一种图像检索模型、训练方法
文献发布时间:2023-06-19 12:24:27
技术领域
本发明属于人工智能技术领域,特别涉及一种图像检索模型、训练方法。
背景技术
对于图像检索识别领域,设计一个有效的相似性度量是提高视觉分析系统性能的关键。现有文献中提出了大量的损失函数,如对比度损失[1]、三重线损失[2]、四线损失[3]、提升结构损失[4]、N对损失[5]、基于距离加权余量的损失[6]、三重线中心损耗[7]、二项式偏离损耗[8]、直方图损失[9]、角度损失[10]、多重相似性损失[11],对于这种基于对的损耗,将样本分为正对和负对,它们都从样本中提取信息,以缩短正对之间的距离,从而将负样本推开。
对比损失:基于成对数据,对比损失旨在最小化正对之间的距离,同时惩罚负对之间的距离小于预定义的裕度m。对比损失只挖掘距离小于m的负对,并为所有选择的对分配相等的权重。
三重态损耗:基于三重态数据,设计了三重态损耗,使三重态中正对的距离比负对的距离小一个裕度m。具体地说,三元组损失挖掘出合适的样本,形成信息丰富的三元组,并为所有选择的对分配相等的权重。
N对损耗:三重态损耗同时拉一个正样本,同时推一个负样本。为了通过与更多的负类和样本的相互作用来提高三重态的损失,设计了N对损失来从N-1类的N-1个负样本(每个类一个负样本)中识别出一个正样本。具体地说,N对损失挖掘信息样本时,每类随机抽取一个正对,形成N对,然后利用N对之间的多类关系进行挖掘。然后它为三重态中的正负对分配相等的权重。
提升结构损失:不再只使用每一类的一个负样本,而是将所有的负样本纳入训练小批量中。对于每一个正样本对,提升结构化损失的目标是拉得尽可能近,并将对应的所有负样本推远到一个裕度m。给定一个查询样本,提升结构化损失打算在小批量中从所有对应的负样本中识别出一个正样本,以充分探索结构关系。具体来说,提升结构损耗利用所有的负样本,挖掘信息样本,使铰链函数返回非零值。然后对于正对,提升结构损失分配权重,而为每个负对分配不同的权重。
多重相似性损失:在提升结构损失的基础上,通过更广义的加权策略,设计多相似度损失,充分利用正负对。首先,通过预先设定的阈值,采用三元组准则挖掘信息对:对距离大于最小负对最小距离的正对进行采样,对距离小于正对最大距离加阈值的负对进行采样。具体地说,多相似性损失通过对正、负对的三元组准则挖掘信息对,然后分别为正对和负对分配不同的权重。
本文涉及的参考文献包括:
[1]R.Hadsell,S.Chopra,and Y.LeCun,“Dimensionality Reduction byLearning an Invariant Mapping,”in 2006IEEE Computer Society Conference onComputer Vision and Pattern Recognition-Volume 2(CVPR’06),New York,NY,USA,2006, vol.2,pp.1735–1742,doi:10.1109/CVPR.2006.100.
[2]W.Ge,W.Huang,D.Dong,and M.R.Scott,“Deep Metric Learning withHierarchical Triplet Loss,”in Computer Vision–ECCV 2018,vol.11210,V.Ferrari,M.Hebert,C.Sminchisescu,and Y.Weiss,Eds.Cham:Springer InternationalPublishing,2018,pp.272–288.
[3]M.T.Law,N.Thome,and M.Cord,“Quadruplet-Wise Image SimilarityLearning,”in 2013IEEE International Conference on Computer Vision,Sydney,Australia,Dec.2013,pp.249–256,doi:10.1109/ICCV.2013.38.
[4]H.O.Song,Y.Xiang,S.Jegelka,and S.Savarese,“Deep Metric Learningvia Lifted Structured Feature Embedding,”in 2016IEEE Conference on ComputerVision and Pattern Recognition(CVPR),Las Vegas,NV,USA,Jun.2016,pp. 4004–4012,doi:10.1109/CVPR.2016.434.
[5]K.Sohn,“Improved Deep Metric Learning with Multi-class N-pair LossObjective,”in Advances in Neural Information Processing Systems 29(nips2016), vol.29,D.D.Lee,M.Sugiyama,U.V.Luxburg,I.Guyon,and R.Garnett,Eds.LaJolla:Neural Information Processing Systems(nips),2016.
[6]C.-Y.Wu,R.Manmatha,A.J.Smola,and P.Krahenbuhl,“Sampling Matters inDeep Embedding Learning,”in 2017Ieee International Conference on ComputerVision(iccv),2017,pp.2859–2867.
[7]X.He,Y.Zhou,Z.Zhou,S.Bai,and X.Bai,“Triplet-Center Loss for Multi-View 3D Object Retrieval,”arXiv:1803.06189[cs],Mar.2018,Accessed:Oct. 18,2020.[Online].Available:http://arxiv.org/abs/1803.06189.
[8]D.Yi,Z.Lei,and S.Z.Li,“Deep Metric Learning for Practical PersonRe-Identification,”arXiv:1407.4979[cs],Jul.2014,Accessed:Oct.18,2020.[Online].Available:http://arxiv.org/abs/1407.4979.
[9]E.Ustinova and V.Lempitsky,“Learning Deep Embeddings withHistogram Loss,”in Advances in Neural Information Processing Systems 29(nips2016),vol. 29,D.D.Lee,M.Sugiyama,U.V.Luxburg,I.Guyon,and R.Garnett,Eds.2016.
[10]J.Wang,F.Zhou,S.Wen,X.Liu,and Y.Lin,“Deep Metric Learning withAngular Loss,”in 2017Ieee International Conference on Computer Vision(iccv),New York:Ieee,2017,pp.2612–2620.
[11]X.Wang,X.Han,W.Huang,D.Dong,and M.R.Scott,“Multi-Similarity Losswith General Pair Weighting for Deep Metric Learning,”arXiv:1904.06627[cs],Mar.2020,Accessed:Oct.17,2020.[Online].Available: http://arxiv.org/abs/1904.06627.
发明内容
本发明提供一种图像检索模型以及训练方法,涉及图像检索和计算机领域。本发明实施例通过对不同相似度的样本赋予不同权重来减少过高相似度的样本对损失函数的影响,实现了一种基于深度度量学习的排序相似性损失的细粒度图像检索方法。
附图说明
通过参考附图阅读下文的详细描述,本发明示例性实施方式的上述以及其他目的、特征和优点将变得易于理解。在附图中,以示例性而非限制性的方式示出了本发明的若干实施方式,其中:
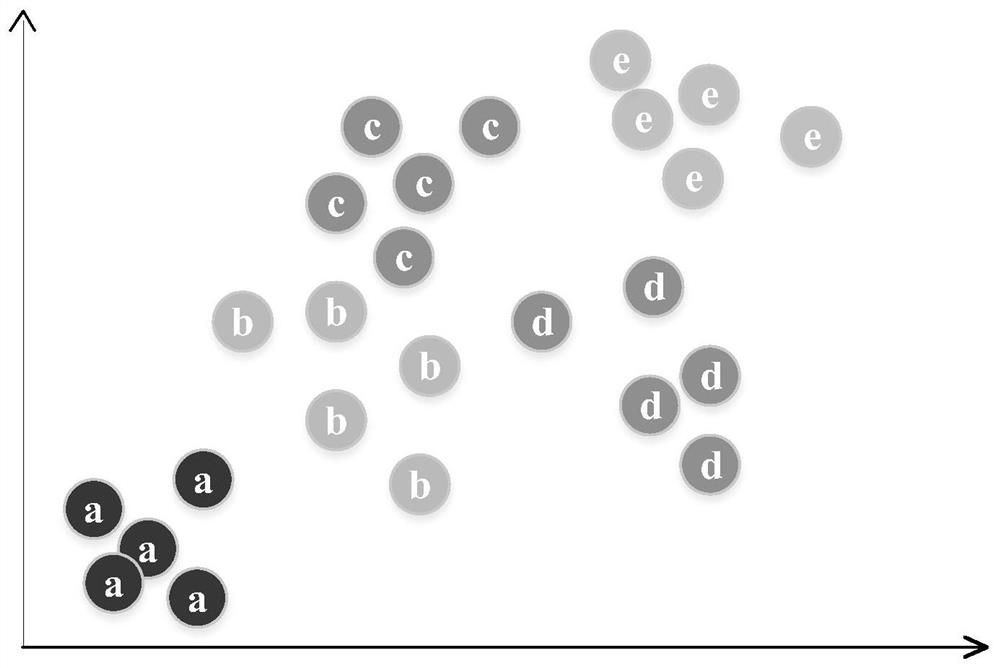
图1本发明实施例中将不同类别样本拉开不同的距离示意图。
具体实施方式
在图像检索模型设计中,由一个查询样本组成的负对之间可能具有不同的相似性,因为它们可能由不同的类构成。一般来说,如果将样本q称为查询样本,将与样本q同一类别的样本组成的样本对称为正样本对,将与不同类别的样本组成的样本对称为负样本对。
尽管进行了积极的研究,但对于负样本对问题,现有方法大多只是为了鼓励不同类别的图像之间存在较小的相似性,这可能会导致不同类别的负样本聚集在一起,难以分离。一个实际的问题是,推开的不同类的图像之间的距离不应该完全相同。这样,就可以得到一个嵌入空间,即不同类的负样本之间拉开不同的距离。在一些文献中,研究者提出了一种对具有不同相似度的样本进行加权的方案,比如多相似度损失,作者只对样本进行加权,而没有在不同类别的样本之间画出距离。
如图1,对于一个查询样本,来自其他不同类别的样本与其组成的负样本对的相似度很可能性是不同的,因为各个类别的样本之间本身就存在差异。因此在计算loss函数时,尤其对于负样本对,不应该简单的推远负样本之间的距离,而是应该对于不同类别的负样本,推开到不同的距离上,以此拉开各个类别样本之间的距离,已达到更好分类的目的。
举例来说,如果一个负样本对之间的相似度较大,则说明这个负样本与查询样本之间本身就存在很高的相似度,因此保证他们之间存在一个较小的距离才是合理的方案,即适当减小该负样本对对loss函数的影响。反之,如果一个负样本对之间的相似度较小,则说明这两个样本之间的差异确实较大,对于这种样本对,合理的方法应该是让他们之间拉开较大的距离。而不像多数Loss函数那样,负样本对之间的相似度越大,对loss函数的影响越大,相似度越小,对loss函数的影响越小,这样会导致在训练的后期,loss函数不能准确的表示出训练结果与优化目标之间的差距,因而无法进一步提高准确度。
因此,要解决前述提出的技术问题,可以考虑以下几个方面:
1、设计合理的损失函数,在深度度量学习的过程中,网络能够充分利用样本对中的特征信息并使之尽快收敛。
2、为达到更佳的效果,需要合理的控制样本对的相似度对损失函数、对网络产生的影响。尤其对于高相似度的样本对,损失函数的设计应该适量减小该类型样本对对网络产生的影响,从而使高相似度的负样本对不会分开过大的距离,导致网络过拟合现象。
3、在拉开各个类别负样本之间距离的同时,正负样本之间的距离应该同时拉开更大的距离,这样才可以避免由于各个类别的负样本对之间拉开了较大距离,而使正负样本的区分难度增大。
4、为保证执行效率以及降低对硬件的要求,在设计的损失函数时,不应出现过于庞大、复杂的计算,保证算法可观的执行效率,同时避免过高的硬件性能开销。
根据一个或者多个实施例,一种图像检索模型训练方法,对于训练样本,拉开不同类负样本之间的距离。
如公式(1),在MS loss中,对于不同的负样本对的相似,,不应该毫无区别的直接作用于损失函数。
对于负样本中相似度较低的样本,由于其本身对Loss函数的影响效果较小,因此不做过多处理,相反,负样本中相似度高的样本会对Loss函数产生较大影响,使二者拉开很远距离,因此可以设计一个方法,降低高相似度的负样本对Loss函数产生的影响。具体方法如下:
对于所有负样本,按照与查询样本的相似度降序排序,δ
S
其中,r为比例系数,n为所有负样本的数量。
根据一个或者多个实施例,一种图像检索模型训练方法,对于训练样本,拉开正负样本之间的距离。
对于同一个查询样本,与它组成的正样本对和负样本对之间应该拉开一定的距离,以便更好地区别本类和其他类,因此正样本对的相似度
为使正负样本对的相似度对Loss函数产生更具差异性的影响,对二者进行了调整,将正样本的相似度进行了不同于负样本对的处理,负样本保持不变,如公式(6)-(7):
的Loss函数将在MS Loss的基础上进行改进,过上面的讨论,采用的Loss函数为公式(8):
该损失函数简称为RMSLoss。公式(8)中,符号参数的含义说明如下: i、k分别代表第i个、第k个样本;
m是全部样本的数量;
P为正样本对集合;
P
N为负样本对集合;
N
n为选择的负样本对数量;
δ为负样本对相似度从高到底排序的顺序(1-n);
r为阈值参数,代表对负样本对优化的权重;
λ、d为阈值参数,共同表示将正负样本拉开的距离(相似度差距);
S表示相似度;
S
α、β为阈值参数,分别代表对正样本对损失的权重和对负样本对损失的权重。
根据本发明实施例,对本发明实施例在三大公共数据集上进行测试,这三大数据集分别是,
(1)CUB-200-2011:有200种鸟类的11788张图片。前100个类别的5864张图片用于训练网络,其他100个类别的5924张图片用于测试。
(2)CARS196:包含196个车型的16185张图片。使用前98个类别(8054张图片)进行训练,其余98个类别(8131张图片)用于测试。
(3)SOP:包含在eBay网上销售的22634个在线产品的120053个图像,训练和测试分别使用11318个类别的59551个图像和11316个类别的60502个图。
对于以上三个数据集,测试方法是在原始图像上进行的,对所有输入图像被裁剪成224x224像素,使用随机裁剪和随机水平镜像进行训练,单中心裁剪用于测试。
根据度量标准,用Recall@K来描述图像检索性能和图像聚类质量。本发明实施例方法由PyTorch框架方法实现。对于网络体系结构,使用具有批处理规范化的初始网络作为的主干网络,在ILSVRC 2012-CLS上进行了预培训,并针对的任务对其进行了微调。在一个16GB内存的Tesla p100GPU上运行图像检索模型实验。对于每一个小批量,随机选择一定数量的类,然后从每个类中随机抽取M个实例,M=5,用于所有实验中的所有数据集。将所有三个数据集的基本学习率设置为1e-5。全连接层的输出尺寸设为d=512。
本发明最终由实验结果数据来证明其有效性,为了验证两个方法分别的效果,采用对比实验来观察在Recall@k的评判指标下的数值变化情况。
1、首先验证拉开不同类别负样本之间的距离方法的有效性,下面的实验对比了MS Loss、MSLoss采用了提出的拉开不用类别负样本之间的距离方法,以及 RMS Loss去掉该方法后的效果,如表格1所示排序加权方法的影响。
表格1
2、对比了Lifted structure loss和MSloss以及分别加上正负样本拉开距离的思想后调整得到的loss函数产生的结果,如表,观察可以发现,在loss中对正负样本的相似度进行区别化处理会进一步提升训练结果,如表格2所示正负样本拉开距离的影响。
表格2
3、最终,本发明将两个前述实施例的方法结合起来,通过对每个参数进行对比实验后,得出了最佳效果,下面是本发明与其他研究成果的效果对比。通过表格可以看出该方法达到了最佳效果,如表格3所示本发明与其他方法的效果对比。
表格3
在本实施例中,对相关参数影响及优化包括以下参数。
1.排序参数r
r为排序加权方式对Loss函数的比重,为了验证排序参数r的大小对效果的影响,设置r=0.05和r=0.2进行对比试验,结果如表格4所示,观察可以发现r<0.1 或者r>0.1后,训练结果开始下降,当r=0时,排序加权不产生任何影响,r越大则排序加权的影响越大。表格4表示参数r的影响。
表格4
2.正负样本拉开距离参数λ
λ为正负样本拉开距离的表示,为验证其最佳效果,将其从0.6到1.0进行对比实验,实验结果如表格5所示参数λ的影响,当λ=0.8时,Recall@k达到最佳效果。
表格5
3.加权权重参数δ
δ为对样本对相似度加权的基础权重参数,为验证其对效果的影响,将从0.04 到0.08进行对比实验,实验结果如表格6所示参数δ的影响,其中当δ=0.06 时,实验达到最佳效果。
表格6
值得说明的是,虽然前述内容已经参考若干具体实施方式描述了本发明创造的精神和原理,但是应该理解,本发明并不限于所公开的具体实施方式,对各方面的划分也不意味着这些方面中的特征不能组合,这种划分仅是为了表述的方便。本发明旨在涵盖所附权利要求的精神和范围内所包括的各种修改和等同布置。
- 图像检索模型的训练方法及图像检索方法、装置、及介质
- 图像检索模型训练方法、图像检索方法、设备及存储介质