一种多模态特征融合的视频描述文本生成方法
文献发布时间:2023-06-19 13:45:04
技术领域
本发明属于视频文本描述生成技术领域,涉及一种多模态特征融合的视频描述文本生成方法。
背景技术
视频文本描述的任务是自动生成一个完整自然的句子来描述视频内容,准确地对视频中包含的内容进行理解在实际中具有重要意义和广泛应用。比如面对海量的视频数据,可以利用视频文本描述进行快速高效的视频检索,也可以利用生成的视频文本描述对视频进行智能审核。
在视频描述文本生成过程中,如果不能更好的学习到视频多模态特征中包含的语义信息,会导致视频内容和生成的描述之间的语义不一致的问题。目前2D和3D卷积神经网络已成功地改善了从视觉、音频和运动信息中学习表示的技术,但是解决如何将提取到的视频多模态特征进行聚合的问题,仍然是一个可以提升文本描述准确率的研究思路。
发明内容
本发明的目的是提供一种多模态特征融合的视频描述文本生成的方法,解决了现有技术在视频描述文本生成中,存在视频内容和生成的描述之间的语义不一致的问题。
本发明采用的技术方案是,一种多模态特征融合的视频描述文本生成方法,按照以下步骤实施:
步骤1、建立数据集、验证集及语义词典;
步骤2、构建多模态特征融合网络,获得聚合特征;
步骤3、利用语法感知视频动作的编码器获得描述语句的主语、谓语和宾语;
步骤4、利用动作指导解码器,生成视频的描述文本;
步骤5、训练视频文本生成网络模型;
步骤6、生成视频的文本描述语句,
经过步骤1至步骤5完成网络训练之后,获得视频文本生成网络模型的所有参数;再将待描述视频作为输入视频,进行步骤2至步骤4之后,获得待描述视频的文本描述。
本发明的有益效果是,在视频描述文本生成网络模型中,将2D卷积神经网络获得的RGB特征和3D卷积神经网络获得的时序特征,通过多模态特征融合模型,获得更符合文本描述需求的聚合特征,聚合特征与语法感知预测动作模块生成的谓语编码信息结合,将其送入到解码网络模型中,对输入视频进行文本描述。采用本发明方法生成的视频描述文本与目前检索到的主流论文的算法指标相比,具有更高的准确性。
附图说明
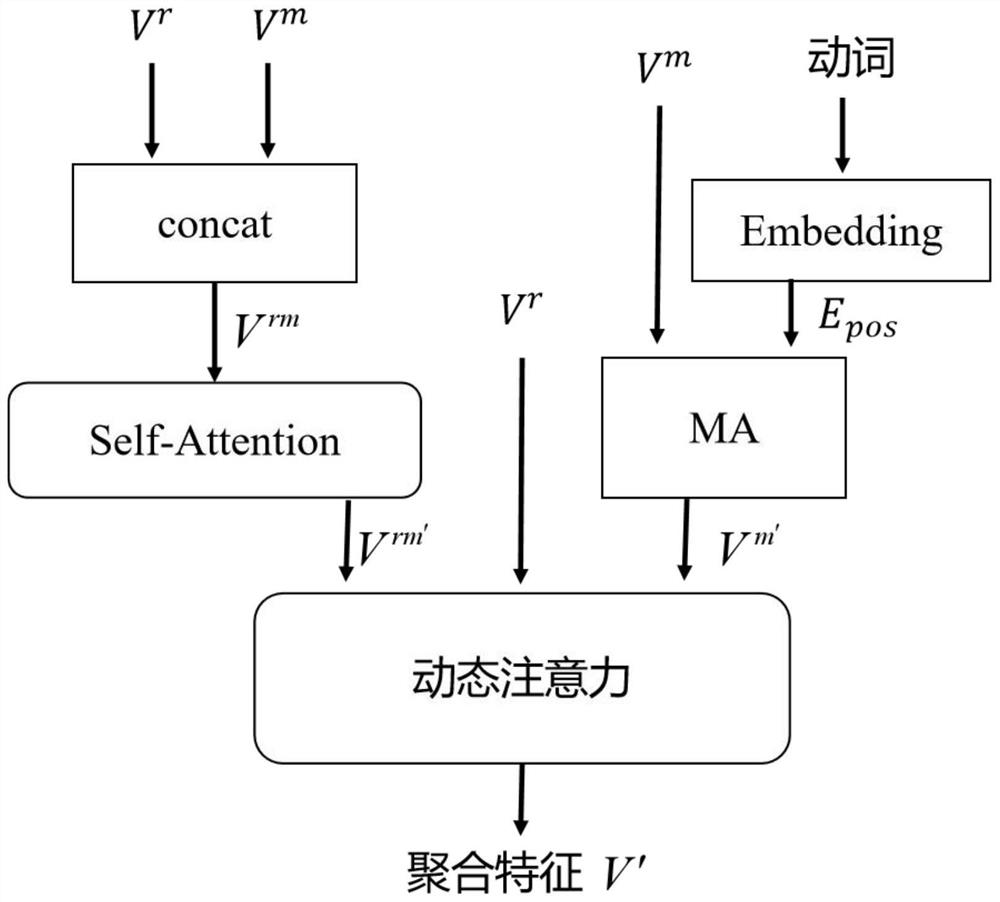
图1是本发明方法的多模态特征融合模型的流程图;
图2是本发明方法中的自注意力机制流程图;
图3是本发明方法中的基于语法感知预测动作模块的编码器流程图;
图4是本发明方法的语法感知预测动作模块中的编码层流程图;
图5是本发明方法所采用的解码器模型的流程图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明的多模态特征融合的视频描述文本生成方法,按照以下步骤具体实施:
步骤1、建立数据集、验证集及语义词典,具体过程是,
1.1)构建数据集和验证集,
因为视频的文本描述网络的数据集的泛化能力的要求,除了特殊情况下需要采用自制的标注的数据集,一般情况下均建议采用公开的数据集;
本步骤优选目前使用率相对较高的视频描述文本生成数据集MSR-VTT和MSVD;其中,MSVD数据集包含1967个YouTube公开短视频,每个视频主要显示一个活动,持续时长为10s~25s,视频包含不同的人、动物、动作及场景等,由不同的人对视频内容进行标注,平均每条视频对应40条文本描述语句;MSR-VTT数据集共10000个视频,平均每个视频对应20条文本描述语句;
从前述MSR-VTT和MSVD数据集中随机选择一部分(本步骤优选为全部数据的80%)作为训练集的数据样本,剩下20%的样本作为验证集样本;
1.2)建立语义词典,
从训练集和验证集的样本标注中,将所有单词按出现次数由高到低排序,选择前m个单词,组成语义概念集合,m是经验值,m优选总单词数的前80%到85%;
先给每个单词分配一个0至m的整数序号,之后(给每个单词)加上四个附加标记,即开始标识
假设训练集的样本总数为N,i是其中的第i个视频样本,i=1,2,...,N,L是第i个视频的文本描述长度;利用建立的语义词典对数据集样本进行语义词典标注,表达式是:
Y
其中,y
步骤2、构建多模态特征融合网络,获得聚合特征,
2.1)提取视频的多模态特征,
采用三个网络结构联合提取视频的多模态特征,首先,对一个输入视频(在模型训练时,输入视频为步骤1给出的训练样本视频,训练结束之后,输入视频为需要进行文本描述的视频)进行等间隔采样,获得预处理后的T帧长度的视频,(T为经验值,结合所需要描述的视频内容决定,优选T∈[16,64]);之后,提取预处理后视频的二维RGB特征和目标区域特征,分别采用二维卷积网络InceptionResnetV2(IRV2)(是现有技术)的最后一层平均池化层输出M
V={V
2.2)利用多模态特征融合模型获取聚合特征,
2.2.1)利用自注意力机制模块计算场景表示特征V
如图1所示,利用多模态特征融合模型的构架,将步骤2.1)得到的二维RGB特征V
{Q
其中,W
2.2.2)如图2所示,利用Self-Attention模块,首先计算查询向量Q
其中,
2.2.3)构建MA模块计算运动特征V
将步骤1中得到的三维时序特征V
其中,W
2.2.4)构建动态注意力模块求解聚合特征V',
前述步骤2.2.1)和步骤2.2.2)得到的场景表示特征V
步骤3、利用语法感知视频动作的编码器获得描述语句的主语、谓语和宾语,
进行语法感知视频动作所用的编码器采用的基本结构为SAAT网络模型(SAAT网络模型为现有技术),属于一种语法感知预测动作模块,分为组件提取器-编码器(Cxe)和组件提取器-解码器(Cxd);
如图3所示,组件提取器-编码器(Cxe)和组件提取器-解码器(Cxd)的结构相同,均是由一个Embedding层和三个结构相同基于自注意力机制的Encoding层堆叠组成;
如图4所示,每个Encoding层的结构是,由一个自注意力机制(Self-Attention)、层归一化(layerNorm)和非线性前馈网络(FFN)组成,具体过程是:
3.1)由组件提取器-编码器(Cxe)得到场景语义特征V
将步骤2.1)得到的视频的目标区域特征
3.1.1)将视频的目标区域特征V
其中,
3.1.2)将步骤3.1.1)得到的级联特征R
{Q
其中,W
3.1.3)经过一个基于自注意力机制的Encoding层(见图2)计算Q
3.2)利用组件提取器-解码器(Cxd)得到视频动作,即文本描述语句的谓语,
利用视频的多模态特征和场景语义特征V
3.2.1)设置全局RGB特征V
E
p
其中,
3.2.2)将步骤3.2.1)得到的主语的编码特征E
E
p
其中,
3.2.3)将谓语的编码特征E
E
p
其中,W
步骤4、利用动作指导解码器,生成视频的描述文本,
如图5所示,利用解码器模型,具体过程如下:
4.1)通过Attention模块,计算谓语特征编码E
将步骤3.2.2)中公式(13)计算出的谓语的特征编码E
其中,
4.2)通过LSTMs(是公开技术)生成单词预测结果h
其中,W
4.3)计算预测单词概率,
预测结果经过softmax函数得到t时刻单词预测概率p
p
word
其中,W
4.4)令t=t+1,循环执行步骤4.1)至步骤(4.3),直到预测的word
步骤5、训练视频文本生成网络模型,
将步骤1给出的所有训练样本输入视频文本生成网络模型,重复步骤2至步骤4,使用标准的交叉熵损失来进行训练,视频文本生成网络模型的总损失函数是SAAT模块的最小化损失L
L(θ)=L
其中,word
步骤6、生成视频的文本描述语句,
经过步骤1至步骤5完成网络训练之后,便可获得视频文本生成网络模型的所有参数;再将待描述视频作为输入视频,进行步骤2至步骤4之后,便可获得视频的文本描述。
至此,构建的视频文本生成网络模型可以根据视频多模态特征和视频动作引导生成的视频文本描述。
- 一种多模态特征融合的视频描述文本生成方法
- 一种基于多模态特征融合的开放域视频自然语言描述生成方法