于为平台各服务推荐与其服务类型相适配的计算资源配额,即在线学习算法的输出为:为平台服务推荐的计算资源配额;配额最优算法用于计算各服务的最优计算资源配额,即配额最优算法的输出为:为平台服务计算的最优计算资源配额。可以理解的是,对于任一平台服务来说,此平台服务对应的配额最优算法减去此平台服务对应的在线学习算法,得到就是求取此平台服务对应的配额误差的损失函数。
基于此,平台每上线一个新服务,就可以得到求取此新服务对应的配额误差的损失函数,而调整在线学习算法的推荐参数的依据是:获取在得到的所有损失函数之和最小的条件下在线学习算法的推荐参数(称为目标推荐参数),按照获取的目标推荐参数修改在线学习算法的推荐参数。
更具体地,考虑到FTRL(Follow The Regularized Leader,跟随正规化的领导)算法在处理诸如逻辑回归之类的带非光滑正则化项的凸优化问题上具有出色的性能,所以本申请利用FTRL算法确定在得到的所有损失函数之和最小的条件下在线学习算法的目标推荐参数,效果较好。
作为一种可选的实施例,配额最优算法为模糊逻辑算法或神经网络算法。
具体地,本申请的配额最优算法可选用模糊逻辑算法,也可选用神经网络算法,本申请在此不做特别的限定。需要说明的是,模糊逻辑算法或神经网络算法需要根据计算目的(根据任一服务对应的计算资源使用率、计算效率、计算请求量及计算请求延迟计算此服务的最优计算资源配额)提前训练设置好,以便后续利用模糊逻辑算法或神经网络算法实现:根据各服务对应的计算资源使用率、计算效率、计算请求量及计算请求延迟相应计算各服务的最优计算资源配额。
作为一种可选的实施例,预先设置用于为平台各服务推荐与其服务类型相适配的计算资源配额的在线学习算法的过程,包括:
预先设置用于为平台各服务推荐与其服务类型相适配的计算资源配额的LinearUCB算法;
根据Linear UCB算法的运算速度要求调整Linear UCB算法中的计算精确度约束,以使Linear UCB算法的实际运算速度达到运算速度要求。
具体地,本申请具体利用Linear UCB(Upper Confidence Bound,置信区间上界)算法为平台各服务推荐与其服务类型相适配的计算资源配额。Linear UCB算法是在UCB算法的前提下,考虑回报和特征的线性关系,并选择置信区间上界最大的项目推荐,观察回报后更新线性关系的参数,以此达到在线学习的目的。
此外,考虑到Linear UCB算法中有较多矩阵求逆的逆运算,而矩阵求逆的时间复杂度为原矩阵维数的三次方,导致矩阵求逆的逆运算的时间开销较大,从而导致LinearUCB算法的运算速度较慢;与此同时,考虑到Linear UCB算法中的计算精确度约束越低,Linear UCB算法的运算速度越快,所以本申请在有Linear UCB算法的运算速度要求的情况下,可以适当调整Linear UCB算法中的计算精确度约束,以使Linear UCB算法的实际运算速度达到运算速度要求。
作为一种可选的实施例,预先设置用于为平台各服务推荐与其服务类型相适配的计算资源配额的在线学习算法的过程,还包括:
按照
进一步地,考虑到Linear UCB算法中的计算精确度约束降低,虽然加快了LinearUCB算法的运算速度,但使得Linear UCB算法的推荐不够准确,所以本申请提供了一种提高Linear UCB算法的推荐准确度但不影响计算速度的方法:将Linear UCB算法中的逆矩阵
作为一种可选的实施例,各服务的计算资源由CPU和GPU共同提供;
服务的计算资源配置方法还包括:
预先设置用于根据各服务对应的计算请求量、CPU剩余使用量、GPU剩余使用量相应确定各服务的服务副本数量的副本扩缩容算法;
在新服务投入工作后,利用副本扩缩容算法,根据新服务实际对应的计算请求量、CPU剩余使用量、GPU剩余使用量确定新服务的目标服务副本数量;
根据目标服务副本数量对新服务的服务副本进行扩缩容处理。
进一步地,本申请的平台服务的计算资源由CPU(Central Processing Unit,中央处理器)和GPU(Graphics Processing Unit,图形处理器)共同提供。
平台服务的服务副本数量与计算请求量有一定关系,具体是:1个服务副本可承受的计算请求量是一定的,则当平台服务的计算请求量增多至其服务副本不足以承受时,需增加服务副本数量来承受增多的计算请求量。平台服务的服务副本数量与平台服务对应的CPU剩余使用量有一定关系,具体是:当平台服务对应的CPU剩余使用量不足时,平台服务会申请新的CPU,此时平台服务对应的CPU剩余使用量充足,可增加平台服务的服务副本数量,如一个CPU有12个核,一个核可供一个服务副本使用,则新申请一个CPU最多可增加12个服务副本。平台服务的服务副本数量与平台服务对应的GPU剩余使用量有一定关系,具体是:当平台服务对应的GPU剩余使用量不足时,平台服务会申请新的GPU卡,此时平台服务对应的GPU剩余使用量充足,可增加平台服务的服务副本数量,如一个GPU卡可供一个服务副本使用,则新申请一个CPU可增加1个服务副本。
基于此,本申请提前设置一个确定各服务的服务副本数量的副本扩缩容算法,此副本扩缩容算法具体用于根据各服务对应的计算请求量、CPU剩余使用量、GPU剩余使用量相应确定各服务的服务副本数量的副本扩缩容算法。在平台上线的新服务投入工作后,利用副本扩缩容算法,根据新服务实际对应的计算请求量、CPU剩余使用量、GPU剩余使用量确定新服务的服务副本数量(称为目标服务副本数量),然后根据目标服务副本数量对新服务的服务副本进行扩缩容处理即可。
请参照图2,图2为本发明实施例提供的一种服务的计算资源配置系统的结构示意图。
该服务的计算资源配置系统包括:
预设模块1,用于预先设置用于为平台各服务推荐与其服务类型相适配的计算资源配额的在线学习算法;
推荐模块2,用于在平台上线新服务时,根据在线学习算法推荐出与新服务的服务类型相适配的目标计算资源配额;
配置模块3,用于按照目标计算资源配额进行新服务的计算资源初始化配置。
作为一种可选的实施例,服务的计算资源配置系统还包括:
最优算法模块,用于预先设置用于根据各服务对应的计算资源使用率、计算效率、计算请求量及计算请求延迟相应计算各服务的最优计算资源配额的配额最优算法;
最优计算模块,用于在新服务投入工作后,利用配额最优算法,根据新服务实际对应的计算资源使用率、计算效率、计算请求量及计算请求延迟计算新服务的最优计算资源配额;
参数修改模块,用于求取计算的最优计算资源配额与推荐的目标计算资源配额之间的配额误差,根据配额误差修改在线学习算法的推荐参数,以减少配额误差。
作为一种可选的实施例,所述参数修改模块具体用于:
根据在线学习算法和配额最优算法得到用于求取新服务对应的配额误差的损失函数;
利用FTRL算法确定在得到的所有损失函数之和最小的条件下在线学习算法的目标推荐参数,并按照目标推荐参数修改在线学习算法的推荐参数。
作为一种可选的实施例,预设模块1具体用于:
预先设置用于为平台各服务推荐与其服务类型相适配的计算资源配额的LinearUCB算法;
根据Linear UCB算法的运算速度要求调整Linear UCB算法中的计算精确度约束,以使Linear UCB算法的实际运算速度达到运算速度要求。
作为一种可选的实施例,预设模块1还用于:
按照
作为一种可选的实施例,各服务的计算资源由CPU和GPU共同提供;
服务的计算资源配置系统还包括:
副本算法模块,用于预先设置用于根据各服务对应的计算请求量、CPU剩余使用量、GPU剩余使用量相应确定各服务的服务副本数量的副本扩缩容算法;
副本计算模块,用于在新服务投入工作后,利用副本扩缩容算法,根据新服务实际对应的计算请求量、CPU剩余使用量、GPU剩余使用量确定新服务的目标服务副本数量;
副本扩缩容模块,用于根据目标服务副本数量对新服务的服务副本进行扩缩容处理。
本申请提供的配置系统的介绍请参考上述配置方法的实施例,本申请在此不再赘述。
本申请还提供了一种服务的计算资源配置装置,包括:
存储器,用于存储计算机程序;
处理器,用于在执行计算机程序时实现上述任一种服务的计算资源配置方法的步骤。
本申请提供的配置装置的介绍请参考上述配置方法的实施例,本申请在此不再赘述。
还需要说明的是,在本说明书中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其他实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 一种服务的计算资源配置方法、系统及装置
- 配电系统云数据中心计算资源优化配置方法、装置、设备及介质