一种基于协同过滤推荐算法用于案例推荐的方法与系统
文献发布时间:2023-06-19 12:22:51
技术领域
本发明涉及信息推荐领域,具体来说,涉及一种基于协同过滤推荐算法用于案例推荐的方法与系统。
背景技术
随着普法工作深入开展和民众法制意识的增强,遇到各种纠纷,更多的人选择运用法律武器去维护自己的合法权益。因此,法院受理的案件也越多,由于审理案件的数量日益增多,各法律相关检索网站提供了对公开的裁判文书的检索查询服务,同时,最高人民法院也在不断的发布各裁判文书中的各类典型案例作为指导性案例。但其仍需工作人员进行大量详细的阅读,才有可能得出类似的判案参考,需要耗费大量时间。而采用基于关键词的匹配技术来实现公益诉讼案例的推荐,其效果达不到要求,无法起到辅助案件审理的作用。
其中,所谓典型案例泛指法律界具有较强典型意义及较大社会影响的法律纠纷案例。发布的典型案例往往案情复杂,判案情况富有逻辑性,往往需要进行大量详细的阅读,才有可能得出类似的判案参考,即使是法律专业人士也需要大量时间,而对于非法律专业人士要想找到自己需要的典型案例则需要耗费更多的时间。所以民众在进行维权时,由于专业性的限制,如何去打官司,以自己的情况是否可以获得法律的支持成为普罗大众的痛点。
针对相关技术中的问题,目前尚未提出有效的解决方案。
发明内容
针对相关技术中的问题,本发明提出一种基于协同过滤推荐算法用于案例推荐的方法与系统,以克服现有相关技术所存在的上述技术问题。
为此,本发明采用的具体技术方案如下:
根据本发明的一个方面,提供一种基于协同过滤推荐算法用于案例推荐的方法,该方法包括以下步骤:
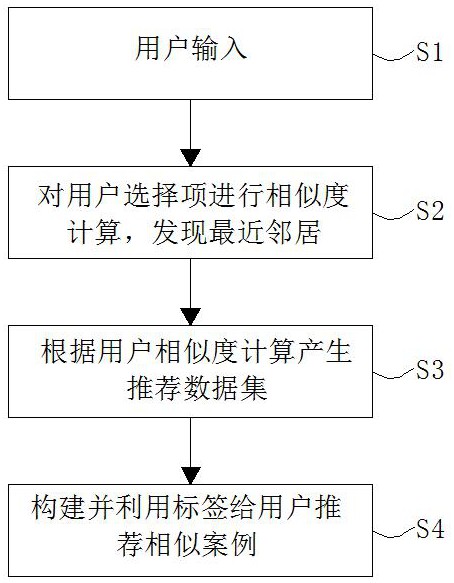
S1、用户输入;
S2、对用户选择项进行相似度计算,发现最近邻居;
S3、根据用户相似度计算产生推荐数据集;
S4、构建并利用标签给用户推荐相似案例。
进一步的,所述用户输入为当前用户选择案由,并对该案由内相关问题进行选择并输入。
进一步的,其特征在于,所述对用户选择项进行相似度计算,发现最近邻居包括以下步骤:
S21、若当前用户选择案由不同时,采用以下公式计算:
S22、若选择案由相同时,采用以下公式计算:
其中,sim(u
S23、根据上述公式判断最近邻居,并选取相似度最近的五个邻居。
进一步的,所述产生推荐数据集包括以下步骤:
S31、计算某个案例组中案例对当前用户输入的推荐值,采用以下公式计算:
其中,p表示推荐值,
S32、选取p值最大的五个案例推荐给当前用户,同时后台分析案例结果,进行综合司法风险评估。
进一步的,所述构建并利用标签给用户推荐相似案例包括以下步骤:
S41、用户对案例进行评价与增加标签;
S42、利用推荐算法,计算用户对案例的兴趣程度,计算公式为:
其中,用户输入标签行为(u,i,b)代表用户u对i案例打上b标签,n
S43、利用领域的方法将标签扩展至其他案件。
进一步的,所述利用领域的方法为通过数据统计出标签之间的相似度,利用以下余弦相似度公式进行计算:
其中,b与b′均表示标签,N(b)为有标签b的案例的集合,n
根据本发明的另一个方面,还提供了一种基于协同过滤推荐算法用于案例推荐的系统,该系统包括以下模块组成:
用户输入模块,用于收集当前用户的输入集;
相似度计算模块,用于计算与当前用户输入最相近的用户输入;
推荐值计算模块,用于计算案例推荐值并选取最大的案例给当前用户;
标签评价与计算模块,用于构建并利用标签给用户推荐相似案例。
进一步的,所述相似度计算模块,用于计算与当前用户输入最相近的用户输入包括以下步骤:
若当前用户选择案由不同时,采用以下公式计算:
若选择案由相同时,采用以下公式计算:
其中,sim(u
根据上述公式判断最近邻居,并选取相似度最近的五个邻居。
进一步的,所述推荐值计算模块,用于选取推荐值最大的案例给当前用户包括以下步骤:
计算某个案例组中案例对当前用户输入的推荐值,采用以下公式计算:
其中,
选取p值最大的五个案例推荐给当前用户。
进一步的,所述标签评价与计算模块4,用于构建与利用标签给用户推荐相似案例包括以下步骤:
用户对案例进行评价与增加标签;
利用推荐算法,计算用户对案例的兴趣程度,计算公式为:
其中,用户输入标签行为(u,i,b)代表用户u对i案例打上b标签,n
利用领域的方法将标签扩展至其他案件。
本发明的有益效果为:通过运用协同过滤算法及对其进行改进,能够提高推荐案例的准确性,在用户选择输入项后,会根据系统推荐的案例选择不相关、基本相关、非常相关,从而能够有效地提高用户对案例的理解程度,降低民众维权的专业性限制。同时本方法通过改进现有推荐算法能够根据用户的选择项直接判断是否为相似输入,甚至找到相同输入,从而减少现有算法中的数据矩阵构建,提高效率与推荐的准确率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是根据本发明实施例的一种基于协同过滤推荐算法用于案例推荐的方法的流程图;
图2是根据本发明实施例的一种基于协同过滤推荐算法用于案例推荐的方法中用户根据选项进行案例推送的流程图;
图3是根据本发明实施例的一种基于协同过滤推荐算法用于案例推荐的方法中评估矩阵示意图;
图4是根据本发明实施例的一种基于协同过滤推荐算法用于案例推荐的方法中用户输入“非常相关”案例的统计数据图;
图5是根据本发明实施例的一种基于协同过滤推荐算法用于案例推荐的系统的系统框图。
图中:
1、用户输入模块;2、相似度计算模块;3、推荐值计算模块;4、标签评价与计算模块。
具体实施方式
为进一步说明各实施例,本发明提供有附图,这些附图为本发明揭露内容的一部分,其主要用以说明实施例,并可配合说明书的相关描述来解释实施例的运作原理,配合参考这些内容,本领域普通技术人员应能理解其他可能的实施方式以及本发明的优点,图中的组件并未按比例绘制,而类似的组件符号通常用来表示类似的组件。
根据本发明的实施例,提供了一种基于协同过滤推荐算法用于案例推荐的方法与系统。
现结合附图和具体实施方式对本发明进一步说明,如图1-4所示,根据本发明实施例的基于协同过滤推荐算法用于案例推荐的方法,该方法包括以下步骤:
S1、用户输入;
S2、对用户选择项进行相似度计算,发现最近邻居;
S3、根据用户相似度计算产生推荐数据集;
S4、构建并利用标签给用户推荐相似案例。
在一个实施例中,所述用户输入为当前用户选择案由,并对该案由内相关问题进行选择并输入。
此外,在案例推荐场景中用户输入集为用户在风险评估上选择问题的组合,例如存在有64种案由,每种案由30个问题左右的输入,其中为20个左右的单选题和10个左右的多选题所以用户输入约为
在一个实施例中,所述对用户选择项进行相似度计算,发现最近邻居包括以下步骤:
S21、若当前用户选择案由不同时,采用以下公式计算:
S22、若选择案由相同时,采用以下公式计算:
其中,sim(u
S23、根据上述公式判断最近邻居,并选取相似度最近的五个邻居。
此外,在现有的协同过滤算法中,发现最近邻居就是找到与当前用户输入最相近的用户输入。而在此之前需要先进行数据表述,即构建一个m*n的“用户输入-案例”的评估矩阵,m代表用户输入,n代表案例,r
在一个实施例中,所述产生推荐数据集包括以下步骤:
S31、计算某个案例组中案例对当前用户输入的推荐值,采用以下公式计算:
其中,p表示推荐值,
S32、选取p值最大的五个案例推荐给当前用户,同时后台分析案例结果,进行综合司法风险评估。
在一个实施例中,所述构建并利用标签给用户推荐相似案例包括以下步骤:
S41、用户对案例进行评价与增加标签;
S42、利用推荐算法,计算用户对案例的兴趣程度,计算公式为:
其中,用户输入标签行为(u,i,b)代表用户u对i案例打上b标签,n
S43、利用领域的方法将标签扩展至其他案件。
此外,在案例库中存在700w余件案件,用户一次使用情况最多浏览到5-10件案件,所以存在数据稀疏的问题。所以给案例增加标签,允许用户在评价案件之外,对案件打标签。例如:“有用”,“离婚相关”,“判决不合理”等标签,之后便可利用这些标签去给用户推荐相似案件。
其中,稀疏性的问题也就是系统运行初期或者案例库新增的案件,很多案件标签不足。标签扩展本质上是对每个标签找到与它相似的标签,找到相似标签后将这个标签扩展到原案件中去,在本方法中,用户的标签为用户自己定义的,因此需要用户自己输入标签,在通过系统计算标签之间的相似度。
在一个实施例中,所述利用领域的方法为通过数据统计出标签之间的相似度,利用以下余弦相似度公式进行计算:
其中,b与b′均表示标签,N(b)为有标签b的案例的集合,n
此外,用户在实际使用过程中,利用本方法的具体运行方式与流程步骤如下:
1)每一种案由选择20种用户输入,同时选中5个基本相关案件,5个不相关案件,5个非常相关案件;
2)然后由用户自己选择,并根据算法推荐TOP5相关案件,由用户自行判断是否相关;
3)用户输入相同,案例相同时,选择次数最高的作为评价值;
4)用户选择具体案件后给用户提供相似案件选择。
而通过上述运行过程,用户的选择“非常相关”的比率越来越高,代表推荐算法在运行过程中运行良好。选择“非常相关”统计数据如图3所示。
根据本发明的另一个实施例,如图4所示,还提供了一种基于协同过滤推荐算法用于案例推荐的系统,该系统包括以下模块组成:
用户输入模块1,用于收集当前用户的输入集;
相似度计算模块2,用于计算与当前用户输入最相近的用户输入;
推荐值计算模块3,用于计算案例推荐值并选取最大的案例给当前用户;
标签评价与计算模块4,用于构建并利用标签给用户推荐相似案例。
在一个实施例中,所述相似度计算模块2,用于计算与当前用户输入最相近的用户输入包括以下步骤:
若当前用户选择案由不同时,采用以下公式计算:
若选择案由相同时,采用以下公式计算:
其中,sim(u
根据上述公式判断最近邻居,并选取相似度最近的五个邻居。
在一个实施例中,所述推荐值计算模块3,用于选取推荐值最大的案例给当前用户包括以下步骤:
计算某个案例组中案例对当前用户输入的推荐值,采用以下公式计算:
其中,
选取p值最大的五个案例推荐给当前用户。
在一个实施例中,所述标签评价与计算模块4,用于构建与利用标签给用户推荐相似案例包括以下步骤:
用户对案例进行评价与增加标签;
利用推荐算法,计算用户对案例的兴趣程度,计算公式为:
其中,用户输入标签行为(u,i,b)代表用户u对i案例打上b标签,n
利用领域的方法将标签扩展至其他案件。
综上所述,借助于本发明的上述技术方案,通过运用协同过滤算法及对其进行改进,能够提高推荐案例的准确性,在用户选择输入项后,会根据系统推荐的案例选择不相关、基本相关、非常相关,从而能够有效地提高用户对案例的理解程度,降低民众维权的专业性限制。同时本方法通过改进现有推荐算法能够根据用户的选择项直接判断是否为相似输入,甚至找到相同输入,从而减少现有算法中的数据矩阵构建,提高效率与推荐的准确率。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 一种基于协同过滤推荐算法用于案例推荐的方法与系统
- 一种基于协同过滤推荐算法的HLS缓存方法及系统