一种基于图注意力的半结构文本分类方案
文献发布时间:2023-06-19 12:22:51
技术领域
本发明涉及文本分类技术领域,具体涉及一种基于图注意力的半结构文本分类方案。
背景技术
在自然语言处理中,文本的分类是一个比较成熟也比较常见的文本处理任务。常见的有文本的标签分类,情感分类等任务,在训练样本充分的情况下,当前的这些任务都能取得比较好的效果,在一些私有领域(如金融领域),存在一类比较特殊的文本数据信息,它主要由大量的数字构成,并且根据一定的排列顺序来区分不同的数据类型,如图1、图2所示,图1是二级现券成交信息,图2是一级投标信息,判断它们不仅需要依赖文字信息,还需要考虑它们的结构信息,在各种文本处理的任务中,需要对这类数据进行分类。专业人员根据文字信息,以及它们的排列结构信息来判断一段文本的类别。因此如何构建既考虑文本信息,又考虑文本排列的结构信息,这对现有的分类算法来说,是一个难点问题。
关于文本分类的任务,有一系列的算法模型,如Fasttext,textcnn和textrnn等,以及随着预训练模型的发展,衍生的一系列基于bert的分类模型,融合attention机制的textcnn+attention,textrnn+attention等等,这些模型能够比较好地解决通用域的一些文本分类问题,针对金融领域的文本语料,很大一部分是如上描述的半结构文本数据,当前的处理技术主要有两种,一是基于“关键词+规则引擎”的技术,根据关键词判别或其余的说辞方式区分所属的不同业务。二是采用以上提到的NLP领域常见的文本分类算法模型,如Bert+的分类模型,需要考虑计算性能的则采用FastText、TextCNN等模型,针对带有结构信息,或者需要依赖结构信息来进行判断的分类任务;两种方法都有一定的局限性,首先基于关键词+规则引擎的方案,需要行业专家提供经验并整合起来,一般在比较理想化的语料中会处理得比较好,在应对实际线上业务数据就会捉襟见肘,要么是规则冲突要么是考虑不周,而且规则堆积之后维护成本极高,且运行效率也会越来越低;其次,基于深度学习的文本分类算法,目前的方案都没有将“结构信息”融合进模型的学习中,虽然基于Bert+的一些预训练模型,能够学习到字符的位置信息,但是仍然不能有效的学习到结构特征,在区分闲聊等语料和业务语料(一级投标、二级现券成交等)数据的时候效果很不错,但是针对相似度比较高的半结构化文本(一级投标和二级现券成交等)的分类时,效果会明显下降很多。
现有方案均没有很好得利用数据内部的结构化信息,因此,若可以将此部分的信息融入到判断方案里头,理应会得到不错的提升。
发明内容
本发明的目的在于针对现有技术的缺陷和不足,提供一种基于图注意力的半结构文本分类方案,以解决上述背景技术中提出的问题,本发明针对金融领域文本分类问题,尤其是在半结构化的文本的情况下,寻常的分类器无法结合结构化信息进行识别,给出一种提取结构信息并且融入到分类系统中,对最终的分类器准确率提升是行之有效的,同时针对模型结构,尤其是取末尾几层transformer、跨句间结构权重比同句内更高、multi-headattention等步骤,大大提高了信息表征抽取的能力,从而增加最后softmax分类的准确率,具有较大的市场推广价值。
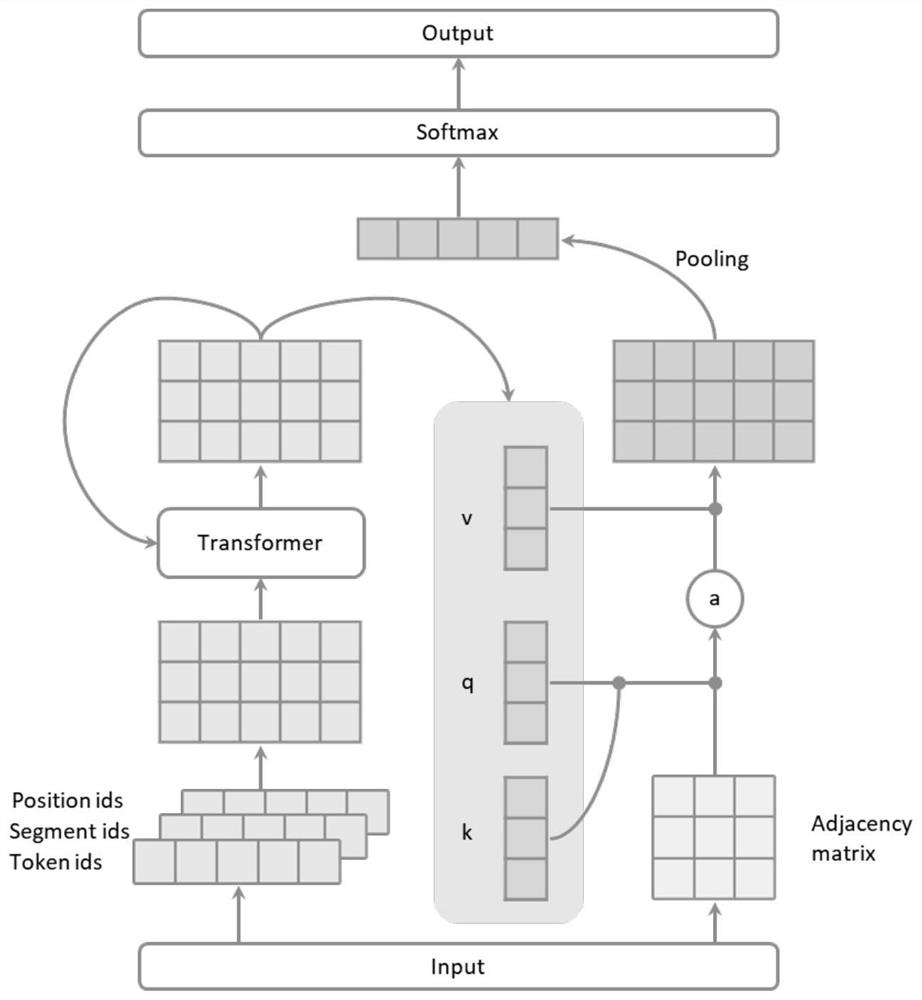
为实现上述目的,本发明包含以下技术方案步骤:步骤一,文本预处理、数据清洗,形成图矩阵M;步骤二,形成编码层,采用albert预训练模型获取embedding矩阵;步骤三,对embedding矩阵进行attention操作,并基于图矩阵进行加权计算;步骤四,对特征向量矩阵压缩后进行文本分类。
所述的步骤一文本通常含有大量的噪音数据,首先对文本进行预处理清洗,如全半角转换、英文大小写统一、多个空白字符合并、去停用词等,文本切割,根据文本换行符,以及空格键、逗号分号、Tab键等分割符的判断,将文本数据切割成多个词或短句的形式,判断短句、词在文本中的位置,所处的行、列的位置信息,判断它们的连接关系,采用简单逻辑规则,在水平方向上,一个词与左右的词直接关联,在垂直方向上,如果水平方向处于同一位置,则关联,如此形成如下图4所示的图矩阵M,图矩阵的表达上,本方案采用不同的值表达不同的关联,单行内相邻字符之间的关联用数值1标识,要素之间的关联用2标识,其余未标出的区域均默认设置为0。
所述的步骤二将文本通过事先在专业语料训练过的预训练模型(此处我们以albert为例进行阐述,也可用其他的预训练模型如bert、xlnet、roberta等替代),记每个字符对应倒数第i层transformer的输出向量为
所述的步骤三类似于self-attention,embedding矩阵中对应每个字符的向量
对查询向量和键向量计算内积并缩放得到权重λ
随后初始的权重矩阵与图矩阵M相乘得加权后的权重矩阵
针对以上的操作也可以跟transformer一样,进行multi-head化和norm的操作再输出。
所述的步骤四拿到特征向量矩阵后,通过max或者mean等pooling层,将矩阵降维压缩成向量;再接入全连接层,最后进入softmax层输出分类结果,训练上,在lossfunction中采取增加惩罚项的方式,防止loss因为模长增大而降低,训练的时候根据业务需求,主要采用recall指标作为metric的方式。
本发明的工作原理:首先通过预处理,对输入的文本进行数据清洗,拆分文本的内部结构,根据要素之间的联系提取关系图矩阵,并且根据关系的不同分配权重得到邻接矩阵M,其次是采用成熟的预训练模型albert,对文本进行embeddding获得文本的向量矩阵E,在此基础上我们加入了一个attention层,对每个字向量
采用上述技术方案后,本发明有益效果为:针对金融领域文本分类问题,尤其是在半结构化的文本的情况下,寻常的分类器无法结合结构化信息进行识别,给出一种提取结构信息并且融入到分类系统中,对最终的分类器准确率提升是行之有效的,同时针对模型结构,尤其是取末尾几层transformer、跨句间结构权重比同句内更高、multi-headattention等步骤,大大提高了信息表征抽取的能力,从而增加最后softmax分类的准确率,具有较大的市场推广价值。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1是传统金融领域二级现券成交信息局部示意图;
图2是传统金融领域一级投标信息局部示意图;
图3是本发明的技术流程结构示意图;
图4是本发明的图矩阵M结构示意图;
具体实施方式
参看图1~图4所示,本具体实施方式包含以下技术方案步骤:步骤一,文本预处理、数据清洗,形成图矩阵M;步骤二,形成编码层,采用albert预训练模型获取embedding矩阵;步骤三,对embedding矩阵进行attention操作,并基于图矩阵进行加权计算;步骤四,对特征向量矩阵压缩后进行文本分类。
进一步的,所述的步骤一文本通常含有大量的噪音数据,首先对文本进行预处理清洗,如全半角转换、英文大小写统一、多个空白字符合并、去停用词等,文本切割,根据文本换行符,以及空格键、逗号分号、Tab键等分割符的判断,将文本数据切割成多个词或短句的形式,判断短句、词在文本中的位置,所处的行、列的位置信息,判断它们的连接关系,采用简单逻辑规则,在水平方向上,一个词与左右的词直接关联,在垂直方向上,如果水平方向处于同一位置,则关联,如此形成如下图4所示的图矩阵M,图矩阵的表达上,本方案采用不同的值表达不同的关联,单行内相邻字符之间的关联用数值1标识,要素之间的关联用2标识,其余未标出的区域均默认设置为0。
进一步的,所述的步骤二将文本通过事先在专业语料训练过的预训练模型(此处我们以albert为例进行阐述,也可用其他的预训练模型如bert、xlnet、roberta等替代),记每个字符对应倒数第i层transformer的输出向量为
进一步的,所述的步骤三类似于self-attention,embedding矩阵中对应每个字符的向量
对查询向量和键向量计算内积并缩放得到权重λ
随后初始的权重矩阵与图矩阵M相乘得加权后的权重矩阵
针对以上的操作也可以跟transformer一样,进行multi-head化和norm的操作再输出。
进一步的,所述的步骤四拿到特征向量矩阵后,通过max或者mean等pooling层,将矩阵降维压缩成向量;再接入全连接层,最后进入softmax层输出分类结果,训练上,在lossfunction中采取增加惩罚项的方式,防止loss因为模长增大而降低,训练的时候根据业务需求,主要采用recall指标作为metric的方式。
进一步的,本发明主要针对金融领域文本数据的分类问题,尤其是在处理半结构化文本的时候效果更佳,方案中获取embedding矩阵涉及到的预训练模型,可采用已有的语言模型、预训练模型或者是将来出现的相关技术替换。
本发明的工作原理:首先通过预处理,对输入的文本进行数据清洗,拆分文本的内部结构,根据要素之间的联系提取关系图矩阵,并且根据关系的不同分配权重得到邻接矩阵M,其次是采用成熟的预训练模型albert,对文本进行embeddding获得文本的向量矩阵E,在此基础上我们加入了一个attention层,对每个字向量
采用上述技术方案后,本发明有益效果为:针对金融领域文本分类问题,尤其是在半结构化的文本的情况下,寻常的分类器无法结合结构化信息进行识别,给出一种提取结构信息并且融入到分类系统中,对最终的分类器准确率提升是行之有效的,同时针对模型结构,尤其是取末尾几层transformer、跨句间结构权重比同句内更高、multi-headattention等步骤,大大提高了信息表征抽取的能力,从而增加最后softmax分类的准确率,具有较大的市场推广价值。
以上所述,仅用以说明本发明的技术方案而非限制,本领域普通技术人员对本发明的技术方案所做的其它修改或者等同替换,只要不脱离本发明技术方案的精神和范围,均应涵盖在本发明的权利要求范围当中。
- 一种基于图注意力的半结构文本分类方案
- 一种基于图注意力网络的中文短文本分类方法